
Heim >Technologie-Peripheriegeräte >KI >Das neue große Modell von Alibaba Cloud ist erschienen! Das KI-Artefakt „Tongyi Listening' befindet sich in der öffentlichen Beta: Lange Videos können in einer Sekunde zusammengefasst werden, außerdem können automatisch Notizen gemacht und Untertitel erstellt werden
Das neue große Modell von Alibaba Cloud ist erschienen! Das KI-Artefakt „Tongyi Listening' befindet sich in der öffentlichen Beta: Lange Videos können in einer Sekunde zusammengefasst werden, außerdem können automatisch Notizen gemacht und Untertitel erstellt werden

- 王林nach vorne
- 2023-06-03 17:23:111324Durchsuche
Ein weiteres praktisches Tool für Gruppentreffen mit Zugriff auf große Modellfunktionen, jetzt für die kostenlose öffentliche Beta verfügbar!
Das große Vorbild dahinter ist Alibabas Tongyi Qianwen. Warum es angeblich ein magisches Werkzeug für Gruppentreffen ist –
Sehen Sie, das ist mein Lehrer an Station B, Herr Li Mu, der Schüler dazu bringt, eine große Modellarbeit intensiv zu lesen.
Leider drängte mich in diesem Moment der Chef, die Steine schnell zu bewegen. Mir blieb nichts anderes übrig, als lautlos meine Kopfhörer abzunehmen, auf das Plug-in „Tongyi Listening“ zu klicken und dann die Seite zu wechseln.
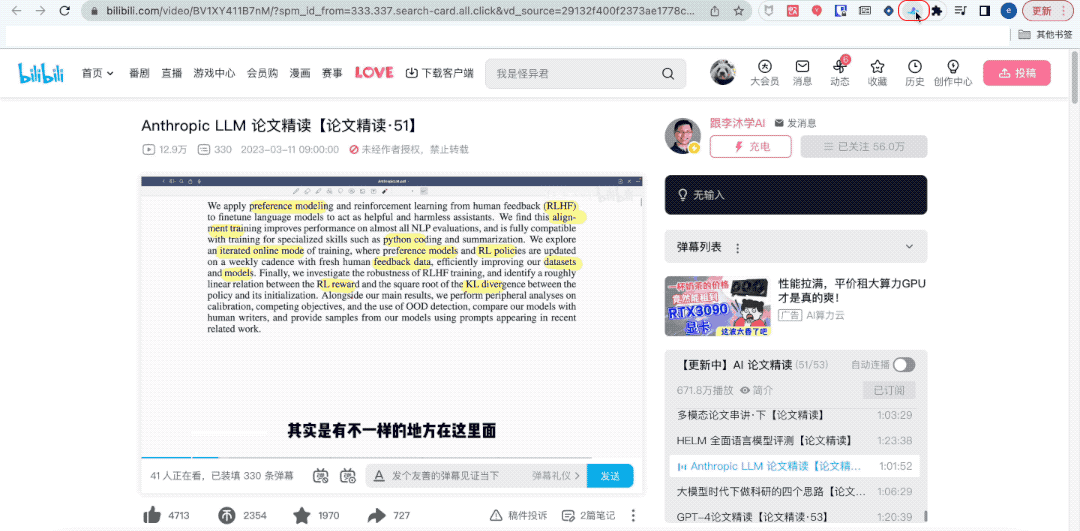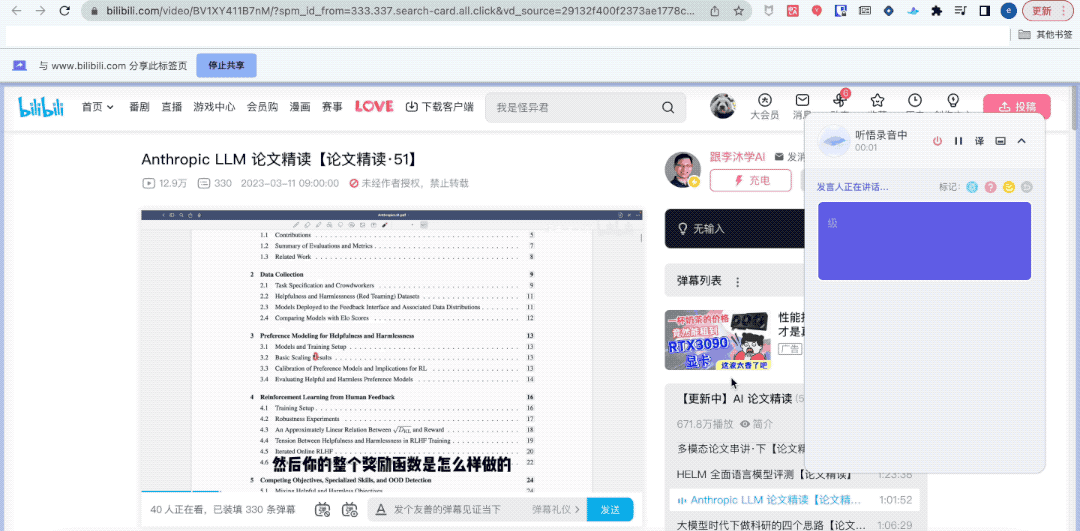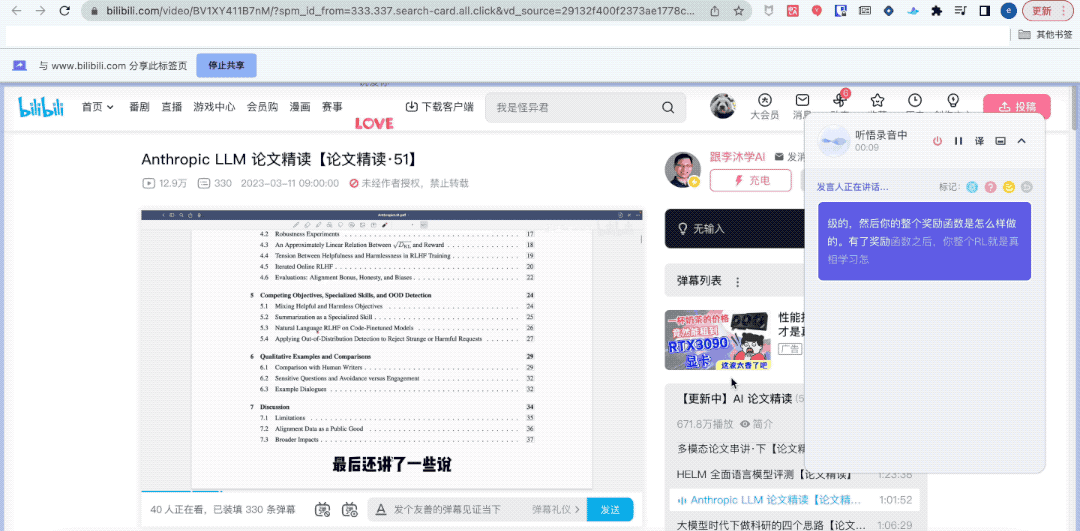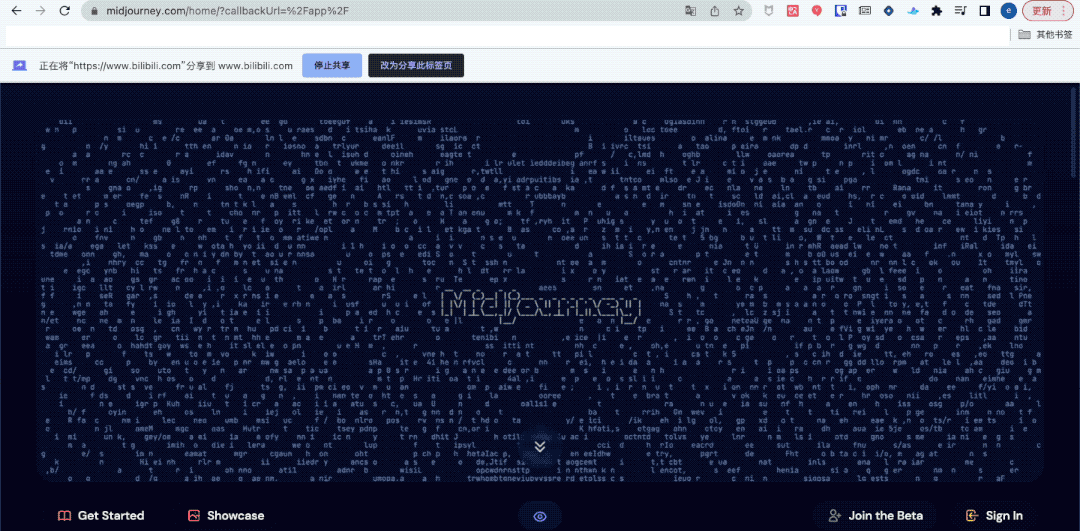
Wissen Sie was? Obwohl ich nicht beim „Gruppentreffen“ dabei war, hat mir Tingwu dabei geholfen, den Inhalt des Gruppentreffens vollständig aufzuzeichnen.
Es hat mir sogar geholfen, Schlüsselwörter, Volltextzusammenfassungen und Lernpunkte mit einem Klick zusammenzufassen.

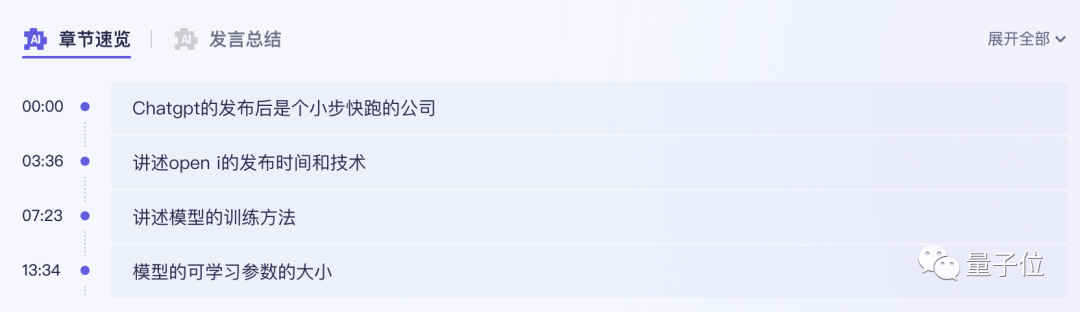
Um es einfach auszudrücken: Dieses „Allgemeine Bedeutungshören“, das gerade mit der Großmodellfunktion verbunden wurde, ist eine Großmodellversion eines KI-Assistenten im Arbeitsstudium, der sich auf Audio- und Videoinhalte konzentriert.
Im Gegensatz zu früheren Tools zur Transkription von Aufnahmen können damit nicht nur Aufnahmen und Videos in Text umgewandelt werden. Es kann den gesamten Text mit einem Klick zusammenfassen und auch die Meinungen verschiedener Sprecher zusammenfassen:
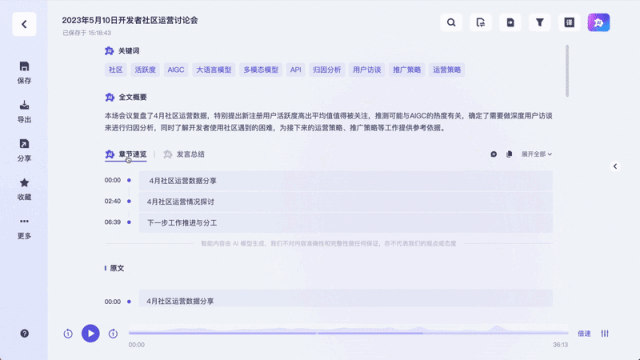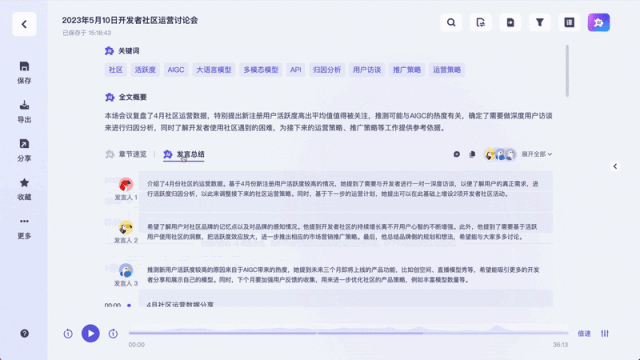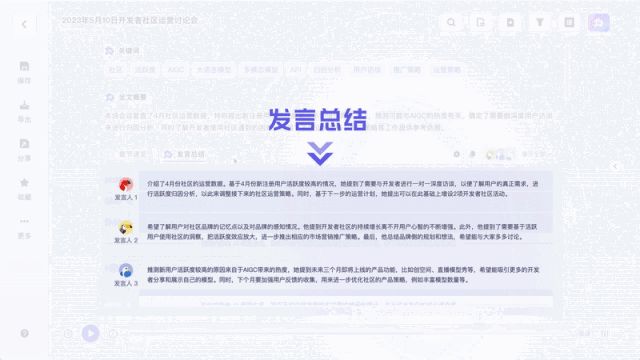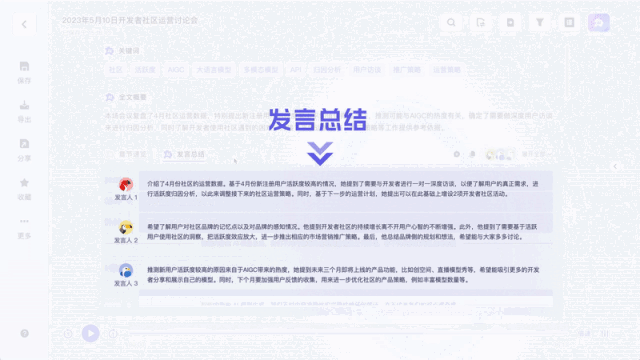
Es kann sogar als Echtzeit-Untertitelübersetzung verwendet werden:

Es scheint, dass dies nicht nur der Fall ist Nützlich für die Abhaltung von Gruppentreffen, aber auch für regelmäßige Qubits, die mit vielen Aufzeichnungen, langem Aufbleiben und verschiedenen ausländischen Konferenzen zu kämpfen haben, ist es wirklich ein neues Artefakt für die tägliche Arbeit.
Wir haben schnell einen ausführlichen Test durchgeführt.
Ein praktischer Test des Tongyi-Hörverständnisses
Der grundlegendste und wichtigste Aspekt beim Organisieren und Analysieren von Audioinhalten ist die Genauigkeit der Transkription.
In Runde 1 laden wir zunächst ein etwa 10-minütiges chinesisches Video hoch, um zu sehen, wie Tingwu im Vergleich zu ähnlichen Tools hinsichtlich der Genauigkeit abschneidet.
Grundsätzlich verarbeitet die KI dieses mittellange Audio- und Videomaterial sehr schnell und kann in weniger als 2 Minuten transkribiert werden.

Werfen wir zunächst einen Blick auf Tingwus Leistung:

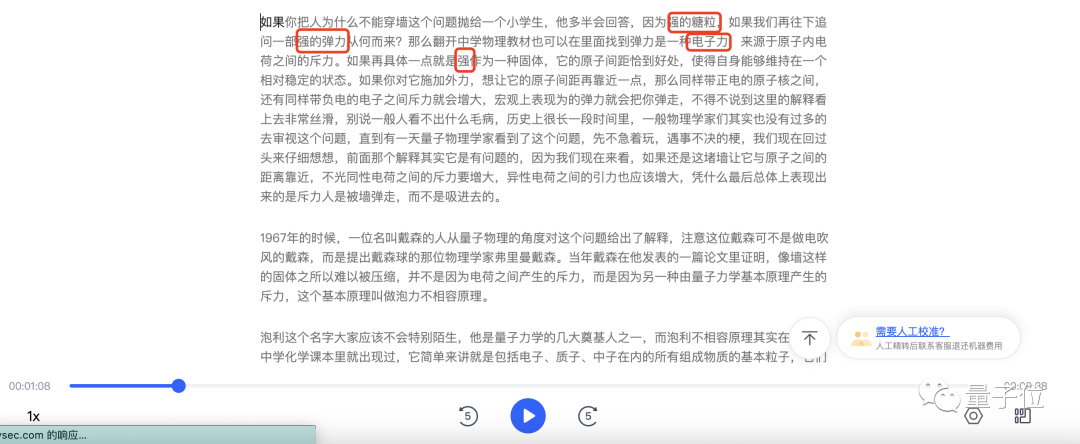
In diesem etwa 200 Wörter langen Absatz machte Tingwu nur zwei Fehler: stark → Wand, beides gut → genau richtig. Physikalische Begriffe wie Atomkern, elektrische Ladung und Abstoßung können durch Zuhören verstanden werden.
Wir haben es auch an Feishu Miaoji mit dem gleichen Video getestet. Das Grundproblem ist nicht groß, aber im Vergleich zum Zuhören von Wu machte Feishu zwei weitere Fehler. Eines der „Atome“ wurde als „Garten“ geschrieben und „Abstoßung“ wurde als „Macht“ gelesen.

Interessant ist, dass Feishu auch die Fehler, die Hengwu gemacht hat, einzeln reproduziert hat. Es scheint, dass dieser Topf von einem bestimmten Meister getragen werden muss, der in Qubit (manueller Hundekopf) spricht und Wörter schluckt.
Als iFlytek es hörte, konnte es das „genau Richtige“ unterscheiden, das die ersten beiden Teilnehmer nicht erkannten. Aber iFlytek übersetzte im Grunde alles „Wand“ in „stark“ und es entstand die magische Kombination aus „starken Zuckerkörnern“. Darüber hinaus missverstand von den drei Teilnehmern nur iFlytek „elektromagnetische Kraft“ als „elektronische Kraft“.
Im Allgemeinen ist die Erkennung von Chinesisch für diese KI-Tools nicht schwierig. Wie werden sie angesichts englischer Materialien abschneiden?
Wir haben ein aktuelles Interview mit Musk über seine früheren Streitigkeiten mit OpenAI hochgeladen.
Werfen wir zunächst einen Blick auf die Ergebnisse von Tingwu. In Musks Antworten identifizierte Hua Wu mit Ausnahme des Namens von Larry Page im Grunde alle anderen korrekt.
Erwähnenswert ist, dass Tingwu die Ergebnisse der englischen Transliteration direkt ins Chinesische übersetzen und zweisprachige Vergleiche anzeigen kann. Die Übersetzungsqualität ist ebenfalls recht gut.
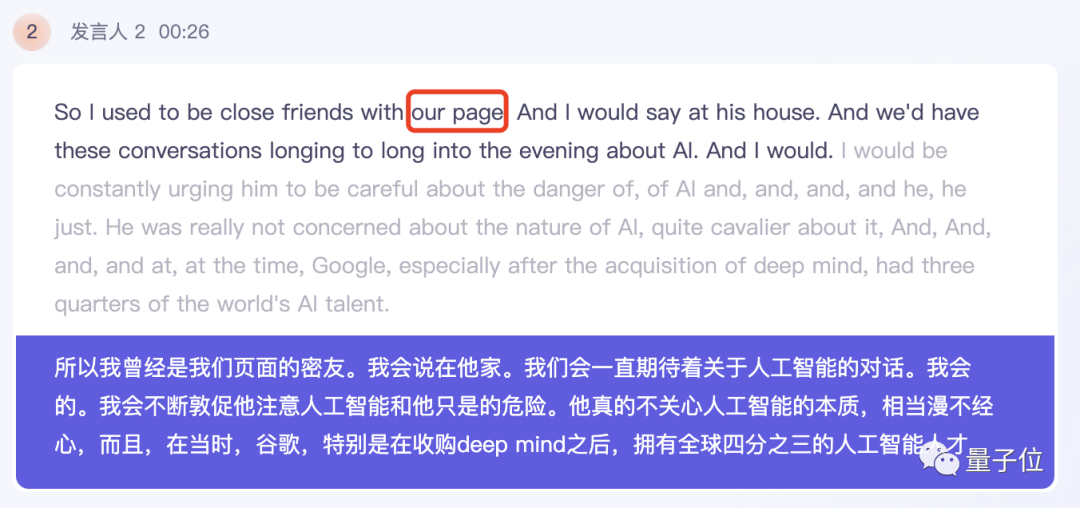
Feishu Miaoji hat den Namen von Larry Page erfolgreich gehört, aber wie beim Zuhören war Musks allgemeine Sprechgeschwindigkeit langsamer. Es ist schnell und hat einige umgangssprachliche Ausdrücke, mit einigen Moll Fehler, wie zum Beispiel „Bleib in seinem Haus“ statt „Sag dieses Haus“.

iFlytek hat hier gehört, dass die Namen und Aussprachedetails gut gehandhabt werden, aber es gibt auch Fälle, in denen man sich durch Musks umgangssprachliche Ausdrücke in die Irre führen lässt. „bis weit in den Abend hinein“ gilt als „Sehnsucht nach dem Abend“.

Es scheint, dass KI-Tools in Bezug auf die grundlegende Fähigkeit der Spracherkennung eine sehr hohe Genauigkeitsrate erreicht haben, trotz teilweise extrem hoher Effizienz Kleine Probleme überwogen die Mängel.
Dann erhöhen wir den Schwierigkeitsgrad auf Runde 2, um ihre Fähigkeit zu testen, etwa einstündige Videos zusammenzufassen.
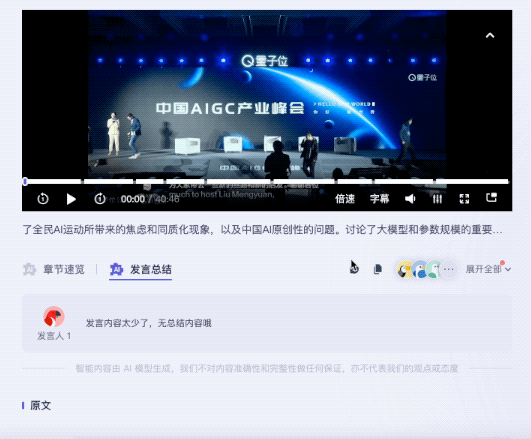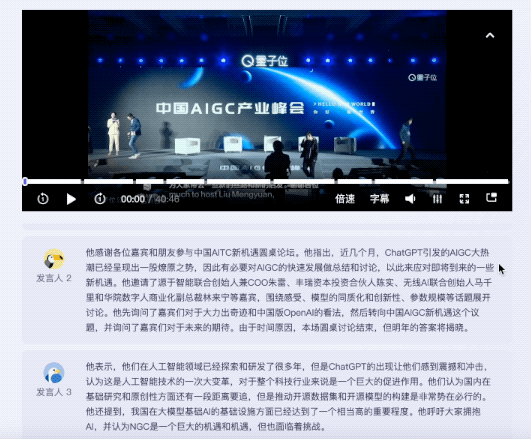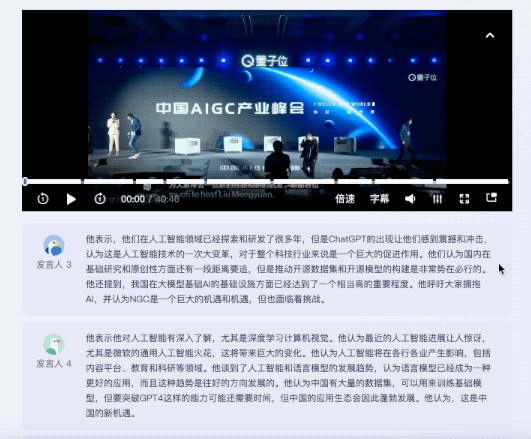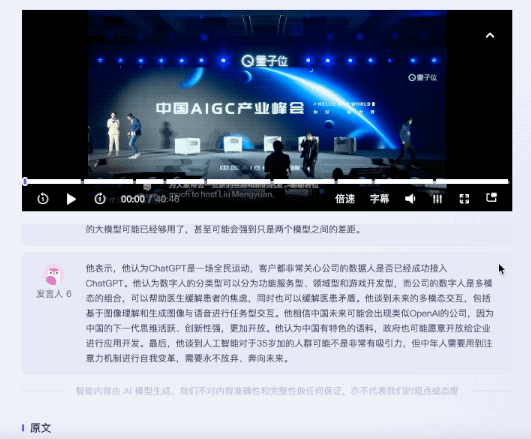
Das Testvideo ist eine 40-minütige Diskussionsrunde zum Thema neue Möglichkeiten für AIGC in China. Insgesamt nahmen 5 Personen an der Diskussionsrunde teil.
Auf der Hörseite dauerte es vom Abschluss der Transkription bis zur KI, Schlüsselwörter zu extrahieren und eine vollständige Textzusammenfassung bereitzustellen, insgesamt weniger als 5 Minuten.
Das Ergebnis ist das von Tante Jiang:


gab nicht nur Schlüsselwörter Auch der Inhalt der Roundtable-Diskussion ist gut zusammengefasst und die Kernpunkte des Videos sind ebenfalls unterteilt.
Wenn ich die von menschlichen Redakteuren ausgelesenen Themenpunkte vergleiche, rieche ich einen Hauch von Krise ...

Es ist erwähnenswert dass zum Anhören der Reden verschiedener Gäste entsprechende Zusammenfassungen ihrer Reden gegeben werden können.
Die gleiche Frage wurde Feishu Miaoji gestellt. Derzeit kann Feishu Miaoji in Bezug auf die Inhaltszusammenfassung nur Schlüsselwörter bereitstellen.

Besprechungsprotokolle müssen manuell im transkribierten Text markiert werden.

iFlytek hat gehört, dass sie intern ein Produkt testen, das auf dem kognitiven Großmodell Spark basiert, das den Inhalt von Dateien analysieren kann, aber das Ausfüllen einer Datei erfordert Bewerbung und Warteschlangen. (Freunde, die für interne Tests qualifiziert sind, können gerne ihre Erfahrungen teilen~)
Im Basis-iFlytek gibt es derzeit keine ähnliche Zusammenfassungsfunktion.

Es scheint, dass diese Testrunde:
Das Überraschendste an Tongyi Tingwu in diesem aktuellen Test ist jedoch tatsächlich ein „kleines“ Design:
Chrome-Plug-in-Funktion.
Ganz gleich, ob Sie englische Videos ansehen, Live-Übertragungen ansehen oder an Besprechungen im Unterricht teilnehmen, Sie können eine Transkription und Übersetzung von Audio und Video in Echtzeit erreichen, indem Sie auf das Listening-Plug-in klicken.
Wie eingangs gezeigt, kann es als Echtzeit-Untertitel mit geringer Latenz, schneller Übersetzung und zweisprachiger Vergleichsfunktion verwendet werden. Gleichzeitig können der aufgezeichnete und transkribierte Text mit einem Klick für die spätere Verwendung gespeichert werden.
Mama muss sich keine Sorgen mehr machen, dass ich das englische Videomaterial nicht lesen kann.
Außerdem habe ich eine mutige Idee ...
Schalten Sie das Zuhören ein, wenn Sie ein Gruppentreffen abhalten, damit Sie sich keine Sorgen mehr machen müssen, dass Sie plötzlich vom Lehrer überprüft werden.
Derzeit ist Tingwu mit Alibaba Cloud Disk verbunden. Auf der Cloud Disk gespeicherte Audio- und Videoinhalte können mit einem Klick transkribiert werden, und Untertitel können automatisch angezeigt werden, wenn Cloud Disk-Videos online abgespielt werden. KI-verarbeitete Audio- und Videodateien können künftig in der Enterprise-Version schnell intern geteilt werden.

Der Hengwu-Beamte gab außerdem bekannt, dass Hengwu in Zukunft weiterhin neue Funktionen für große Modelle hinzufügen wird, z. B. das direkte Extrahieren von PPT-Screenshots aus Videos und das direkte Stellen von KI-Fragen zu Audio- und Videoinhalten ...
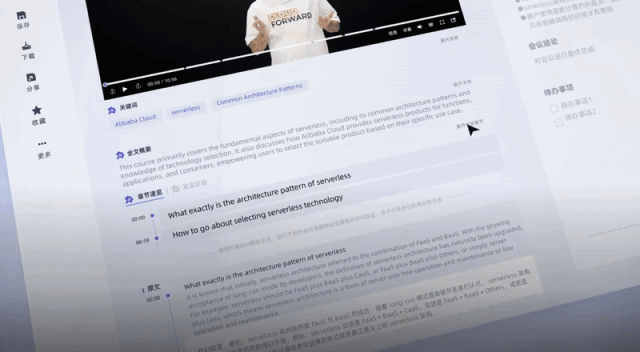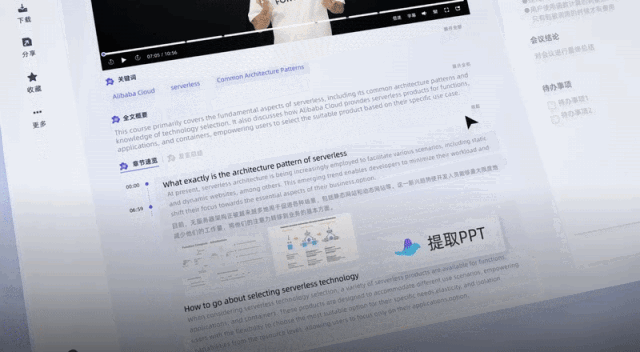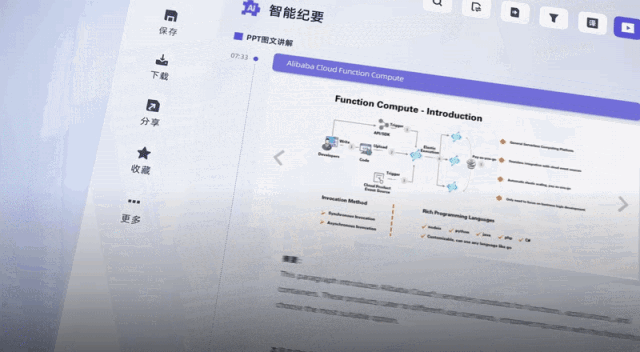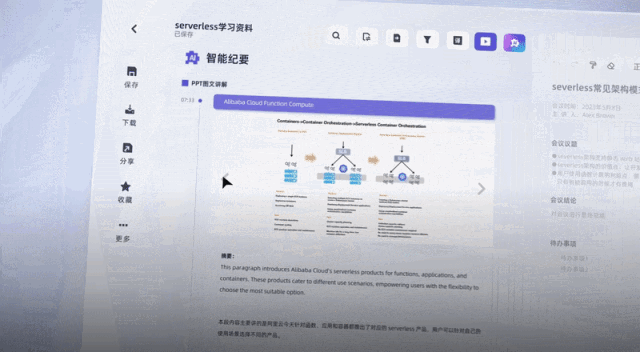

Der Schlüssel ist, dass die öffentlichen Beta-Vorteile jetzt für alle verfügbar sind, indem Sie sich jeden Tag anmelden Große Plattform-Communities werden außerdem eine große Anzahl von 20-Stunden-Transkribierungs-Passwortcodes herausgeben, und die Dauer kann gestapelt werden, gültig innerhalb eines Jahres.
Als fleißiger Wollmeister ist es kein Traum, mehr als 100 Stunden Freizeit zu sparen (manueller Hundekopf).

Die Technologie dahinter: großes Sprachmodell + Stimme SOTA
Tatsächlich wurde Tongyi Listening vor der öffentlichen Beta innerhalb von Alibaba sorgfältig aufpoliert.
Ende letzten Jahres haben einige Qubit-Leser die Listening Internal Beta Experience Card erhalten. Die damalige Version enthielt bereits Offline-Sprach-/Videotranskription und Echtzeit-Transkriptionsfunktionen.
In dieser offenen Beta hat Tingwu hauptsächlich Zugriff auf die Zusammenfassungs- und Dialogfunktionen des großen Tongyi Qianwen-Modells. Genauer gesagt basiert diese Arbeit auf dem großen Modell von Tongyi Qianwen und integriert die Forschungsergebnisse des Forschungsteams in die Argumentation, Ausrichtung und Beantwortung von Konversationsfragen.
Zuallererst ist die genaue Extraktion wichtiger Informationen der Schlüssel zur Verbesserung der Arbeitseffizienz mit dieser Art von Artefakten. Dies erfordert die Argumentationsfähigkeiten großer Modelle.
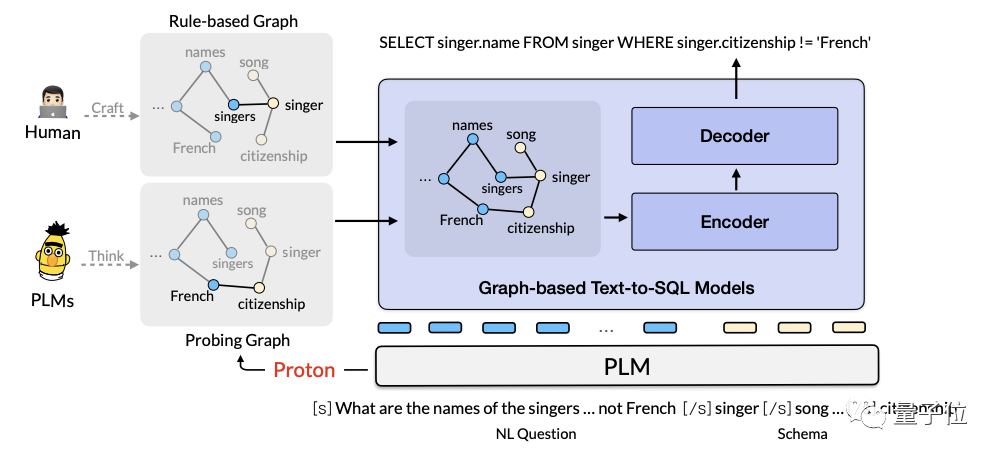
Das Alibaba AI-Team schlug im Jahr 2022 Proton (Probing Turning from Large Language Models) vor, ein Framework zur Wissenserkennung und Argumentationsnutzung, das auf großen Sprachmodellen basiert. Das entsprechende Papier wird auf internationalen Top-Konferenzen wie KDD2022 und SIGIR2023 veröffentlicht.

Die Kernidee dieses Frameworks besteht darin, das interne Wissen großer Modelle zu erkennen und die Denkkette als Träger für Wissensfluss und -nutzung zu nutzen.
Proton belegt den ersten Platz in den drei Hauptlisten Commonsense QA2.0, Physical Commonsense Reasoning PIQA und Numerical Commonsense Reasoning Numbersense.
Auf der TabFact-Liste (Faktenüberprüfung) hat Proton mit seiner Wissenszerlegungs- und vertrauenswürdigen Denkkettentechnologie zum ersten Mal übermenschliche Ergebnisse erzielt.
Zweitens: Um sicherzustellen, dass der Inhalt und das Format der Zusammenfassung in Bezug auf die Ausrichtung den Erwartungen der Benutzer entsprechen, verwendet Listening auch ELHF, eine effiziente Ausrichtungsmethode, die auf menschlichem Feedback basiert.
Diese Methode erfordert nur eine kleine Anzahl hochwertiger manueller Feedback-Beispiele, um eine Ausrichtung zu erreichen. Bei der subjektiven Bewertung von Modelleffekten kann ELHF die Erfolgsquote des Modells um 20 % steigern.
Darüber hinaus hat das Forschungs- und Entwicklungsteam hinter Wu auch Doc2Bot veröffentlicht, einen sehr umfangreichen Datensatz für chinesische Dokumentkonversationen. Die Re3G-Methode des Teams zur Verbesserung der Fragebeantwortungsfähigkeiten des Modells wurde für ICASSP 2023 ausgewählt: Diese Methode kann die Antwort des Modells auf Benutzerfragen in vier Phasen verbessern: Retrieve (Abruf), Rerank (Neuranking), Refine (Feinabstimmung) und Generate ( Seine Fähigkeiten zum Verstehen, zum Wissensabruf und zur Antwortgenerierung belegten den ersten Platz in den beiden wichtigsten Dokumentendialoglisten von Doc2Dial und Multi Doc2Dial.
Neben den Fähigkeiten großer Modelle beherrscht Tingwu auch die Sprachtechnologie von Alibaba.
Das dahinter stehende Spracherkennungsmodell Paraformer von der Alibaba Damo Academy löst das Problem des Ausgleichs von End-to-End-Erkennungseffekt und -effizienz erstmals auf Anwendungsebene auf industrieller Ebene:
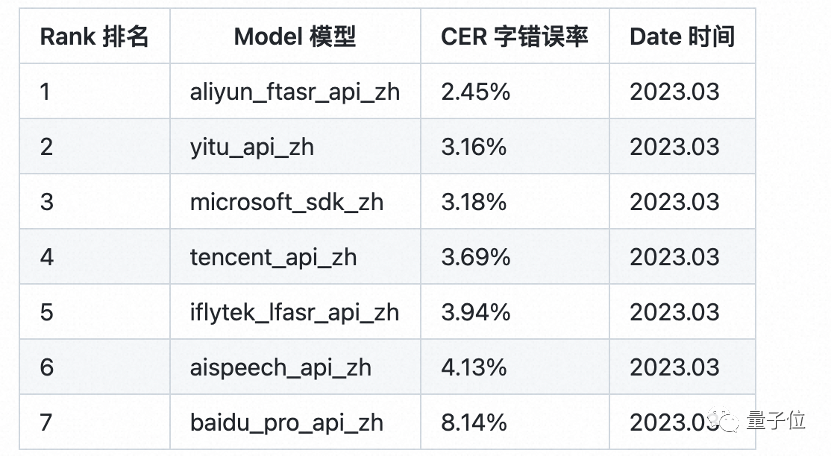
Es verbessert nicht nur die Argumentationseffizienz um 10 Zeiten im Vergleich zu herkömmlichen Modellen und brach bei seiner ersten Einführung auch die Rekorde vieler maßgeblicher Datensätze, wodurch die Genauigkeit der Spracherkennung SOTA aufgefrischt wurde. Im professionellen White-Box-Test zur Bewertung der chinesischen Spracherkennung SpeechIO TIOBE in der öffentlichen Cloud mit vollständigem Netzwerk eines Drittanbieters ist Paraformer-large immer noch das chinesische Spracherkennungsmodell mit der höchsten Genauigkeit.
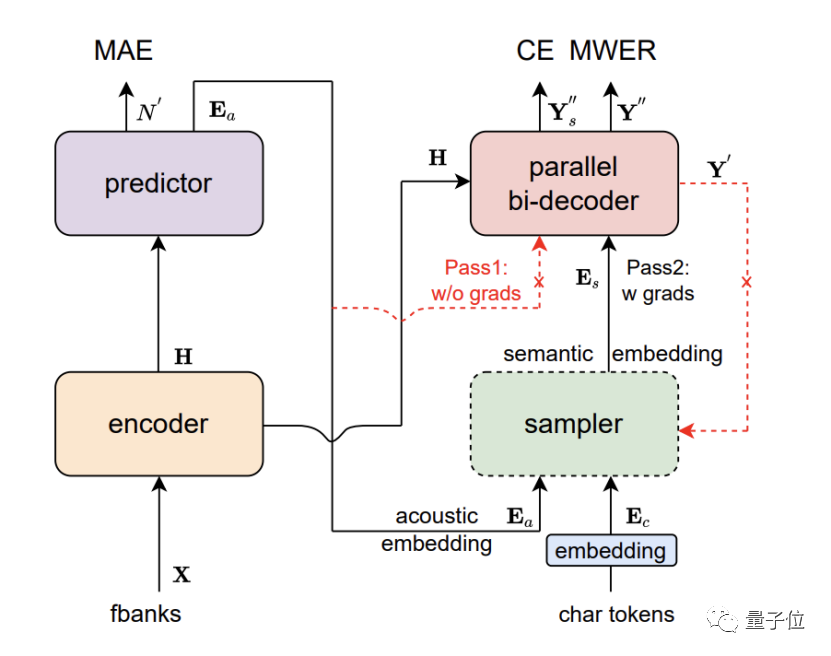
Paraformer ist ein nicht autoregressives Einzelrundenmodell, das aus fünf Teilen besteht: Encoder, Prädiktor, Sampler, Decoder und Verlustfunktion.
Durch das innovative Design des Prädiktors erreicht Paraformer eine genaue Vorhersage der Anzahl der Zielwörter und der entsprechenden akustischen latenten Variablen.
Darüber hinaus führten die Forscher auch die Idee des Browsing Language Model (GLM) im Bereich der maschinellen Übersetzung ein, entwarfen einen auf GLM basierenden Sampler und verbesserten die Modellierung der kontextuellen Semantik durch das Modell.
Gleichzeitig nutzte Paraformer auch Zehntausende Trainingsstunden für extrem große Industriedatensätze, die umfangreiche Szenarien abdeckten, wodurch die Erkennungsgenauigkeit weiter verbessert wurde.
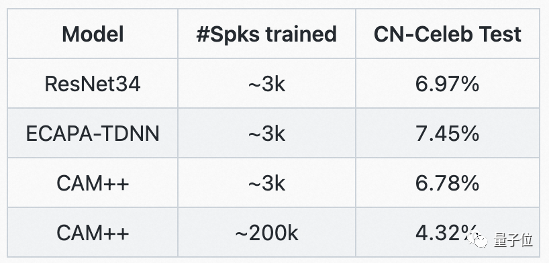
Die genaue Identifizierung von Sprechern in Diskussionen mit mehreren Personen profitiert vom CAM++-Grundmodell der Sprechererkennung der DAMO Academy. Dieses Modell verwendet ein Verzögerungsnetzwerk D-TDNN, das auf dichten Verbindungen basiert. Die Eingabe jeder Schicht wird aus der Ausgabe aller vorherigen Schichten gespleißt. Dieses hierarchische Merkmalsmultiplexen und die eindimensionale Faltung des Verzögerungsnetzwerks können die Recheneffizienz erheblich verbessern das Netzwerk.
Auf den gängigen chinesischen und englischen Testsets VoxCeleb und CN-Celeb der Branche hat CAM++ die beste Genauigkeitsrate aktualisiert.
Große Modellöffnung, Benutzer profitieren davon
Laut dem Bericht des China Institute of Scientific and Technological Information wurden unvollständigen Statistiken zufolge 79 große Modelle in China veröffentlicht.
Unter diesem Trend der groß angelegten Modellentwicklung ist die Geschwindigkeit der Entwicklung von KI-Anwendungen erneut in ein Sprintstadium eingetreten.
Aus Sicht der Anwender zeichnet sich allmählich eine erfreuliche Situation ab:
Unter der „Koordination“ großer Modelle beginnen auf der Anwendungsseite verschiedene KI-Technologien zu gedeihen, die Werkzeuge immer effizienter und intelligenter machen.
Von intelligenten Dokumenten, die Ihnen dabei helfen können, automatisch einen Arbeitsplan mit einem Schrägstrich zu schreiben, bis hin zu Audio- und Videoaufzeichnungs- und Analysetools, die Ihnen dabei helfen, Elemente schnell zusammenzufassen: Der Funke von AGI, generativen großen Modellen, lässt immer mehr Menschen spüren die Magie der KI.
Gleichzeitig haben sich für Technologieunternehmen zweifellos neue Herausforderungen und neue Chancen ergeben.
Die Herausforderung besteht darin, dass alle Produkte vom Sturm der großen Modelle erfasst werden und technologische Innovation zu einem unvermeidlichen Schlüsselthema geworden ist.
Die bestehende Marktstruktur hat den Moment erreicht, in dem sie für neue Killeranwendungen umgestaltet werden kann. Wer die Führung übernehmen kann, hängt davon ab, wer technisch besser vorbereitet ist und wessen Technologie sich schneller weiterentwickelt.
Egal was passiert, die technische Entwicklung wird letztendlich den Benutzern zugute kommen.
Das obige ist der detaillierte Inhalt vonDas neue große Modell von Alibaba Cloud ist erschienen! Das KI-Artefakt „Tongyi Listening' befindet sich in der öffentlichen Beta: Lange Videos können in einer Sekunde zusammengefasst werden, außerdem können automatisch Notizen gemacht und Untertitel erstellt werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr