
So ermitteln Sie, ob Redis Leistungsprobleme hat, und wie lösen Sie diese

- PHPznach vorne
- 2023-06-03 17:16:21888Durchsuche

Redis ist normalerweise eine wichtige Komponente in unserem Geschäftssystem, z. B. Cache, Kontoanmeldeinformationen, Rankings usw.
Sobald die Verzögerung der Redis-Anfrage zunimmt, kann es zu einer „Lawine“ des Geschäftssystems kommen.
Ich arbeite für ein Internetunternehmen vom Typ Single-Matchmaker. Während Double Eleven habe ich eine Kampagne gestartet, um meiner Freundin ein Geschenk zu machen, wenn ich eine Bestellung aufgegeben habe.
Wer hätte gedacht, dass nach 12 Uhr morgens die Zahl der Nutzer stark anstieg und es eine technische Panne gab, die Nutzer daran hinderte, Bestellungen aufzugeben. Damals brach der alte Brand aus!
Nach der Suche habe ich festgestellt, dass Redis gemeldet hat, dass Ressource nicht aus dem Pool abgerufen werden konnte. Could not get a resource from the pool。
获取不到连接资源,并且集群中的单台 Redis 连接量很高。
大量的流量没了 Redis 的缓存响应,直接打到了 MySQL,最后数据库也宕机了……
于是各种更改最大连接数、连接等待数,虽然报错信息频率有所缓解,但还是持续报错。
后来经过线下测试,发现存放 Redis 中的字符数据很大,平均 1s 返回数据。
可以发现,一旦 Redis 延迟过高,会引发各种问题。
今天跟大家一起来分析下如何确定 Redis 有性能问题和解决方案。
Redis 性能出问题了么?
最大延迟是客户端发出命令到客户端收到命令的响应的时间,正常情况下 Redis 处理的时间极短,在微秒级别。
当 Redis 出现性能波动的时候,比如达到几秒到十几秒,这个很明显我们可以认定 Redis 性能变慢了。
有的硬件配置比较高,当延迟 0.6ms,我们可能就认定变慢了。硬件比较差的可能 3 ms 我们才认为出现问题。
那我们该如何定义 Redis 真的变慢了呢?
所以,我们需要对当前环境的 Redis 基线性能做测量,也就是在一个系统在低压力、无干扰情况下的基本性能。
当你发现 Redis 运行时时的延迟是基线性能的 2 倍以上,就可以判定 Redis 性能变慢了。
延迟基线测量
redis-cli 命令提供了–intrinsic-latency 选项,用来监测和统计测试期间内的最大延迟(以毫秒为单位),这个延迟可以作为 Redis 的基线性能。
redis-cli --latency -h `host` -p `port`
比如执行如下指令:
redis-cli --intrinsic-latency 100 Max latency so far: 4 microseconds. Max latency so far: 18 microseconds. Max latency so far: 41 microseconds. Max latency so far: 57 microseconds. Max latency so far: 78 microseconds. Max latency so far: 170 microseconds. Max latency so far: 342 microseconds. Max latency so far: 3079 microseconds. 45026981 total runs (avg latency: 2.2209 microseconds / 2220.89 nanoseconds per run). Worst run took 1386x longer than the average latency.
注意:参数100是测试将执行的秒数。我们运行测试的时间越长,我们就越有可能发现延迟峰值。
通常运行 100 秒通常是合适的,足以发现延迟问题了,当然我们可以选择不同时间运行几次,避免误差。
运行的最大延迟是 3079 微秒,所以基线性能是 3079 (3 毫秒)微秒。
需要注意的是,我们要在 Redis 的服务端运行,而不是客户端。这样,可以避免网络对基线性能的影响。
可以通过 -h host -p port
Es kann festgestellt werden, dass eine zu hohe Redis-Verzögerung verschiedene Probleme verursacht. Lassen Sie uns heute analysieren, wie Sie feststellen können, ob Redis Leistungsprobleme und Lösungen aufweist. Gibt es ein Problem mit der Redis-Leistung?Später, nach Offline-Tests, stellten wir fest, dass die in Redis gespeicherten Zeichendaten sehr groß sind und die Rückgabe der Daten durchschnittlich 1 Sekunde dauert.
Wenn die Leistung von Redis schwankt, beispielsweise einige Sekunden bis mehr als zehn Sekunden erreicht, können wir offensichtlich daraus schließen, dass sich die Leistung von Redis verlangsamt hat. Einige Hardwarekonfigurationen sind relativ hoch. Wenn die Verzögerung 0,6 ms beträgt, können wir sie als langsam betrachten. Wenn die Hardware schlecht ist, kann es 3 ms dauern, bis wir denken, dass ein Problem vorliegt.Die maximale Verzögerung ist die Zeit von der Ausgabe eines Befehls durch den Client bis zum Empfang der Antwort auf den Befehl. Unter normalen Umständen ist die Verarbeitungszeit von Redis im Mikrosekundenbereich extrem kurz.
Wie definieren wir also, ob Redis wirklich langsam ist?
- Wir müssen also die Redis-Basisleistung der aktuellen Umgebung messen, also die Grundleistung eines Systems unter geringem Druck und ohne Störungen. Wenn Sie feststellen, dass die Latenz der Redis-Laufzeit mehr als das Zweifache der Basisleistung beträgt, können Sie feststellen, dass die Leistung von Redis nachlässt.
Latenz-Basismessung
Der Befehl redis-cli bietet die Option –intrinsic-latency, um die maximale Latenz (in Millisekunden) während des Testzeitraums zu überwachen und zu zählen. Diese Latenz kann als Basisleistung von Redis verwendet werden.
redis-cli CONFIG SET slowlog-log-slower-than 6000Führen Sie beispielsweise den folgenden Befehl aus:
127.0.0.1:6381> SLOWLOG get 2
1) 1) (integer) 6
2) (integer) 1458734263
3) (integer) 74372
4) 1) "hgetall"
2) "max.dsp.blacklist"
2) 1) (integer) 5
2) (integer) 1458734258
3) (integer) 5411075
4) 1) "keys"
2) "max.dsp.blacklist"
Hinweis: Parameter 100 ist die Anzahl der Sekunden, die der Test ausgeführt wird. Je länger wir den Test durchführen, desto wahrscheinlicher ist es, dass wir Latenzspitzen feststellen.
Normalerweise ist eine Ausführung von 100 Sekunden ausreichend, um Latenzprobleme zu erkennen. Natürlich können wir uns auch dafür entscheiden, mehrere Ausführungen zu unterschiedlichen Zeiten durchzuführen, um Fehler zu vermeiden.
Die maximale Latenz beim Ausführen beträgt 3079 Mikrosekunden, sodass die Basisleistung 3079 (3 Millisekunden) Mikrosekunden beträgt. Es ist zu beachten, dass wir auf dem Redis-Server und nicht auf dem Client ausgeführt werden müssen. Auf diese Weise können Auswirkungen des Netzwerks auf die Grundleistung vermieden werden. 🎜🎜Sie können über -h host -p port eine Verbindung zum Server herstellen. Wenn Sie die Auswirkungen des Netzwerks auf die Redis-Leistung überwachen möchten, können Sie Iperf verwenden, um die Netzwerkverzögerung vom Client zum zu messen Der Server. 🎜🎜Wenn die Netzwerkverzögerung mehrere hundert Millisekunden erreicht, kann dies darauf hinweisen, dass andere Programme mit hohem Datenverkehr ausgeführt werden, was zu einer Überlastung des Netzwerks führt. Sie müssen sich an das Betriebs- und Wartungspersonal wenden, um die Verteilung des Netzwerkverkehrs zu koordinieren. 🎜🎜Überwachung langsamer Befehle🎜🎜🎜Wie kann man beurteilen, ob es sich um einen langsamen Befehl handelt? 🎜🎜🎜Überprüfen Sie, ob die Operationskomplexität O(N) ist. Die offizielle Dokumentation stellt die Komplexität jedes Befehls vor. Verwenden Sie so oft wie möglich die Befehle O(1) und O(log N). 🎜🎜Die Komplexität von Mengenoperationen beträgt im Allgemeinen O(N), wie z. B. vollständige Mengenabfragen HGETALL, SMEMBERS und Mengenaggregationsoperationen: SORT, LREM, SUNION usw. 🎜🎜🎜Gibt es Überwachungsdaten, die beobachtet werden können? Ich habe den Code nicht geschrieben. Ich weiß nicht, ob jemand langsame Anweisungen verwendet hat. 🎜🎜🎜Es gibt zwei Möglichkeiten zur Fehlerbehebung: 🎜🎜🎜🎜Verwenden Sie die Redis-Slow-Log-Funktion, um langsame Befehle zu erkennen; 🎜🎜🎜🎜latency-monitor (Latenzüberwachung). 🎜🎜🎜🎜Außerdem können Sie den CPU-Verbrauch des Redis-Hauptprozesses schnell selbst überprüfen (top, htop, prstat usw.). Wenn die CPU-Auslastung hoch ist, der Datenverkehr jedoch gering ist, deutet dies normalerweise darauf hin, dass langsame Befehle verwendet werden. 🎜🎜🎜Langsame Protokollfunktion🎜🎜🎜Mit dem Slowlog-Befehl in Redis können wir langsame Befehle schnell finden, die die angegebene Ausführungszeit überschreiten. Wenn die Ausführungszeit des Befehls standardmäßig 10 ms überschreitet, wird er im Protokoll aufgezeichnet. 🎜🎜slowlog zeichnet nur die Ausführungszeit des Befehls auf, ausgenommen E/A-Roundtrip-Vorgänge und langsame Antworten aufgrund von Netzwerkverzögerungen. 🎜🎜Wir können den Standard langsamer Befehle basierend auf der Basisleistung anpassen (konfiguriert auf das Zweifache der maximalen Verzögerung der Basisleistung) und den Schwellenwert anpassen, der die Aufzeichnung langsamer Befehle auslöst. 🎜🎜Sie können den folgenden Befehl in redis-cli eingeben, um den Befehl so zu konfigurieren, dass er länger als 6 Millisekunden aufzeichnet: 🎜CONFIG SET latency-monitor-threshold 9🎜Es kann auch in der Konfigurationsdatei Redis.config in Mikrosekunden festgelegt werden. 🎜
想要查看所有执行时间比较慢的命令,可以通过使用 Redis-cli 工具,输入 slowlog get 命令查看,返回结果的第三个字段以微秒位单位显示命令的执行时间。
假如只需要查看最后 2 个慢命令,输入 slowlog get 2 即可。
示例:获取最近2个慢查询命令
127.0.0.1:6381> SLOWLOG get 2
1) 1) (integer) 6
2) (integer) 1458734263
3) (integer) 74372
4) 1) "hgetall"
2) "max.dsp.blacklist"
2) 1) (integer) 5
2) (integer) 1458734258
3) (integer) 5411075
4) 1) "keys"
2) "max.dsp.blacklist"以第一个 HGET 命令为例分析,每个 slowlog 实体共 4 个字段:
字段 1:1 个整数,表示这个 slowlog 出现的序号,server 启动后递增,当前为 6。
字段 2:表示查询执行时的 Unix 时间戳。
字段 3:表示查询执行微秒数,当前是 74372 微秒,约 74ms。
字段4表示查询命令及其参数,如果参数数量较多或较大,则只显示部分参数。hgetall max.dsp.blacklist是当前正在执行的命令。
Latency Monitoring
Redis 在 2.8.13 版本引入了 Latency Monitoring 功能,用于以秒为粒度监控各种事件的发生频率。
启用延迟监视器的第一步是设置延迟阈值(单位毫秒)。只有超过该阈值的时间才会被记录,比如我们根据基线性能(3ms)的 3 倍设置阈值为 9 ms。
可以用 redis-cli 设置也可以在 Redis.config 中设置;
CONFIG SET latency-monitor-threshold 9
工具记录的相关事件的详情可查看官方文档:https://redis.io/topics/latency-monitor
如获取最近的 latency
127.0.0.1:6379> debug sleep 2 OK (2.00s) 127.0.0.1:6379> latency latest 1) 1) "command" 2) (integer) 1645330616 3) (integer) 2003 4) (integer) 2003
事件的名称;
事件发生的最新延迟的 Unix 时间戳;
毫秒为单位的时间延迟;
该事件的最大延迟。
如何解决 Redis 变慢?
Redis 的数据读写由单线程执行,如果主线程执行的操作时间太长,就会导致主线程阻塞。
一起分析下都有哪些操作会阻塞主线程,我们又该如何解决?
网络通信导致的延迟
客户端使用 TCP/IP 连接或 Unix 域连接连接到 Redis。1 Gbit/s 网络的典型延迟约为 200 us。
redis 客户端执行一条命令分 4 个过程:
发送命令-〉 命令排队 -〉 命令执行-〉 返回结果
这个过程称为 Round trip time(简称 RTT, 往返时间),mget mset 有效节约了 RTT,但大部分命令(如 hgetall,并没有 mhgetall)不支持批量操作,需要消耗 N 次 RTT ,这个时候需要 pipeline 来解决这个问题。
Redis pipeline 将多个命令连接在一起来减少网络响应往返次数。
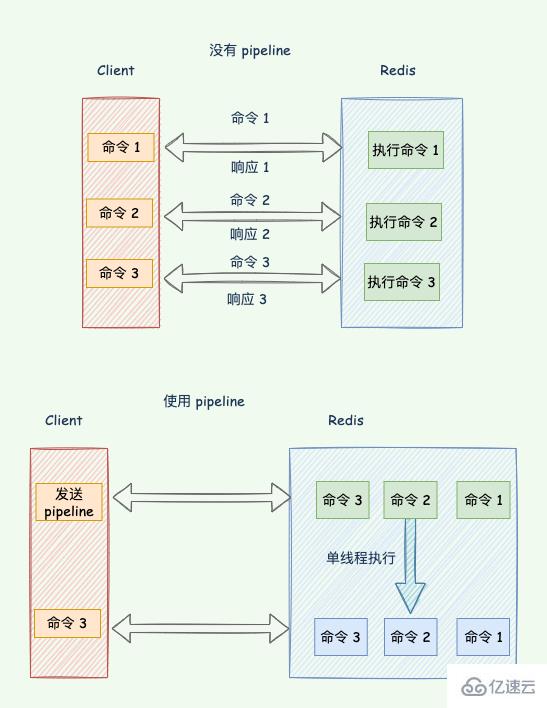
redis-pipeline
慢指令导致的延迟
根据上文的慢指令监控查询文档,查询到慢查询指令。可以通过以下两种方式解决:
在 Cluster 集群中,聚合运算等 O(N) 操作可以在 slave 节点上运行,也可以在客户端端完成。
使用高效的命令代替。采用增量迭代的方法查询数据,避免一次性查询大量数据,在此可参考SCAN、SSCAN、HSCAN和ZSCAN命令。
除此之外,生产中禁用KEYS 命令,它只适用于调试。因为它会遍历所有的键值对,所以操作延时高。
Fork 生成 RDB 导致的延迟
生成 RDB 快照,Redis 必须 fork 后台进程。fork 操作(在主线程中运行)本身会导致延迟。
Redis 使用操作系统的多进程写时复制技术 COW(Copy On Write) 来实现快照持久化,减少内存占用。

写时复制技术保证快照期间数据可修改
但 fork 会涉及到复制大量链接对象,一个 24 GB 的大型 Redis 实例需要 24 GB / 4 kB * 8 = 48 MB 的页表。
执行 bgsave 时,这将涉及分配和复制 48 MB 内存。
此外,从库加载 RDB 期间无法提供读写服务,所以主库的数据量大小控制在 2~4G 左右,让从库快速的加载完成。
内存大页(transparent huge pages)
常规的内存页是按照 4 KB 来分配,Linux 内核从 2.6.38 开始支持内存大页机制,该机制支持 2MB 大小的内存页分配。
Redis 使用了 fork 生成 RDB 做持久化提供了数据可靠性保证。
当生成 RDB 快照的过程中,Redis 采用**写时复制**技术使得主线程依然可以接收客户端的写请求。
也就是当数据被修改的时候,Redis 会复制一份这个数据,再进行修改。
采用了内存大页,生成 RDB 期间,即使客户端修改的数据只有 50B 的数据,Redis 需要复制 2MB 的大页。当写的指令比较多的时候就会导致大量的拷贝,导致性能变慢。
使用以下指令禁用 Linux 内存大页即可:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
swap:操作系统分页
当物理内存(内存条)不够用的时候,将部分内存上的数据交换到 swap 空间上,以便让系统不会因内存不够用而导致 oom 或者更致命的情况出现。
当某进程向 OS 请求内存发现不足时,OS 会把内存中暂时不用的数据交换出去,放在 SWAP 分区中,这个过程称为 SWAP OUT。
当某进程又需要这些数据且 OS 发现还有空闲物理内存时,又会把 SWAP 分区中的数据交换回物理内存中,这个过程称为 SWAP IN。
内存 swap 是操作系统里将内存数据在内存和磁盘间来回换入和换出的机制,涉及到磁盘的读写。
触发 swap 的情况有哪些呢?
对于 Redis 而言,有两种常见的情况:
Redis 使用了比可用内存更多的内存;
与 Redis 在同一机器运行的其他进程在执行大量的文件读写 I/O 操作(包括生成大文件的 RDB 文件和 AOF 后台线程),文件读写占用内存,导致 Redis 获得的内存减少,触发了 swap。
我要如何排查是否因为 swap 导致的性能变慢呢?
Linux 提供了很好的工具来排查这个问题,所以当怀疑由于交换导致的延迟时,只需按照以下步骤排查。
获取 Redis 实例 pid
$ redis-cli info | grep process_id process_id:13160
进入此进程的 /proc 文件系统目录:
cd /proc/13160
在这里有一个 smaps 的文件,该文件描述了 Redis 进程的内存布局,运行以下指令,用 grep 查找所有文件中的 Swap 字段。
$ cat smaps | egrep '^(Swap|Size)' Size: 316 kB Swap: 0 kB Size: 4 kB Swap: 0 kB Size: 8 kB Swap: 0 kB Size: 40 kB Swap: 0 kB Size: 132 kB Swap: 0 kB Size: 720896 kB Swap: 12 kB
每行 Size 表示 Redis 实例所用的一块内存大小,和 Size 下方的 Swap 对应这块 Size 大小的内存区域有多少数据已经被换出到磁盘上了。
如果 Size == Swap 则说明数据被完全换出了。
可以看到有一个 720896 kB 的内存大小有 12 kb 被换出到了磁盘上(仅交换了 12 kB),这就没什么问题。
Redis 本身会使用很多大小不一的内存块,所以,你可以看到有很多 Size 行,有的很小,就是 4KB,而有的很大,例如 720896KB。不同内存块被换出到磁盘上的大小也不一样。
敲重点了
如果 Swap 一切都是 0 kb,或者零星的 4k ,那么一切正常。
当出现百 MB,甚至 GB 级别的 swap 大小时,就表明,此时,Redis 实例的内存压力很大,很有可能会变慢。
解决方案
增加机器内存;
将 Redis 放在单独的机器上运行,避免在同一机器上运行需要大量内存的进程,从而满足 Redis 的内存需求;
增加 Cluster 集群的数量分担数据量,减少每个实例所需的内存。
AOF 和磁盘 I/O 导致的延迟
为了保证数据可靠性,Redis 使用 AOF 和 RDB 快照实现快速恢复和持久化。
可以使用 appendfsync 配置将 AOF 配置为以三种不同的方式在磁盘上执行 write 或者 fsync (可以在运行时使用 CONFIG SET命令修改此设置,比如:redis-cli CONFIG SET appendfsync no)。
no:Redis 不执行 fsync,唯一的延迟来自于 write 调用,write 只需要把日志记录写到内核缓冲区就可以返回。
everysec:Redis 每秒执行一次 fsync。使用后台子线程异步完成 fsync 操作。最多丢失 1s 的数据。
always:每次写入操作都会执行 fsync,然后用 OK 代码回复客户端(实际上 Redis 会尝试将同时执行的许多命令聚集到单个 fsync 中),没有数据丢失。建议使用能够快速执行 fsync 并搭配快速的磁盘的文件系统实现,因为在这种模式下性能通常非常低。
我们通常将 Redis 用于缓存,数据丢失完全恶意从数据获取,并不需要很高的数据可靠性,建议设置成 no 或者 everysec。
除此之外,避免 AOF 文件过大, Redis 会进行 AOF 重写,生成缩小的 AOF 文件。
可以把配置项 no-appendfsync-on-rewrite设置为 yes,表示在 AOF 重写时,不进行 fsync 操作。
也就是说,Redis 实例把写命令写到内存后,不调用后台线程进行 fsync 操作,就直接返回了。
expires 淘汰过期数据
Redis 有两种方式淘汰过期数据:
惰性删除:当接收请求的时候发现 key 已经过期,才执行删除;
定时删除:每 100 毫秒删除一些过期的 key。
定时删除的算法如下:
随机采样 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP个数的 key,删除所有过期的 key;
如果发现还有超过 25% 的 key 已过期,则执行步骤一。
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP默认设置为 20,每秒执行 10 次,删除 200 个 key 问题不大。
Wenn das zweite Element ausgelöst wird, führt dies dazu, dass Redis abgelaufene Daten regelmäßig löscht, um Speicher freizugeben. Und das Löschen blockiert.
Was sind die auslösenden Bedingungen?
Das heißt, eine große Anzahl von Tasten stellt die gleichen Zeitparameter ein. Um die Anzahl abgelaufener Schlüssel auf weniger als 25 % zu reduzieren, sind mehrere Deduplizierungen erforderlich. Diese Schlüssel verfallen in großer Zahl innerhalb derselben Sekunde.
Kurz gesagt: Eine große Anzahl gleichzeitig ablaufender Schlüssel kann zu Leistungsschwankungen führen.
Lösung
Wenn ein Schlüsselstapel gleichzeitig abläuft, können Sie den Ablaufzeitparametern von EXPIREAT und EXPIRE eine Zufallszahl innerhalb eines bestimmten Größenbereichs hinzufügen, um sicherzustellen, dass sich die Schlüssel in einer bestimmten Reihenfolge befinden Der nahegelegene Zeitbereich wird innerhalb der Datei gelöscht und gleichzeitig wird der durch den Ablauf verursachte Druck vermieden.
bigkey
Normalerweise bezeichnen wir Schlüssel, die große Datenmengen oder eine große Anzahl von Mitgliedern oder Listen enthalten, als große Schlüssel. Im Folgenden werden einige praktische Beispiele verwendet, um die Eigenschaften großer Schlüssel zu beschreiben:
-
Ein Schlüssel vom Typ STRING , sein Wert beträgt 5 MB (die Daten sind zu groß)
Ein Schlüssel vom Typ LIST, die Anzahl der Listen beträgt 10.000 (die Anzahl der Listen ist zu groß)
Ein Schlüssel vom Typ ZSET, der 10.000 Mitglieder hat (zu viele Mitglieder)
Ein Schlüssel im HASH-Format Obwohl er nur 1.000 Mitglieder hat, beträgt die Gesamtwertgröße dieser Mitglieder 10 MB (die Mitgliedsgröße ist zu groß)
Die durch Bigkey verursachten Probleme sind wie folgt:
Der Redis-Speicher wächst weiter, was zu OOM führt oder den maxmemory-Einstellungswert erreicht, was zu Schreibblockaden oder der Entfernung wichtiger Schlüssel führt;
-
Der Speicher eines bestimmten Knotens im Redis-Cluster übersteigt den der anderen Knoten bei weitem Da die minimale Granularität der Datenmigration im Redis-Cluster jedoch der Schlüssel ist, kann der Speicher auf dem Knoten nicht ausgeglichen werden. Die Leseanforderung von bigkey beansprucht zu viel Bandbreite, verlangsamt sich selbst und beeinträchtigt andere Dienste auf dem Server
- Das Löschen eines Bigkeys führt dazu, dass die Hauptbibliothek für eine lange Zeit blockiert wird und eine Synchronisierungsunterbrechung oder ein Master-Slave-Wechsel auftritt.
Finden Sie den Bigkey.
Lösung
Große Schlüssel aufteilenTeilen Sie beispielsweise einen HASH-Schlüssel mit Zehntausenden von Mitgliedern in mehrere HASH-Schlüssel auf und stellen Sie sicher, dass die Anzahl der Mitglieder jedes Schlüssels im Redis-Cluster in einem angemessenen Bereich liegt Struktur kann die Aufteilung großer Schlüssel eine wichtige Rolle bei der Speicherbalance zwischen Knoten spielen.
Asynchrone Reinigung großer SchlüsselRedis stellt seit 4.0 den UNLINK-Befehl zur Verfügung, der eingehende Schlüssel langsam und schrittweise auf nicht blockierende Weise bereinigen kann. Mit UNLINK können Sie große Schlüssel oder sogar besonders große Schlüssel sicher löschen.Das obige ist der detaillierte Inhalt vonSo ermitteln Sie, ob Redis Leistungsprobleme hat, und wie lösen Sie diese. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!