
Heim >Technologie-Peripheriegeräte >KI >GPT-4 verfügt über großartige mathematische Fähigkeiten! Die explosive Forschung von OpenAI zum Thema „Prozessüberwachung' durchbricht 78,2 % der Probleme und beseitigt Halluzinationen
GPT-4 verfügt über großartige mathematische Fähigkeiten! Die explosive Forschung von OpenAI zum Thema „Prozessüberwachung' durchbricht 78,2 % der Probleme und beseitigt Halluzinationen

- 王林nach vorne
- 2023-06-03 12:25:131315Durchsuche
ChatGPT steht seit seiner Veröffentlichung wegen seiner mathematischen Fähigkeiten in der Kritik.
Sogar das „mathematische Genie“ Terence Tao sagte einmal, dass GPT-4 in seinem Fachgebiet Mathematik keinen großen Mehrwert bringe.
Was soll ich tun, ChatGPT einfach zu einem „Mathematikbehinderten“ werden lassen?
OpenAI arbeitet hart – Um die mathematischen Denkfähigkeiten von GPT-4 zu verbessern, nutzt das OpenAI-Team „Process Supervision“ (PRM), um das Modell zu trainieren.
Lassen Sie uns Schritt für Schritt überprüfen!

Papieradresse: https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step.pdf
In dem Papier trainierten die Forscher das Modell, indem sie jeden einzelnen belohnten richtige Antwort Die Argumentationsschritte, also die „Prozessüberwachung“, erreichen nicht nur die Belohnung des richtigen Endergebnisses (Ergebnisüberwachung), sondern erreichen den neuesten SOTA in der mathematischen Problemlösung.
Konkret löst PRM 78,2 % der Probleme in einer repräsentativen Teilmenge des MATH-Testsatzes.

Darüber hinaus stellte OpenAI fest, dass die „Prozessüberwachung“ von großem Wert bei der Ausrichtung ist – dem Training des Modells, um eine von Menschen erkannte Gedankenkette zu erzeugen.
Die neuesten Forschungsergebnisse sind für die Weiterleitung natürlich unverzichtbar von Sam Altman: „Unser Mathgen-Team hat sehr spannende Ergebnisse in der Prozessüberwachung erzielt, was ein positives Zeichen der Ausrichtung ist.“ „ist für große Modelle und verschiedene Aufgaben äußerst kostspielig, da manuelles Feedback erforderlich ist. Daher ist diese Arbeit von großer Bedeutung und kann als bestimmend für die zukünftige Forschungsrichtung von OpenAI bezeichnet werden.
Mathematische Probleme lösen
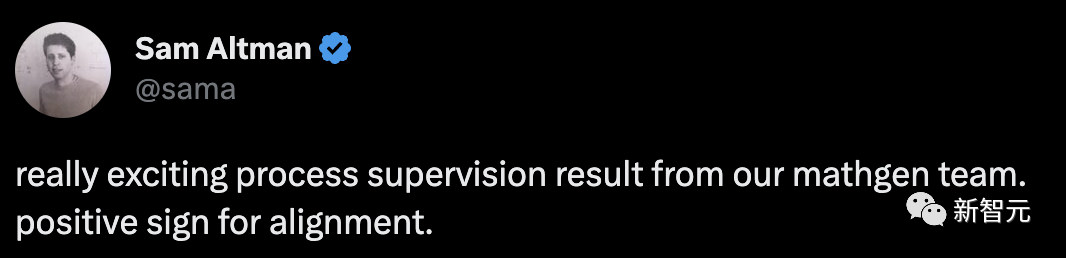 In dem Experiment verwendeten die Forscher Probleme im MATH-Datensatz, um die Belohnungsmodelle „Prozessüberwachung“ und „Ergebnisüberwachung“ zu bewerten.
In dem Experiment verwendeten die Forscher Probleme im MATH-Datensatz, um die Belohnungsmodelle „Prozessüberwachung“ und „Ergebnisüberwachung“ zu bewerten.
Die Grafik zeigt den Prozentsatz der ausgewählten Lösungen, die zu einer richtigen Endantwort führten, als Funktion der Anzahl der berücksichtigten Lösungen.
Das Belohnungsmodell „Prozessüberwachung“ schneidet nicht nur insgesamt besser ab, sondern die Leistungslücke vergrößert sich auch, je mehr Lösungen für jedes Problem in Betracht gezogen werden.
 Dies zeigt, dass das Belohnungsmodell „Prozessüberwachung“ zuverlässiger ist.
Dies zeigt, dass das Belohnungsmodell „Prozessüberwachung“ zuverlässiger ist.
Unten zeigt OpenAI 10 mathematische Probleme und Lösungen für das Modell, sowie Kommentare zu den Vor- und Nachteilen des Belohnungsmodells.
Das Modell wurde anhand der folgenden drei Arten von Indikatoren bewertet: wahr (TP), wahr negativ (TN) und falsch positiv (FP).
True (TP)
Vereinfachen wir zunächst die trigonometrische Funktionsformel.
 Dieses anspruchsvolle trigonometrische Funktionsproblem erfordert die Anwendung mehrerer Identitäten in einer nicht offensichtlichen Reihenfolge.
Dieses anspruchsvolle trigonometrische Funktionsproblem erfordert die Anwendung mehrerer Identitäten in einer nicht offensichtlichen Reihenfolge.

Hier führt GPT-4 erfolgreich eine Reihe komplexer Polynomfaktorisierungen durch.
Die Verwendung der Sophie-Germain-Identität in Schritt 5 ist ein wichtiger Schritt. Es ist ersichtlich, dass dieser Schritt sehr aufschlussreich ist.

In den Schritten 7 und 8 beginnt GPT-4 mit der Durchführung von Vermutungen und Prüfungen.
Dies ist ein häufiger Ort, an dem das Modell „halluzinieren“ und behaupten kann, dass eine bestimmte Vermutung erfolgreich war. In diesem Fall validiert das Belohnungsmodell jeden Schritt und stellt fest, dass die Gedankenkette korrekt ist. Das Modell wendet erfolgreich mehrere trigonometrische Identitäten an, um den Ausdruck zu vereinfachen.

True Negative (TN)
In Schritt 7 versucht GPT-4 An Der Versuch, einen Ausdruck zu vereinfachen, ist fehlgeschlagen. Das Belohnungsmodell hat diesen Fehler entdeckt.

In Schritt 11 hat GPT-4 einen einfachen Berechnungsfehler gemacht. Auch vom Belohnungsmodell entdeckt.

GPT-4 hat in Schritt 12 versucht, die quadrierte Differenzformel zu verwenden, aber dieser Ausdruck ist eigentlich nicht das Quadrat Unterschied . Der Grund für Schritt 8 ist seltsam, aber das Bonusmodell schafft es. In Schritt 9 faktorisiert das Modell den Ausdruck jedoch falsch.
Das Belohnungsmodell korrigiert diesen Fehler.

False Positive (FP)
 In Schritt 4 trat ein GPT-4-Fehler auf Es wird behauptet, dass „die Sequenz alle 12 Elemente wiederholt wird“, aber tatsächlich wiederholt sie sich alle 10 Elemente. Dieser Zählfehler täuscht gelegentlich das Belohnungsmodell.
In Schritt 4 trat ein GPT-4-Fehler auf Es wird behauptet, dass „die Sequenz alle 12 Elemente wiederholt wird“, aber tatsächlich wiederholt sie sich alle 10 Elemente. Dieser Zählfehler täuscht gelegentlich das Belohnungsmodell.
In Schritt 13 versucht GPT-4, die Gleichung durch Zusammenführen ähnlicher Begriffe zu vereinfachen. Die linearen Terme werden korrekt nach links verschoben und kombiniert, die rechte Seite bleibt jedoch fälschlicherweise unverändert. Das Belohnungsmodell wird durch diesen Fehler getäuscht.

GPT-4 versucht eine lange Division, vergisst jedoch in Schritt 16, den sich wiederholenden Teil von einzubeziehen die Dezimalzahl Die führende Null. Das Belohnungsmodell wird durch diesen Fehler getäuscht. GPT-4 hat in Schritt 9 einen subtilen Zählfehler gemacht.
Oberflächlich betrachtet erscheint die Behauptung, dass es 5 Möglichkeiten gibt, Bälle derselben Farbe auszutauschen (da es 5 Farben gibt), vernünftig.
Allerdings wird diese Zahl um den Faktor 2 unterschätzt, da Bob zwei Möglichkeiten hat, nämlich zu entscheiden, welchen Ball er Alice geben möchte. Das Belohnungsmodell wird durch diesen Fehler getäuscht.

Prozessüberwachung
Obwohl sich große Sprachmodelle in Bezug auf komplexe Argumentationsfähigkeiten stark verbessert haben, erzeugen selbst die fortschrittlichsten Modelle immer noch logische Fehler oder Unsinn, wie die Leute oft „Halluzination“ sagen.
Im Hype um generative künstliche Intelligenz hat die Illusion großer Sprachmodelle den Menschen schon immer Sorgen bereitet.
Musk sagte, was wir brauchen, ist TruthGPT.
OpenAI-Forscher erwähnten im Bericht: „Diese Illusionen sind besonders problematisch in Bereichen, die mehrstufiges Denken erfordern, da ein einfacher Logikfehler der gesamten Lösung großen Schaden zufügen kann.“
Darüber hinaus ist die Linderung von Halluzinationen auch der Schlüssel zum Aufbau konsistente AGI.
Wie kann man die Illusion großer Modelle reduzieren? Im Allgemeinen gibt es zwei Methoden: Prozessüberwachung und Ergebnisüberwachung.
„Ergebnisüberwachung“ besteht, wie der Name schon sagt, darin, dem großen Modell basierend auf den Endergebnissen Feedback zu geben, während „Prozessüberwachung“ Feedback für jeden Schritt in der Denkkette geben kann.

OpenAI-Forscher sagten, dass die Prozessüberwachung zwar nicht von OpenAI erfunden wurde, OpenAI jedoch hart daran arbeitet, sie voranzutreiben.
In der neuesten Forschung hat OpenAI sowohl Methoden der „Ergebnisüberwachung“ als auch der „Prozessüberwachung“ ausprobiert. Und unter Verwendung des MATH-Datensatzes als Testplattform wird ein detaillierter Vergleich der beiden Methoden durchgeführt.
Die Ergebnisse zeigten, dass „Prozessüberwachung“ die Modellleistung deutlich verbessern kann.
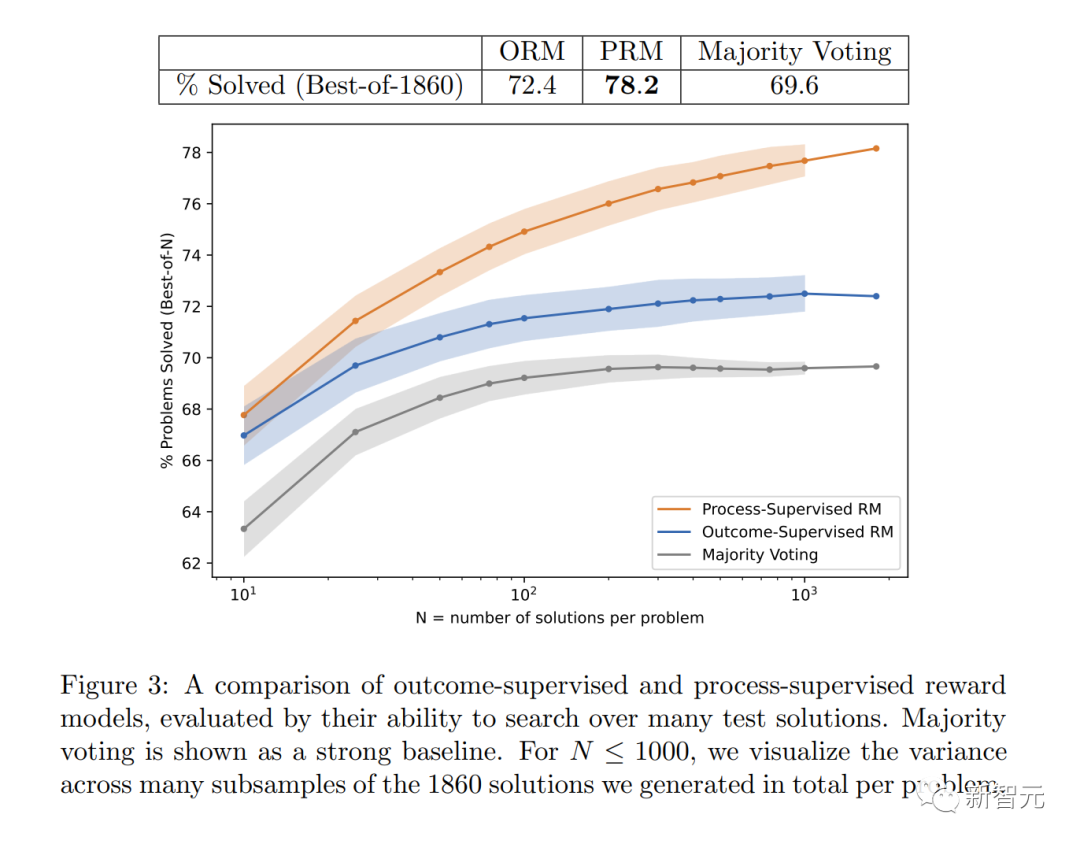
Auf diese Weise können Illusionen oder logische Fehler reduziert werden, die selbst bei den leistungsstärksten Modellen schwer zu vermeiden sind.
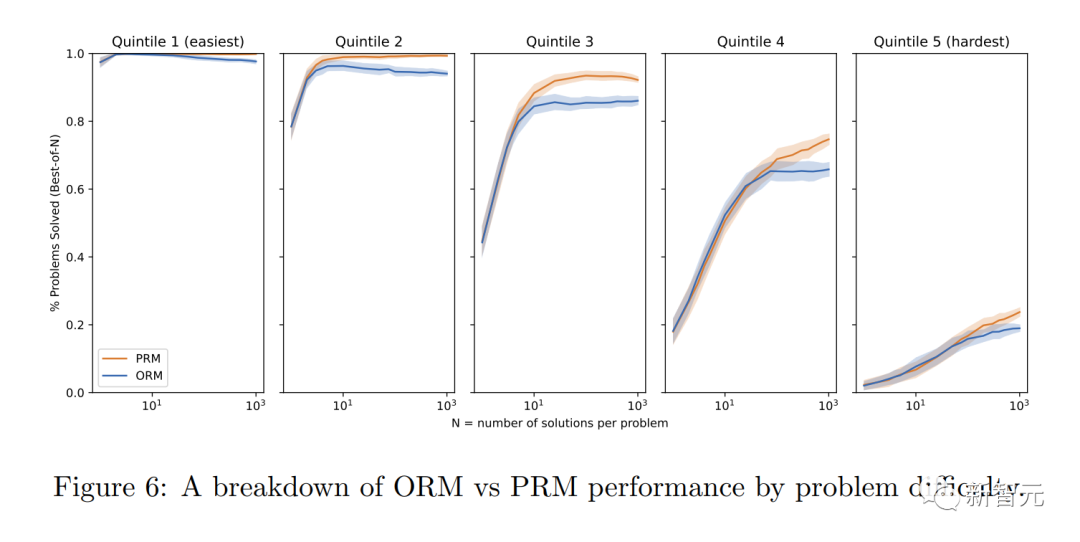
Forscher haben herausgefunden, dass „Prozessüberwachung“ mehrere Ausrichtungsvorteile gegenüber „Ergebnisüberwachung“ hat:
· Direkte Belohnungen folgen einem konsistenten Denkkettenmodell, da jeder Schritt im Prozess erfolgt Alle unterliegen einer genauen Aufsicht.
· Es ist wahrscheinlicher, dass interpretierbare Argumente entstehen, da die „Prozessüberwachung“ Modelle dazu ermutigt, von Menschen genehmigten Prozessen zu folgen. Im Gegensatz dazu kann die Ergebnisüberwachung einen inkonsistenten Prozess belohnen und ist oft schwieriger zu überprüfen.
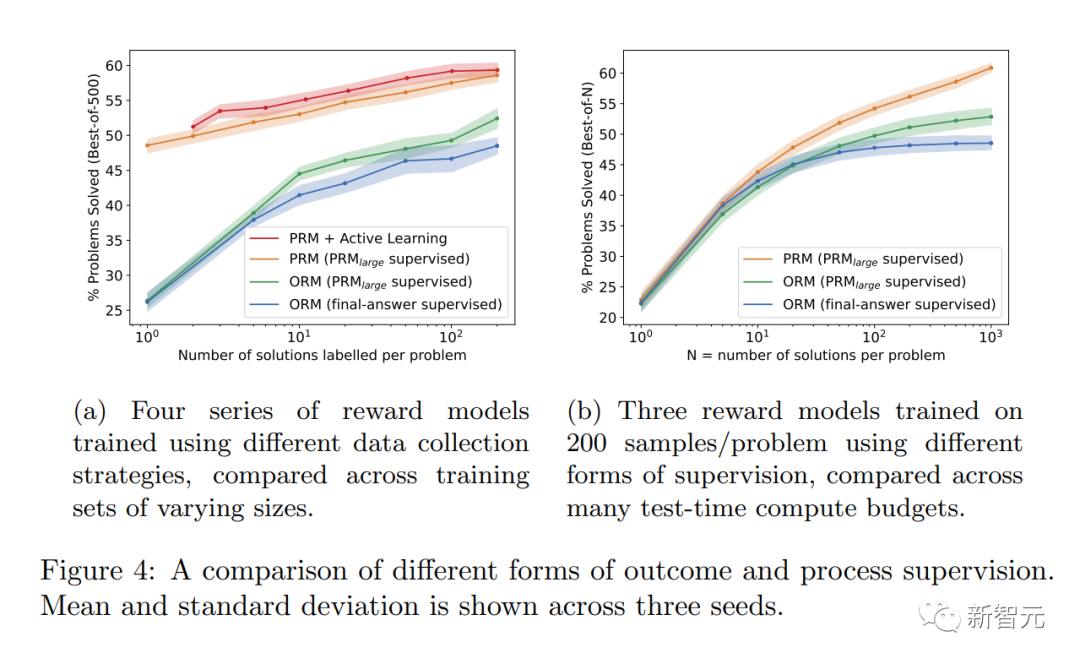
Im Allgemeinen können etwaige „Alignment-Steuer“-Kosten die Einführung von Alignment-Methoden behindern, um die leistungsfähigsten Modelle einzusetzen.
Die folgenden Ergebnisse von Forschern zeigen jedoch, dass „Prozessüberwachung“ bei Tests im Mathematikbereich tatsächlich eine „negative Ausrichtungssteuer“ erzeugt.
Man kann sagen, dass durch die Ausrichtung kein großer Leistungsverlust entsteht.
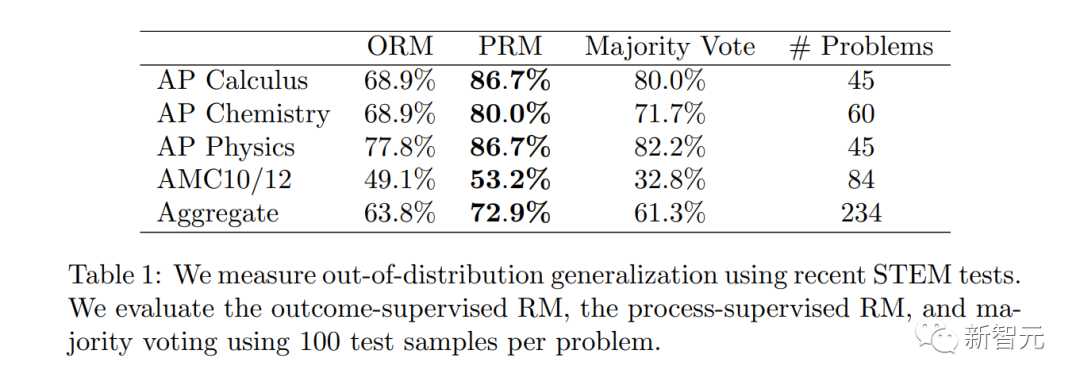
OpenAI veröffentlicht 800.000 von Menschen kommentierte Datensätze
Es ist erwähnenswert, dass PRM mehr menschliche Anmerkungen erfordert und immer noch zutiefst untrennbar mit RLHF verbunden ist.
Wie anwendbar ist die Prozessüberwachung in anderen Bereichen als der Mathematik? Dieser Prozess erfordert weitere Untersuchungen.
OpenAI-Forscher haben diesen PRM-Datensatz für menschliches Feedback geöffnet, der 800.000 korrekte Anmerkungen auf Schrittebene enthält: 75.000 Lösungen, die aus 12.000 mathematischen Problemen generiert wurden

Das Folgende ist ein Beispiel für eine Anmerkung. OpenAI veröffentlicht die Rohanmerkungen zusammen mit Anweisungen für Annotatoren während der Phasen 1 und 2 des Projekts.
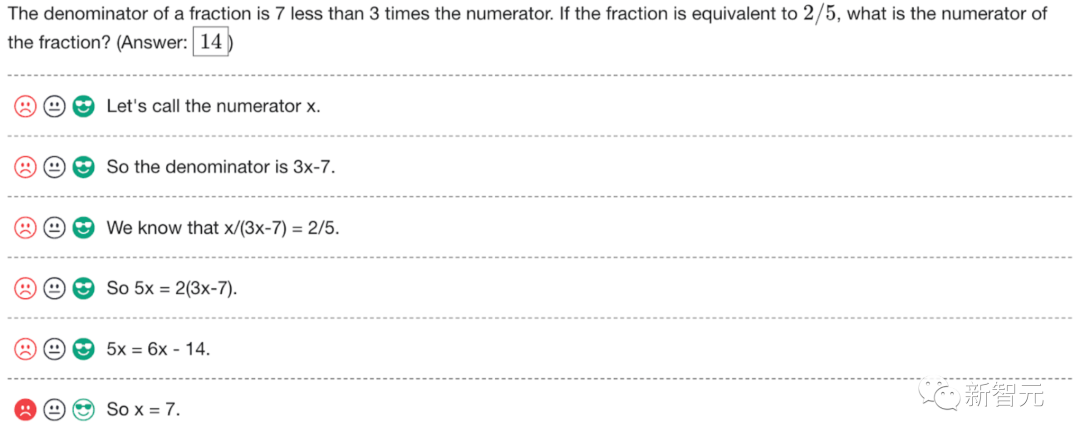
Heiße Kommentare von Internetnutzern
NVIDIA-Wissenschaftler Jim Fan hat eine Zusammenfassung der neuesten Forschungsergebnisse von OpenAI erstellt:
Geben Sie bei herausfordernden Schritt-für-Schritt-Aufgaben bei jedem Schritt Belohnungen, anstatt jeweils nur eine einzige Antwort zu geben Abschlusspreis. Grundsätzlich gilt: dichtes Belohnungssignal > spärliches Belohnungssignal. Das Process Reward Model (PRM) kann Lösungen für schwierige MATH-Benchmarks besser auswählen als das Outcome Reward Model (ORM). Der offensichtliche nächste Schritt besteht darin, GPT-4 mit PRM zu verfeinern, was in diesem Artikel noch nicht geschehen ist. Es ist zu beachten, dass PRM mehr menschliche Anmerkungen erfordert. OpenAI hat einen Datensatz mit menschlichem Feedback veröffentlicht: 800.000 Anmerkungen auf Schrittebene zu 75.000 Lösungen für 12.000 mathematische Probleme.

Das ist wie ein altes Sprichwort in der Schule: Lernen Sie zu denken.

Dem Modell beizubringen, zu denken und nicht nur die richtige Antwort auszugeben, wird die Lösung komplexer Probleme entscheidend verändern.

ChatGPT ist in Mathe superschwach. Heute habe ich versucht, eine Matheaufgabe aus einem Mathebuch der 4. Klasse zu lösen. ChatGPT hat die falsche Antwort gegeben. Ich habe meine Antworten mit Antworten von ChatGPT, Antworten von Perplexity AI, Google und meinem Lehrer der vierten Klasse überprüft. Es kann überall bestätigt werden, dass die Antwort von chatgpt falsch ist.

Referenz: https://www.php.cn/link/daf642455364613e2120c636b5a1f9c7
Das obige ist der detaillierte Inhalt vonGPT-4 verfügt über großartige mathematische Fähigkeiten! Die explosive Forschung von OpenAI zum Thema „Prozessüberwachung' durchbricht 78,2 % der Probleme und beseitigt Halluzinationen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr