
So implementieren Sie Redis-Daten-Sharding

- 王林nach vorne
- 2023-06-03 09:05:251577Durchsuche
Einführung in Twemproxy
Twemproxy von Twitter ist derzeit der am weitesten verbreitete Redis-Cluster-Dienst auf dem Markt. Da Redis Single-Threaded ist, ist der offizielle Cluster nicht sehr stabil und weit verbreitet. Twemproxy ist ein Proxy-Sharding-Mechanismus. Als Proxy kann Twemproxy den Zugriff mehrerer Programme akzeptieren, ihn gemäß Routing-Regeln an verschiedene Redis-Server weiterleiten und dann zur ursprünglichen Route zurückkehren. Diese Lösung löst das Problem der Tragfähigkeit einer einzelnen Redis-Instanz gut. Natürlich ist Twemproxy selbst auch ein einzelner Punkt und muss Keepalived als Hochverfügbarkeitslösung (oder LVS) verwenden. Durch Twemproxy können mehrere Server zur horizontalen Erweiterung des Redis-Dienstes verwendet werden, wodurch einzelne Fehlerpunkte effektiv vermieden werden können. Obwohl die Verwendung von Twemproxy mehr Hardwareressourcen erfordert und einen gewissen Verlust an Redis-Leistung mit sich bringt (etwa 20 % im Twitter-Test), ist es recht kostengünstig, die HA des gesamten Systems zu verbessern. Tatsächlich implementiert Twemproxy nicht nur das Redis-Protokoll, sondern auch das Memcached-Protokoll. Mit anderen Worten: Twemproxy kann nicht nur Redis, sondern auch Memcached als Proxy verwenden.
Die Vorteile von Twemproxy:
1) Durch die Offenlegung eines Zugangsknotens gegenüber der Außenwelt wird die Programmkomplexität verringert.
2) Unterstützt das automatische Löschen ausgefallener Knoten. Sie können die Zeit zum erneuten Verbinden des Knotens festlegen und den Knoten löschen, nachdem Sie die Anzahl der Verbindungen festgelegt haben. Andernfalls wird der Schlüssel gelöscht verloren; #🎜🎜 #
3) Unterstützt das Festlegen von HashTag Über HashTag können Sie zwei KEYhash auf dieselbe Instanz festlegen. 4) Mehrere Hash-Algorithmen und die Gewichtung der Backend-Instanz können festgelegt werden. 5) Reduzieren Sie die Anzahl direkter Verbindungen zu Redis: Halten Sie eine lange Verbindung mit Redis aufrecht, legen Sie die Anzahl jeder Redis-Verbindung zwischen dem Agenten und dem Backend fest und teilen Sie sie automatisch auf mehrere Redis-Instanzen auf Backend. 6) Vermeiden Sie Einzelpunktprobleme: Mehrere Proxy-Schichten können parallel bereitgestellt werden, und der Client wählt automatisch die verfügbare aus. 7) Hoher Durchsatz: Wiederverwendung von Verbindungen, Wiederverwendung von Speicher, mehrere Verbindungsanforderungen, bestehend aus Redis-Pipelining und einheitlichen Anforderungen an Redis. #?? 2) Redis-Transaktionsvorgänge werden nicht unterstützt. 3) Der verwendete Speicher wird nicht freigegeben. Alle Maschinen müssen über großen Speicher verfügen und müssen regelmäßig neu gestartet werden, da es sonst zu Client-Verbindungsfehlern kommt. 4) Das dynamische Hinzufügen und Löschen von Knoten wird nicht unterstützt und nach dem Ändern der Konfiguration ist ein Neustart erforderlich. 5) Beim Knotenwechsel ordnet das System vorhandene Daten nicht neu zu. Wenn Sie kein eigenes Skript für die Datenmigration schreiben, gehen einige Schlüssel verloren (der Schlüssel selbst ist auf einem bestimmten Redis vorhanden, aber der Schlüssel wurde gehackt) Hope erreicht andere Knoten und verursacht „Verlust“). 6) Das Gewicht wirkt sich direkt auf das Hash-Ergebnis des Schlüssels aus. Eine Änderung des Knotengewichts führt zum Verlust einiger Schlüssel. 7) Standardmäßig läuft Twemproxy in einem einzelnen Thread, aber die meisten Unternehmen, die Twemproxy verwenden, führen die Sekundärentwicklung selbst durch und stellen sie auf Multithreading um. Insgesamt ist Twemproxy immer noch sehr zuverlässig, obwohl es Leistungseinbußen gibt, ist es immer noch relativ lohnenswert. Es ist seit langem getestet und weit verbreitet. Ausführlichere Informationen finden Sie in der offiziellen Dokumentation. Darüber hinaus eignet sich Twemproxy nur für statische Cluster und nicht für Szenarien, die das dynamische Hinzufügen und Löschen von Knoten sowie die manuelle Lastanpassung erfordern. Wenn wir es direkt verwenden, müssen wir Entwicklungs- und Verbesserungsarbeiten durchführen. https://github.com/wandoulabs/codis Dieses System basiert auf Twemproxy und fügt Funktionen wie dynamische Datenmigration hinzu. Die spezifische Verwendung erfordert weitere Tests. Twemproxy-NutzungsarchitekturDer erste Typ: Einzelknoten-Twemproxyps: Hardware speichern Ressourcen, aber anfällig für Single Points of Failure.
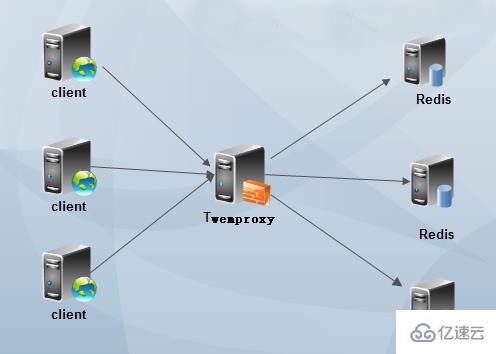
PS: Die Hälfte der Ressourcen wird verschwendet, aber der Knoten ist hoch verfügbar.
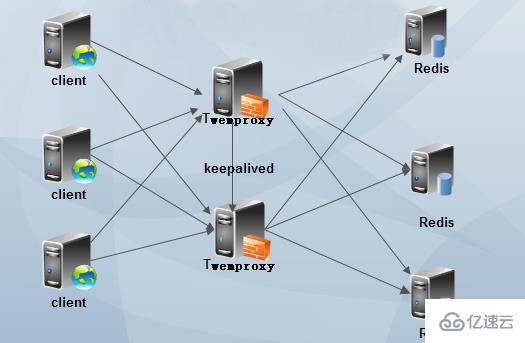
PS: Wenn Sie ein großes Redis- oder Memcached-Anwendungsszenario haben, Sie können die Lastarmee und das Szenario von Twemproxy ausführen, d Sehr leistungsstarke Proxy-Funktionen. Insbesondere können Sie die Einführung in das LVS-Kapitel dieses Blogs lesen. Wenn Sie jedoch LVS verwenden, treten erneut Probleme mit Twemproxy und einzelnen Fehlerquellen auf. Zu diesem Zeitpunkt müssen Sie eine hohe Verfügbarkeit für LVS gewährleisten. Mithilfe der OSPF-Routing-Technologie kann LVS auch einen Lastausgleich erreichen. Und diese Architektur ist die Architektur, die ich derzeit in meiner Arbeit verwende.
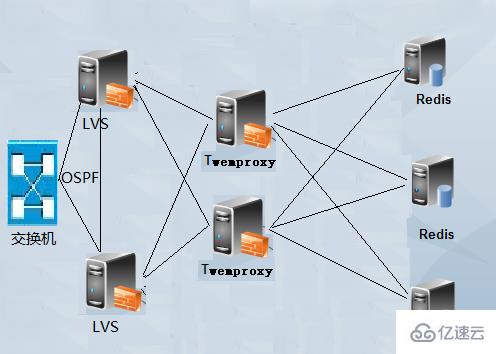
herunter.
Bitte schreiben Sie die folgende Aussage in einen Satz um: Klonen Sie das Twemproxy-Repository mit dem folgenden Befehl auf Ihren lokalen Computer: git clone https://github.com/twitter/twemproxy.git Nach dem Umschreiben: Verwenden Sie den folgenden Befehl auf Ihrem lokalen Computer: git clone https://github.com/twitter/twemproxy.git, um das Twemproxy-Repository zu klonen
2. Twemproxy installieren
Twemproxy muss Autoconf für die Kompilierung und Konfiguration verwenden. GNU Autoconf ist ein Tool zum Erstellen von Konfigurationsskripten zum Kompilieren, Installieren und Packen von Software unter der Bourne-Shell. Autoconf ist nicht durch die Programmiersprache eingeschränkt und wird häufig in C, C++, Erlang und Objective-C verwendet. Ein Konfigurationsskript steuert die Installation eines Softwarepakets auf einem bestimmten System. Durch die Ausführung einer Reihe von Tests generiert das Konfigurationsskript die Makefile- und Header-Dateien aus der Vorlage und passt das Paket nach Bedarf an, um es für das jeweilige System geeignet zu machen. Autoconf bildet zusammen mit Automake und Libtool das GNU Build System. Autoconf wurde im Sommer 1991 von David McKenzie geschrieben, um seine Programmierarbeit bei der Free Software Foundation zu unterstützen. Autoconf hat verbesserten Code integriert, der von mehreren Personen geschrieben wurde, und ist zur am weitesten verbreiteten kostenlosen Kompilierungs- und Konfigurationssoftware geworden.
Beginnen wir mit der Verwendung von Autoconf zum Kompilieren und Konfigurieren von Twemproxy:
[root@www twemproxy]# autoreconfconfigure.ac:8: error: Autoconf version 2.64 or higher is required configure.ac:8: the top level autom4te: /usr/bin/m4 failed with exit status: 63 aclocal: autom4te failed with exit status: 63 autoreconf: aclocal failed with exit status: 63 [root@www twemproxy]# autoconf --versionautoconf (GNU Autoconf) 2.63
Es wird angezeigt, dass die Version von Autoconf zu niedrig ist. Oben wird die Version von Autoconf 2.63 verwendet. Laden Sie also die Version von Autoconf 2.69 zur Kompilierung und Installation herunter. Beachten Sie, dass Ihre Standardversion 2.63 ist, wenn Sie CentOS6 verwenden. Wenn Sie CentOS7 verwenden, sollte Ihre Standardversion 2.69 sein. Wenn Sie Debian8 oder Ubuntu16 sind, sollte Ihre Standardversion ebenfalls 2.69 sein. Wenn beim Ausführen von autoreconf ein Fehler gemeldet wird, bedeutet dies jedenfalls, dass die Version alt ist und kompiliert und installiert werden muss.
Autoconf kompilieren und installieren libtool direkt, wenn es Debian ist, verwenden Sie apt – installieren Sie einfach libtool).
[root@www ~]# wget http://ftp.gnu.org/gnu/autoconf/autoconf-2.69.tar.gz[root@www ~]# tar xvf autoconf-2.69.tar.gz[root@www ~]# cd autoconf-2.69[root@www autoconf-2.69]# ./configure --prefix=/usr[root@www autoconf-2.69]# make && make install[root@www autoconf-2.69]# autoconf --versionautoconf (GNU Autoconf) 2.69
Twemproxy fügt Konfigurationsdatei hinzu
[root@www ~]# cd /root/twemproxy/[root@www twemproxy]# autoreconf -fvi[root@www twemproxy]# ./configure --prefix=/etc/twemproxy CFLAGS="-DGRACEFUL -g -O2" --enable-debug=full[root@www twemproxy]# make && make install
Einführung in die Konfigurationsoptionen:
redis-cluster: Geben Sie diesem Konfigurationssegment einen Namen, es können mehrere Konfigurationssegmente vorhanden sein
listen: Legen Sie die Überwachungs-IP und den Port fest; Die spezifische Hash-Funktion unterstützt mehr als zehn Arten von MD5, crc16, crc32, finv1a_32, fnv1a_64, hsieh, murmur, jenkins usw. Im Allgemeinen kann fnv1a_64 verwendet werden, und der Standardwert ist fnv1a_64;
Umschreiben: Verwenden Sie die Funktion hash_tag Passen Sie die Funktion entsprechend einem Schlüssel an. Berechnet teilweise den Hash-Wert des Schlüssels. Hash_tag besteht aus zwei Zeichen, eines ist der Anfang von hash_tag und das andere ist das Ende von hash_tag. Zwischen dem Anfang und dem Ende von hash_tag befindet sich der Teil, der zur Berechnung des Hash-Werts des Schlüssels und des berechneten Ergebnisses verwendet wird kann zur Auswahl des Servers verwendet werden. Beispiel: Wenn hash_tag als „{}“ definiert ist, basieren die Hashwerte mit den Schlüsselwerten „user:{user1}:ids“ und „user:{user1}:tweets“ auf „ user1“ und wird schließlich demselben Server zugeordnet. Und „user:user1:ids“ verwendet den gesamten Schlüssel zur Berechnung des Hashs, der verschiedenen Servern zugeordnet werden kann.
Verteilung: Geben Sie den Hash-Algorithmus an, der bestimmt, wie die oben genannten Hash-Schlüssel auf mehrere Server verteilt werden. Der Standardwert ist „ketama“-konsistentes Hashing. Ketama: Der konsistente Ketama-Hash-Algorithmus erstellt einen Hash-Ring basierend auf dem Server und weist den Knoten im Ring Hash-Bereiche zu. Der Vorteil von Ketama besteht darin, dass nach dem Hinzufügen oder Löschen eines einzelnen Knotens die zwischengespeicherten Schlüsselwerte im gesamten Cluster weitestgehend wiederverwendet werden können. Modula: Modula ist sehr einfach. Es verwendet das Modulo basierend auf dem Hash-Wert des Schlüsselwerts und wählt den entsprechenden Server basierend auf dem Modulo-Ergebnis aus. Zufällig: Zufällig bedeutet, dass unabhängig vom Hash des Schlüsselwerts ein Server zufällig als Ziel der Schlüsselwertoperation ausgewählt wird.
timeout: Legen Sie das Timeout von twemproxy fest und wenn nach dem Timeout keine Antwort vom Server empfangen wird, wird die Timeout-Fehlermeldung SERVER_ERROR Connection Time Out an den Client gesendet.
backlog: Überwachung der Länge von TCP-Rückstand (Verbindungswarteschlange), der Standardwert ist 512.
preconnect: Geben Sie an, ob twemproxy beim Systemstart Verbindungen mit allen Redis herstellen soll. Der Standardwert ist false, ein boolescher Wert;
redis: Geben Sie an, ob dieser Konfigurationsabschnitt als Proxy für Redis verwendet werden soll , es ist wahr. Sie können als Proxy für den Memcached-Cluster fungieren (dies ist der einzige Unterschied zwischen Twemproxy als Redis- oder Memcached-Cluster-Proxy); Geben Sie das Authentifizierungskennwort an.
server_connections: Die Anzahl der Verbindungen zwischen twemproxy und jedem Redis-Server beträgt standardmäßig 1. Wenn sie größer als 1 ist, können Benutzerbefehle an verschiedene Verbindungen gesendet werden, was die tatsächliche Ausführungsreihenfolge der Befehle beeinflussen kann mit dem angegebenen Benutzer inkonsistent sein (ähnlich der Parallelität);
auto_eject_hosts: ob Eliminieren, wenn der Knoten nicht antworten kann. Es sollte jedoch beachtet werden, dass nach dem Eliminieren die Anzahl der Maschinen abnimmt Die Maschinen-Hash-Position ändert sich, einige Tasten werden jedoch nicht berührt, wenn die Programmverbindung nicht entfernt wird.
server_retry_timeout: Steuert das Zeitintervall für die Serververbindung. Es wird wirksam, wenn auto_eject_host aktiviert ist auf true gesetzt. Der Standardwert ist 30000 Millisekunden;
server_failure_limit:Redis连续超时的次数,超过这个次数就视其为无法连接,如果auto_eject_hosts设置为true,那么此Redis会被移除;
servers:一个pool中的服务器的地址、端口和权重的列表,包括一个可选的服务器的名字,如果提供服务器的名字,将会使用它决定server的次序,从而提供对应的一致性hash的hash ring。否则,将使用server被定义的次序,可以通过两种字符串格式指定’host:port:weight’或者’host:port:weight name’。一般都是使用第二种别名的方式,这样当其中某个Redis节点出现问题时,可以直接添加一个新的Redis节点但服务器名字不要改变,这样twemproxy还是使用相同的服务器名称进行hash ring,所以其他数据节点的数据不会出现问题(只有挂点的机器数据丢失)。
PS:要严格按照Twemproxy配置文件的格式来,不然就会有语法错误;另外,在Twemproxy的配置文件中可以同时设置代理Redis集群或Memcached集群,只需要定义不同的配置段即可。
启动twemproxy (nutcracker)
刚已经加好了配置文件,现在测试下配置文件:
[root@www twemproxy]# /etc/twemproxy/sbin/nutcracker -tnutcracker: configuration file 'conf/nutcracker.yml' syntax is ok
说明配置文件已经成功,现在开始运行nutcracker:
[root@www ~]# /etc/twemproxy/sbin/nutcracker -c /etc/twemproxy/conf/nutcracker.yml -p /var/run/nutcracker.pid -o /var/log/nutcracker.log -d选项说明: -h, –help #查看帮助文档,显示命令选项;-V, –version #查看nutcracker版本;-c, –conf-file=S #指定配置文件路径 (default: conf/nutcracker.yml);-p, –pid-file=S #指定进程pid文件路径,默认关闭 (default: off);-o, –output=S #设置日志输出路径,默认为标准错误输出 (default: stderr);-d, –daemonize #以守护进程运行;-t, –test-conf #测试配置脚本的正确性;-D, –describe-stats #打印状态描述;-v, –verbosity=N #设置日志级别 (default: 5, min: 0, max: 11);-s, –stats-port=N #设置状态监控端口,默认22222 (default: 22222);-a, –stats-addr=S #设置状态监控IP,默认0.0.0.0 (default: 0.0.0.0);-i, –stats-interval=N #设置状态聚合间隔 (default: 30000 msec);-m, –mbuf-size=N #设置mbuf块大小,以bytes单位 (default: 16384 bytes);
PS:一般在生产环境中,都是使用进程管理工具来进行twemproxy的启动管理,如supervisor或pm2工具,避免当进程挂掉的时候能够自动拉起进程。
验证是否正常启动
[root@www ~]# ps aux | grep nutcrackerroot 20002 0.0 0.0 19312 916 ? Sl 18:48 0:00 /etc/twemproxy/sbin/nutcracker -c /etc/twemproxy/conf/nutcracker.yml -p /var/run/nutcracker.pid -o /var/log/nutcracker.log -d root 20006 0.0 0.0 103252 832 pts/0 S+ 18:48 0:00 grep nutcracker [root@www ~]# netstat -nplt | grep 22122tcp 0 0 0.0.0.0:22122 0.0.0.0:* LISTEN 20002/nutcracker
Twemproxy代理Redis集群
这里我们使用第一种方案在同一台主机上测试Twemproxy代理Redis集群,一个twemproxy和两个Redis节点(想添加更多的也可以)。Twemproxy就是用上面的配置了,下面只需要增加两个Redis节点。
安装配置Redis
在安装Redis之前,需要安装Redis的依赖程序tcl,如果不安装tcl在Redis执行make test的时候就会报错的哦。
[root@www ~]# yum install -y tcl[root@www ~]# wget https://github.com/antirez/redis/archive/3.2.0.tar.gz[root@www ~]# tar xvf 3.2.0.tar.gz -C /usr/local[root@www ~]# cd /usr/local/[root@www local]# mv redis-3.2.0 redis[root@www local]# cd redis[root@www redis]# make[root@www redis]# make test[root@www redis]# make install
配置两个Redis节点
[root@www ~]# mkdir /data/redis-6546[root@www ~]# mkdir /data/redis-6547[root@www ~]# cat /data/redis-6546/redis.confdaemonize yes pidfile /var/run/redis/redis-server.pid port 6546bind 0.0.0.0 loglevel notice logfile /var/log/redis/redis-6546.log [root@www ~]# cat /data/redis-6547/redis.confdaemonize yes pidfile /var/run/redis/redis-server.pid port 6547bind 0.0.0.0 loglevel notice logfile /var/log/redis/redis-6547.log
PS:简单提供两个Redis配置文件,如果开启了Redis认证,那么在twemproxy中也需要填写Redis密码。
启动两个Redis节点
[root@www ~]# /usr/local/redis/src/redis-server /data/redis-6546/redis.conf[root@www ~]# /usr/local/redis/src/redis-server /data/redis-6547/redis.conf[root@www ~]# ps aux | grep redisroot 23656 0.0 0.0 40204 3332 ? Ssl 20:14 0:00 redis-server 0.0.0.0:6546 root 24263 0.0 0.0 40204 3332 ? Ssl 20:16 0:00 redis-server 0.0.0.0:6547
验证Twemproxy读写数据
首先twemproxy配置项中servers的主机要配置正确,然后连接Twemproxy的22122端口即可测试。
[root@www ~]# redis-cli -p 22122127.0.0.1:22122> set key vlaue OK 127.0.0.1:22122> get key"vlaue"127.0.0.1:22122> FLUSHALL Error: Server closed the connection 127.0.0.1:22122> quit
上面我们set一个key,然后通过twemproxy也可以获取到数据,一切正常。但是在twemproxy中使用flushall命令就不行了,不支持。
然后我们去找分别连接两个redis节点,看看数据是否出现在某一个节点上了,如果有,就说明twemproxy正常运行了。
[root@www ~]# redis-cli -p 6546127.0.0.1:6546> get key (nil) 127.0.0.1:6546>
由上面的结果我们可以看到,数据存储到6547节点上了。目前没有很好的办法明确知道某个key存储到某个后端节点了。
如何Reload twemproxy?
Twemproxy没有为启动提供脚本,只能通过命令行参数启动。所以,无法使用对twemproxy进行reload的操作,在生产环境中,一个应用无法reload(重载配置文件)是一个灾难。当你对twemproxy进行增删节点时如果直接使用restart的话势必会影响线上的业务。所以最好的办法还是reload,既然twemproxy没有提供,那么可以使用kill命令带一个信号,然后跟上twemproxy主进程的进行号即可。
kill -SIGHUP PID
注意,PID就是twemproxy master进程。
Das obige ist der detaillierte Inhalt vonSo implementieren Sie Redis-Daten-Sharding. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!