
Heim >Datenbank >MySQL-Tutorial >So implementieren Sie die Zufallsextraktion in MySQL
So implementieren Sie die Zufallsextraktion in MySQL

- PHPznach vorne
- 2023-06-03 08:25:522099Durchsuche
1. Einführung
Jetzt besteht die Anforderung, jeweils drei Wörter zufällig aus einer Wortliste auszuwählen.
Die Anweisung zur Tabellenerstellung dieser Tabelle lautet wie folgt:
mysql> Create table 'words'(
'id' int(11) not null auto_increment;
'word' varchar(64) default null;
primary key ('id')
) ENGINE=InnoDB;Dann fügen wir 10.000 Datenzeilen ein. Als nächstes sehen wir uns an, wie man zufällig drei Wörter daraus auswählt.
2. Temporäre Speichertabelle
Zuerst denken wir normalerweise daran, order by rand() zu verwenden, um diese Logik zu implementieren:
mysql> select word from words order by rand() limit 3;
Obwohl dieser Satz sehr einfach ist, ist der Ausführungsprozess komplizierter. Wir verwenden „explain“, um die Ausführung der Anweisung zu sehen: Die Verwendung von „temporär“ im Feld „Extra“ zeigt an, dass eine temporäre Tabelle verwendet werden muss, und „Using filesort“ gibt an, dass eine Sortierung erforderlich ist. Das heißt, es ist ein Sortiervorgang erforderlich.
 Für InnoDB-Tabellen
Für InnoDB-Tabellen
Bei Speichertabellen greift der Tabellenrückgabeprozess einfach direkt auf den Speicher zu, um die Daten basierend auf der Position der Datenzeilen abzurufen, was überhaupt nicht zu mehreren Festplattenzugriffen führt
. Daher wird MySQL zu diesem Zeitpunkt der Rowid-Sortierung Priorität einräumen. 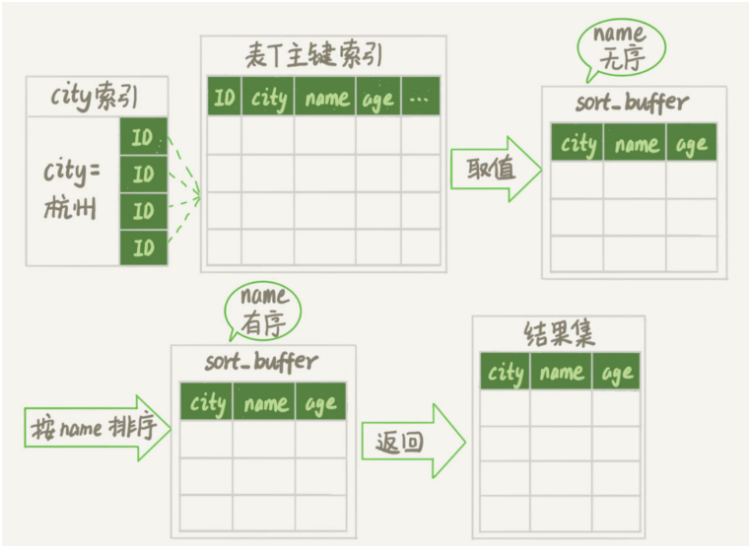
Lassen Sie uns den Ausführungsprozess dieser Anweisung klären:
Diese Tabelle verwendet die Speicher-Engine. Das erste Feld ist vom Typ Double B. R, das zweite Feld ist vom Typ varchar(64) und als W gekennzeichnet. Und diese Tabelle hat keinen Index.
Extrahieren Sie alle Wörter aus der Worttabelle in der Reihenfolge des Primärschlüssels. Rufen Sie für jedes Wort die Funktion rand() auf, um zufällig eine zufällige Dezimalzahl größer als 0 und kleiner als 1 zu generieren, und speichern Sie die zufällige Dezimalzahl und das Wort jeweils in den Feldern R und W der temporären Tabelle.
Der nächste Schritt besteht darin, nach Feld R zu sortieren.- Sort_buffer initialisieren. sort_buffer enthält einen Double-Typ und ein Integer-Feld.
- Nehmen Sie den R-Wert und die Positionsinformationen Zeile für Zeile aus der temporären Speichertabelle heraus und speichern Sie sie jeweils in den beiden Feldern von sort_buffer.
- sort_buffer wird nach dem R-Wert sortiert
- Nach Abschluss der Sortierung werden die Standortinformationen der ersten drei Ergebnisse entnommen, das entsprechende Wort aus der temporären Speichertabelle entnommen und an die zurückgegeben Kunde.
- Das Prozessdiagramm lautet wie folgt:
Die oben genannten Standortinformationen sind tatsächlich der Standort der Zeile, bei dem es sich um die zuvor erwähnte Zeilen-ID handelt.
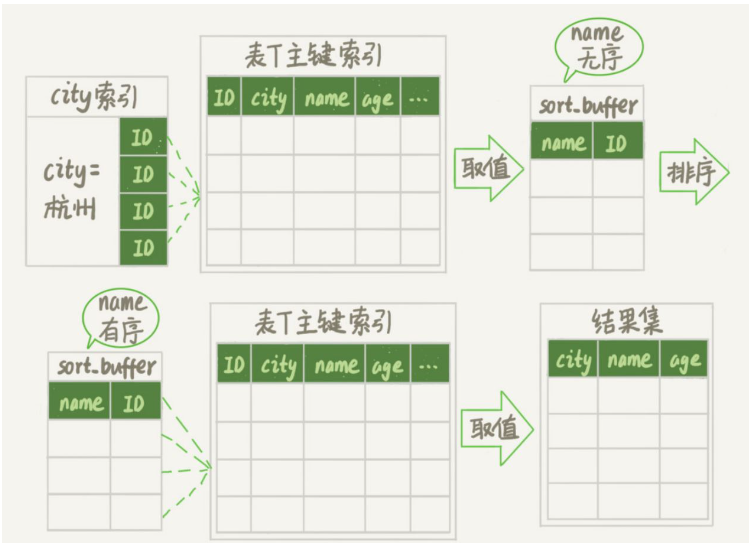
 Für die InnoDB-Engine gibt es zwei Verarbeitungsmethoden für Tabellen mit oder ohne Primärschlüssel:
Für die InnoDB-Engine gibt es zwei Verarbeitungsmethoden für Tabellen mit oder ohne Primärschlüssel:
Für
InnoDB-Tabellen mit Primärschlüsselnist diese Zeilen-ID die Primärschlüssel-ID
Fürohne Primärschlüssel Bei InnoDB-Tabellen wird diese Zeilen-ID vom System generiert und zur Identifizierung verschiedener Zeilen verwendet.
- Daher verwendet
order by randn() eine temporäre Speichertabelle, und die Sortiermethode der temporären Speichertabelle verwendet die Rowid-Sortiermethode.
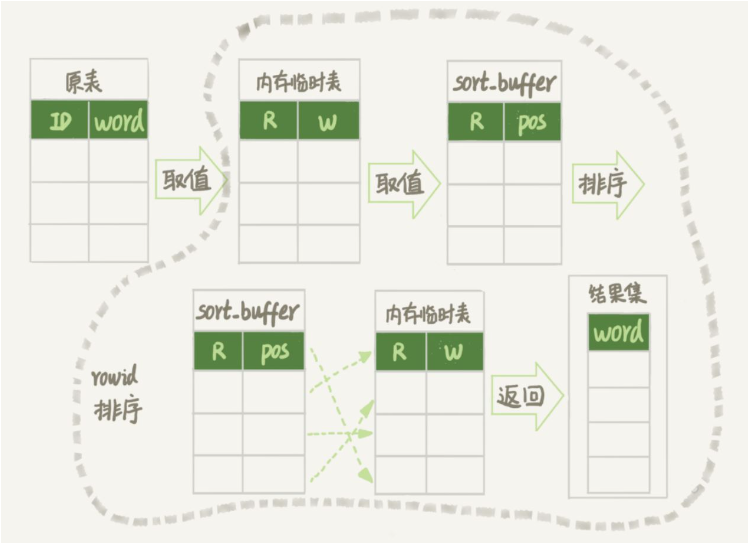
3. Temporäre Festplattentabelle
Nicht alle temporären Tabellen sind temporäre Speichertabellen. Die Konfiguration „tmp_table_size“ begrenzt die Größe der temporären Speichertabelle. Wenn diese Größe überschritten wird, wird die temporäre Tabelle der Festplatte verwendet. Die InnoDB-Engine verwendet standardmäßig temporäre Festplattentabellen
. 4. Sortieralgorithmus der PrioritätswarteschlangeNach MySQL 5.6 wurde der Algorithmus zur Sortierung der Prioritätswarteschlange eingeführt. Dieser Algorithmus erfordert keine Verwendung temporärer Dateien. Der ursprüngliche Zusammenführungssortierungsalgorithmus erfordert die Verwendung temporärer Dateien. Denn wenn Sie den Zusammenführungsalgorithmus verwenden, müssen Sie eigentlich nur die Top 3 erreichen, aber wenn Ihnen die Zusammenführungssortierung ausgeht, ist das Ganze bereits in Ordnung, was zu einer Verschwendung von Ressourcen führt.
Der Sortieralgorithmus der Prioritätswarteschlange kann nur die ersten drei übernehmen, und der Ausführungsprozess ist wie folgt:Um diese 10.000 (R, Zeilen-ID) zu sortieren, nehmen Sie zuerst die ersten drei Zeilen, erstellen Sie einen Heap und Setzen Sie den größten Wert an die Spitze des Heaps.
Nehmen Sie die nächste Zeile (R’, rowid’) und vergleichen Sie sie mit dem größten R im aktuellen Heap. Entfernen Sie (R, rowid) aus dem Heap und ersetzen Sie es durch (R’,rowid’).- Wiederholen Sie den obigen Vorgang.
- Der Prozess ist in der folgenden Abbildung dargestellt:
Aber wenn die Anzahl der Grenzwerte relativ groß ist, ist es schwieriger, den Heap aufrechtzuerhalten, sodass der Zusammenführungssortierungsalgorithmus verwendet wird.
Das obige ist der detaillierte Inhalt vonSo implementieren Sie die Zufallsextraktion in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!