
So verwenden Sie Gaussian Redis zum Implementieren eines Sekundärindex

- PHPznach vorne
- 2023-06-02 18:53:231405Durchsuche
1. Hintergrund
Wenn es um die Indizierung geht, ist der erste Eindruck der Begriff Datenbank, aber Gaussian Redis kann auch eine sekundäre Indizierung implementieren! ! ! Sekundärindizes in Gaussian Redis werden im Allgemeinen mit zset implementiert. Gaussian Redis bietet höhere Stabilität und Kostenvorteile als Open-Source-Redis. Durch die Verwendung von Gaussian Redis zset zur Implementierung von Geschäftssekundärindizes kann eine Win-Win-Situation in Bezug auf Leistung und Kosten erzielt werden.
Der Kern der Indizierung besteht darin, geordnete Strukturen zu verwenden, um Abfragen zu beschleunigen, sodass numerische und Zeichentypindizes einfach über die Zset-Struktur Gaussian Redis implementiert werden können.
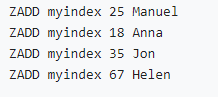
• Numerischer Typindex (zset ist nach Bewertung sortiert):

• Zeichentypindex (zset ist nach lexikografischer Reihenfolge sortiert, wenn die Bewertungen gleich sind):


Schauen wir uns zwei Arten klassischer Geschäftsszenarien an und sehen wir uns an, wie man mit Gaussian Redis ein stabiles und zuverlässiges Sekundärindexsystem aufbaut.
2. Szenario 1: Wörterbuchvervollständigung
Beim Eingeben einer Abfrage im Browser empfiehlt der Browser normalerweise Suchvorgänge mit demselben Präfix basierend auf der Wahrscheinlichkeit. Dieses Szenario kann mithilfe der sekundären Indexfunktion von Gaussian Redis realisiert werden.

2.1 Basislösung
Der einfachste Weg besteht darin, jede Abfrage des Benutzers zum Index hinzuzufügen. Wenn Sie Benutzern Eingabeaufforderungen zur Vervollständigung bereitstellen müssen, können Sie ZRANGEBYLEX verwenden, um Bereichsabfragen durchzuführen. Um die Anzahl der Ergebnisse zu reduzieren, ist die Verwendung der LIMIT-Option eine von Gaussian Redis unterstützte Methode.
• Benutzersuchbanane zum Index hinzufügen:
ZADD myindex 0 banana:1
• Angenommen, der Benutzer gibt „bit“ in das Suchformular ein und wir möchten Suchbegriffe bereitstellen, die mit „bit“ beginnen können.
ZRANGEBYLEX myindex "[bit" "[bit\xff"
Das heißt, verwenden Sie ZRANGEBYLEX, um eine Bereichsabfrage durchzuführen. Der Abfragebereich ist die aktuell vom Benutzer eingegebene Zeichenfolge und dieselbe Zeichenfolge plus ein nachfolgendes Byte von 255 (xff). Mit dieser Methode können wir alle Zeichenfolgen abrufen, denen die vom Benutzer eingegebene Zeichenfolge vorangestellt ist.
2.2 Häufigkeitsbezogene Wörterbuchvervollständigung
In praktischen Anwendungen möchten Benutzer normalerweise Vervollständigungsbegriffe automatisch sortieren, um sie an die Häufigkeit des Auftretens anzupassen, nicht mehr beliebte Begriffe eliminieren und gleichzeitig an zukünftige Eingaben anpassen. Wir können weiterhin die ZSet-Struktur von Gaussian Redis verwenden, um dieses Ziel zu erreichen, aber in der Indexstruktur müssen nicht nur die Suchbegriffe, sondern auch die damit verbundenen Häufigkeiten gespeichert werden.
• Benutzersuchbanane zum Index hinzufügen
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1
• Angenommen, Banane existiert nicht, 1 ist die Häufigkeit
ZADD myindex 0 banana:1
• Angenommen, Banane existiert, Bedarf um die Häufigkeit zu erhöhen
Wenn die in ZRANGEBYLEX myindex „[banana:“ + LIMIT 0 1 zurückgegebene Häufigkeit 1 ist
1) Löschen Sie den alten Eintrag:
ZREM myindex 0 banana:1
2) Fügen Sie die Häufigkeit um eins hinzu und treten Sie erneut bei:
ZADD myindex 0 banana:2
Bitte Beachten Sie, dass aufgrund der Möglichkeit gleichzeitiger Aktualisierungen die oben genannten drei Befehle über ein Lua-Skript gesendet werden sollten, das automatisch die alte Zählung abruft und den Eintrag nach der Erhöhung der Punktzahl erneut hinzufügt.
Wenn der Benutzer „Banane“ in das Suchformular eingibt, hoffen wir, relevante Suchbegriffe bereitzustellen. Sortieren Sie nach Häufigkeit, nachdem Sie Ergebnisse über ZRANGEBYLEX erhalten haben.
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 10 1) "banana:123" 2) "banaooo:1" 3) "banned user:49" 4) "banning:89"
• Verwenden Sie den Streaming-Algorithmus, um selten verwendete Eingaben zu bereinigen. Wählen Sie zufällig einen zurückgegebenen Eintrag aus, subtrahieren Sie eins von seiner Punktzahl und addieren Sie ihn dann wieder mit der aktualisierten Punktzahl. Wenn die neue Punktzahl jedoch 0 ist, müssen wir den Eintrag aus der Liste entfernen.
• Wenn die Häufigkeit zufällig ausgewählter Einträge 1 beträgt, z. B. banaooo:1
ZREM myindex 0 banaooo:1
• Wenn die Häufigkeit zufällig ausgewählter Einträge größer als 1 ist, z. B. banane:123
ZREM myindex 0 banana:123 ZADD myindex 0 banana:122
Der Index umfasst beliebte Suchanfragen. Er passt sich auch automatisch an, wenn sich beliebte Suchanfragen im Laufe der Zeit ändern.
3. Szenario 2: Mehrdimensionaler Index
Gaussian Redis unterstützt nicht nur Abfragen in einer einzelnen Dimension, sondern kann auch mehrdimensionale Daten abrufen. Suchen Sie beispielsweise nach Personen, die die folgenden Kriterien erfüllen: Alter zwischen 50 und 55 Jahren und Gehalt zwischen 70.000 und 85.000. Die Konvertierung zweidimensionaler Datenkodierung in eindimensionale Daten und die anschließende Verwendung des Gaußschen verteilten Redis-Zset-Speichers ist eine wichtige Methode zur Implementierung mehrdimensionaler Sekundärindizes.
Stellen Sie den zweidimensionalen Index aus einer visuellen Perspektive dar. In diesem Raum gibt es einige Datenabtastpunkte, die als Koordinaten (x, y) dargestellt werden, und die Maximalwerte der x- und y-Variablen in diesen Koordinaten betragen 400. Das blaue Kästchen im Bild stellt unsere Anfrage dar. Wir wollen alle Punkte mit den Koordinaten x zwischen 50 und 100 und y zwischen 100 und 300 finden.
 3.1 Datenkodierung
3.1 Datenkodierung
Wenn der eingefügte Datenpunkt x = 75 und y = 200 ist
1) Geben Sie 0 ein (die maximalen Daten sind 400, geben Sie also 3 Ziffern ein)
x = 075
y = 200
2)交织数字,以x表示最左边的数字,以y表示最左边的数字,依此类推,以便创建一个编码
027050
若使用00和99替换最后两位,即027000 to 027099,map回x和y,即:
x = 70-79
y = 200-209
因此,针对x=70-79和y = 200-209的二维查询,可以通过编码map成027000 to 027099的一维查询,这可以通过高斯Redis的Zset结构轻松实现。

同理,我们可以针对后四/六/etc位数字进行相同操作,从而获得更大范围。
3)使用二进制
如果将数据表示为二进制,就可以获得更细的粒度,而在数字替换时,每次都将搜索范围扩大两倍。如果我们使用二进制表示法数字,每个变量最多需要9位(表示最多400个值),那么我们将得到:
x = 75 -> 001001011
y = 200 -> 011001000
交织后,000111000011001010
让我们看看在交错表示中用0s ad 1s替换最后的2、4、6、8,...位时我们的范围是什么:

3.2 添加新元素
若插入数据点为x = 75和y = 200
x = 75和y = 200二进制交织编码后为000111000011001010,
ZADD myindex 0 000111000011001010
3.3 查询
查询:x介于50和100之间,y介于100和300之间的所有点
从索引中替换N位会给我们边长为2^(N/2)的搜索框。因此,我们要做的是检查搜索框较小的尺寸,并检查与该数字最接近的2的幂,并不断切分剩余空间,随后用ZRANGEBYLEX进行搜索。
下面是示例代码:
def spacequery(x0,y0,x1,y1,exp)
bits=exp*2
x_start = x0/(2**exp)
x_end = x1/(2**exp)
y_start = y0/(2**exp)
y_end = y1/(2**exp)
(x_start..x_end).each{|x|
(y_start..y_end).each{|y|
x_range_start = x*(2**exp)
x_range_end = x_range_start | ((2**exp)-1)
y_range_start = y*(2**exp)
y_range_end = y_range_start | ((2**exp)-1)
puts "#{x},#{y} x from #{x_range_start} to #{x_range_end}, y from #{y_range_start} to #{y_range_end}"
# Turn it into interleaved form for ZRANGEBYLEX query.
# We assume we need 9 bits for each integer, so the final
# interleaved representation will be 18 bits.
xbin = x_range_start.to_s(2).rjust(9,'0')
ybin = y_range_start.to_s(2).rjust(9,'0')
s = xbin.split("").zip(ybin.split("")).flatten.compact.join("")
# Now that we have the start of the range, calculate the end
# by replacing the specified number of bits from 0 to 1.
e = s[0..-(bits+1)]+("1"*bits)
puts "ZRANGEBYLEX myindex [#{s} [#{e}"
}
}
end
spacequery(50,100,100,300,6)Das obige ist der detaillierte Inhalt vonSo verwenden Sie Gaussian Redis zum Implementieren eines Sekundärindex. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!