
Heim >Technologie-Peripheriegeräte >KI >Wie gibt ChatGPT Wort für Wort aus?
Wie gibt ChatGPT Wort für Wort aus?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-02 17:40:222233Durchsuche

Wenn ChatGPT eine Frage beantwortet, wird sie Wort für Wort angezeigt und gibt den Leuten das Gefühl, ernsthaft nachzudenken.
Der grundlegende Inhalt dieses Gesprächs ist:
F: Wie funktionieren generative Modelle großer Sprachen?
A: Generative Modelle großer Sprachen (wie GPT-3) sind neuronale Netze, die auf Deep-Learning-Technologie basieren Modell. Diese Modelle verwenden häufig eine Architektur namens „Transformer“, die im Bereich der Verarbeitung natürlicher Sprache große Erfolge erzielt hat.Hier ist ein Überblick darüber, wie groß angelegte Sprachgenerierungsmodelle funktionieren:
… Einen Absatz weglassen…
Text generieren: Sobald das Modell trainiert ist, können Sie es verwenden Text generieren. Bei einem anfänglichen Text oder einer anfänglichen Eingabeaufforderung generiert das Modell das nächste Wort basierend auf der erlernten Wahrscheinlichkeitsverteilung, verwendet dann das generierte Wort als Eingabe und fährt mit der Generierung des nächsten Wortes usw. fort, bis die gewünschte Textlänge erreicht ist oder eine Beendigung generiert wird Symbol.
... Lassen Sie einen Absatz weg...
Großes Sprachmodell, als LLM bezeichnet.
Aus Modellsicht generiert LLM jedes Mal ein Token, wenn es eine Inferenz durchführt, bis die Textlängenbeschränkung erreicht ist oder ein Abschlusszeichen generiert wird.
Aus Sicht des Servers müssen die generierten Token einzeln über das HTTPS-Protokoll an den Browser zurückgegeben werden.
Im Client-Server-Modus besteht die herkömmliche Interaktionsmethode darin, dass der Client eine Anfrage sendet und eine Antwort erhält. Offensichtlich kann dies nicht das Szenario erfüllen, in dem ChatGPT auf Fragen antwortet.
Zweitens denken wir vielleicht an WebSocket, das zur Implementierung des Handshakes auf HTTP basiert und auf WebSocket aktualisiert wird. WebSocket erfordert jedoch, dass sowohl der Client als auch der Server kontinuierlich einen Socket belegen, und die Kosten auf der Serverseite sind relativ hoch. Im SSE-Modus muss der Client nur einmal Nachrichten an den Server senden angefordert, kann der Server die Ausgabe bis zum Ende der Anfrage fortsetzen. Der gesamte Interaktionsprozess ist in der folgenden Abbildung dargestellt:
SSE verwendet weiterhin HTTP als Übertragungsprotokoll der Anwendungsschicht und nutzt die lange Verbindungsfähigkeit von HTTP vollständig aus, um serverseitige Push-Funktionen zu erreichen. 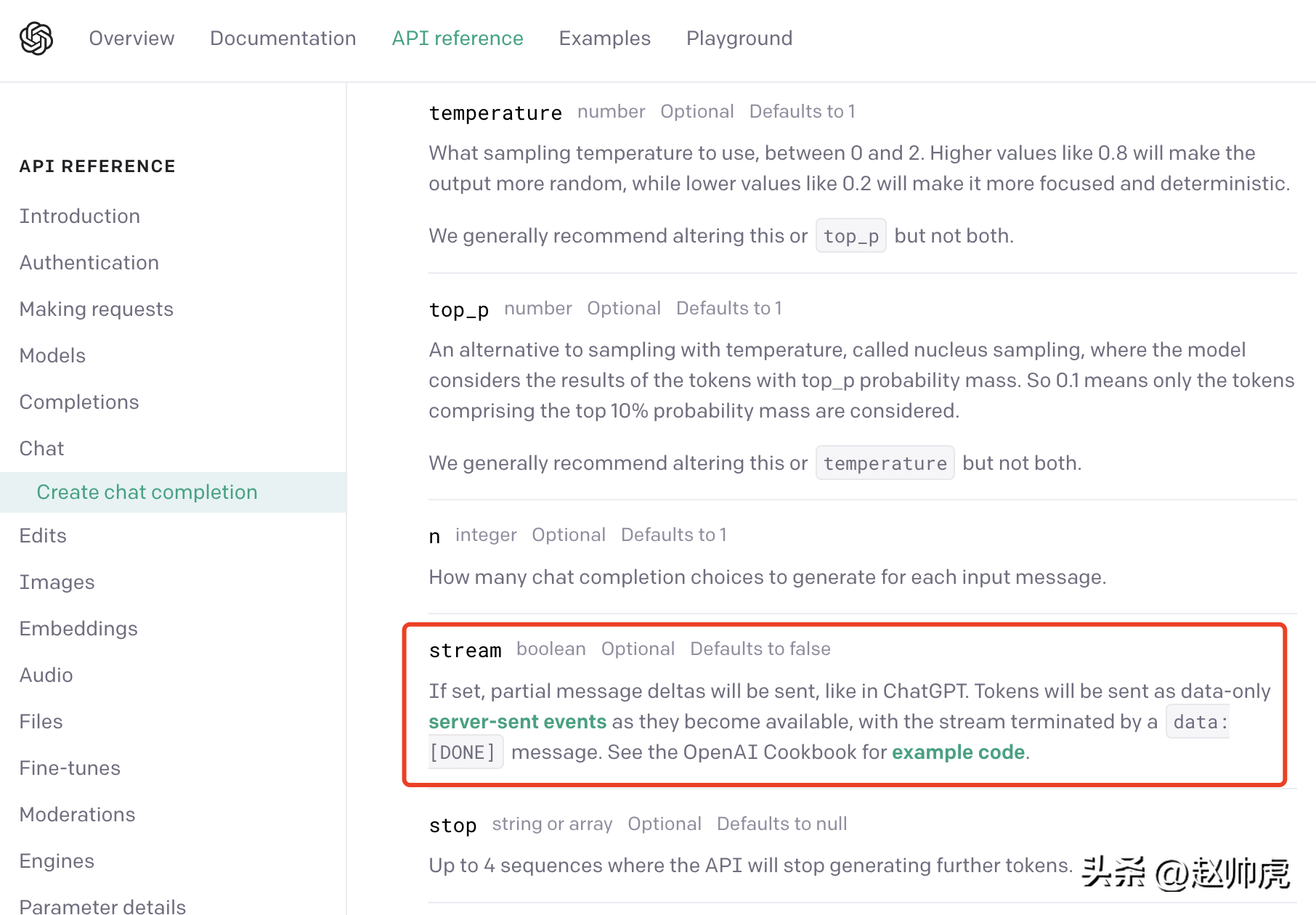
Auf Codeebene sind die Unterschiede zwischen dem SSE-Modus und einer einzelnen HTTP-Anfrage:
Der HTTP-Antwortheader enthält Content-Type=text/event-stream, Cache-Cnotallow=no-cache usw.
Der Hauptteil einer HTTP-Antwort ist im Allgemeinen eine Struktur wie „Daten: ...“.
- Die HTTP-Antwort enthält möglicherweise einige leere Daten, um eine Zeitüberschreitung der Verbindung zu vermeiden.
- Nehmen wir als Beispiel die ChatGPT-API: Wenn Sie beim Senden einer Anfrage den Stream-Parameter auf „true“ setzen, wird die SSE-Funktion aktiviert, Sie müssen jedoch ein wenig auf das SDK achten, das die Daten liest.
- Im normalen Modus, nachdem Sie
- http.Response
func main() {payload := strings.NewReader(`{"model": "gpt-3.5-turbo","messages": [{"role": "user", "content": "大语言生成式模型是如何工作的"}],"max_tokens": 1024,"temperature": 1,"top_p": 1,"n": 1,"stream": false}`)client := &http.Client{}req, _ := http.NewRequest("POST", "https://api.openai.com/v1/chat/completions", payload)req.Header.Add("Content-Type", "application/json")req.Header.Add("Authorization", "Bearer <openai-token>")resp, err := client.Do(req)if err != nil {fmt.Println(err)return}defer resp.Body.Close()body, _ := ioutil.ReadAll(resp.Body)fmt.Println(string(body))}</openai-token>
Die Ausführung dauert mehr als 20 Sekunden und wir erhalten ein vollständiges Ergebnis:
{"id": "chatcmpl-7KklTf9mag5tyBXLEqM3PWQn4jlfD","object": "chat.completion","created": 1685180679,"model": "gpt-3.5-turbo-0301","usage": {"prompt_tokens": 21,"completion_tokens": 358,"total_tokens": 379},"choices": [{"message": {"role": "assistant","content": "大语言生成式模型通常采用神经网络来实现,具体工作流程如下:\n\n1. 数据预处理:将语料库中的文本数据进行预处理,包括分词、删除停用词(如“的”、“了”等常用词汇)、去重等操作,以减少冗余信息。\n\n2. 模型训练:采用递归神经网络(RNN)、长短期记忆网络(LSTM)或变种的Transformers等模型进行训练,这些模型都具有一定的记忆能力,可以学习到语言的一定规律,并预测下一个可能出现的词语。\n\n3. 模型应用:当模型完成训练后,可以将其应用于实际的生成任务中。模型接收一个输入文本串,并预测下一个可能出现的词语,直到达到一定长度或遇到结束符号为止。\n\n4. 根据生成结果对模型进行调优:生成的结果需要进行评估,如计算生成文本与语料库文本的相似度、流畅度等指标,以此来调优模型,提高其生成质量。\n\n总体而言,大语言生成式模型通过对语言的规律学习,从而生成高质量的文本。"},"finish_reason": "stop","index": 0}]}
Wenn wir Stream ohne Änderungen auf „true“ setzen, beträgt der gesamte Anforderungsverbrauch mehr als 28 Sekunden, was sich in vielen Stream-Nachrichten widerspiegelt:
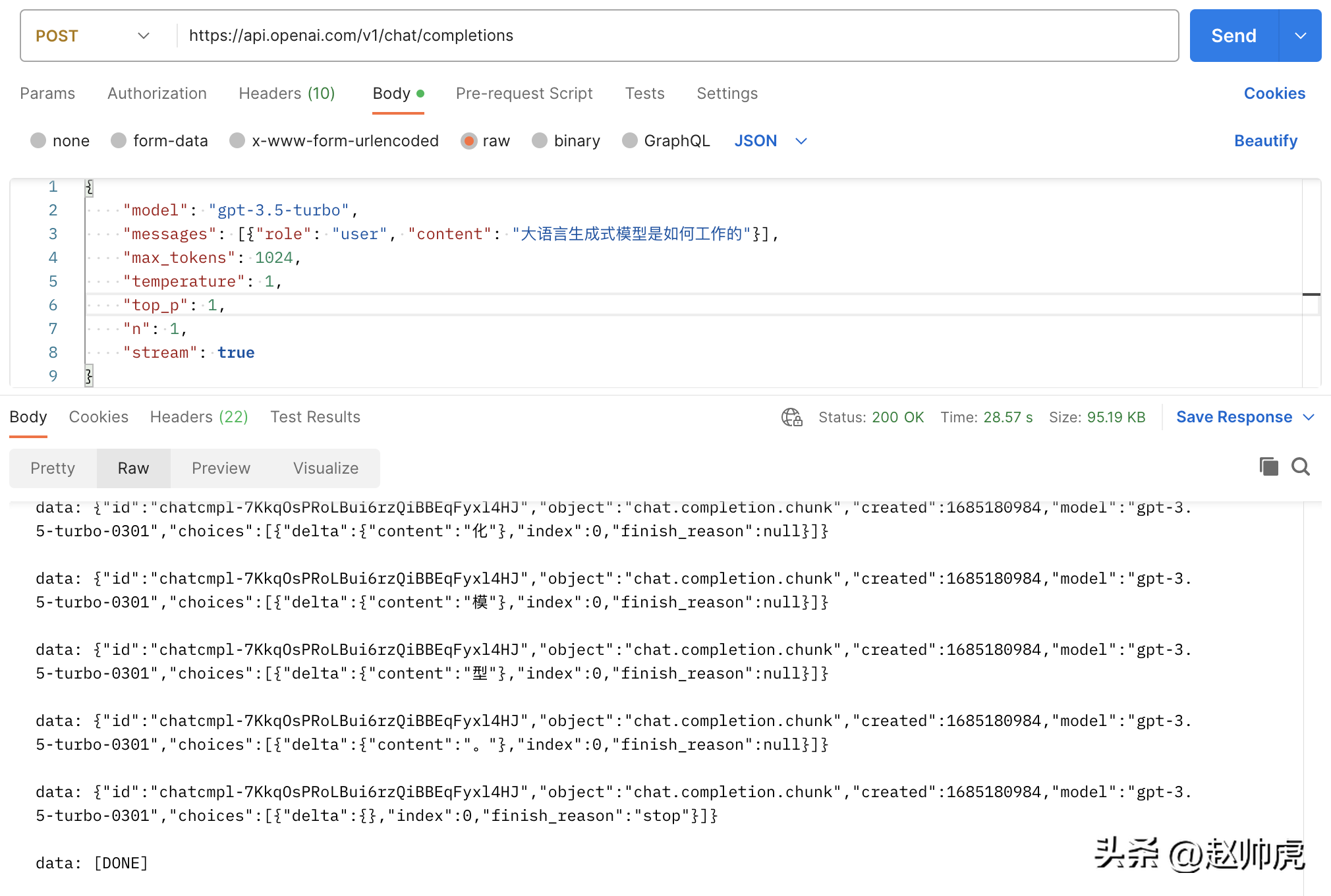
Das Bild oben ist ein Bild von Postman, wie er die Chatgpt-API im Modus ioutil.ReadAll aufruft. Um das Stream-Lesen zu implementieren, können wir http.Response.Body in Segmenten lesen. Der folgende Grund ist der Grund, warum diese Methode machbar ist:
- http.Response.Body ist vom Typ io.ReaderCloser Die zugrunde liegende Schicht basiert auf einer HTTP-Verbindung und unterstützt Stream-Lesen.
- Die von SSE zurückgegebenen Daten werden durch das Zeilenumbruchzeichen n geteilt
Die Korrekturmethode besteht also darin, sie durch bufio.NewReader(resp.Body) zu wickeln und in einer for-Schleife zu lesen , Der Code lautet wie folgt:
// stream event 结构体定义type ChatCompletionRspChoiceItem struct {Deltamap[string]string `json:"delta,omitempty"` // 只有 content 字段Indexint `json:"index,omitempty"`Logprobs *int`json:"logprobs,omitempty"`FinishReason string`json:"finish_reason,omitempty"`}type ChatCompletionRsp struct {IDstring`json:"id"`Objectstring`json:"object"`Created int `json:"created"` // unix secondModel string`json:"model"`Choices []ChatCompletionRspChoiceItem `json:"choices"`}func main() {payload := strings.NewReader(`{"model": "gpt-3.5-turbo","messages": [{"role": "user", "content": "大语言生成式模型是如何工作的"}],"max_tokens": 1024,"temperature": 1,"top_p": 1,"n": 1,"stream": true}`)client := &http.Client{}req, _ := http.NewRequest("POST", "https://api.openai.com/v1/chat/completions", payload)req.Header.Add("Content-Type", "application/json")req.Header.Add("Authorization", "Bearer "+apiKey)req.Header.Set("Accept", "text/event-stream")req.Header.Set("Cache-Control", "no-cache")req.Header.Set("Connection", "keep-alive")resp, err := client.Do(req)if err != nil {fmt.Println(err)return}defer resp.Body.Close()reader := bufio.NewReader(resp.Body)for {line, err := reader.ReadBytes('\n')if err != nil {if err == io.EOF {// 忽略 EOF 错误break} else {if netErr, ok := err.(net.Error); ok && netErr.Timeout() {fmt.Printf("[PostStream] fails to read response body, timeout\n")} else {fmt.Printf("[PostStream] fails to read response body, err=%s\n", err)}}break}line = bytes.TrimSuffix(line, []byte{'\n'})line = bytes.TrimPrefix(line, []byte("data: "))if bytes.Equal(line, []byte("[DONE]")) {break} else if len(line) > 0 {var chatCompletionRsp ChatCompletionRspif err := json.Unmarshal(line, &chatCompletionRsp); err == nil {fmt.Printf(chatCompletionRsp.Choices[0].Delta["content"])} else {fmt.Printf("\ninvalid line=%s\n", line)}}}fmt.Println("the end")}
Nachdem wir die Clientseite gelesen haben, schauen wir uns die Serverseite an. Jetzt versuchen wir, den Chatgpt-Server zu verspotten und einen Text wörtlich zurückzugeben. Hier sind zwei Punkte beteiligt:
- Der Antwortheader muss Connection auf Keep-Alive und Content-Type auf Text/Event-Stream setzen.
- Nachdem die Antwort geschrieben wurde, muss sie an den Client weitergeleitet werden.
Der Code lautet wie folgt:
func streamHandler(w http.ResponseWriter, req *http.Request) {w.Header().Set("Connection", "keep-alive")w.Header().Set("Content-Type", "text/event-stream")w.Header().Set("Cache-Control", "no-cache")var chatCompletionRsp ChatCompletionRsprunes := []rune(`大语言生成式模型通常使用深度学习技术,例如循环神经网络(RNN)或变压器(Transformer)来建模语言的概率分布。这些模型接收前面的词汇序列,并利用其内部神经网络结构预测下一个词汇的概率分布。然后,模型将概率最高的词汇作为生成的下一个词汇,并递归地生成一个词汇序列,直到到达最大长度或遇到一个终止符号。在训练过程中,模型通过最大化生成的文本样本的概率分布来学习有效的参数。为了避免模型产生过于平凡的、重复的、无意义的语言,我们通常会引入一些技巧,如dropout、序列扰动等。大语言生成模型的重要应用包括文本生成、问答系统、机器翻译、对话建模、摘要生成、文本分类等。`)for _, r := range runes {chatCompletionRsp.Choices = []ChatCompletionRspChoiceItem{{Delta: map[string]string{"content": string(r)}},}bs, _ := json.Marshal(chatCompletionRsp)line := fmt.Sprintf("data: %s\n", bs)fmt.Fprintf(w, line)if f, ok := w.(http.Flusher); ok {f.Flush()}time.Sleep(time.Millisecond * 100)}fmt.Fprintf(w, "data: [DONE]\n")}func main() {http.HandleFunc("/stream", streamHandler)http.ListenAndServe(":8088", nil)}
In einem realen Szenario stammen die zurückzugebenden Daten von einem anderen Dienst oder Funktionsaufruf. Wenn die Rückgabezeit dieses Dienst- oder Funktionsaufrufs instabil ist, kann es sein, dass der Client Da die Nachricht längere Zeit nicht empfangen werden kann, lautet die allgemeine Verarbeitungsmethode:
- Stellen Sie den Anruf an den Dritten in einer Goroutine.
- Erstellen Sie einen Timer über die Zeit. Aktivieren Sie das Kontrollkästchen und senden Sie eine leere Nachricht an den Kunden.
- Erstellen Sie einen Timeout-Kanal, um zu lange Reaktionszeiten zu vermeiden.
Um Daten aus verschiedenen Kanälen lesen zu können, ist „select“ ein gutes Schlüsselwort, wie zum Beispiel dieser Democode:
// 声明一个 event channel// 声明一个 time.Tick channel// 声明一个 timeout channelselect {case ev := <h2>Um es zusammenzufassen:</h2><p style="text-align: justify;"><span style="color: #333333;">Der Prozess der Generierung einer Antwort auf das gesamte Ergebnis eines Das große Sprachmodell ist relativ lang. Ja, aber die von Token zu Token generierte Antwort ist relativ schnell. ChatGPT kombiniert diese Funktion vollständig mit der SSE-Technologie, um Antworten Wort für Wort anzuzeigen und so eine qualitative Verbesserung der Benutzererfahrung zu erzielen. </span></p><p style="text-align: justify;"><span style="color: #333333;">Betrachten Sie generative Modelle, sei es LLAMA/Little Alpaca (nicht im Handel erhältlich) oder Stable Diffusion/Midjourney. Bei der Bereitstellung von Online-Diensten kann die SSE-Technologie eingesetzt werden, um das Benutzererlebnis zu verbessern und Serverressourcen zu schonen. </span></p>Das obige ist der detaillierte Inhalt vonWie gibt ChatGPT Wort für Wort aus?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr