
Heim >Technologie-Peripheriegeräte >KI >Eine ausführliche Interpretation des visuellen 3D-Wahrnehmungsalgorithmus für autonomes Fahren
Eine ausführliche Interpretation des visuellen 3D-Wahrnehmungsalgorithmus für autonomes Fahren

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-02 15:42:141257Durchsuche
Für autonome Fahranwendungen ist es letztlich notwendig, 3D-Szenen wahrzunehmen. Der Grund ist einfach. Ein Fahrzeug kann nicht auf der Grundlage der aus einem Bild gewonnenen Wahrnehmungsergebnisse fahren. Selbst ein menschlicher Fahrer kann nicht auf der Grundlage eines Bildes fahren. Da die Entfernung von Objekten und die Tiefeninformationen der Szene nicht in den 2D-Wahrnehmungsergebnissen widergespiegelt werden können, sind diese Informationen der Schlüssel für das autonome Fahrsystem, um korrekte Urteile über die Umgebung zu fällen.
Im Allgemeinen werden die visuellen Sensoren (z. B. Kameras) autonomer Fahrzeuge oberhalb der Fahrzeugkarosserie oder am Innenrückspiegel installiert. Egal wo sie ist, was die Kamera erhält, ist die Projektion der realen Welt in der perspektivischen Ansicht (Weltkoordinatensystem zu Bildkoordinatensystem). Diese Ansicht ähnelt dem menschlichen visuellen System und ist daher für menschliche Fahrer leicht zu verstehen. Ein fatales Problem bei perspektivischen Ansichten ist jedoch, dass sich der Maßstab von Objekten mit der Entfernung ändert. Wenn das Wahrnehmungssystem daher ein Hindernis vor dem Bild erkennt, kennt es weder die Entfernung des Hindernisses vom Fahrzeug noch die tatsächliche dreidimensionale Form und Größe des Hindernisses.
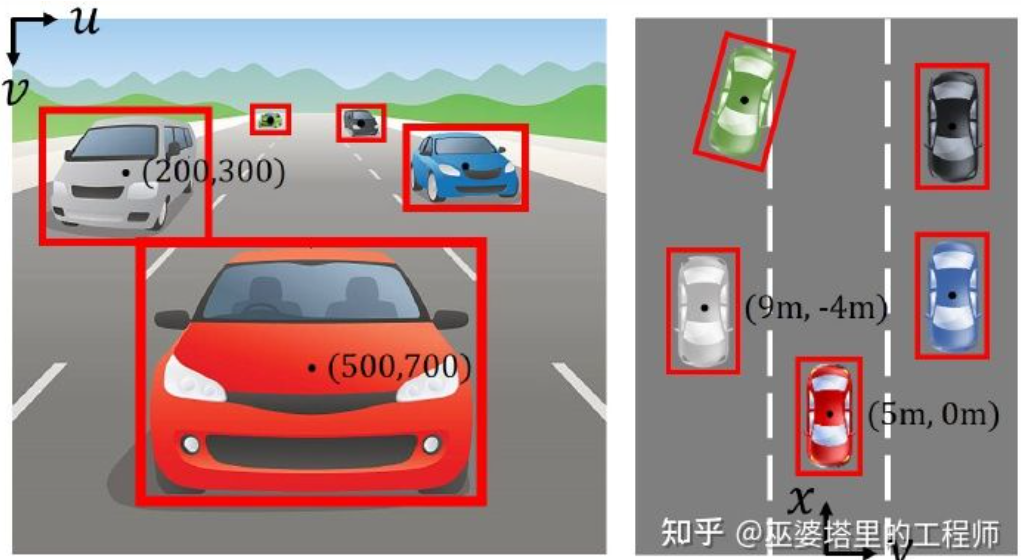
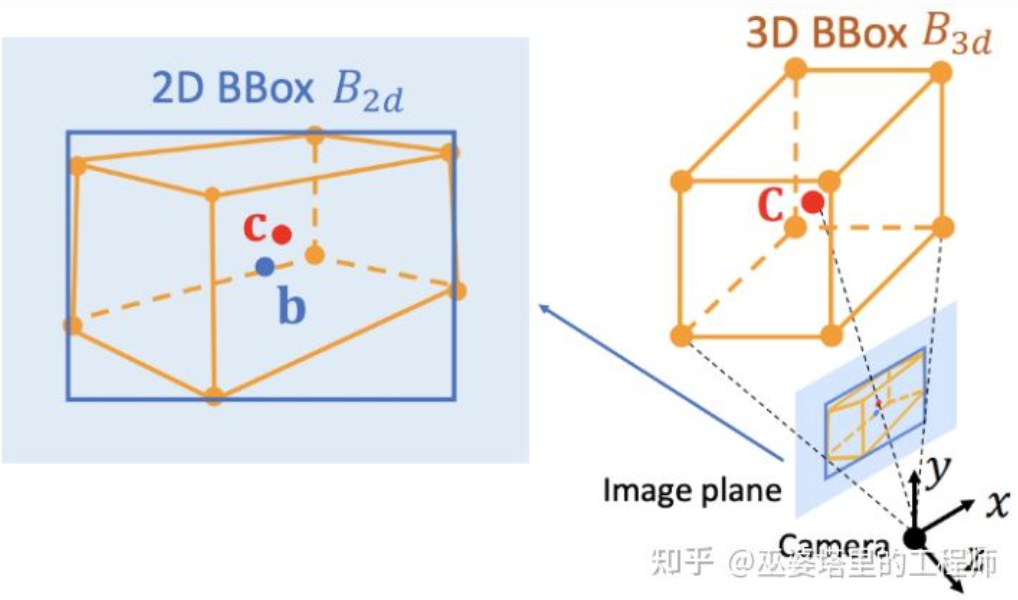
Bildkoordinatensystem (perspektivische Ansicht) vs. Weltkoordinatensystem (Vogelperspektive) [IPM-BEV]
Wenn Sie Informationen über den 3D-Raum erhalten möchten, ist einer der Die direkteste Methode ist die Verwendung von LiDAR. Einerseits kann die von LiDAR ausgegebene 3D-Punktwolke direkt verwendet werden, um die Entfernung und Größe von Hindernissen (3D-Objekterkennung) sowie die Tiefe der Szene (semantische 3D-Segmentierung) zu ermitteln. Andererseits können 3D-Punktwolken auch mit 2D-Bildern fusioniert werden, um die unterschiedlichen Informationen, die beide liefern, voll auszunutzen: Der Vorteil von Punktwolken liegt in der genauen Entfernungs- und Tiefenwahrnehmung, während der Vorteil von Bildern in reichhaltigeren semantischen Informationen liegt.
Allerdings hat LiDAR auch seine Nachteile, wie z. B. höhere Kosten, Schwierigkeiten bei der Massenproduktion von Produkten in Automobilqualität, stärkere Witterungseinflüsse usw. Daher ist die ausschließlich auf Kameras basierende 3D-Wahrnehmung immer noch eine sehr bedeutungsvolle und wertvolle Forschungsrichtung. In den folgenden Abschnitten dieses Artikels werden die 3D-Wahrnehmungsalgorithmen basierend auf Einzel- und Doppelkameras ausführlich vorgestellt.
01
Monokulare 3D-Wahrnehmung
Die Wahrnehmung der 3D-Umgebung auf der Grundlage einzelner Kamerabilder ist ein schlecht gestelltes Problem, aber einige geometrische Einschränkungen und Vorkenntnisse können bei der Erfüllung dieser Aufgabe hilfreich sein und sind tief neuronal Netzwerke können auch verwendet werden, um durchgängig zu lernen, wie 3D-Informationen aus Bildmerkmalen vorhergesagt werden. „Objekterkennung“ Bild ist von echt Die Welt Die Projektion von 3D-Koordinaten auf 2D-Ebenenkoordinaten. Eine sehr direkte Idee für die 3D-Objekterkennung aus Bildern besteht darin, das 2D-Bild in 3D-Weltkoordinaten umzuwandeln und dann die Objekterkennung im Weltkoordinatensystem durchzuführen. Theoretisch ist dies ein schlecht gestelltes Problem, das jedoch mit einigen zusätzlichen Informationen (z. B. Tiefenschätzung) oder geometrischen Annahmen (z. B. auf dem Boden befindliche Pixel) gelöst werden kann.
BEV-IPM [1] schlägt vor, Bilder von der perspektivischen Ansicht in die Vogelperspektive (BEV) zu konvertieren. Hier gibt es zwei Annahmen: Zum einen ist die Straßenoberfläche parallel zum Weltkoordinatensystem und die Höhe ist Null, zum anderen ist das eigene Koordinatensystem des Fahrzeugs parallel zum Weltkoordinatensystem. Ersteres ist nicht erfüllt, wenn die Straßenoberfläche nicht eben ist, während letzteres durch Fahrzeuglageparameter (Pitch und Roll) korrigiert werden kann, bei denen es sich tatsächlich um die Kalibrierung des Fahrzeugkoordinatensystems und des Weltkoordinatensystems handelt. Unter der Annahme, dass alle Pixel im Bild in der realen Welt eine Höhe von Null haben, kann die Homographietransformation verwendet werden, um das Bild in eine BEV-Ansicht umzuwandeln. In der BEV-Ansicht wird eine auf dem YOLO-Netzwerk basierende Methode verwendet, um die untere Box des Ziels zu erkennen, bei der es sich um das Rechteck handelt, das Kontakt mit der Straßenoberfläche hat. Die Höhe der unteren Box ist Null, sodass sie als GroudTruth genau auf die BEV-Ansicht projiziert werden kann, um das neuronale Netzwerk zu trainieren. Gleichzeitig kann die vom neuronalen Netzwerk vorhergesagte Box auch ihre Entfernung genau schätzen. Hierbei wird davon ausgegangen, dass das Ziel Kontakt mit der Straßenoberfläche haben muss, was im Allgemeinen für Fahrzeug- und Fußgängerziele ausreicht.
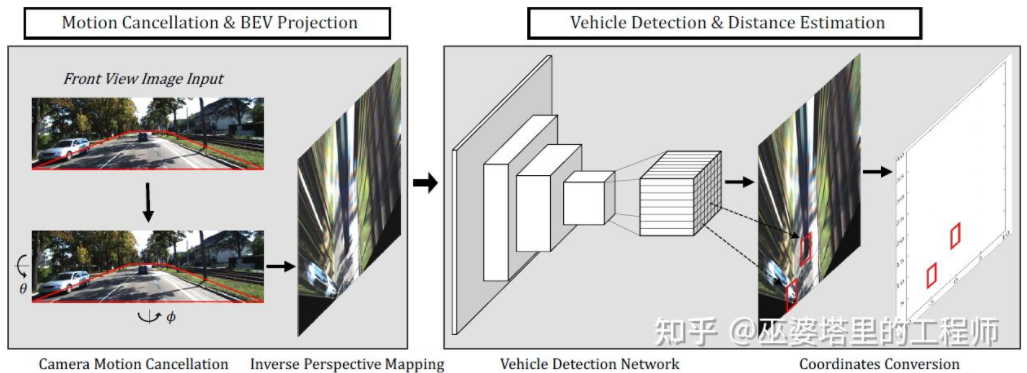
BEV-IPM
Eine weitere inverse Transformationsmethode verwendet Orthographic Feature Transform (OFT) [2]. Die Idee besteht darin, mit CNN Bildmerkmale in mehreren Maßstäben zu extrahieren, diese Bildmerkmale dann in BEV-Ansichten umzuwandeln und schließlich eine 3D-Objekterkennung für BEV-Merkmale durchzuführen. Zunächst muss ein 3D-Gitter aus der BEV-Perspektive erstellt werden (der Gitterbereich des Experiments in diesem Artikel beträgt 80 Meter x 80 Meter x 4 Meter und die Gittergröße beträgt 0,5 m). Jedes Gitter entspricht durch perspektivische Transformation einem Bereich auf dem Bild (der Einfachheit halber als rechteckiger Bereich definiert), und der Mittelwert der Bildmerkmale in diesem Bereich wird als Merkmal des Gitters verwendet, wodurch die 3D-Gittereigenschaften erhalten werden. Um den Rechenaufwand zu reduzieren, werden die 3D-Gittermerkmale in der Höhendimension komprimiert (gewichteter Durchschnitt), um die 2D-Gittermerkmale zu erhalten. Die endgültige Objekterkennung wird an 2D-Netzmerkmalen durchgeführt. Die Projektion von 3D-Gittern auf 2D-Bildpixel entspricht nicht eins zu eins. Mehrere Gitter entsprechen benachbarten Bildbereichen, was zu Mehrdeutigkeiten bei den Gittermerkmalen führt. Daher muss auch davon ausgegangen werden, dass sich die zu erkennenden Objekte alle auf der Straße befinden und der Höhenbereich sehr eng ist. Daher ist das im Experiment verwendete 3D-Gitter nur 4 Meter hoch, was ausreicht, um Fahrzeuge und Fußgänger auf dem Boden abzudecken. Wenn Sie jedoch Verkehrszeichen erkennen möchten, ist diese Methode der Annahme, dass sich Objekte in Bodennähe befinden, nicht anwendbar.
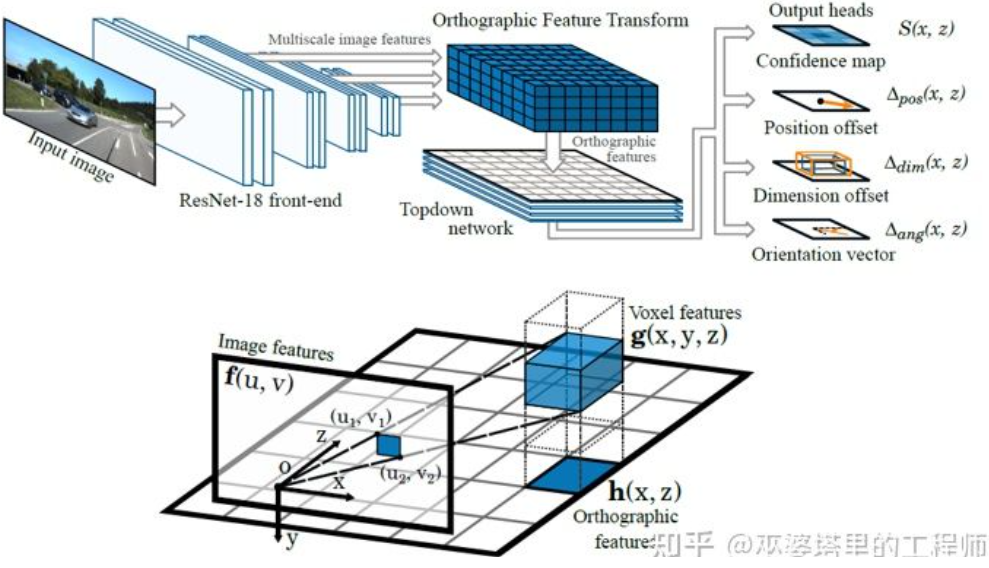
Orthographic Feature Transform
Die beiden oben genannten Methoden basieren auf der Annahme, dass sich das Objekt auf dem Boden befindet. Darüber hinaus besteht eine weitere Idee darin, die Ergebnisse der Tiefenschätzung zur Generierung von Pseudo-Punktwolkendaten zu nutzen. Eine typische Arbeit ist Pseudo-LiDAR [3]. Die Ergebnisse der Tiefenschätzung werden im Allgemeinen als zusätzliche Bildkanäle behandelt (ähnlich wie RGB-D-Daten), und bildbasierte Objekterkennungsnetzwerke werden direkt verwendet, um 3D-Objektbegrenzungsrahmen zu generieren. Der Autor wies in dem Artikel darauf hin, dass der Hauptgrund dafür, dass die Genauigkeit der 3D-Objekterkennung basierend auf Tiefenschätzung viel schlechter ist als die von LiDAR-basierten Methoden, nicht darin liegt, dass die Genauigkeit der Tiefenschätzung unzureichend ist, sondern darin, dass ein Problem besteht die Datendarstellungsmethode. Erstens ist in den Bilddaten der Bereich entfernter Objekte sehr klein, was die Erkennung entfernter Objekte sehr ungenau macht. Zweitens kann der Tiefenunterschied zwischen benachbarten Pixeln sehr groß sein (z. B. am Rand eines Objekts). In diesem Fall treten bei der Verwendung von Faltungsoperationen zum Extrahieren von Merkmalen Probleme auf. Unter Berücksichtigung dieser beiden Punkte schlug der Autor vor, das Eingabebild in Punktwolkendaten umzuwandeln, die denen ähneln, die von LiDAR basierend auf der Tiefenkarte generiert werden, und dann Punktwolken- und Bildfusionsalgorithmen (wie AVOD und F-PointNet) zu verwenden 3D-Objekte erkennen. Die Pseudo-LiDAR-Methode basiert nicht auf einem spezifischen Tiefenschätzungsalgorithmus, und jede Tiefenschätzung aus einem Monokular oder Fernglas kann direkt verwendet werden. Durch diese spezielle Datendarstellungsmethode kann Pseudo-LiDAR die Genauigkeit der Objekterkennung in einer Reichweite von 30 Metern von 22 % auf 74 % steigern.

Pseudo-LiDAR
Im Vergleich zur echten LiDAR-Punktwolke weist die Pseudo-LiDAR-Methode noch eine gewisse Genauigkeit der 3D-Objekterkennung auf, die hauptsächlich auf die Tiefenschätzung zurückzuführen ist Dies wird durch unzureichende Genauigkeit verursacht (binokular ist besser als monokular), insbesondere durch den Tiefenschätzungsfehler um das Objekt herum, der einen großen Einfluss auf die Erkennung hat. Daher hat Pseudo-LiDAR seitdem auch viele Erweiterungen erfahren. Pseudo-LiDAR++ [4] nutzt Low-Wire-LiDAR, um virtuelle Punktwolken zu verbessern. Pseudo-Lidar End2End[5] verwendet Instanzsegmentierung, um den Objektrahmen in F-PointNet zu ersetzen. RefinedMPL [6] generiert nur virtuelle Punktwolken auf Vordergrundpunkten, wodurch die Anzahl der Punktwolken auf 10 % des Originals reduziert wird, wodurch die Anzahl falscher Erkennungen und der Berechnungsaufwand des Algorithmus effektiv reduziert werden können.
Wichtige Punkte und 3D-Modelle
In autonomen Fahranwendungen sind die Größe und Form vieler Ziele, die erkannt werden müssen (z. B. Fahrzeuge und Fußgänger), relativ fest und bekannt. Dieses Vorwissen kann genutzt werden, um die 3D-Informationen des Ziels abzuschätzen.
DeepMANTA[7] ist eines der Pionierwerke in dieser Richtung. Zunächst werden herkömmliche Bildobjekterkennungsalgorithmen wie Faster RNN verwendet, um den 2D-Objektrahmen zu erhalten und auch wichtige Punkte am Fahrzeug zu erkennen. Anschließend werden diese 2D-Objektrahmen und Schlüsselpunkte mit verschiedenen 3D-Fahrzeug-CAD-Modellen in der Datenbank abgeglichen und das Modell mit der höchsten Ähnlichkeit als Ausgabe der 3D-Objekterkennung ausgewählt.
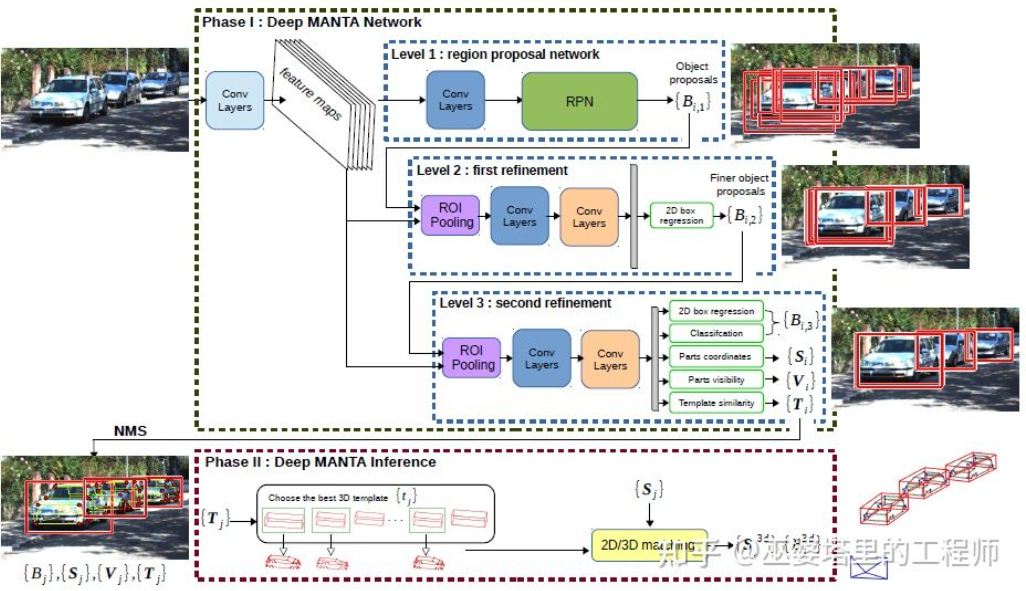
Deep MANTA
3D-RCNN [8] schlägt vor, die Inverse-Graphics-Methode zu verwenden, um die 3D-Form und Haltung jedes Ziels in der Szene basierend auf Bildern wiederherzustellen. Die Grundidee besteht darin, vom 3D-Modell des Ziels auszugehen und durch Parametersuche das Modell zu finden, das am besten zum Ziel im Bild passt. Diese 3D-Modelle verfügen normalerweise über viele Steuerparameter und einen großen Suchraum. Daher liefern herkömmliche Methoden keine guten Ergebnisse bei der Suche nach optimalen Ergebnissen in hochdimensionalen Parameterräumen. 3D-RCNN verwendet PCA, um die Dimensionalität des Parameterraums (10-D) zu reduzieren, und verwendet ein tiefes neuronales Netzwerk (R-CNN), um die niedrigdimensionalen Modellparameter jedes Ziels vorherzusagen. Die vorhergesagten Modellparameter können verwendet werden, um ein zweidimensionales Bild oder eine Tiefenkarte jedes Ziels zu erstellen, und der durch Vergleich mit den GroudTruth-Daten erhaltene Verlust kann als Leitfaden für das Lernen des neuronalen Netzwerks verwendet werden. Dieser Verlust wird als Render-and-Compare-Verlust bezeichnet und basiert auf OpenGL. Die 3D-RCNN-Methode erfordert viele Eingabedaten und das Design von Loss ist relativ komplex, was die Implementierung in der Technik erschwert.
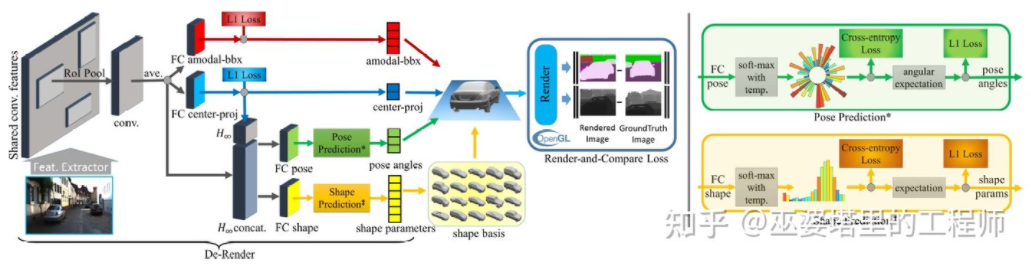
3D-RCNN
MonoGRNet [9] schlägt vor, die monokulare 3D-Objekterkennung in vier Schritte zu unterteilen, die zur Vorhersage des 2D-Objektrahmens und der Tiefe des 3D-Zentrums verwendet werden das Objekt und das 3D-Objekt. Die projizierte 2D-Position des Mittelpunkts und die 3D-Positionen der 8 Eckpunkte. Zunächst wird der vorhergesagte 2D-Objektrahmen im Bild von ROIAlign bearbeitet, um die visuellen Eigenschaften des Objekts zu erhalten. Diese Merkmale werden dann verwendet, um die Tiefe des 3D-Zentrums des Objekts und die projizierte 2D-Position des 3D-Zentrums vorherzusagen. Mit diesen beiden Informationen kann die Position des 3D-Mittelpunkts des Objekts ermittelt werden. Schließlich werden die relativen Positionen der acht Eckpunkte basierend auf der Position des 3D-Zentrums vorhergesagt. Man kann sich MonoGRNet so vorstellen, dass nur die Mitte des Objekts als Schlüsselpunkt verwendet wird und die Übereinstimmung von 2D und 3D die Berechnung des Punktabstands ist. MonoGRNetV2 [10] erweitert den Mittelpunkt auf mehrere Schlüsselpunkte und verwendet ein 3D-CAD-Objektmodell zur Tiefenschätzung, das dem zuvor eingeführten DeepMANTA und 3D-RCNN sehr ähnlich ist.
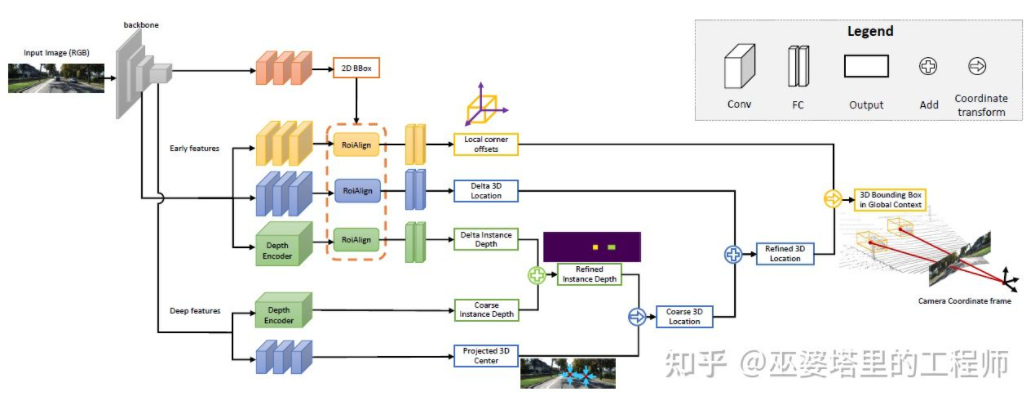
MonoGRNet
Monoloco[11] löst hauptsächlich das 3D-Erkennungsproblem von Fußgängern. Fußgänger sind nicht starre Objekte mit vielfältigeren Körperhaltungen und Verformungen, was sie zu einer größeren Herausforderung als die Fahrzeugerkennung macht. Monoloco basiert auch auf der Erkennung von Schlüsselpunkten, und die relative 3D-Position von Schlüsselpunkten kann a priori zur Tiefenschätzung verwendet werden. Beispielsweise wird der Abstand eines Fußgängers anhand der Länge von 50 Zentimetern von der Schulter des Fußgängers bis zur Hüfte geschätzt. Der Grund für die Verwendung dieser Länge als Maßstab liegt darin, dass dieser Teil des menschlichen Körpers die geringste Verformung hervorrufen kann und für die Tiefenschätzung mit der höchsten Genauigkeit verwendet werden kann. Natürlich können auch andere Schlüsselpunkte als Hilfsmittel verwendet werden, um die Aufgabe der detaillierten Schätzung zu erfüllen. Monoloco verwendet ein mehrschichtiges, vollständig verbundenes Netzwerk, um die Entfernung eines Fußgängers vom Standort wichtiger Punkte vorherzusagen und gleichzeitig die Unsicherheit der Vorhersage anzugeben.
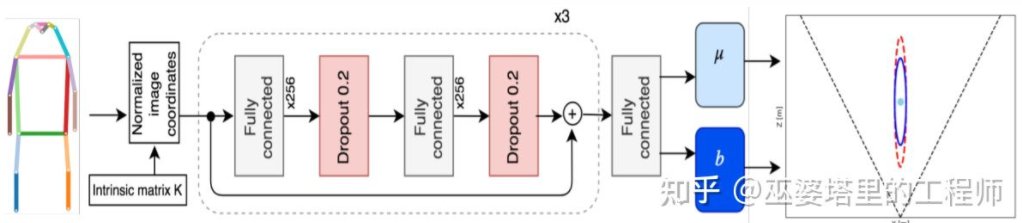
Monoloco
Zusammenfassend lässt sich sagen, dass die oben genannten Methoden Schlüsselpunkte aus 2D-Bildern extrahieren und sie mit dem 3D-Modell abgleichen, um die 3D-Informationen des Ziels zu erhalten. Bei dieser Art von Methode wird davon ausgegangen, dass das Ziel ein relativ festes Formmodell hat, was für Fahrzeuge im Allgemeinen zufriedenstellend, für Fußgänger jedoch relativ schwierig ist. Darüber hinaus erfordert diese Art von Methode die Markierung mehrerer Schlüsselpunkte auf dem 2D-Bild, was ebenfalls sehr zeitaufwändig ist.
2D/3D geometrische Einschränkungen
Deep3DBox[12] ist eine frühe und repräsentative Arbeit in dieser Richtung. Für die Darstellung des 3D-Objektrahmens sind 9-dimensionale Variablen erforderlich, nämlich Mittelpunkt, Größe und Ausrichtung (die 3D-Ausrichtung kann zu Gier vereinfacht werden, sodass sie zu einer 7-dimensionalen Variablen wird). Die Bilderkennung von 2D-Objekten kann einen 2D-Objektrahmen bereitstellen, der 4 bekannte Variablen (2D-Zentrum und 2D-Größe) enthält, was nicht ausreicht, um Variablen mit 7 oder 9 Freiheitsgraden zu lösen. Von diesen drei Gruppen von Variablen hängen Größe und Ausrichtung relativ eng mit visuellen Merkmalen zusammen. Beispielsweise hängt die 3D-Größe eines Objekts eng mit seiner Kategorie (Fußgänger, Fahrrad, Auto, Bus, LKW usw.) zusammen, und die Objektkategorie kann anhand visueller Merkmale vorhergesagt werden. Aufgrund der durch die perspektivische Projektion verursachten Mehrdeutigkeit ist es schwierig, die 3D-Position des Mittelpunkts allein anhand visueller Merkmale vorherzusagen. Daher schlägt Deep3DBox vor, zunächst Bildmerkmale innerhalb der 2D-Objektbox zu verwenden, um die Objektgröße und -ausrichtung abzuschätzen. Anschließend wird eine geometrische 2D/3D-Beschränkung verwendet, um die 3D-Position des Mittelpunkts zu ermitteln. Diese Einschränkung besteht darin, dass die Projektion des 3D-Objektrahmens auf dem Bild eng vom 2D-Objektrahmen umgeben ist, d. h. auf jeder Seite des 2D-Objektrahmens befindet sich mindestens ein Eckpunkt des 3D-Objektrahmens. Durch die zuvor vorhergesagte Größe und Ausrichtung, kombiniert mit den Kalibrierungsparametern der Kamera, kann die 3D-Position des Mittelpunkts ermittelt werden.
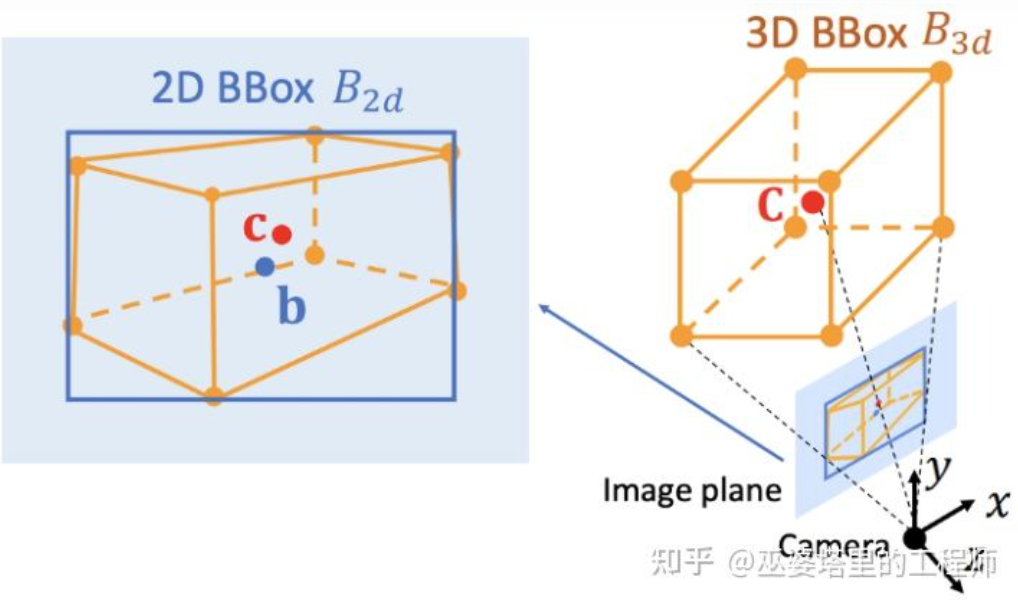
Geometrische Beschränkungen zwischen 2D- und 3D-Objektrahmen (Bild aus Referenz [9])
Diese Methode zur Verwendung von 2D/3D-Beschränkungen erfordert eine sehr genaue 2D-Objektrahmenerkennung. Im Deep3DBox-Framework kann ein kleiner Fehler im 2D-Objektrahmen dazu führen, dass die Vorhersage des 3D-Objektrahmens fehlschlägt. Die ersten beiden Stufen von Shift R-CNN [13] sind Deep3DBox sehr ähnlich. Sie sagen die 3D-Größe und -Ausrichtung anhand von 2D-Objektboxen und visuellen Merkmalen voraus und lösen dann die 3D-Position anhand geometrischer Einschränkungen. Shift R-CNN fügt jedoch eine dritte Stufe hinzu, die die in den ersten beiden Stufen erhaltenen 2D-Objektrahmen, 3D-Objektrahmen und Kameraparameter als Eingabe kombiniert und ein vollständig verbundenes Netzwerk verwendet, um eine genauere 3D-Position vorherzusagen.
Shift R-CNN
Bei Verwendung geometrischer 2D-/3D-Beschränkungen ermitteln alle oben genannten Methoden die 3D-Position des Objekts durch Lösen eines Satzes von Super-Beschränkungsgleichungen, und dieser Prozess ist als Der Nachbearbeitungsschritt liegt nicht innerhalb des neuronalen Netzwerks. Die erste und dritte Stufe von Shift R-CNN werden ebenfalls separat trainiert. MVRA [14] baute den Lösungsprozess dieser stark eingeschränkten Gleichung in ein Netzwerk ein und entwarf IoU-Verlust in Bildkoordinaten und L2-Verlust in BEV-Koordinaten, um den Fehler der Objektrahmen- bzw. Entfernungsschätzung zu messen und bei der Vervollständigung der End-to- Ausbildung beenden. Auf diese Weise wirkt sich die Qualität der 3D-Positionsvorhersage des Objekts auch auf die vorherige 3D-Größen- und Orientierungsvorhersage aus.
Generieren Sie direkt 3D-Objektrahmen
Die drei zuvor vorgestellten Methoden beginnen alle mit 2D-Bildern, einige wandeln das Bild in eine BEV-Ansicht um, andere erkennen 2D-Schlüsselpunkte und gleichen sie mit dem 3D-Modell ab, und einige geometrische Einschränkungen Verwendung von 2D- und 3D-Objektrahmen. Darüber hinaus gibt es eine andere Art von Methode, die von dichten 3D-Objektkandidaten ausgeht und alle Kandidatenrahmen anhand der Merkmale im 2D-Bild bewertet. Der Kandidatenrahmen mit einer hohen Bewertung ist die endgültige Ausgabe. Diese Strategie ähnelt in gewisser Weise der herkömmlichen Sliding-Window-Methode bei der Objekterkennung.
Mono3D[15] ist ein Vertreter dieser Art von Methode. Zunächst wird eine dichte 3D-Kandidatenbox basierend auf der vorherigen Position des Ziels (die Z-Koordinate befindet sich am Boden) und der Größe generiert. Im KITTI-Datensatz werden pro Frame etwa 40.000 (Fahrzeuge) oder 70.000 (Fußgänger und Fahrräder) Kandidatenfelder generiert. Nachdem diese 3D-Kandidatenfelder auf Bildkoordinaten projiziert wurden, werden sie anhand von Merkmalen im 2D-Bild bewertet. Diese Merkmale stammen aus semantischer Segmentierung, Instanzsegmentierung, Kontext, Form und Standort-Vorinformationen. Alle diese Merkmale werden kombiniert, um die Kandidatenfelder zu bewerten, und dann wird derjenige mit der höheren Punktzahl als endgültiger Kandidat ausgewählt. Diese Kandidaten werden dann für die nächste Bewertungsrunde durch CNN weitergeleitet, um den endgültigen 3D-Objektrahmen zu erhalten.
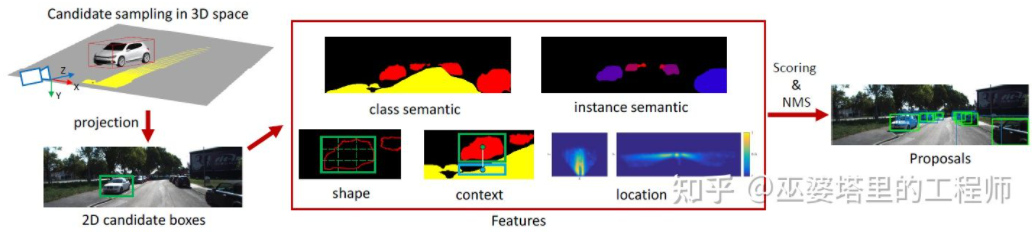
Mono3D
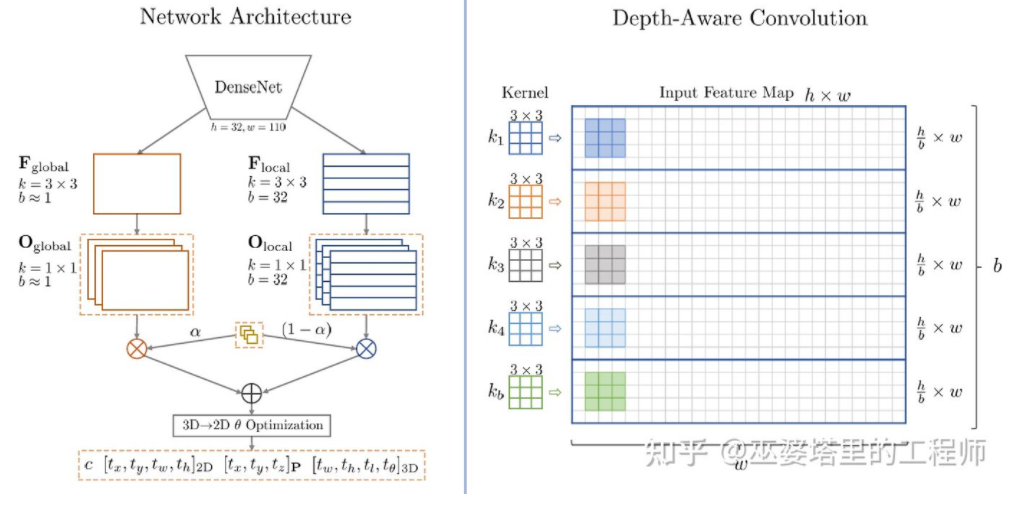
M3D-RPN[16] ist eine ankerbasierte Methode. Diese Methode definiert 2D- und 3D-Anker, die 2D- bzw. 3D-Objektrahmen darstellen. Der 2D-Anker wird durch dichtes Abtasten des Bildes erhalten, während die Parameter des 3D-Ankers auf der Grundlage von A-priori-Wissen aus den Trainingssatzdaten bestimmt werden. Insbesondere wird jeder 2D-Anker mit dem im Bild markierten 2D-Objektrahmen gemäß IoU abgeglichen und der Mittelwert des entsprechenden 3D-Objektrahmens wird zur Definition der Parameter des 3D-Ankers verwendet. Es ist erwähnenswert, dass in M3D-RPN sowohl Standardfaltungsoperationen (mit räumlicher Invarianz) als auch tiefenbewusste Faltung verwendet werden. Letzteres unterteilt die Zeilen (Y-Koordinaten) des Bildes in mehrere Gruppen. Jede Gruppe entspricht einer anderen Szenentiefe und wird von verschiedenen Faltungskernen verarbeitet. 🔜 ist immer noch Basierend auf einer dichten Stichprobe ist der Rechenaufwand sehr groß und die Praktikabilität wird stark beeinträchtigt. Einige nachfolgende Methoden schlugen vor, Erkennungsergebnisse auf zweidimensionalen Bildern zu verwenden, um den Suchraum weiter zu reduzieren.
TLNet[17] platziert Anker dicht auf der zweidimensionalen Ebene. Die Ankerabstände betragen 0,25 Meter, die Ausrichtungen betragen 0 Grad und 90 Grad und die Größe entspricht dem Durchschnitt der Ziele. Die zweidimensionalen Erkennungsergebnisse auf dem Bild bilden mehrere Betrachtungskegel im dreidimensionalen Raum. Durch diese Betrachtungskegel kann eine große Anzahl von Ankern im Hintergrund herausgefiltert werden, wodurch die Effizienz des Algorithmus verbessert wird. Der gefilterte Anker wird auf das Bild projiziert und die nach dem ROI-Pooling erhaltenen Merkmale werden verwendet, um die Parameter des 3D-Objektrahmens weiter zu verfeinern. 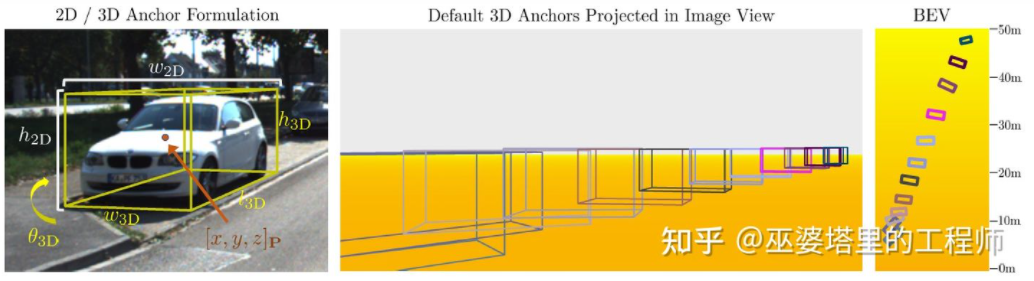
TLTNet
SS3D [18] verwendet eine effizientere einstufige Erkennung und verwendet ein Netzwerk ähnlich der CenterNet-Struktur, um verschiedene 2D- und 3D-Informationen direkt aus dem Bild auszugeben B. Objektkategorie, 2D-Objektrahmen, 3D-Objektrahmen. Es ist zu beachten, dass es sich beim 3D-Objektrahmen hier nicht um eine allgemeine 9D- oder 7D-Darstellung handelt (diese Darstellung lässt sich direkt aus dem Bild nur schwer vorhersagen), sondern um eine 2D-Darstellung, die aus dem Bild leichter vorherzusagen ist und mehr Redundanz, einschließlich der Entfernung, enthält . (1-d), Orientierung (2-d, sin und cos), Größe (3-d), Bildkoordinaten von 8 Eckpunkten (16-d). In Verbindung mit der 4D-Darstellung der 2D-Objektbox ergeben sich insgesamt 26D-Features. Alle diese Funktionen werden verwendet, um den 3D-Objektrahmen vorherzusagen. Der Vorhersageprozess besteht tatsächlich darin, einen 3D-Objektrahmen zu finden, der den 26D-Funktionen am besten entspricht. Ein besonderer Punkt ist, dass dieser Lösungsprozess innerhalb des neuronalen Netzwerks durchgeführt wird und daher differenzierbar sein muss. Dies ist auch ein wichtiges Highlight dieses Artikels. Dank der einfachen Struktur und Implementierung kann SS3D mit einer Geschwindigkeit von 20 FPS ausgeführt werden.
SS3D
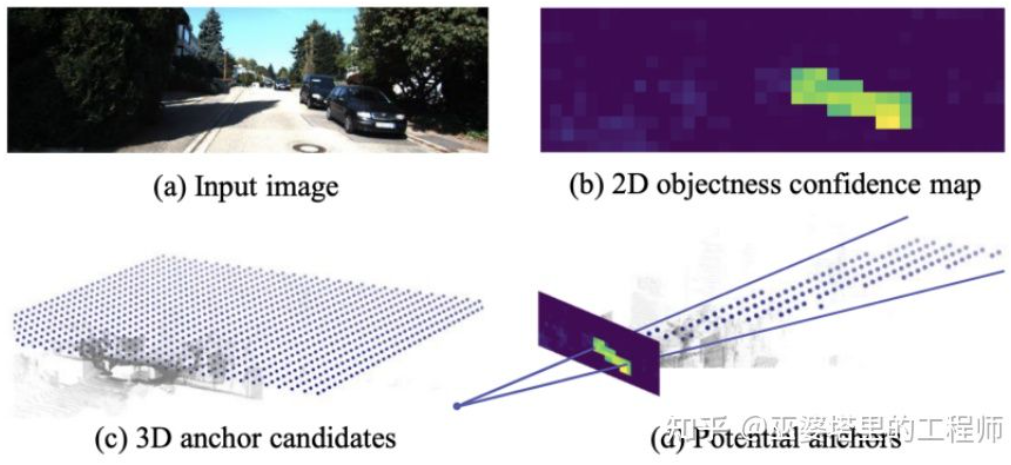
FCOS3D[19] ist ebenfalls eine einstufige Erkennungsmethode, aber prägnanter als SS3D. Die Mitte des 3D-Objektrahmens wird auf das 2D-Bild projiziert, um die 2,5D-Mitte (X, Y, Tiefe) zu erhalten, die als eines der Ziele der Regression verwendet wird. Darüber hinaus umfassen die Regressionsziele auch die 3D-Größe und -Ausrichtung. Die Ausrichtung wird hier durch die Kombination aus Winkel (0-pi) + Kurs dargestellt.
FCOS3D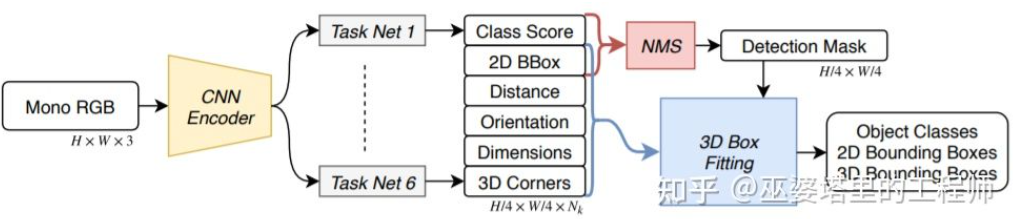
SMOKE [20] schlug ebenfalls eine ähnliche Idee vor, bei der 2D- und 3D-Informationen direkt aus Bildern über eine CenterNet-ähnliche Struktur vorhergesagt werden. Die 2D-Informationen umfassen die Projektionsposition der Schlüsselpunkte des Objekts (Mittelpunkt und Eckpunkt) auf dem Bild und die 3D-Informationen umfassen die Tiefe, Größe und Ausrichtung des Mittelpunkts. Durch die Bildposition und Tiefe des Mittelpunkts kann die 3D-Position des Objekts wiederhergestellt werden. Die 3D-Position jedes Eckpunkts kann dann durch die 3D-Größe und -Ausrichtung wiederhergestellt werden.
Die Idee der oben vorgestellten einstufigen Netzwerke besteht darin, 3D-Informationen direkt aus Bildern zurückzugeben, ohne dass eine komplexe Vorverarbeitung (z. B. Bildumkehrtransformation) und Nachbearbeitung (z. B. 3D-Modellabgleich) erforderlich ist. noch genaue geometrische Einschränkungen (z. B. kann mindestens ein Eckpunkt des 3D-Objektrahmens auf jeder Seite des 2D-Objektrahmens gefunden werden). Diese Methoden nutzen nur geringe Vorkenntnisse, etwa die durchschnittliche tatsächliche Größe verschiedener Objekttypen und die daraus resultierende Entsprechung zwischen Größe und Tiefe von 2D-Objekten. Dieses Vorwissen definiert die Anfangswerte der 3D-Parameter des Objekts, und das neuronale Netzwerk muss nur die Abweichung vom tatsächlichen Wert zurückführen, was den Suchraum erheblich reduziert und somit die Schwierigkeit des Netzwerklernens verringert.
Tiefenschätzung
Im vorherigen Abschnitt wurden die repräsentativen Methoden der monokularen 3D-Objekterkennung vorgestellt. Die Ideen reichen von der frühen Bildtransformation, dem 3D-Modellabgleich und 2D/3D-geometrischen Einschränkungen bis hin zur aktuellen direkten Bildvorhersage 3D-Informationen. Dieser Denkwandel ist größtenteils auf den Fortschritt der Faltungs-Neuronalen Netze bei der Tiefenschätzung zurückzuführen. Die meisten der zuvor eingeführten einstufigen 3D-Objekterkennungsnetzwerke umfassen einen Tiefenschätzungszweig. Die Tiefenschätzung erfolgt hier nur auf der Ebene des spärlichen Ziels und nicht auf der Ebene der dichten Pixel, ist jedoch für die Objekterkennung ausreichend.
Neben der Objekterkennung hat die autonome Fahrwahrnehmung noch eine weitere wichtige Aufgabe, nämlich die semantische Segmentierung. Der direkteste Weg, die semantische Segmentierung von 2D auf 3D zu erweitern, ist die Verwendung einer dichten Tiefenkarte, sodass die Semantik- und Tiefeninformationen jedes Pixels verfügbar sind.
Basierend auf den beiden oben genannten Punkten spielt die monokulare Tiefenschätzung eine sehr wichtige Rolle bei 3D-Wahrnehmungsaufgaben. Analog zur Einführung von 3D-Objekterkennungsmethoden im vorherigen Abschnitt können auch vollständig Faltungs-Neuronale Netze zur Schätzung dichter Tiefen verwendet werden. Im Folgenden stellen wir den aktuellen Entwicklungsstand dieser Richtung vor.
Die Eingabe der monokularen Tiefenschätzung ist ein Bild, und die Ausgabe ist ebenfalls ein Bild (im Allgemeinen in der gleichen Größe wie die Eingabe), und jeder Pixelwert darauf entspricht der Szenentiefe des Eingabebilds. Diese Aufgabe ähnelt in gewisser Weise der semantischen Bildsegmentierung, mit der Ausnahme, dass die semantische Segmentierung die semantische Klassifizierung jedes Pixels ausgibt. Natürlich kann die Eingabe auch eine Videosequenz sein, wobei zusätzliche Informationen von der Kamera oder der Objektbewegung verwendet werden, um die Genauigkeit der Tiefenschätzung zu verbessern (entsprechend der semantischen Videosegmentierung).
Wie bereits erwähnt, ist die Vorhersage von 3D-Informationen aus 2D-Bildern ein schlecht gestelltes Problem. Daher nutzen herkömmliche Methoden geometrische Informationen, Bewegungsinformationen und andere Anhaltspunkte, um die Pixeltiefe anhand von Hand entworfener Merkmale vorherzusagen. Ähnlich wie bei der semantischen Segmentierung werden häufig zwei Methoden verwendet, Superpixel (SuperPixel) und bedingtes Zufallsfeld (CRF), um die Genauigkeit der Schätzung zu verbessern. In den letzten Jahren haben tiefe neuronale Netze bei verschiedenen Bildwahrnehmungsaufgaben bahnbrechende Fortschritte gemacht, und die Tiefenschätzung ist sicherlich keine Ausnahme. Eine umfangreiche Arbeit hat gezeigt, dass tiefe neuronale Netze durch Trainingsdaten bessere Funktionen lernen können als handentworfene Funktionen. In diesem Abschnitt wird hauptsächlich diese Methode vorgestellt, die auf überwachtem Lernen basiert. Einige andere unbeaufsichtigte Lernideen, wie die Verwendung binokularer Disparitätsinformationen, monokularer Dual-Pixel-Differenzinformationen (Dual Pixel), Videobewegungsinformationen usw., werden später vorgestellt.
Eine frühe repräsentative Arbeit in dieser Richtung ist die von Eigen et al. vorgeschlagene Methode, die auf globaler und lokaler Hinweisfusion basiert. Die Mehrdeutigkeit der monokularen Tiefenschätzung ergibt sich hauptsächlich aus der globalen Skala. In dem Artikel wurde beispielsweise erwähnt, dass ein realer Raum und ein Spielzeugzimmer auf dem Bild möglicherweise sehr unterschiedlich erscheinen, die tatsächliche Schärfentiefe jedoch sehr unterschiedlich ist. Obwohl es sich hierbei um ein extremes Beispiel handelt, gibt es in realen Datensätzen immer noch Abweichungen bei den Raum- und Möbelabmessungen. Daher schlägt diese Methode vor, eine mehrschichtige Faltung und ein Downsampling des Bildes durchzuführen, um die Beschreibungsmerkmale der gesamten Szene zu erhalten und diese zur Vorhersage der globalen Tiefe zu verwenden. Anschließend wird ein weiterer lokaler Zweig (relativ höhere Auflösung) verwendet, um die Tiefe des lokalen Bildes vorherzusagen. Hier wird die globale Tiefe als Eingabe für den lokalen Zweig verwendet, um die Vorhersage der lokalen Tiefe zu unterstützen.
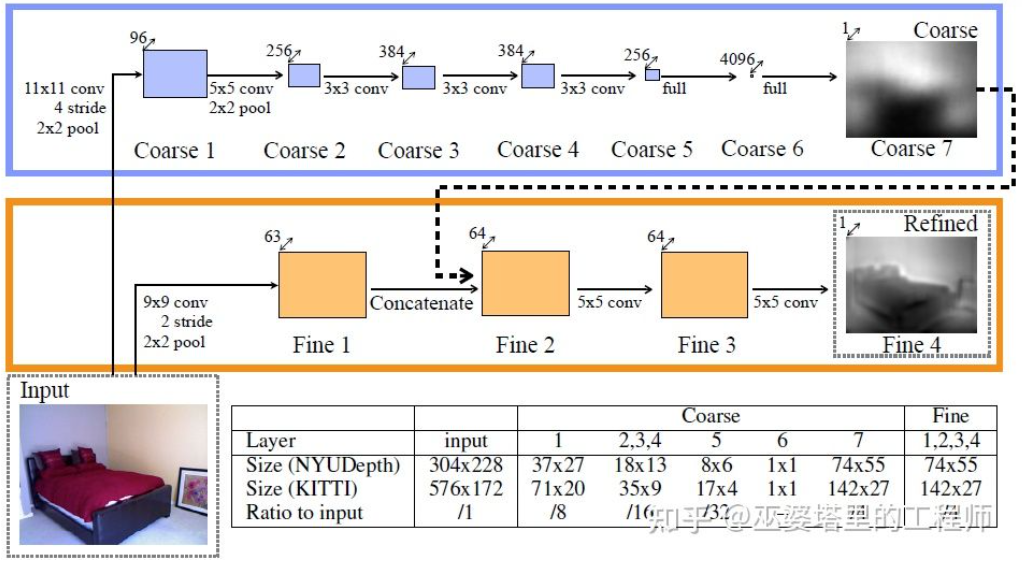
Globale und lokale Informationsfusion [21]
Literatur [22] schlägt außerdem vor, von Faltungs-Neuronalen Netzen ausgegebene Feature-Maps mit mehreren Maßstäben zu verwenden, um Tiefenkarten mit unterschiedlichen Auflösungen vorherzusagen ( Dort sind nur zwei Resolutionen in [21]). Diese Feature-Maps unterschiedlicher Auflösung werden durch kontinuierliche MRF fusioniert, um eine Tiefenkarte zu erhalten, die dem Eingabebild entspricht.
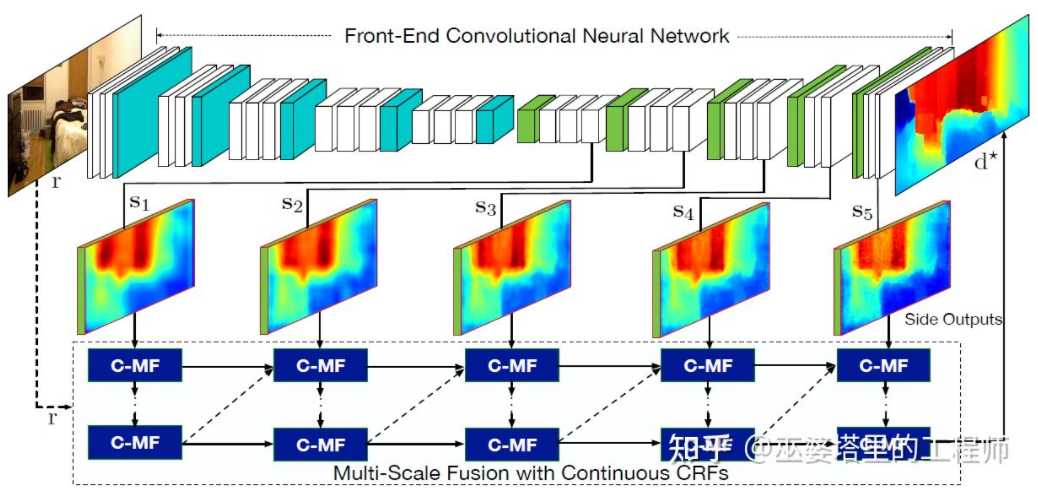
Multiskalige Informationsfusion [22]
Die beiden oben genannten Artikel verwenden Faltungs-Neuronale Netze, um Tiefenkarten zurückzugeben. Eine andere Idee besteht darin, das Regressionsproblem in ein Klassifizierungsproblem umzuwandeln Teilen Sie kontinuierliche Tiefenwerte in diskrete Intervalle auf, und jedes Intervall dient als Kategorie. Das repräsentative Werk in dieser Richtung ist DORN [23]. Das neuronale Netzwerk im DORN-Framework ist ebenfalls eine Codierungs- und Decodierungsstruktur, es gibt jedoch einige Unterschiede im Detail, z. B. die Verwendung einer vollständig verbundenen Schichtdecodierung, einer erweiterten Faltung zur Merkmalsextraktion usw.
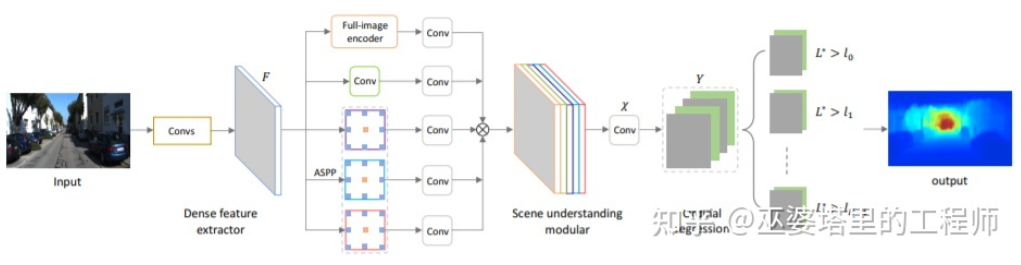
DORN-Tiefenklassifizierung
Wie bereits erwähnt, weist die Tiefenschätzung Ähnlichkeiten mit semantischen Segmentierungsaufgaben auf, sodass die Größe des Empfangsfelds auch für die Tiefenschätzung sehr wichtig ist. Zusätzlich zu den oben erwähnten Pyramidenknoten und erweiterten Windungen verfügt die kürzlich beliebte Transformer-Struktur über ein globales Empfangsfeld und ist daher für solche Aufgaben sehr gut geeignet. In der Literatur [24] wird vorgeschlagen, Transformer und Mehrskalenstrukturen zu verwenden, um gleichzeitig die lokale Genauigkeit und die globale Konsistenz der Vorhersage sicherzustellen. „Transformer für dichte Vorhersage“ Es kann eine kulare 3D-Wahrnehmung erreicht werden Nicht ganz zufriedenstellend. Insbesondere beim Einsatz von Deep-Learning-Strategien hängt die Genauigkeit des Algorithmus stark von der Größe und Qualität des Datensatzes ab. Bei Szenen, die nicht im Datensatz enthalten sind, weist der Algorithmus große Abweichungen bei der Tiefenschätzung und Objekterkennung auf.
Binokulares Sehen kann die durch die Perspektivtransformation verursachte Mehrdeutigkeit beseitigen und so theoretisch die Genauigkeit der 3D-Wahrnehmung verbessern. Allerdings stellt das Binokularsystem relativ hohe Anforderungen an Hardware und Software. Hardwareseitig sind zwei genau registrierte Kameras erforderlich, wobei die Korrektheit der Registrierung im Fahrzeugbetrieb gewährleistet sein muss. In Bezug auf die Software muss der Algorithmus Daten von zwei Kameras gleichzeitig verarbeiten. Die Berechnungskomplexität ist hoch und es ist noch schwieriger, die Echtzeitleistung des Algorithmus sicherzustellen. 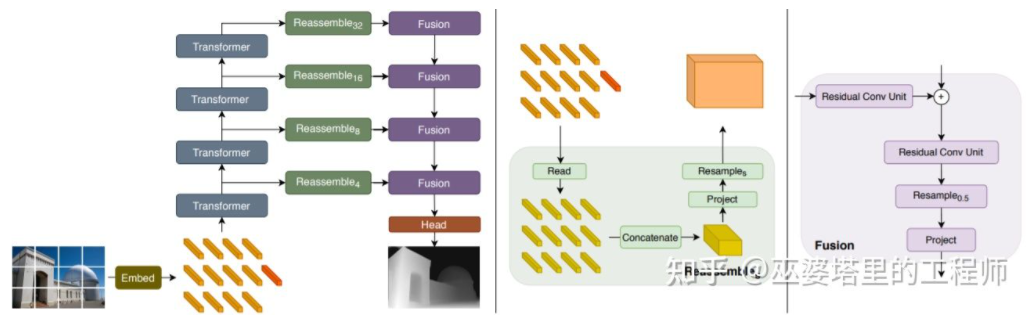
Im Allgemeinen gibt es im Vergleich zur monokularen visuellen Wahrnehmung relativ wenige Arbeiten zur binokularen visuellen Wahrnehmung. Nachfolgend werden einige typische Artikel zur Einführung ausgewählt. Darüber hinaus gibt es einige Arbeiten, die auf Mehrzweckzwecken basieren, aber auf die Systemanwendungsebene ausgerichtet sind, wie beispielsweise das 360°-Wahrnehmungssystem, das Tesla auf dem AI Day demonstriert hat. Objekterkennung
3DOP [25] verwendet zunächst Bilder von Doppelkameras, um Tiefenkarten zu erstellen, wandelt die Tiefenkarten in Punktwolken um, quantisiert sie dann in Gitterdatenstrukturen und verwendet diese als Eingabe, um 3D-Objekte zu generieren Kandidaten. Bei der Generierung von Kandidaten werden einige Intuitionen und Vorkenntnisse verwendet. Beispielsweise ist die Dichte der Punktwolke im Kandidatenfeld groß genug, die Höhe stimmt mit dem tatsächlichen Objekt überein und der Höhenunterschied zur Punktwolke außerhalb des Felds ist groß genug , und die Überlappung zwischen dem Kandidatenfeld und dem freien Speicherplatz ist ausreichend. Unter diesen Bedingungen werden schließlich etwa 2K 3D-Objektkandidaten im 3D-Raum abgetastet. Diese Kandidaten werden auf 2D-Bilder abgebildet und die Merkmalsextraktion erfolgt über ROI-Pooling, um die Objektkategorie vorherzusagen und den Objektrahmen zu verfeinern. Die hier eingegebene Bildeingabe kann ein RGB-Bild von einer Kamera oder eine Tiefenkarte sein.
Im Allgemeinen handelt es sich hierbei um eine zweistufige Erkennungsmethode. Die erste Stufe nutzt Tiefeninformationen (Punktwolke), um Objektkandidaten zu generieren, und die zweite Stufe nutzt Bildinformationen (oder Tiefe) zur weiteren Verfeinerung. Theoretisch kann die erste Stufe der Punktwolkengenerierung auch durch LiDAR ersetzt werden, daher führte der Autor experimentelle Vergleiche durch. Der Vorteil von LiDAR besteht darin, dass die Entfernungsmessung genau ist und daher bei kleinen Objekten, teilweise verdeckten Objekten und entfernten Objekten besser funktioniert. Der Vorteil des binokularen Sehens besteht darin, dass die Punktwolkendichte hoch ist, sodass es besser funktioniert, wenn im Nahbereich weniger Hindernisse vorhanden sind und das Objekt relativ groß ist. Ohne Berücksichtigung der Kosten und der Rechenkomplexität werden natürlich die besten Ergebnisse durch die Integration beider erzielt.
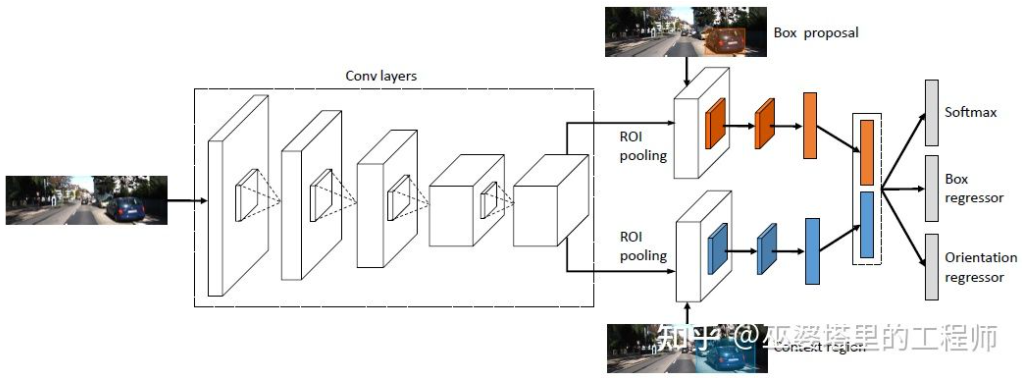
3DOP
3DOP hat eine ähnliche Idee wie Pseudo-LiDAR[3], das im vorherigen Abschnitt vorgestellt wurde und dichte Tiefenkarten (von monokularem, binokularem und sogar Low-Line-LiDAR) kombiniert In eine Punktwolke umgewandelt und dann Algorithmen im Bereich der Punktwolkenobjekterkennung angewendet.
Schätzen Sie die Tiefenkarte aus dem Bild, generieren Sie dann die Punktwolke aus der Tiefenkarte und wenden Sie schließlich den Punktwolken-Objekterkennungsalgorithmus an. Jeder Schritt dieses Prozesses wird separat durchgeführt, ein End-to-End-Training ist nicht erforderlich möglich. DSGN [26] schlug einen einstufigen Algorithmus vor, der ausgehend vom linken und rechten Bild eine Zwischendarstellung wie Plane-Sweep Volume verwendet, um eine 3D-Darstellung in der BEV-Ansicht zu generieren und gleichzeitig Tiefenschätzung und Objekterkennung durchzuführen. Alle Schritte dieses Prozesses sind differenzierbar und können daher durchgängig trainiert werden.
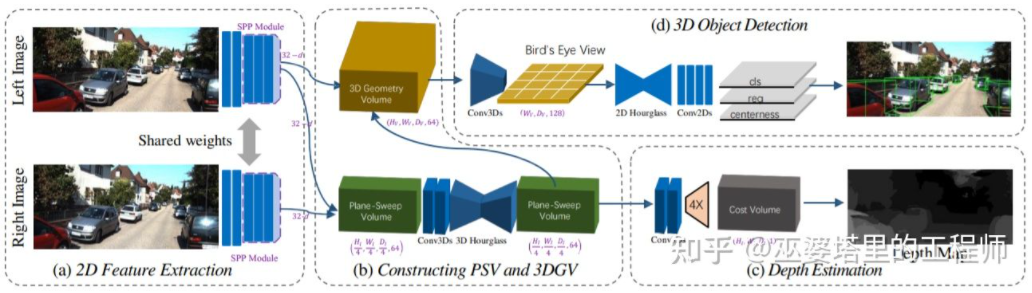
DSGN
Die Tiefenkarte ist eine dichte Darstellung. Tatsächlich ist es für das Objektlernen nicht notwendig, Tiefeninformationen an allen Positionen in der Szene zu erhalten, sondern nur an der Es reicht aus, die Position des Objekts abzuschätzen. Ähnliche Ideen wurden bereits bei der Einführung des monokularen Algorithmus erwähnt. Stereo R-CNN [27] schätzt die Tiefenkarte nicht, sondern stapelt die Feature-Maps von zwei Kameras im Rahmen von RPN, um Objektkandidaten zu generieren. Der Schlüssel zur Verknüpfung der Informationen der linken und rechten Kamera liegt hier in der Änderung der Anmerkungsdaten. Wie in der Abbildung unten gezeigt, wird zusätzlich zu den linken und rechten Beschriftungsfeldern auch eine Vereinigung der linken und rechten Beschriftungsfelder hinzugefügt. Ein Anker, dessen IoU mit der linken oder rechten Box 0,7 überschreitet, wird als positive Stichprobe verwendet, und ein Anker, dessen IoU mit der Union-Box kleiner als 0,3 ist, wird als negative Stichprobe verwendet. Der Anker von Positive gibt gleichzeitig die Position und Größe des linken und rechten Beschriftungsfelds zurück. Bei dieser Methode werden neben dem Objektrahmen auch Eckpunkte als Hilfsmittel verwendet. Mit all diesen Informationen kann der 3D-Objektrahmen wiederhergestellt werden.
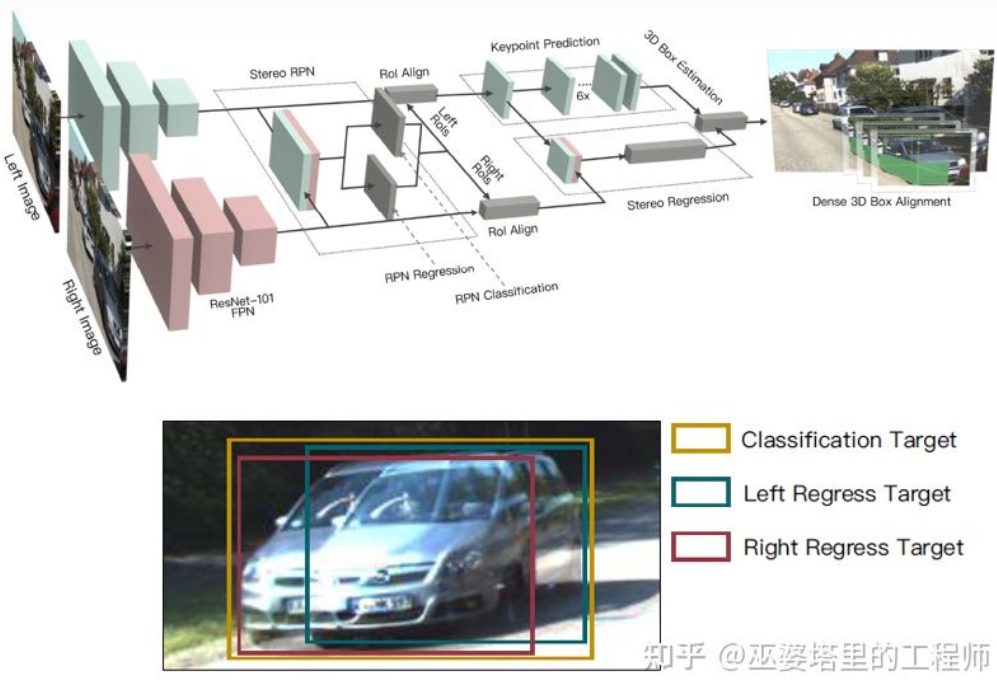
Stereo R-CNN
führt eine dichte Tiefenschätzung für die gesamte Szene durch, was sich sogar negativ auf die Objekterkennung auswirken kann. Aufgrund der Überlappung der Objektkante mit dem Hintergrund ist die Abweichung der Tiefenschätzung beispielsweise groß, und der große Tiefenbereich der gesamten Szene wirkt sich auch auf die Geschwindigkeit des Algorithmus aus. Daher wird in [28] ähnlich wie bei Stereo RCNN auch vorgeschlagen, die Tiefe nur am interessierenden Objekt abzuschätzen und nur Punktwolken auf dem Objekt zu erzeugen. Diese objektzentrierten Punktwolken werden schließlich verwendet, um die 3D-Informationen des Objekts vorherzusagen. „Objektzentriertes Stereo-Matching“ Ausgehend von der Einführung in die binokulare Objekterkennung im vorherigen Abschnitt verwenden viele Algorithmen eine Tiefenschätzung, einschließlich der Tiefenschätzung auf Szenenebene und der Tiefenschätzung auf Objektebene. Im Folgenden finden Sie einen kurzen Überblick über die Grundprinzipien der binokularen Tiefenschätzung sowie mehrere repräsentative Arbeiten.
Das Prinzip der binokularen Tiefenschätzung ist eigentlich sehr einfach, nämlich basierend auf dem Abstand d zwischen demselben 3D-Punkt auf dem linken und rechten Bild (vorausgesetzt, dass die beiden Kameras die gleiche Höhe beibehalten, also nur der Abstand in Die horizontale Richtung wird berücksichtigt), die Kamera Die Brennweite f und der Abstand B (Basislinienlänge) zwischen den beiden Kameras, um die Tiefe des 3D-Punkts abzuschätzen. 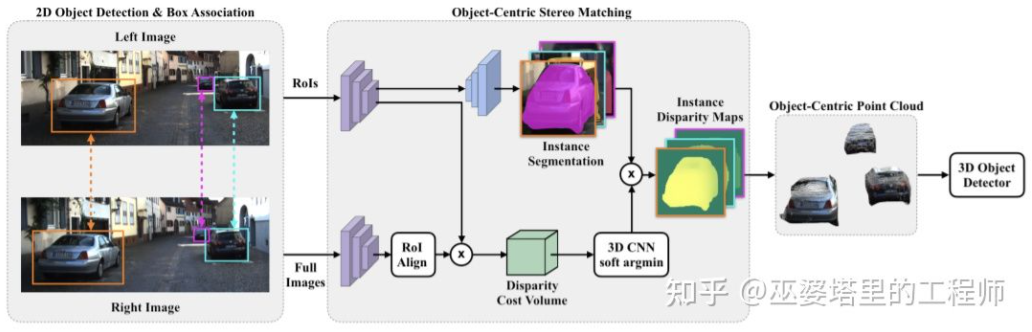
Im binokularen System sind f und B fest, sodass nur die Entfernung d, also die Parallaxe, geschätzt werden muss. Für jedes Pixel müssen Sie lediglich den passenden Punkt im anderen Bild finden. Der Bereich der Entfernung d ist begrenzt, daher ist auch der passende Suchbereich begrenzt. Für jedes mögliche d kann der Übereinstimmungsfehler an jedem Pixel berechnet werden, sodass dreidimensionale Fehlerdaten erhalten werden, die als Kostenvolumen bezeichnet werden. Bei der Berechnung des Übereinstimmungsfehlers wird im Allgemeinen der lokale Bereich in der Nähe des Pixels berücksichtigt. Eine der einfachsten Methoden besteht darin, die Differenzen aller entsprechenden Pixelwerte im lokalen Bereich zu summieren: 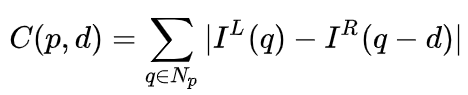

MC-CNN [29] formalisiert den Matching-Prozess als Berechnung der Ähnlichkeit zweier Bildfelder und lernt die Eigenschaften der Bildfelder über ein neuronales Netzwerk. Durch die Kennzeichnung der Daten kann ein Trainingssatz erstellt werden. An jedem Pixel werden ein positives Sample und ein negatives Sample erzeugt, wobei jedes Sample ein Paar Bildfelder darstellt. Die positiven Proben sind zwei Bildblöcke vom selben 3D-Punkt (gleiche Tiefe), und die negativen Proben sind Bildblöcke von verschiedenen 3D-Punkten (unterschiedliche Tiefen). Es gibt viele Möglichkeiten für negative Proben. Um ein Gleichgewicht zwischen positiven und negativen Proben aufrechtzuerhalten, wird nur eine zufällig ausgewählt. Mit positiven und negativen Proben kann ein neuronales Netzwerk trainiert werden, um Ähnlichkeiten vorherzusagen. Die Kernidee besteht darin, Überwachungssignale zu verwenden, um das neuronale Netzwerk beim Erlernen von Bildmerkmalen anzuleiten, die für Matching-Aufgaben geeignet sind.
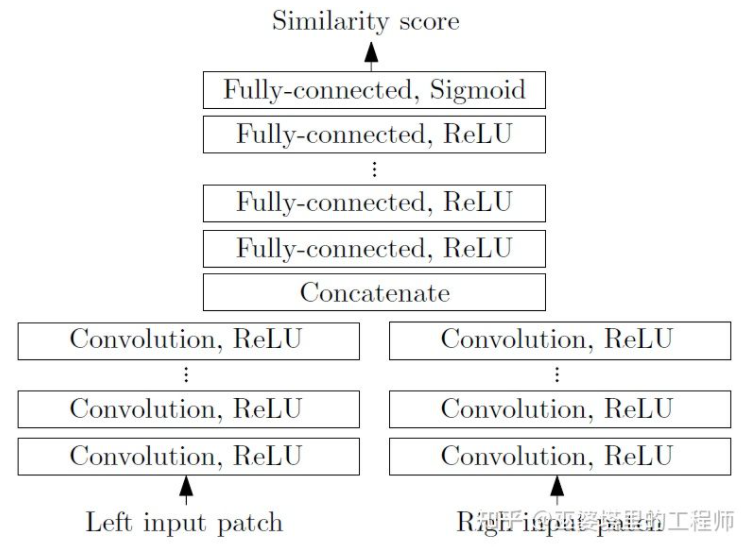
MC-CNN
MC-Net weist hauptsächlich zwei Mängel auf: 1) Die Berechnung des Kostenvolumens basiert auf lokalen Bildblöcken, die bei einigen Texturen mit weniger Textur oder wiederholt auftreten können Muster Der Bereich wird große Fehler mit sich bringen; 2) Die Nachbearbeitungsschritte basieren auf manuellem Design, was viel Zeit in Anspruch nimmt und es schwierig ist, die Optimalität sicherzustellen. GC-Net[30] hat diese beiden Punkte verbessert. Zunächst werden mehrschichtige Faltungs- und Downsampling-Operationen an den linken und rechten Bildern durchgeführt, um semantische Merkmale besser zu extrahieren. Für jede Disparitätsstufe (in Pixel) werden die linken und rechten Feature-Maps ausgerichtet (Pixelversatz) und dann gespleißt, um die Feature-Map dieser Disparitätsstufe zu erhalten. Die Feature-Maps aller Disparitätsstufen werden zusammengeführt, um das 4D-Kostenvolumen (Höhe, Breite, Disparität, Features) zu erhalten. Cost Volume enthält nur Informationen aus einem einzelnen Bild und es gibt keine Interaktion zwischen Bildern. Daher besteht der nächste Schritt darin, das Kostenvolumen mithilfe der 3D-Faltung zu verarbeiten, sodass die relevanten Informationen zwischen den linken und rechten Bildern und die Informationen zwischen verschiedenen Disparitätsniveaus gleichzeitig extrahiert werden können. Die Ausgabe dieses Schritts ist das 3D-Kostenvolumen (Höhe, Breite, Parallaxe). Schließlich müssen wir Argmin in der Disparitätsdimension finden, um den optimalen Disparitätswert zu erhalten, aber das Standard-Argmin kann nicht abgeleitet werden. Soft Argmin wird in GC-Net verwendet, um das Ableitungsproblem zu lösen, sodass das gesamte Netzwerk durchgängig trainiert werden kann.
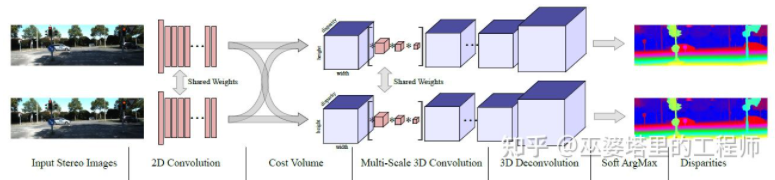
GC-Net
PSMNet [31] ist GC-Net in seiner Struktur sehr ähnlich, wurde jedoch in zwei Aspekten verbessert: 1) Verwendung einer Pyramidenstruktur und atroöser Faltung zum Extrahieren Informationen mit mehreren Auflösungen und erweitern das Empfangsfeld. Dank der Verschmelzung globaler und lokaler Merkmale ist auch die Schätzung des Kostenvolumens genauer. 2) Verwenden Sie mehrere überlagerte Sanduhrstrukturen, um die 3D-Faltung zu verbessern. Die Nutzung globaler Informationen wird weiter verbessert. Im Allgemeinen hat PSMNet Verbesserungen bei der Nutzung globaler Informationen erzielt, wodurch die Disparitätsschätzung stärker von Kontextinformationen in verschiedenen Maßstäben abhängig ist als von lokalen Informationen auf Pixelebene.
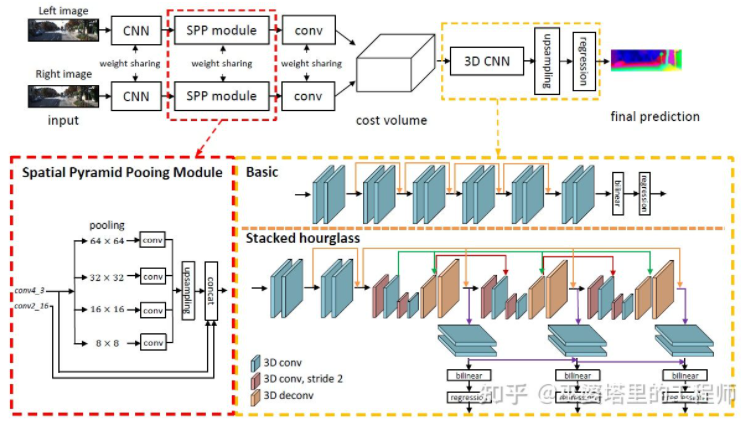
PSMNet
Im Kostenvolumen ist das Disparitätsniveau diskret (in Pixeln). Was das neuronale Netzwerk lernt, ist die Kostenverteilung an diesen diskreten Punkten, und die Extrempunkte der Verteilung entsprechen dem Disparitätswert am aktuellen Standort. Allerdings sollte der Parallaxenwert (Tiefe) tatsächlich kontinuierlich sein, und die Verwendung diskreter Punkte zu seiner Schätzung führt zu Fehlern. Das Konzept der kontinuierlichen Schätzung wird im CDN [32] vorgeschlagen. Zusätzlich zur Verteilung diskreter Punkte wird auch der Versatz an jedem Punkt geschätzt. Die diskreten Punkte und Offsets bilden zusammen eine kontinuierliche Disparitätsschätzung.
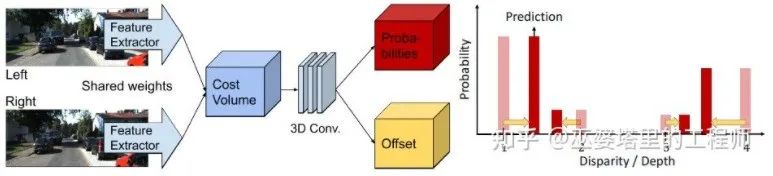
CDN
Das obige ist der detaillierte Inhalt vonEine ausführliche Interpretation des visuellen 3D-Wahrnehmungsalgorithmus für autonomes Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr