
Heim >Datenbank >MySQL-Tutorial >In welchen Situationen ist MySQL nicht zum Erstellen von Indizes geeignet und es kommt zu Indexfehlern?
In welchen Situationen ist MySQL nicht zum Erstellen von Indizes geeignet und es kommt zu Indexfehlern?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-02 13:28:121888Durchsuche
Fazit
Spezifische Fälle werden im Folgenden ausführlich beschrieben
Szenarien, die nicht für die Indizierung geeignet sind:
Es wird nicht empfohlen, Indizes für Tabellen mit kleinen Datenmengen zu erstellen.
Es wird nicht empfohlen, Indizes für zu erstellen Felder mit einer großen Menge doppelter Daten (ähnlich: Feld „Geschlecht“)
Es wird nicht empfohlen, einen Index für Tabellen zu erstellen, die häufig aktualisiert werden müssen.
Unbenutzte Felder nach „wo“, „gruppieren nach“, „ordnen nach“ sind nicht indiziert
Definieren Sie keine redundanten Indizes
Szenario eines Indexfehlers:
Die verwendete Filterbedingung ist nicht gleich (!=, )
Die verwendete Filterbedingung ist nicht null
Verwenden Sie Funktionen oder Berechnungen für das Indexfeld
Wenn Sie einen gemeinsamen Index verwenden, müssen Sie die „Best-Left-Prefix-Regel“ erfüllen, andernfalls ist er ungültig
Wenn die Typkonvertierung erfolgt Wird der Index verwendet, ist er ebenfalls ungültig.
Bei Verwendung von Bereichsabfragen wird der gemeinsame Indexteil ungültig gemacht (wobei das Alter >18 beträgt).
Wenn das Feld „Gefällt mir“ mit % beginnt, ist der Index ungültig (wobei der Name „%abc“ lautet)
Bei Verwendung von oder zum Abfragen werden Vorher- und Nachher-Felder oder Nicht-Indexfelder angezeigt, und der Index wird ungültig. Die Zeichensätze der Tabelle und der Bibliothek sind inkonsistent, was dazu führt Wissenspunkte:
Es wird nicht empfohlen, mehr als 6 Indizes für jede Tabelle zu haben (dies nimmt Platz ein und verringert die Aktualisierungsgeschwindigkeit)
Am Ende ist es so entschieden, ob der Index oder der Optimierer verwendet werden soll
Der Optimierer vergleicht die Abfragekosten basierend auf dem Datenvolumen, der Datenbankversion und der gelesenen Datenauswahl und entscheidet dann, ob der Index verwendet werden soll
Beim Erstellen eines Indexes Legen Sie am Ende des Index die Felder fest, die einen Bereichsabgleich erfordern, und legen Sie beim Erstellen der Tabelle einen Standardwert fest. Dies kann verwendet werden, wenn Sie Datensätze ohne Werte suchen müssen = Standardwert, die Verwendung ist nicht null, um einen Indexfehler zu verursachen
Bei der Suche auf der Seite verwenden Sie bitte den Links- oder Volltext-Fuzzy-Matching (wie „%abc“)
Für eine bessere Filterung der Felder vor dem Gemeinsamer Index, auf diese Weise können Sie zuerst mehr Daten filtern
Es wird nicht empfohlen, ein Indexszenario zu erstellen
Szenario 1: Tabelle mit weniger DatenWenn die Daten relativ klein sind, ist der Vorteil des Index nicht offensichtlich Da die Speicher-Engine der Datenbank auch sehr schnell ist, verglichen mit der Notwendigkeit, den Index vor dem Ausführen des Tabellenrückgabevorgangs abzufragen, ist die Leistung der direkten Abfrage möglicherweise höher. Daher wird nicht empfohlen, einen Index für relativ kleine Tabellen zu erstellen Daten
Szenario 2: Ja Felder mit einer großen Menge wiederholter Daten ähneln den Geschlechtsfeldern. Es gibt nur zwei unterschiedliche Werte „männlich“ und „weiblich“. männlich“ und die Hälfte der Daten ist „weiblich“. Dann kann die Indizierung nicht schnell durchgeführt werden. Abfrage usw., daher wird nicht empfohlen, Indizes für Spalten mit einer großen Menge doppelter Daten zu erstellenSzenario 3: Häufig aktualisierte Tabellen ( (aktualisieren/löschen/einfügen)
Denn wenn Daten in der Tabelle aktualisiert werden, muss auch der Index entsprechend gepflegt werden. Ja, wenn eine Tabelle in naher Zukunft häufig hinzugefügt, gelöscht und geändert werden muss, wird dies viel Zeit in Anspruch nehmen Es wird nicht empfohlen, einen Index zu erstellen, wenn häufige Aktualisierungsvorgänge erforderlich sind, und den Index nach Abschluss der Aktualisierung neu zu erstellen
Szenario 4: Nicht verwendete Felder (wo/gruppieren nach/Reihenfolge). by)
Es besteht keine Notwendigkeit, einen Index für Felder zu erstellen, die nicht „wo/gruppieren nach/sortieren nach“ sind, da der Index nicht verwendet wird
Szenario 5: Definieren Sie keinen redundanten verbleibenden Index
create index username_password_address on xiao(username,password,address); -- 如果建立了第一个索引,那么就没有必要建立第二个索引 create index username on xiao (username); --第二个索引就是冗余索引,因为第一个已经是先根据username排序的索引 --也就是第二个索引的功能完全可以由第一个索引实现
Hier, weil Benutzername ist das erste Feld des ersten gemeinsamen Index. Wenn der Benutzername identisch ist, wird er nach Passwort und Adresse sortiert, sodass klar ist, dass nur die Spalte „Benutzername“ als Funktion des Index verwendet wird. Das heißt, der zweite Index ist überflüssig
Szenario eines Indexfehlers
Szenario 1: Durchführen von Operationen (Funktionen usw.) für die indizierten Felder, was zu einem Indexfehler führt
Hier wird der Index zuerst für das Alter erstellt Der Index wurde bei der ersten Abfrage verwendet, aber der zweite Schlüsselwert war null (Indexfehler). Der Grund für den Indexfehler war, dass das Alter bei der zweiten Abfrage berechnet wurde und der Computer nicht wusste, welche Berechnung durchgeführt wurde , daher wird age+1 berechnet und mit 1 verglichen, und der Index wird ungültig, wenn man die Funktion concat() für ein Feld usw. verwendet. Dies führt dazu, dass der Index ungültig wird to (where age != 18)
Bei Verwendung äquivalenter Operationen können Sie im Index suchen. Wenn dieser jedoch nicht gleich ist, müssen Sie alle Daten durchlaufen, sodass sie ungültig sind
explain select * from xiaoyuanhao where age = 18; explain select * from xiaoyuanhao where age != 18; --这里是在age字段上建立了普通索引,第二个查询时候索引失效
Szenario 3: Die Verwendung erfolgt nicht Null-Index ist ungültig
Dasselbe wie „ungleich“ wenn er nicht null ist, müssen alle Daten durchlaufen werden und der Index wird ungültig. Wenn jedoch null verwendet wird, kann der Index weiterhin verwendet werden
--这里是在age字段上建立了普通索引,第二个查询时候索引失效 explain select * from xiaoyuanhao where age is null; --可以正常使用索引 explain select * from xiaoyuanhao where age is not null; --索引失效
Szenario 4: Bei Verwendung der optimalen linken Präfixregel wird bei der gemeinsamen Indizierung nicht befolgt
CREATE INDEX age_classid_name ON student(age,classId,NAME); EXPLAIN SELECT * FROM student WHERE classId = 30 AND NAME = 'xiaoyuanhao'; -- 因为没有使用age字段,所以没有准许最佳左前缀原则,索引失效
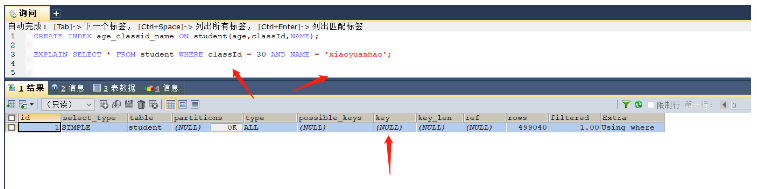
从这里可以看出是没有使用索引的(key = null),因为创建的索引是先按照age进行排序,在age相同的情况下按照classId和name排序,如果在查询的时候需要直接按照classId进行排序查找,那么就无法使用该索引,即索引失效。
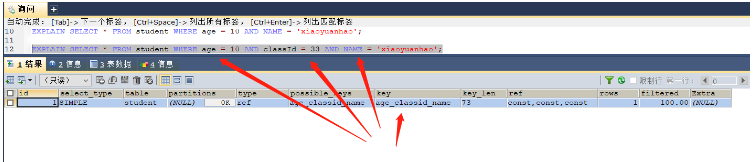
如果需要使用使用索引,那么就一定需要到联合索引的第一个字段age,案例如下
EXPLAIN SELECT * FROM student WHERE age = 10 AND NAME = 'xiaoyuanhao'; EXPLAIN SELECT * FROM student WHERE age = 10 AND classId = 33 AND NAME = 'xiaoyuanhao'; --两者都是使用age字段索引,所以索引有效

场景五:类型转换导致索引失效
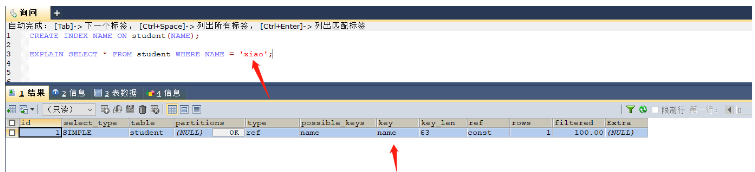
CREATE INDEX NAME ON student(NAME); -- 这里的name字段是varchar类型 EXPLAIN SELECT * FROM student WHERE NAME = 'xiao'; -- 本次查询是可以使用索引的,因为类型都是一致的,都是字符串 EXPLAIN SELECT * FROM student WHERE NAME = 123; -- 本次查询则无法使用索引,因为是将数字类型123转换为字符类型
没有发生类型转换,使用索引key = name
发生了类型转换,无法使用索引kye = null,索引失效
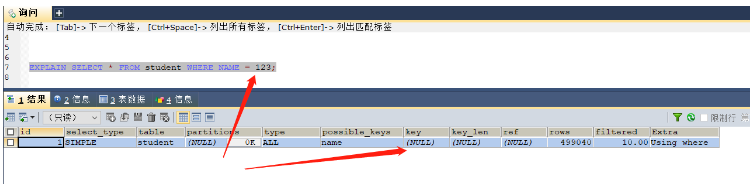
使用索引的时候一定需要保证数据类型是一致的,否则系统就需要进行转换,那么就无法使用索引
场景六:使用范围查询导致联合索引其他字段失效
create index age_classId_name on student (age,classId,name); EXPLAIN SELECT * FROM student WHERE age = 10 AND classId > 20 AND NAME = 'xiaoyuanhao'; -- 这里只能使用age,classId,索引的前两个字段 EXPLAIN SELECT * FROM student WHERE age = 10 AND classId = 20 AND NAME = 'xiaoyuanhao'; -- 这里可以使用完整的索引,因为都是等值连接
在classId字段上使用范围查询,导致name字段失效,有效索引长度为63

使用的都是等值匹配,整个索引皆可用,有效索引长度为73

也就是在对于联合索引来说,如果在使用的时候是等值匹配,那么就可以重复的利用索引,如果不是等值匹配,那么该字段也是可以使用索引的,但是该字段右边的字段就将失效
建议在建立索引的时候将需要范围匹配的字段建立在索引的最后面
场景七:在使用like的时候,如果以%开头导致索引失效
EXPLAIN SELECT * FROM student WHERE NAME LIKE 'abc%'; -- 可以正常使用索引 EXPLAIN SELECT * FROM student WHERE NAME LIKE '%abc'; -- 这里在like中,%在前面无法使用索引
key = name,使用了该索引,索引有效
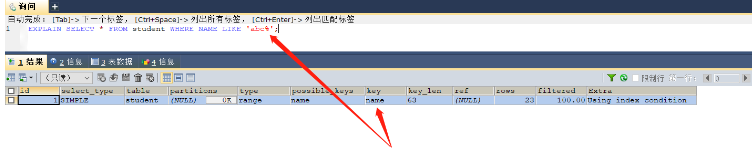
key = null,索引失效

因为建立的索引实际上是按照整个字符串的从第一个开始进行比较排序的,所以在使用like的时候,也只能够重现进行比较,如果使用的是’%abc’,那么查询的就是以abc结尾的数据,无法使用索引
场景八:or前后出现非索引字段,索引失效
-- 该表中只有name字段上的索引 CREATE INDEX NAME ON student(NAME); EXPLAIN SELECT * FROM student WHERE NAME = 'xiao'; -- 这里是可以使用name索引的 EXPLAIN SELECT * FROM student WHERE NAME = 'xiao' OR classId = 1001; -- 这个则无法使用索引,进行的是全表扫描
key = null,无法使用索引,or条件中出现非索引字段
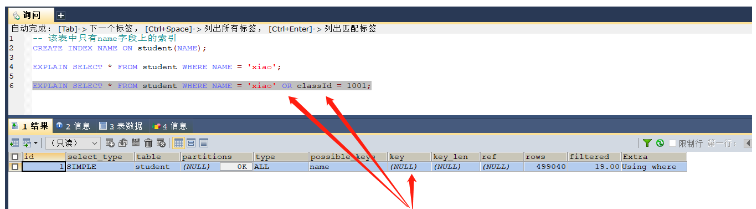
因为如果name不等于’xiao’的时候那么就会继续判断classId是否等于1001,那么实际上还是会进行全表扫描,所以索引失效(也就是进行name判断的时候可以使用索引,但是在判断classId的时候又要全表扫描,那么优化器就直接进行全表扫描),但是如果or前后的字段都有索引了,那么就就会使用索引
Das obige ist der detaillierte Inhalt vonIn welchen Situationen ist MySQL nicht zum Erstellen von Indizes geeignet und es kommt zu Indexfehlern?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!