
Heim >Datenbank >MySQL-Tutorial >So lösen Sie das Duplizierungsproblem in MySQL mithilfe einer Left-Join-Verbindung
So lösen Sie das Duplizierungsproblem in MySQL mithilfe einer Left-Join-Verbindung

- 王林nach vorne
- 2023-06-02 13:13:412913Durchsuche
Duplikate treten auf, wenn MySQL eine Left-Join-Verbindung verwendet.
Problembeschreibung: Wenn Sie eine Join-Abfrage verwenden, z. B. Tabelle A als Haupttabelle und Left-Join-Tabelle B verwenden, erwarten wir, wie viele Datensätze darin enthalten sind Tabelle A, Abfrage Das Ergebnis wird so viele Datensätze wie vorhanden sein, aber es kann ein Ergebnis wie dieses geben, das heißt, die Gesamtzahl der abgefragten Datensätze ist größer als die Gesamtzahl der Datensätze in Tabelle A, und einige Spalten werden wiederholt Wenn die Abfrageergebnisse angezeigt werden, wird einfach das kartesische Produkt erstellt.
Beispiel für ein Problem
Tabelle A ist die Benutzertabelle (Benutzer) und die Felder sind:
ID-Name Benutzer-ID1 aaaa 10001ID Titelzeit Benutzer-ID2 bbbb 10002
Tabelle B ist der erste Typ von Produkttabelle (Produkt), die Felder sind:
3 ccccc 10003
1 Titel 1 2014-01-01 100022 Titel 2 2014-01-01 10002
Als wir zu diesem Zeitpunkt die folgende SQL zur Ausführung verwendeten, stellten wir fest, dass
3 Titel 3 2014-01-01 10001
4 Titel 4 2018-03-20 10002
5 Titel 5 2018-03-20 10003
selecct * from user left join product on user.userid=product.userid;
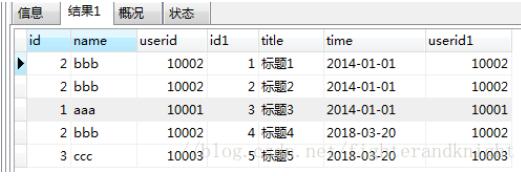 Das Ausführungsergebnis höher war als die Gesamtsumme Anzahl der Datensätze in der Benutzertabelle
Das Ausführungsergebnis höher war als die Gesamtsumme Anzahl der Datensätze in der Benutzertabelle
Problem gelöst
Tatsächlich kann dieses Problem von einem anspruchsvollen Auge auf einen Blick erkannt werden, da das linke Join-Schlüsselwort in der Produkttabelle nicht eindeutig ist, sodass dieser Teil der nicht eindeutigen Daten ist erzeugt ein kartesisches Produkt, was zu mehr Ausführungsergebnissen als erwartet führt.
Die Lösung besteht darin, eindeutige Schlüssel zu verwenden, um Verknüpfungsabfragen zuzuordnen und durchzuführen.
Wenn MySQL Left Join verwendet, weisen die Daten in der rechten Tabelle doppelte Daten auf.
Das Schlüsselwort LEFT JOIN gibt alle Zeilen aus der linken Tabelle (Tabellenname1) zurück. Auch wenn es in der richtigen Tabelle (table_name2) keine passenden Zeilen gibt. Zu diesem Zeitpunkt gibt es kein Problem, wenn die rechte Tabelle (table_name2) keine Daten oder nur ein Datenelement enthält, nachdem sie mit dem Schlüsselwort on gefiltert wurde.
Was ich sagen möchte, ist, was zu tun ist, wenn in der richtigen Tabelle (Tabellenname2) doppelte Daten (vollständige Duplizierung im Geschäft) vorhanden sind.
Wenn nach dem Filtern mit dem Schlüsselwort „on“ doppelte Daten in der rechten Tabelle (Tabellenname2) angezeigt werden, sind die zu diesem Zeitpunkt gefundenen Daten: Daten der rechten Tabelle * doppelte Daten + andere bedingte Daten in der rechten Tabelle und die Anzahl der Daten wir brauchen anders.
Meine Lösung besteht darin, zuerst die richtige Tabelle (table_name2) gemäß der Filterfeldgruppierung abzufragen, dieselben Daten herauszufiltern und dann das Ergebnis als die richtige Tabelle für die Zuordnung zu behandeln
前面脑补 LEFT JOIN (SELECT MODEL_CODE,MODEL_NAME from tm_model GROUP BY MODEL_CODE) tm on tav.model_code = tm.MODEL_CODE 后面脑补
Das obige ist der detaillierte Inhalt vonSo lösen Sie das Duplizierungsproblem in MySQL mithilfe einer Left-Join-Verbindung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!