
Wie läuft die Verarbeitung von Redis-Anfragen ab?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-01 20:49:471166Durchsuche
Übersicht#
Das erste, was Sie tun müssen, ist, den Prozessor zu registrieren.
Öffnen Sie den Loop-Listening-Port. Jedes Mal, wenn eine Verbindung überwacht wird, wird eine Goroutine erstellt Schleife, um die Anforderungsdaten zu empfangen, und passen Sie dann den entsprechenden Prozessor in der Prozessor-Routing-Tabelle entsprechend der angeforderten Adresse an und übergeben Sie die Anforderung dann zur Verarbeitung an den Prozessor.
-
Der Code lautet wie folgt:
func (srv *Server) Serve(l net.Listener) error { ... baseCtx := context.Background() ctx := context.WithValue(baseCtx, ServerContextKey, srv) for { // 接收 listener 过来的网络连接 rw, err := l.Accept() ... tempDelay = 0 c := srv.newConn(rw) c.setState(c.rwc, StateNew) // 创建协程处理连接 go c.serve(connCtx) } } Bei Redis ist dies etwas anders, da es Single-Threaded ist und kein Multithreading zum Verarbeiten von Verbindungen verwenden kann. Daher entscheidet sich Redis für die Verwendung eines Ereignistreibers basierend auf dem Reactor-Modus, um die gleichzeitige Verarbeitung von Ereignissen zu implementieren.
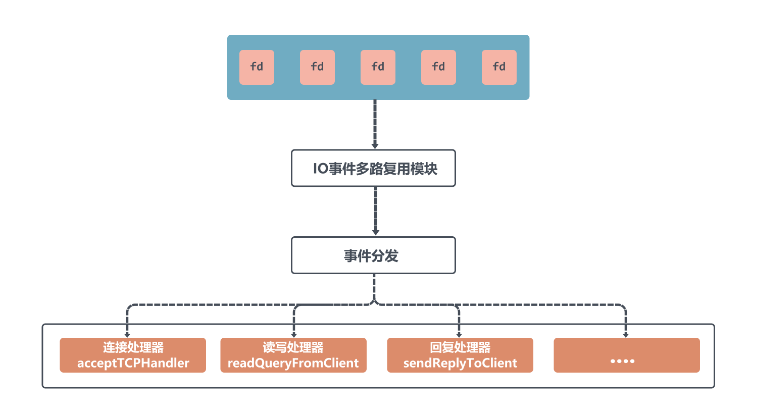 Zum Beispiel: „Akzeptieren“ entspricht dem Ereignishandler „acceptTCPHandler“, „Lesen und Schreiben“ entspricht dem Ereignishandler „readQueryFromClient“ usw., und dann wird das Ereignis dem Ereignisprozessor zur Verarbeitung durch den Ereignisschleifenversand zugewiesen.
Zum Beispiel: „Akzeptieren“ entspricht dem Ereignishandler „acceptTCPHandler“, „Lesen und Schreiben“ entspricht dem Ereignishandler „readQueryFromClient“ usw., und dann wird das Ereignis dem Ereignisprozessor zur Verarbeitung durch den Ereignisschleifenversand zugewiesen.
Der obige Reaktormodus wird also über Epoll implementiert. Für Epoll gibt es hauptsächlich drei Methoden:
//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大 int epoll_create(int size); /* * 可以理解为,增删改 fd 需要监听的事件 * epfd 是 epoll_create() 创建的句柄。 * op 表示 增删改 * epoll_event 表示需要监听的事件,Redis 只用到了可读,可写,错误,挂断 四个状态 */ int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); /* * 可以理解为查询符合条件的事件 * epfd 是 epoll_create() 创建的句柄。 * epoll_event 用来存放从内核得到事件的集合 * maxevents 获取的最大事件数 * timeout 等待超时时间 */ int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
Wir können also einen einfachen Server basierend auf diesen drei Methoden implementieren:
// 创建监听
int listenfd = ::socket();
// 绑定ip和端口
int r = ::bind();
// 创建 epoll 实例
int epollfd = epoll_create(xxx);
// 添加epoll要监听的事件类型
int r = epoll_ctl(..., listenfd, ...);
struct epoll_event* alive_events = static_cast<epoll_event*>(calloc(kMaxEvents, sizeof(epoll_event)));
while (true) {
// 等待事件
int num = epoll_wait(epollfd, alive_events, kMaxEvents, kEpollWaitTime);
// 遍历事件,并进行事件处理
for (int i = 0; i < num; ++i) {
int fd = alive_events[i].data.fd;
// 获取事件
int events = alive_events[i].events;
// 进行事件的分发
if ( (events & EPOLLERR) || (events & EPOLLHUP) ) {
...
} else if (events & EPOLLRDHUP) {
...
}
...
}
}Aufrufprozess #
Also basierend auf dem oben Gesagten Einführung, Sie können wissen, dass eine Ereignisschleife für Redis nichts weiter als ein paar Schritte ist:
Ereignisüberwachungs- und Rückruffunktionen registrieren;
Schleife, die darauf wartet, Ereignisse abzurufen und zu verarbeiten; Rückruffunktion zum Verarbeiten der Datenlogik;
- Registrieren Sie fd bei epoll und stellen Sie die Rückruffunktion ein. Wenn eine neue Verbindung besteht, wird die Rückruffunktion ausgeführt aufgerufen werden;
- Starten Sie eine Endlosschleife, um epoll_wait aufzurufen, um zu warten und mit der Verarbeitung des Ereignisses fortzufahren takeTcpHandler wird vollständig aufgerufen. readQueryFromClient analysiert die Client-Daten und findet die entsprechende cmd-Funktion zur Ausführung an den Client. Ausgabepuffer, anstatt sofort zurückzukehren.
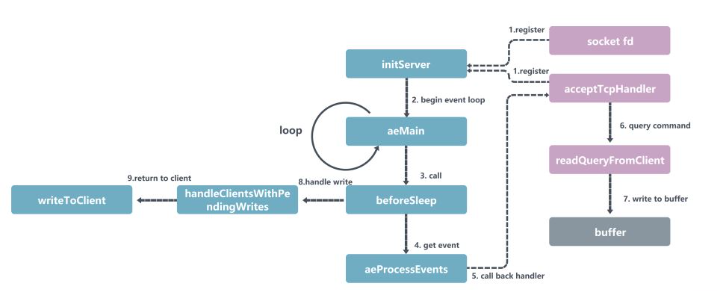 Dann wird die Funktion beforeSleep jedes Mal aufgerufen, um die Daten im Puffer zurück an den Client zu schreiben eigentlich der Code Die Schritte wurden sehr klar geschrieben und es gibt viele Artikel im Internet darüber, daher werde ich nicht auf Details eingehen.
Dann wird die Funktion beforeSleep jedes Mal aufgerufen, um die Daten im Puffer zurück an den Client zu schreiben eigentlich der Code Die Schritte wurden sehr klar geschrieben und es gibt viele Artikel im Internet darüber, daher werde ich nicht auf Details eingehen.
- Befehlsausführungsprozess und Write-Back-Client#
Befehlsausführung#
Lassen Sie uns nun über etwas sprechen, das in vielen Artikeln im Internet nicht erwähnt wurde. Schauen wir uns an, wie Redis den Befehl ausführt, ihn dann im Cache speichert und schreibt die Daten aus dem Cache zurück zum Client-Prozess. - Wir haben im vorherigen Abschnitt auch erwähnt, dass bei einem Netzwerkereignis die Funktion readQueryFromClient aufgerufen wird, in der der Befehl tatsächlich ausgeführt wird. Wir werden dieser Methode folgen und nach unten schauen:
- readQueryFromClient ruft die Funktion „processInputBufferAndReplicate“ auf, um den angeforderten Befehl zu verarbeiten Der Befehl wird auf andere Knoten kopiert. Die Funktion „processInputBuffer“ verarbeitet den angeforderten Befehl in einer Schleife, ruft die Funktion „processInlineBuffer“ gemäß dem angeforderten Protokoll auf und ruft dann „processCommand“ auf, um den Befehl nach dem Objekt „redisObject“ auszuführen
processCommand geht bei der Ausführung des Befehls zur Tabelle
server.commands, um die entsprechende Ausführungsfunktion basierend auf dem Befehl zu finden, und ruft dann nach einer Reihe von Überprüfungen die entsprechende Funktion auf, um den Befehl auszuführen Befehl und ruft addReply auf, um die zurückgegebenen Daten in den Client-Ausgabepufferbereich zu schreiben der Befehlsname. Um beispielsweise den get-Befehl auszuführen, wird die getCommand-Funktion aufgerufen: void getCommand(client *c) { getGenericCommand(c); } int getGenericCommand(client *c) { robj *o; // 查找数据 if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.nullbulk)) == NULL) return C_OK; ... } robj *lookupKeyReadOrReply(client *c, robj *key, robj *reply) { //到db中查找数据 robj *o = lookupKeyRead(c->db, key); // 写入到缓存中 if (!o) addReply(c,reply); return o; }Suchen Sie die Daten in der getCommand-Funktion und rufen Sie dann addReply auf, um die zurückgegebenen Daten in den Client-Ausgabepuffer zu schreiben.
Daten zurück an den Client schreiben#
Nachdem der Befehl in den Puffer geschrieben wurde, müssen die Daten aus dem Puffer entnommen und an den Client zurückgegeben werden. Der Prozess des Zurückschreibens von Daten an den Client wird tatsächlich in der Ereignisschleife des Servers abgeschlossen.
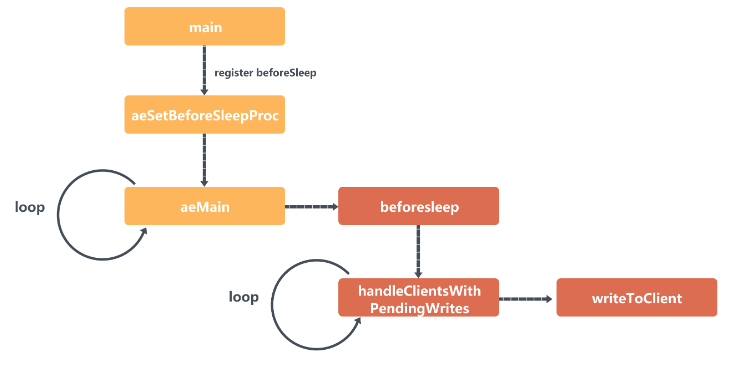
Zunächst ruft Redis die Funktion aeSetBeforeSleepProc in der Hauptfunktion auf, um die Funktion beforeSleep des Writeback-Pakets in der eventLoop zu registrieren.
Anschließend ermittelt Redis, ob beforesleep vorhanden ist, wenn es die Funktion aeMain aufruft Wenn die Ereignisschleife festgelegt ist, wird sie aufgerufen. Die Funktion „beforesleep“ ruft die Funktion „handleClientsWithPendingWrites“ auf, die writeToClient aufruft, um die Daten aus dem Puffer zurück zu schreiben.
Das obige ist der detaillierte Inhalt vonWie läuft die Verarbeitung von Redis-Anfragen ab?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!