
Beispielcode-Analyse für Redis-Datenstrukturtypen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-01 14:16:131047Durchsuche
intset
Wenn die Set-Sammlung Ganzzahlen speichert, ist die Codierung vom Typ Intset (kleine Integer-Sammlung). 16 Bit , 32-Bit- oder 64-Bit-Aufzählung repräsentiert
| Anzahl der Elemente | ||
|---|---|---|
| Inhalt | Integer-Array, speicherndes Element. Wert | |
| intset ist arrangiert von klein bis groß Elemente der Reihe nach speichern. Entscheiden Sie beim Speichern von Elementen, ob die Codierung basierend auf der Größe der Ganzzahl aktualisiert werden soll, suchen Sie die Position, an der das Element eingefügt werden soll. Wenn dies nicht die letzte Position ist, verschieben Sie das Element um eine Position nach der Position und fügen Sie es schließlich ein Element. Wenn das eingefügte Element keine Ganzzahl ist, wird die Speicherform zu einer Hash-Struktur. | ziplist | Wenn die folgenden Bedingungen in der Konfigurationsdatei erfüllt sind, ist der Codierungstyp von Hash und Zset Ziplist (komprimierte Liste). |
| Feld | Beschreibung | Beschreibung
zlbytes
Anzahl der von der Ziplist belegten Bytes
| zltail_offset | Der Offset des letzten Elements von der Startposition der komprimierten Liste | Wird verwendet, um schnell den letzten Knoten zu finden und ihn dann in umgekehrter Reihenfolge zu durchlaufen | |||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| markiert das Ende der komprimierten Liste | Immer FF | ||||||||||||||||||||||||||||||||||||||||
| Feld | Beschreibung | Erklärung | |||||||||||||||||||||||||||||||||||||||
| prevlen | Die Bytelänge des vorherigen Eintrags |
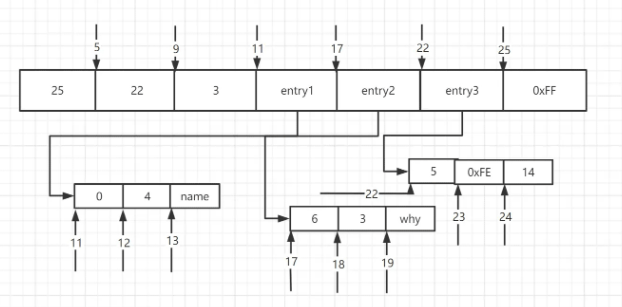
Der erste Eintrag ist immer 0 und das Byte Die Länge ändert sich dynamisch. Wenn die Zeichenfolgenlänge weniger als 254 beträgt, verwenden Sie ein Byte, andernfalls verwenden Sie fünf Bytes. Kodierung: Kodierungstyp: Der Kodierungstyp ändert sich dynamisch entsprechend dem Elementinhalt, was äußerst kompliziert ist Ich werde es nicht im Detail beschreiben. Die Details können nach Ziplist-Kodierungstyp gesucht werden. Inhalt: Elementinhalt: optional 下图是一个ziplist的demo
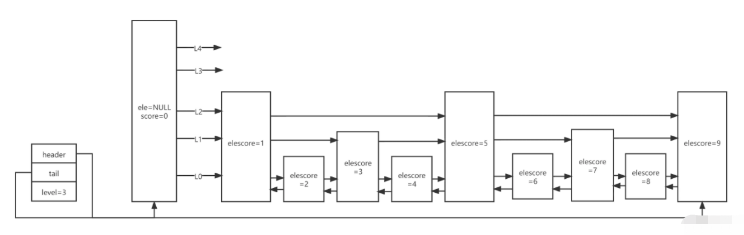
当用ziplist存储hash结构时,将key与value分别当作一个entry存储。 可见压缩列表存储非常的紧凑,当某一个entry长度变为254时,下一个entry的prevlen将从1个字节扩展到5个字节,这就是级联更新 quicklistquicklist(快速列表)用于存储list集合,它是ziplist与linkedlist的混合体,linkedlist与双向列表结构类似。 quicklist内部默认单个ziplist长度为8K,超过这个长度,就会另起一个node,可在配置文件中配置。 # -2表示8k,枚举类型可在配置文件中查看 list-max-ziplist-size -2 quicklist默认的压缩深度为0,也就是不压缩。如果压缩深度为1,那么就是首尾不压缩,如果压缩深度为2,那么就是首2个、尾2个不压缩,可在配置文件中配置。 list-compress-depth 0 skiplistzset使用dict存储value与score的映射,另一方面还需要按照score提供排序功能,于是就有了skiplist(跳跃列表) 先看skiplist的一个demo
typedef struct zsl {
zslnode* header;
zslnode* tail;
int maxLevel;
}typedef struct zslnode {
sds value;
double score;
zslforward*[] forwards;
zslnode* backward;
}typedef struct zslforward {
zslnode* item;
int span;
}
最小分值的backward固定null,对于每一个新插入的节点,会调用一个随机算法,来给它分配一个合理的层数 level1的概率为 level2的概率为 leveln的概率为 总结Redis作为单线程内存服务,在响应、数据结构上作出了很多的优化,值得我们学习
HyperLogLogHyperLogLog的原理为伯努利试验,即丢硬币,根据连续出现反面的次数X,推算出一共丢了2的X次方次硬币,当X很大时,推算出来的总数与实际总数误差就很接近了。具体可查询其他文章。 pfaddelement经过hash算法之后是一个64位的固定值 低14位为桶 查找高50位第一个为1的位数,如果大于当前桶的位数,就将其设置为当前桶的位数 假设hash值是 :{此处省略45位}01100 00000000000101
HyperLogLog用了16384个桶,每个桶占用6bit,因此说一个HyperLogLog所占用内存是12K。 调和平均数: 假设我的工资为10_000,马云的工资为1_000_000,那我和马云的平均工资为505_000,我肯定是不认同的。。。 如果使用调和平均数,则为2/(1/10_000+1/1_000_000)=19_801 同理,桶位数的平均数为:n/(1/桶1位数+1/桶2位数+...+1/桶n位数) 桶的平均个数为:Math.pow(2,桶位数的平均数) 总数量:const*桶总数n*桶的平均个数,其中constant为不定值,与桶个数有关,假设m为桶个数,取对数 pfcountp=log2m
switch (p) {
case 4:
constant = 0.673 * m * m;
case 5:
constant = 0.697 * m * m;
case 6:
constant = 0.709 * m * m;
default:
constant = (0.7213 / (1 + 1.079 / m)) * m * m;
} |
Das obige ist der detaillierte Inhalt vonBeispielcode-Analyse für Redis-Datenstrukturtypen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!