
Heim >Technologie-Peripheriegeräte >KI >Endlich hat jemand die aktuelle Situation von GPT klargestellt! Die neueste Rede von OpenAI ging viral und es muss sich um ein von Musk handverlesenes Genie handeln
Endlich hat jemand die aktuelle Situation von GPT klargestellt! Die neueste Rede von OpenAI ging viral und es muss sich um ein von Musk handverlesenes Genie handeln

- PHPznach vorne
- 2023-05-31 16:23:411292Durchsuche
Nach der Veröffentlichung von Windows Copilot wurde die Popularität der Microsoft Build-Konferenz durch eine Rede entfacht.
Der frühere KI-Direktor von Tesla, Andrej Karpathy, glaubte in seiner Rede, dass der „Gedankenbaum“ der „Monte Carlo Tree Search (MCTS)“ von AlphaGo ähnelt! Netizens riefen: Dies ist die detaillierteste und interessanteste Anleitung zur Verwendung großer Sprachmodelle und GPT-4-Modelle!
Darüber hinaus enthüllte Karpathy, dass LLAMA 65B aufgrund von Training und Datenerweiterung „deutlich leistungsfähiger als GPT-3 175B“ ist, und stellte die große anonyme Arena ChatBot Arena vor: 
Internetnutzer sagten, dass Karpathys Reden immer großartig seien und der Inhalt dieses Mal wie immer nicht alle enttäuscht habe. 
Also, dieser Absatz ist vorbereitet Wurde in der Rede ein bestimmter Inhalt erwähnt, der viel Aufmerksamkeit erregte? 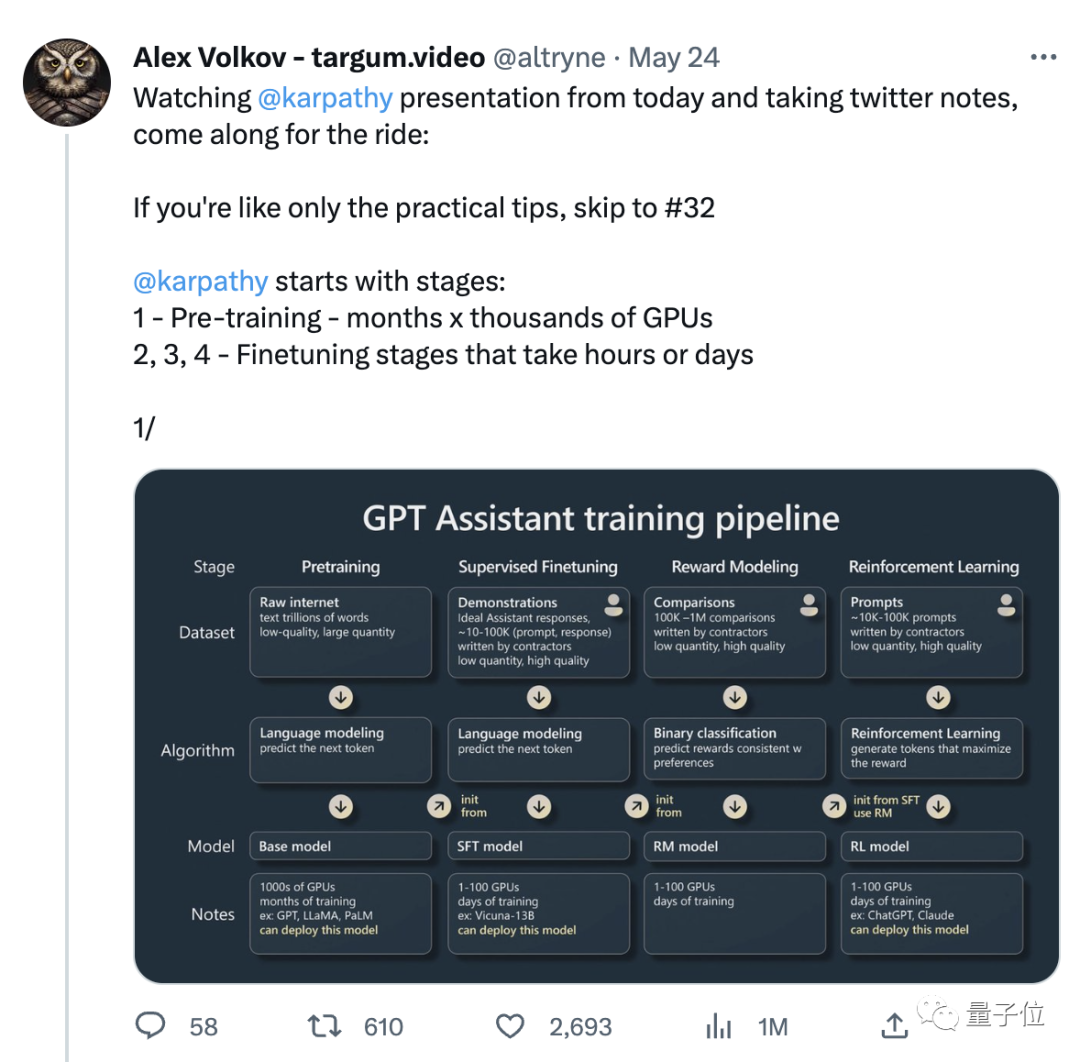
Karpathys Rede ist dieses Mal hauptsächlich in zwei Teile gegliedert.
Teil 1, er sprach darüber, wie man einen „GPT-Assistenten“ ausbildet.
Karpathy spricht hauptsächlich über die vier Trainingsphasen des KI-Assistenten: Vortraining, überwachte Feinabstimmung, Belohnungsmodellierung und verstärkendes Lernen.
Jede Phase erfordert einen Datensatz.In der Phase vor dem Training müssen große Mengen an Rechenressourcen verwendet werden, um eine große Anzahl von Datensätzen zu sammeln. Ein Basismodell wird anhand eines großen unbeaufsichtigten Datensatzes trainiert. 
Dann kommen wir in die Feinabstimmungsphase. 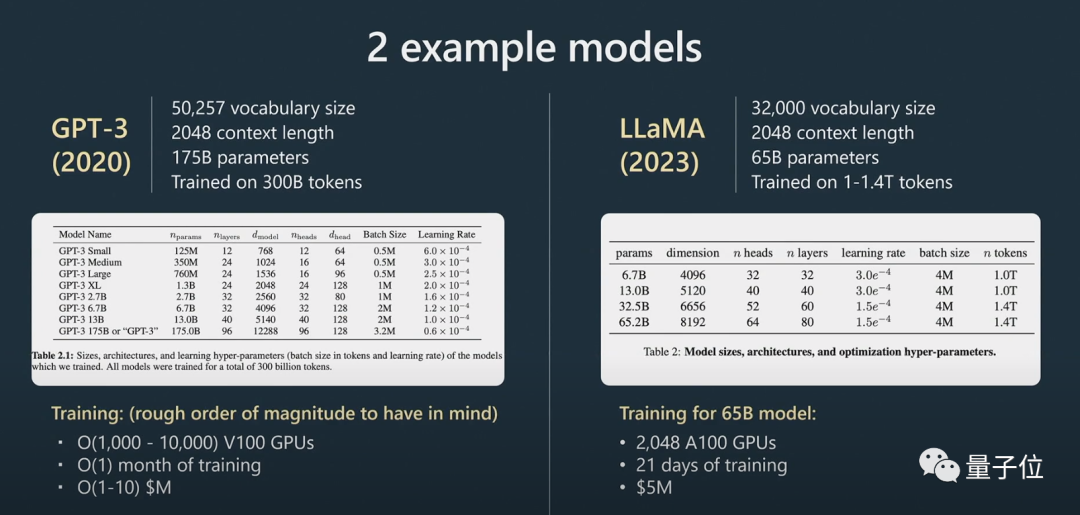
zu erstellen, das die Frage beantworten kann.
Er zeigte auch den Evolutionsprozess einiger Modelle. Ich glaube, viele Menschen haben das obige „Evolutionsbaum“-Bild schon einmal gesehen. 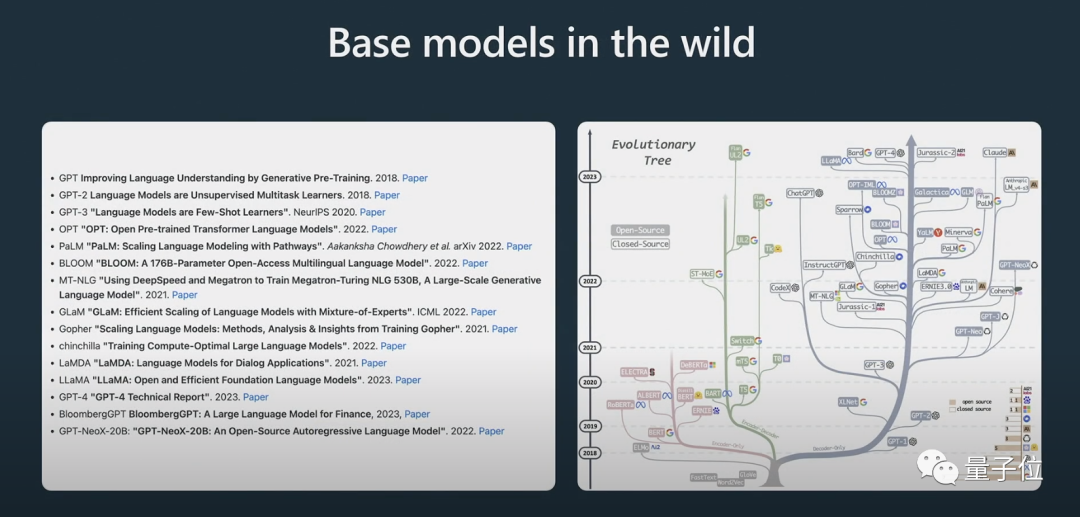
Hier muss klar darauf hingewiesen werden, dass es sich beim
handelt.
Obwohl das Basismodell in der Lage ist, das Problem zu lösen, sind die Antworten, die es gibt, nicht vertrauenswürdig, während das Assistentenmodell zuverlässige Antworten liefern kann. Das überwachte, fein abgestimmte Assistentenmodell wird auf der Grundlage des Basismodells trainiert und seine Leistung beim Generieren von Antworten und beim Verstehen der Textstruktur ist besser als die des Basismodells. Bestärkendes Lernen ist ein weiterer wichtiger Prozess beim Training von Sprachmodellen.
Während des Trainingsprozesses werden hochwertige, manuell kommentierte Daten verwendet und eine Verlustfunktion wird in Form einer Belohnungsmodellierung erstellt, um die Leistung zu verbessern. Ein Verstärkungstraining kann erreicht werden, indem die Wahrscheinlichkeit einer positiven Bewertung erhöht und die Wahrscheinlichkeit einer negativen Bewertung verringert wird.
Menschliches Urteilsvermögen ist entscheidend für die Verbesserung von KI-Modellen, wenn es um kreative Aufgaben geht, und Modelle können durch die Einbeziehung menschlichen Feedbacks effektiver trainiert werden.
Nach dem verstärkenden Lernen mit menschlichem Feedback kann ein RLHF-Modell erhalten werden.
Nachdem die Modelle trainiert wurden, besteht der nächste Schritt darin, diese Modelle effektiv zur Lösung von Problemen einzusetzen.
Wie kann man Modelle besser nutzen?
In Teil 2 spricht Karpathy über Anstoßstrategien, Feinabstimmung, das sich schnell entwickelnde Tool-Ökosystem und zukünftige Erweiterungen.
Karpathy gab zur Veranschaulichung ein weiteres konkretes Beispiel:

Beim Schreiben müssen wir viele mentale Aktivitäten ausführen, einschließlich der Überlegung, ob unser Ausdruck korrekt ist. Für GPT ist dies lediglich eine Folge von markierten Token.
Und prompt kann diese kognitive Lücke ausgleichen.
Karpathy erklärt weiter, wie die Aufforderungen der Gedankenkette funktionieren.
Wenn Sie bei Argumentationsproblemen möchten, dass Transformer bei der Verarbeitung natürlicher Sprache eine bessere Leistung erbringt, müssen Sie ihn die Informationen Schritt für Schritt verarbeiten lassen, anstatt sie direkt einem sehr komplexen Problem zu stellen.
Wenn Sie ihm ein paar Beispiele geben, wird die Vorlage dieses Beispiels nachgeahmt und das Endergebnis wird besser sein.

Das Modell kann Fragen nur entsprechend seiner Reihenfolge beantworten. Wenn der von ihm generierte Inhalt falsch ist, können Sie ihn dazu auffordern und ihn neu generieren lassen.
Wenn Sie es nicht zur Überprüfung auffordern, wird es sich nicht selbst überprüfen.
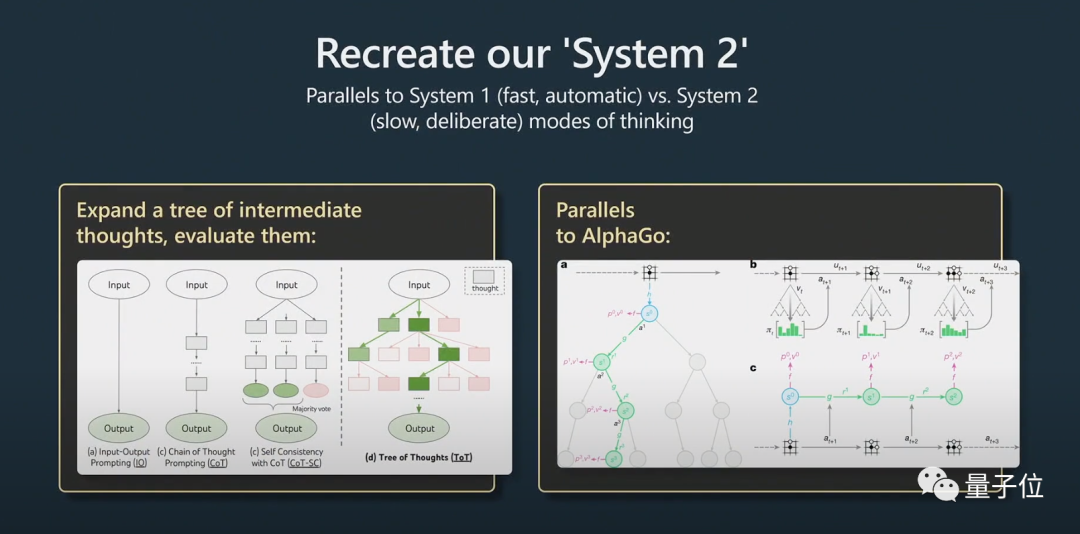
Dabei handelt es sich um das Problem von System1 und System2.
Nobelpreisträger Daniel Kahneman schlug in „Thinking Fast and Slow“ vor, dass das menschliche kognitive System aus zwei Subsystemen besteht, System1 und System2. System1 basiert hauptsächlich auf Intuition, während System2 ein logisches Analysesystem ist.
Laienhaft ausgedrückt ist System1 ein schneller und automatisch generierter Prozess, während System2 ein gut durchdachter Teil ist.
Dies wurde auch in einem kürzlich erschienenen populären Artikel „Tree of Thought“ erwähnt.

Nachdenklich bedeutet nicht einfach, eine Antwort auf eine Frage zu geben, sondern eher wie eine Eingabeaufforderung, die mit Python-Klebercode verwendet wird, um viele Eingabeaufforderungen aneinanderzureihen. Um die Hinweise zu skalieren, muss das Modell mehrere Hinweise verwalten und einen Baumsuchalgorithmus ausführen.
Karpathy glaubt, dass diese Idee AlphaGo sehr ähnlich ist:
Wenn AlphaGo Go spielt, muss es überlegen, wo das nächste Stück platziert werden soll. Ursprünglich lernte es durch die Nachahmung von Menschen.
Darüber hinaus implementiert es die Monte-Carlo-Baumsuche, um Ergebnisse mit mehreren potenziellen Strategien zu erhalten. Es bewertet viele mögliche Züge und behält nur die besseren bei. Ich denke, das entspricht in gewisser Weise AlphaGo.
In diesem Zusammenhang erwähnte Karpathy auch AutoGPT:
Ich denke, die Wirkung ist derzeit nicht sehr gut und ich empfehle es nicht für die praktische Anwendung. Ich denke, im Laufe der Zeit können wir vielleicht aus seiner Entwicklung lernen.

Zweitens ist ein weiterer kleiner Trick das Abrufen einer verbesserten Generation (Retrieval Agumented Generation) und effektiver Tipps.
Der Inhalt des Fensterkontexts ist der Arbeitsspeicher von Transformern zur Laufzeit. Wenn Sie dem Kontext aufgabenbezogene Informationen hinzufügen können, ist die Leistung sehr gut, da er sofort auf diese Informationen zugreifen kann.
Kurz gesagt bedeutet dies, dass relevante Daten indiziert werden können, sodass effizient auf das Modell zugegriffen werden kann.
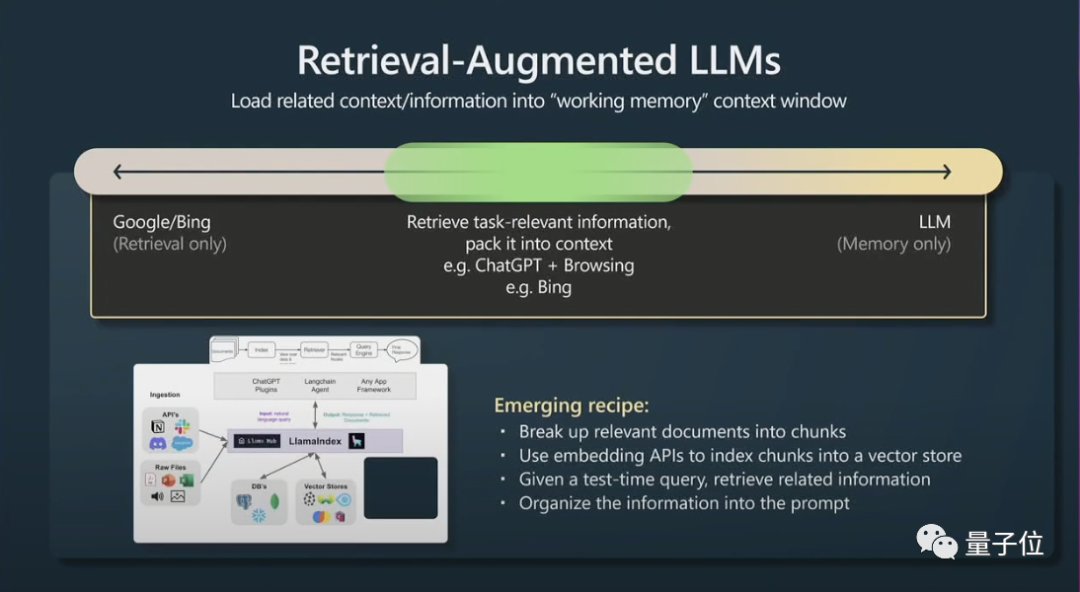
Transformer erzielen eine bessere Leistung, wenn sie auch über eine Hauptdatei als Referenz verfügen.
Abschließend sprach Karpathy kurz über die Eingabeaufforderung und Feinabstimmung von Einschränkungen in großen Sprachmodellen.
Große Sprachmodelle können durch Einschränkungshinweise und Feinabstimmung verbessert werden. Einschränkungshinweise erzwingen Vorlagen in der Ausgabe großer Sprachmodelle, während durch Feinabstimmung die Gewichtungen des Modells angepasst werden, um die Leistung zu verbessern.
Ich empfehle, große Sprachmodelle in Anwendungen mit geringem Risiko zu verwenden, sie immer mit menschlicher Aufsicht zu kombinieren, sie als Quelle der Inspiration und Beratung zu betrachten und Copiloten in Betracht zu ziehen, anstatt sie zu vollständig autonomen Agenten zu machen.
Über Andrej Karpathy

Andrej Karpathys erster Job nach seinem Abschluss bestand darin, Computer Vision bei OpenAI zu studieren.
Später verliebte sich Musk, einer der Mitbegründer von OpenAI, in Karpathy und stellte ihn bei Tesla ein. Musk und OpenAI waren sich in dieser Angelegenheit uneinig, und Musk wurde schließlich ausgeschlossen. Karpathy ist für Teslas Autopilot, FSD und andere Projekte verantwortlich.
Im Februar dieses Jahres, 7 Monate nachdem er Tesla verlassen hatte, trat Karpathy erneut OpenAI bei.
Kürzlich hat er getwittert, dass er derzeit sehr an der Entwicklung des Open-Source-Ökosystems für große Sprachmodelle interessiert ist, was ein bisschen wie Anzeichen der frühen kambrischen Explosion ist.
Portal:
[1]https://www.youtube.com/watch?v=xO73EUwSegU (Sprachvideo)
[2]https://arxiv . org/PDF/2305.10601.pdf („Tree of Thought“-These)
Referenzlink:
[1] https://twitter.com/altryne/status/16612367888832896
[ 2 ]https://www.reddit.com/r/MachineLearning/comments/13qrtek/n_state_of_gpt_by_andrej_karpathy_in_msbuild_2023/
[3]https://www.wisdominanutshell.academy/state-of-gpt/
Das obige ist der detaillierte Inhalt vonEndlich hat jemand die aktuelle Situation von GPT klargestellt! Die neueste Rede von OpenAI ging viral und es muss sich um ein von Musk handverlesenes Genie handeln. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr