
Heim >Technologie-Peripheriegeräte >KI >Google DeepMind, OpenAI und andere haben gemeinsam einen Artikel veröffentlicht: Wie bewertet man die extremen Risiken großer KI-Modelle?
Google DeepMind, OpenAI und andere haben gemeinsam einen Artikel veröffentlicht: Wie bewertet man die extremen Risiken großer KI-Modelle?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-31 12:59:151356Durchsuche
Derzeit bergen die Methoden zum Aufbau allgemeiner künstlicher Intelligenzsysteme (AGI), obwohl sie den Menschen helfen, reale Probleme besser zu lösen, auch einige unerwartete Risiken.
Deshalb Die Weiterentwicklung der künstlichen Intelligenz kann in Zukunft zu vielen extremen Risiken führen, wie z. B. offensive Netzwerkfähigkeiten oder starke Manipulationsfähigkeiten usw.
Heute hat Google DeepMind in Zusammenarbeit mit Universitäten wie der University of Cambridge und der Oxford University, Unternehmen wie OpenAI und Anthropic sowie Institutionen wie dem Alignment Research Center einen Artikel mit dem Titel „Modellbewertung für Extreme“ veröffentlicht Risiken“ auf der Preprint-Website arXiv. schlägt einen Rahmen für ein gemeinsames Modell für die Bewertung neuartiger Bedrohungen vor und erklärt, warum die Modellbewertung für den Umgang mit extremen Risiken von entscheidender Bedeutung ist.
Sie glauben, dass Entwickler in der Lage sein müssen, Gefahren (durch eine „Bewertung der Gefahrenfähigkeit“), und die Neigung des Modells, seine Fähigkeiten einzusetzen, um Schaden zu verursachen, zu identifizieren (über „Ausrichtungsbewertung“). Diese Bewertungen werden von entscheidender Bedeutung sein, um politische Entscheidungsträger und andere Interessengruppen auf dem Laufenden zu halten und verantwortungsvolle Entscheidungen über Modellschulung, -bereitstellung und -sicherheit zu treffen.

Academic Headlines (ID: SciTouTiao) hat eine einfache Zusammenstellung erstellt, ohne die Hauptidee des Originaltextes zu ändern. Der Inhalt ist wie folgt:
Um die Weiterentwicklung der KI-Spitzenforschung verantwortungsvoll voranzutreiben, müssen wir neue Fähigkeiten und Risiken in KI-Systemen so früh wie möglich erkennen.
KI-Forscher haben eine Reihe von Bewertungsmaßstäben verwendet, um unerwünschtes Verhalten in KI-Systemen zu identifizieren, beispielsweise wenn KI-Systeme irreführende Behauptungen aufstellen, voreingenommene Entscheidungen treffen oder urheberrechtlich geschützte Inhalte duplizieren. Jetzt, da die KI-Community immer leistungsfähigere KI aufbaut und einsetzt, müssen wir unsere Einschätzung erweitern, um die potenziellen Konsequenzen allgemeiner KI-Modelle mit der Fähigkeit zur Manipulation, Täuschung, Cyberangriffen oder auf andere Weise extreme Risiken einzubeziehen Überlegungen.
In Zusammenarbeit mit der University of Cambridge, der University of Oxford, der University of Toronto, der University of Montreal, OpenAI, Anthropic, dem Alignment Research Center, dem Centre for Long-Term Resilience und dem Centre for the Governance of KI führen wir einen Rahmen zur Bewertung dieser neuen Bedrohungen ein.
Die Bewertung der Modellsicherheit, einschließlich der Bewertung extremer Risiken, wird ein wichtiger Bestandteil der sicheren KI-Entwicklung und -Einführung werden.
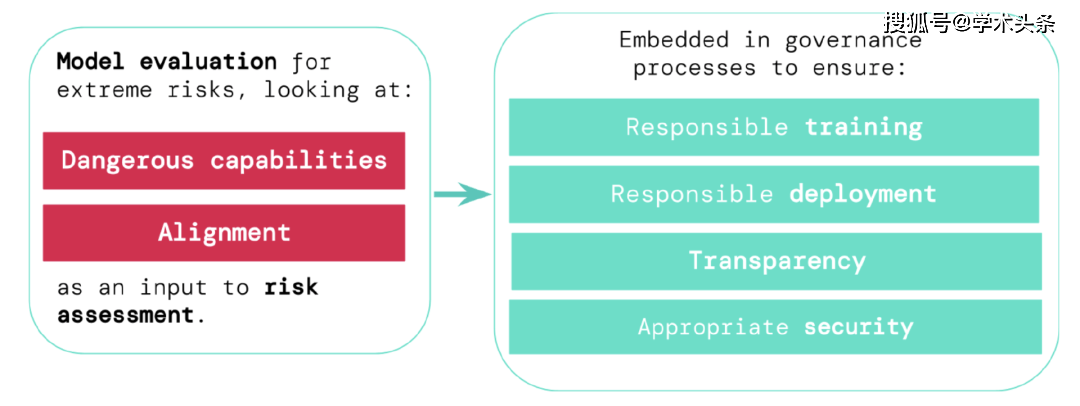
Um die extremen Risiken neuer allgemeiner künstlicher Intelligenzsysteme einzuschätzen, müssen Entwickler ihre gefährlichen Fähigkeiten und Ausrichtungsgrade bewerten. Das frühzeitige Erkennen von Risiken kann zu einer größeren Verantwortung bei der Schulung neuer KI-Systeme, dem Einsatz dieser KI-Systeme, der transparenten Beschreibung ihrer Risiken und der Anwendung geeigneter Cybersicherheitsstandards führen.
Einschätzung extremer Risiken
Universelle Modelle lernen ihre Fähigkeiten und Verhaltensweisen normalerweise während des Trainings. Allerdings sind die bestehenden Methoden zur Steuerung des Lernprozesses unvollkommen. Frühere Untersuchungen von Google DeepMind haben beispielsweise untersucht, wie KI-Systeme lernen können, Ziele zu verfolgen, die Menschen nicht wollen, selbst wenn wir sie für gutes Verhalten richtig belohnen.
Verantwortungsvolle KI-Entwickler müssen einen Schritt weiter gehen und mögliche zukünftige Entwicklungen und neue Risiken antizipieren. Im weiteren Verlauf können künftige Allzweckmodelle standardmäßig verschiedene gefährliche Fähigkeiten erlernen. Künftige künstliche Intelligenzsysteme werden beispielsweise in der Lage sein, anstößige Netzwerkaktivitäten durchzuführen, Menschen in Gesprächen geschickt zu täuschen, Menschen zu schädlichen Verhaltensweisen zu manipulieren, Waffen (wie biologische oder chemische Waffen) zu entwerfen oder zu erwerben sowie Cloud Computing zu optimieren und zu betreiben Andere hochriskante KI-Systeme oder die Unterstützung von Menschen bei einer dieser Aufgaben sind möglich (wenn auch nicht sicher).
Menschen mit schlechten Absichten können die Fähigkeiten dieser Modelle missbrauchen. Diese KI-Modelle können schädlich wirken, weil sie andere Werte und Moralvorstellungen haben als Menschen, auch wenn das niemand beabsichtigt hat.
Die Modellbewertung hilft uns, diese Risiken im Vorfeld zu erkennen. Im Rahmen unseres Frameworks werden KI-Entwickler die Modellevaluierung nutzen, um Folgendes aufzudecken:
- Das Ausmaß, in dem ein Modell über bestimmte „gefährliche Fähigkeiten“ verfügt, die die Sicherheit gefährden, Einfluss ausüben oder sich der Aufsicht entziehen.
- Das Ausmaß, in dem ein Modell dazu neigt, seine Fähigkeiten zu nutzen, um Schaden anzurichten (d. h. die Ausrichtungsstufe des Modells). Es muss bestätigt werden, dass sich das Modell auch unter den unterschiedlichsten Umständen wie erwartet verhält, und wenn möglich sollte das Innenleben des Modells untersucht werden.
Anhand der Ergebnisse dieser Bewertungen können KI-Entwickler verstehen, ob es Faktoren gibt, die zu extremen Risiken führen können. Die Situationen mit dem höchsten Risiko beinhalten eine Kombination gefährlicher Fähigkeiten. Wie unten gezeigt:
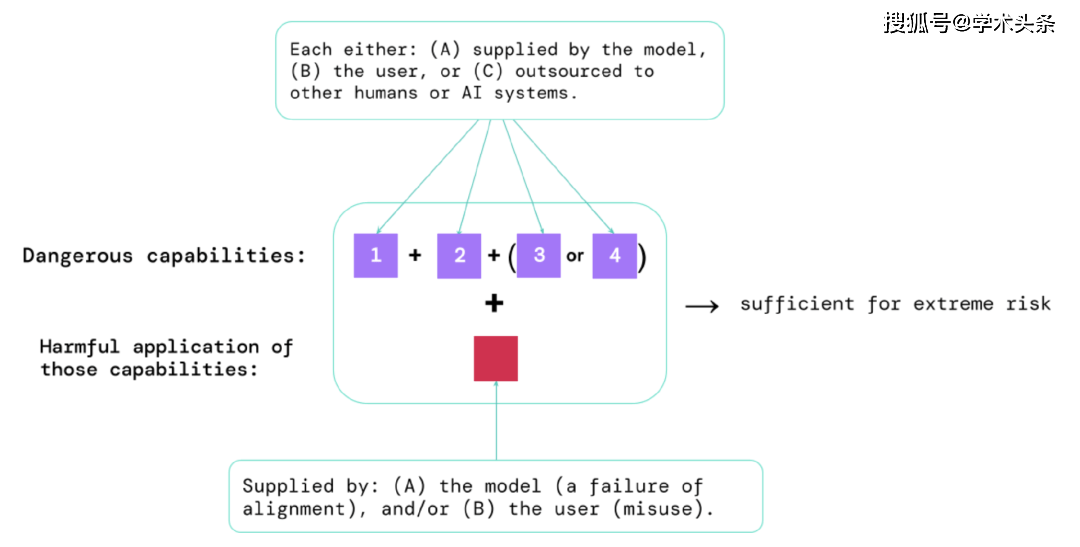
Abbildung |. Elemente, die extreme Risiken bergen: Manchmal können bestimmte Fähigkeiten ausgelagert werden, entweder an Menschen (z. B. Benutzer oder Crowdworker) oder an andere KI-Systeme. Ob durch Missbrauch oder durch das Versäumnis, eine Ausrichtung zu erreichen, diese Fähigkeiten müssen genutzt werden, um Schaden anzurichten.
Eine Faustregel: Wenn ein KI-System Eigenschaften aufweist, die extremen Schaden anrichten können, vorausgesetzt, es wird missbraucht oder falsch ausgerichtet, dann sollte die KI-Community es als „höchst gefährlich“ einstufen. Um solche Systeme in der realen Welt einzusetzen, müssen KI-Entwickler außergewöhnlich hohe Sicherheitsstandards nachweisen.
Modellbewertung ist eine entscheidende Governance-Infrastruktur
Wenn wir bessere Tools zur Identifizierung riskanter Modelle haben, können Unternehmen und Regulierungsbehörden besser sicherstellen, dass:
- Verantwortungsvolles Training: Entscheiden Sie verantwortungsvoll, ob und wie Sie ein neues Modell trainieren, das erste Anzeichen von Risiken aufweist.
- Verantwortungsvolle Bereitstellung: Treffen Sie verantwortungsvolle Entscheidungen darüber, ob, wann und wie potenziell riskante Modelle bereitgestellt werden.
- Transparenz: Melden Sie den Stakeholdern nützliche und umsetzbare Informationen, um ihnen zu helfen, auf potenzielle Risiken zu reagieren oder diese zu reduzieren.
- Angemessene Sicherheit: Für Modelle, die extreme Risiken bergen können, sind robuste Informationssicherheitskontrollen und -systeme vorhanden.
Wir haben einen Entwurf dafür entwickelt, wie die Modellbewertung für extreme Risiken wichtige Entscheidungen über das Training und den Einsatz leistungsstarker Allzweckmodelle unterstützen soll. Entwickler führen während des gesamten Prozesses Bewertungen durch und gewähren externen Sicherheitsforschern und Modellprüfern strukturierten Zugriff auf das Modell, damit diese zusätzliche Bewertungen durchführen können. Die Bewertungsergebnisse können als Referenz für die Risikobewertung vor dem Training und Einsatz des Modells dienen.
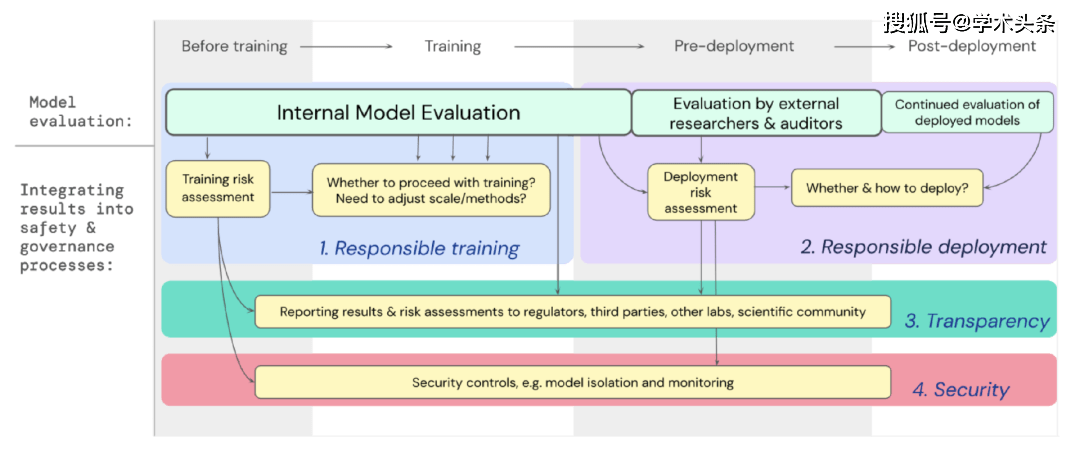
Abbildung |. Integrieren Sie die Modellbewertung für extreme Risiken in den wichtigen Entscheidungsprozess des gesamten Modelltrainings und -einsatzes.
Der Blick in die Zukunft
Bei Google DeepMind und anderswo haben wichtige Vorarbeiten zur Modellbewertung für extreme Risiken begonnen. Um jedoch einen Bewertungsprozess aufzubauen, der alle möglichen Risiken erfasst und zum Schutz vor künftigen Herausforderungen beiträgt, „brauchen wir mehr technische und institutionelle Anstrengungen“. Modellbewertung ist kein Allheilmittel; manchmal entgehen einige Risiken unserer Bewertung, weil sie zu sehr von Faktoren außerhalb des Modells abhängen, wie etwa den komplexen sozialen, politischen und wirtschaftlichen Kräften in der Gesellschaft. Es besteht die Notwendigkeit, Modellbewertungen mit breiteren Bedenken der Industrie, der Regierung und der Öffentlichkeit in Bezug auf Sicherheit und andere Instrumente zur Risikobewertung zu integrieren.
Google erwähnte kürzlich in seinem Blog über verantwortungsvolle KI, dass „individuelle Praktiken, gemeinsame Branchenstandards und solide Regierungsrichtlinien für den ordnungsgemäßen Einsatz von KI von entscheidender Bedeutung sind.“ Wir hoffen, dass die vielen Branchen, die in der KI arbeiten und von dieser Technologie betroffen sind, zusammenarbeiten können, um gemeinsam Methoden und Standards für die sichere Entwicklung und den Einsatz von KI zum Nutzen aller zu entwickeln.
Wir glauben, dass Verfahren zur Verfolgung der in Modellen auftretenden Risikoattribute und zur angemessenen Reaktion auf entsprechende Ergebnisse ein entscheidender Bestandteil der Arbeit als verantwortungsbewusster Entwickler an der Spitze der KI-Forschung sind.
Das obige ist der detaillierte Inhalt vonGoogle DeepMind, OpenAI und andere haben gemeinsam einen Artikel veröffentlicht: Wie bewertet man die extremen Risiken großer KI-Modelle?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr