
Beispielanalyse des Redis-Puffermechanismus

- 王林nach vorne
- 2023-05-31 08:40:401665Durchsuche
Redis-Puffermechanismus
Der Puffermechanismus in Redis dient dazu, den Geschwindigkeitsunterschied zwischen dem Senden von Befehlen durch den Client und dem Verarbeiten von Befehlen durch den Server auszugleichen. Wenn der Client zu schnell schreibt oder der Server zu langsam liest, führt dies einmal zu einem Pufferüberlauf Wenn der Puffer überläuft, führt dies zu einer Reihe von Leistungsproblemen. Lassen Sie uns weiter unten ausführlich darüber sprechen.
Client-Puffermechanismus
Redis weist jedem Client einen Eingabepuffer und einen Ausgabepuffer zu. Der Eingabepuffer speichert vorübergehend den Anforderungsbefehl des Clients, und der Redis-Hauptthread erhält den Befehl aus dem Puffer. Es schreibt das Ergebnis in den Ausgabepuffer und gibt es über den Ausgabepuffer an den Client zurück, wie unten gezeigt zu schnell geschrieben, oder die in Bigkey geschriebenen Daten füllen den Datenpuffer.
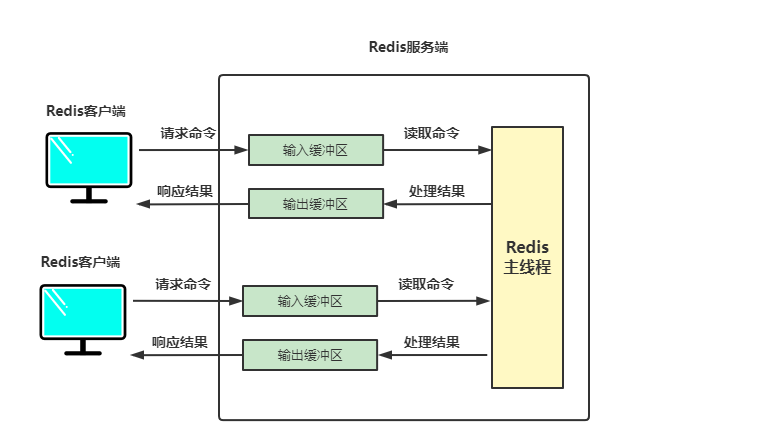
- Wir können
client listverwenden, um die spezifischen Informationen des Eingabepuffers anzuzeigen127.0.0.1:6379> client list id=13 addr=127.0.0.1:50484 fd=7 name= age=1136 idle=1 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client user=default id=14 addr=127.0.0.1:50486 fd=8 name= age=1114 idle=6 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=client user=default
Jedes Mal, wenn ein Client verbunden wird, gibt es eine weitere Eingabepufferinformation , der obige Befehl Es ist das Ergebnis meiner lokalen Verbindung zu zwei Clients. Wenn wir den Puffer anzeigen, konzentrieren wir uns hauptsächlich auf zwei speicherbezogene Parameter - qbuf: die Länge des verwendeten Puffers (in Bytes). 0 bedeutet, dass kein Puffer zugewiesen ist.
client list查看输入缓冲区的具体信息
127.0.0.1:6379> monitor OK 1652184977.609761 [0 127.0.0.1:50484] "get" "name" 1652185391.529292 [0 127.0.0.1:50484] "set" "test" "lisi" ......
每连接上一个客户端就会多一条输入缓冲区信息,上面命令是我本地连接两个客户端的结果,我们查看缓冲区主要关注内存相关的两个参数
qbuf:缓冲区已经使用的长度(字节为单位,0表示没有分配缓冲区)。
qbuf-free:缓冲区剩余空闲空间(字节为单位),上面一个客户端的qbuf=26,空闲缓冲区qbuf-free=32742,那么分配内存总大小为26+32742=32768字节也就是32KB。
如果输入缓冲区信息中的qbuf-free很小并且qbuf很大时就需要注意了,这时输入缓冲区可能已经快溢出了,如果此时还有大量请求写入输入缓冲区,Redis的解决办法就是关闭和这个客户端的连接,那么业务数据将无法正常存取。
而且还有一个问题就是输入缓冲区是每一个客户端都会存在,那么当所有客户端的输入缓冲区内存总和超过了maxmemory配置,那么将引发内存淘汰,部分淘汰的数据再次访问需要从后台数据库获取,获取的耗时肯定比Redis直接读取慢的多,所以这也是Redis产生延迟的一个原因。
如何解决输入缓冲区溢出
输入缓冲区溢出本质就是缓冲区的容量不够,所以第一个思路就是扩大输入缓冲区的大小,很不幸Redis没有提供给我们修改输入缓冲区大小的配置,Redis要求每个客户端的输入缓冲区最大不能超过1G,注意是每个客户端!!!,如果客户端的输入缓冲区超过一个1G将关闭客户端连接,所以这个是行不通的。
那就只能从客户端发送数据的大小以及服务端处理命令的速度,客户端需要避免bigkey的写入bigkey的劣势太多一般都需要拆分,第二服务端的命令处理速度这个一般依赖于主线程是否阻塞,需要尽量的避免一些阻塞操作如AOF文件重写,键值删除,fork线程等等。
应对输出缓冲区溢出
对于服务端而言,客户端的输入信息通常都是不可预测的,但是输出信息大多可以预测,如Set命令返回信息只是一个简单的OK,又如一些报错信息,Redis为这些不变的返回信息分配了16KB的固定缓冲空间,也就是说输出缓冲区分为两个部分一部分是输出缓冲区固定返回信息,一部分是可变的返回信息。
输出缓冲区溢出分为三种情况
输出bigkey等容量大的键值。
客户端执行Monitor命令,监控Redis执行。
缓冲区设置不合理。
bigkey是老生常谈的一个问题,当服务端输出一个bigkey或者keys这类命令,对输出缓冲区的考验是非常大的,因为查询的一瞬间会占据输入缓冲区大量的内存空间。
Monitor命令的执行
Monitor命令一般是一个debug命令,用来监控Redis的具体执行情况,能够返回服务器处理的每一个命令。
## 普通客户端配置 client-output-buffer-limit normal 0 0 0 ## 从节点客户端配置 client-output-buffer-limit replica 256mb 64mb 60 ## 消息订阅频道的客户端 client-output-buffer-limit pubsub 32mb 8mb 60 ######################配置解释###################### ## 第一个参数:代表分配给客户端的缓存大小,为0代表没有限制 ## 第二个参数:表示持续写入的最大内存,为0代表没有限制 ## 第三个参数:表示持续写入的最长时间,为0代表没有限制
一直运行monitor将一直占据输出缓冲区,也就是说占据时间越长,越容易造成输出缓冲区的溢出,所以Monitor命令仅仅只适用于调试环境,不能在生产上执行这些命令。
输出缓冲区设置不合理
输入缓冲区的大小不能设置,但是输出缓冲区的是可以设置的我们可以通过配置项client-output-buffer-limit
- Wenn die qbuf-freien Informationen im Eingabepuffer sehr klein und qbuf sehr groß sind, müssen Sie darauf achten, dass der Eingabepuffer zu diesem Zeitpunkt möglicherweise fast übergelaufen ist Zu diesem Zeitpunkt besteht die Lösung von Redis darin, die Verbindung mit diesem Client für den Eingabepuffer zu schließen, sodass auf die Geschäftsdaten nicht normal zugegriffen werden kann.
-
Und ein weiteres Problem besteht darin, dass der Eingabepuffer für jeden Client vorhanden ist. Wenn die Summe des Eingabepufferspeichers aller Clients die maximale Speicherkonfiguration überschreitet, kommt es zu einer Speichereliminierung und auf einige der gelöschten Daten muss im Hintergrund erneut zugegriffen werden Die Erfassung und Erfassung der Datenbank ist definitiv viel langsamer als das direkte Lesen aus Redis, daher ist dies auch ein Grund für die Verzögerung in Redis.
🎜So beheben Sie einen Eingabepufferüberlauf🎜🎜Das Wesentliche beim Eingabepufferüberlauf ist, dass die Pufferkapazität nicht ausreicht. Daher besteht die erste Idee darin, die Größe des Eingabepuffers zu erweitern. Leider stellt uns Redis keine Konfiguration zum Ändern zur Verfügung Die Eingabepuffergröße von Redis erfordert, dass der Eingabepuffer jedes Clients 1 GB nicht überschreiten darf. ! ! Wenn der Eingabepuffer des Clients eine 1G-Clientverbindung überschreitet, wird die Verbindung geschlossen, sodass dies nicht funktioniert. 🎜🎜 Dann können Sie nur Daten vom Client senden und die Geschwindigkeit der Befehlsverarbeitung durch den Client muss zu viele Nachteile haben, und zweitens muss die Befehlsverarbeitungsgeschwindigkeit des Servers aufgeteilt werden Im Allgemeinen hängt es davon ab, ob der Hauptthread blockiert ist. Sie müssen versuchen, einige blockierende Vorgänge wie das Umschreiben von AOF-Dateien, das Löschen von Schlüsselwerten, Gabelthreads usw. zu vermeiden. 🎜🎜Umgang mit Ausgabepufferüberlauf🎜🎜Für den Server sind die Eingabeinformationen des Clients normalerweise unvorhersehbar, die Ausgabeinformationen sind jedoch größtenteils vorhersehbar. Beispielsweise gibt der Set-Befehl ein einfaches OK und einige Fehlermeldungen zurück, Redis weist eine zu 16 KB fester Pufferspeicher für diese konstanten Rückgabeinformationen, was bedeutet, dass der Ausgabepuffer in zwei Teile unterteilt ist: Ein Teil sind die festen Rückgabeinformationen des Ausgabepuffers und der andere Teil sind variable Rückgabeinformationen. 🎜🎜Der Überlauf des Ausgabepuffers ist in drei Situationen unterteilt 🎜🎜🎜🎜Schlüsselwerte mit großer Kapazität ausgeben, z. B. Bigkey. 🎜🎜🎜🎜Der Client führt den Monitor-Befehl aus, um die Redis-Ausführung zu überwachen. 🎜🎜🎜🎜Die Puffereinstellungen sind unangemessen. 🎜🎜🎜🎜Bigkey ist ein häufiges Problem. Wenn der Server einen Befehl wie Bigkey oder Schlüssel ausgibt, ist der Test für den Ausgabepuffer sehr groß, da die Abfrage sofort viel Speicherplatz im Eingabepuffer belegt . 🎜🎜Befehlsausführung überwachen🎜🎜Der Befehl „Monitor“ ist im Allgemeinen ein Debug-Befehl, der zur Überwachung der spezifischen Ausführung von Redis verwendet wird und jeden vom Server verarbeiteten Befehl zurückgeben kann. 🎜rrreee🎜 Wenn der Monitor läuft, wird er immer den Ausgabepuffer belegen. Das heißt, je länger er belegt, desto leichter kann es zu einem Überlauf des Ausgabepuffers kommen. Daher ist der Monitor-Befehl nur für Debugging-Umgebungen geeignet in der Produktion ausgeführt. 🎜🎜Die Einstellung des Ausgabepuffers ist unangemessen🎜🎜Die Größe des Eingabepuffers kann nicht eingestellt werden, aber der Ausgabepuffer kann über das Konfigurationselementclient-output-buffer-limiteingestellt werden . Der Inhalt ist die Speichergröße der beiden Teile 🎜🎜🎜🎜 Puffer. Wenn die Pufferkonfigurationsgröße überschritten wird, schließt der Server die Verbindung mit dem Client. 🎜 持续写入的时间限制和持续写入的容量限制,当超过持续写入时间限制和容量限制,服务端也会强制关闭和客户端的连接。
客户端种类
在聊缓冲区配置时,我们需要先了解下客户端的种类,本文中强调的客户端并不是单纯指通过命令./redis-cli -c -h 127.0.0.1 -p 6379去连接Redis服务器这类客户端称为常规客户端,我们还有通过消息订阅Redis频道的客户端,还有一种最为特殊的主从同步,从节点也是一个特殊的客户端称为从节点客户端。
配置项client-output-buffer-limit也是针对这三种,给出了不一样的配置,如下所示
## 普通客户端配置 client-output-buffer-limit normal 0 0 0 ## 从节点客户端配置 client-output-buffer-limit replica 256mb 64mb 60 ## 消息订阅频道的客户端 client-output-buffer-limit pubsub 32mb 8mb 60 ######################配置解释###################### ## 第一个参数:代表分配给客户端的缓存大小,为0代表没有限制 ## 第二个参数:表示持续写入的最大内存,为0代表没有限制 ## 第三个参数:表示持续写入的最长时间,为0代表没有限制
普通客户端设置
普通客户端就是传输的一些普通的指令,一个指令发送完需要等待其返回后才会发送下一个指令,也就是说只要不是返回的bigkey数据,占用输出缓冲区的内存就极少,能够立即发送给客户端响应,所以一般正常客户端默认配置都是0,也就是不限制。
消息订阅频道客户端
当订阅频道产生消息后,会将消息通过输出缓冲区发送给客户端,这种属于非阻塞的方式,一瞬间可能有多个指令到达,所以需要指定缓冲区大小。
如何解决输出缓冲区溢出
到这里其实我们已经能够得到输出缓冲区溢出的解决方案了
bigkey应当避免使用。
Monitor命令只在调试的时候使用,不能应用到生产。
合理设置输出缓冲区上限、持续写入时间上限以及持续写入内存容量上限。
主从集群中的缓冲区
除了输入缓冲区和输出缓冲区外在主从集群场景下还存在两种缓冲区,我们称为复制缓冲区和复制积压缓冲区,这两个缓冲区的溢出和输入输出缓冲区稍有不同。
复制缓冲区
复制缓冲区这个名词看着很陌生,但是我们之前在聊主从同步时讲过,主从全量同步期间从节点会加载主节点的RDB文件,这时主节点同样还能写入数据,但是从节点在加载RDB文件没办法实时同步,所以Redis就为每一个从节点开辟了一片空间,用来存放主从全量同步期间产生的操作命令,这就是replication buffer,也就是复制缓冲区。
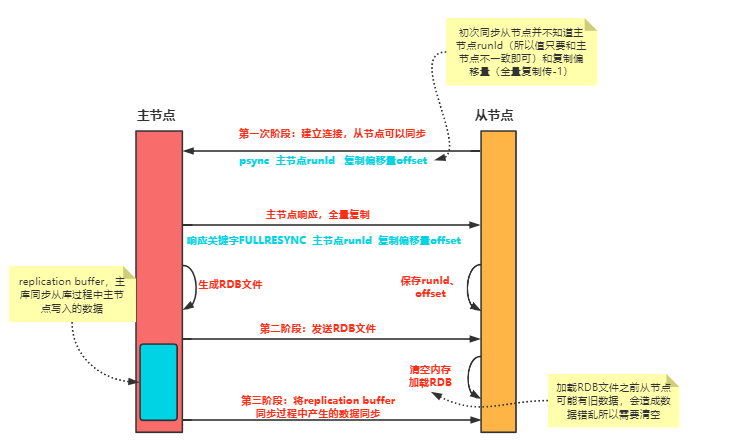
复制缓冲区溢出
复制缓冲区什么时候会溢出呢?
当从节点在加载RDB文件这个过程中如果存在大量的写操作就会造成复制缓冲区内存溢出。
从节点加载RDB文件的时间过长。
发生溢出后,主节点会关闭与从节点的连接,导致全量同步失败。
解决复制缓冲区溢出
控制主节点实例的大小,减小生成的RDB文件,这样就能减少从节点加载RDB文件的时间,减小复制缓冲区的压力。
从节点其本质就是主节点的特殊客户端,所以使用的是输出缓冲区(也就是指replication buffer),可以设置client-output-buffer-limit replica 256mb 64mb 60扩大缓冲区大小。
注意:主节点上的复制缓冲区会为每一个从节点分配一个,那么从节点的数量过多即使每个从节点没有达到maxmemory,但累加的结果也会给主节点带来内存压力。
复制积压缓冲区
复制积压缓冲区溢出
主从集群在写操作时会将操作写入复制缓冲区和复制积压缓冲区中,一旦网络发送故障后恢复连接,在2.8版本之前主从节点会进行全量同步开销非常大,所以2.8版本后还是采用了增量同步,仅仅将网络断开这段时间的操作同步给从节点,所以在网络恢复连接后从节点会将自己的复制偏移量slave_repl_offset发送给主节点,主节点将自身的写入偏移量master_repl_offset和slave_repl_offset在复制积压缓冲区中做对比得到网络断连期间的操作。
复制积压缓冲区又叫repl_backlog_buffer,是一个环形缓冲区,同步示意图如下。
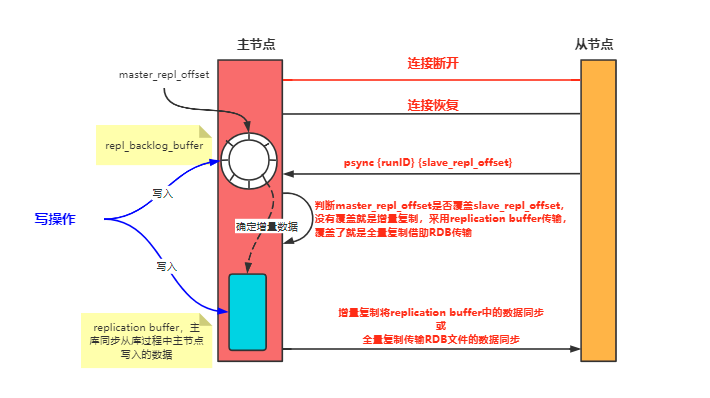
复制积压缓冲区溢出其实也就是因为复制积压缓冲区是一个有限环形结构,一般主节点写入偏移量要大于从节点的读取偏移量,但如果写入偏移量覆盖了从节点的读取偏移量这就引发了复制积压缓冲区溢出。
Um den Überlauf des Replikations-Backlog-Puffers zu beheben
passen Sie normalerweise die Größe des Parameters repl_backlog_size an, erweitern Sie die Größe des Replikations-Backlog-Puffers und verringern Sie das Risiko, dass der Master-Knoten-Schreiboffset den Slave-Knoten-Leseoffset überschreibt.
Das obige ist der detaillierte Inhalt vonBeispielanalyse des Redis-Puffermechanismus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!