
Mit welcher Methode wird die Pika-Architektur des Redis-Speichersystems entworfen?

- 王林nach vorne
- 2023-05-29 20:07:171744Durchsuche
Pika ist ein effizientes, stabiles, einfaches und zuverlässiges Open-Source-NoSQL-Datenbankprodukt, das gemeinsam vom 360-Infrastrukturteam und dem DBA-Team entwickelt wurde. Es ist vollständig mit dem Redis-Protokoll kompatibel und unterstützt 5 Datenstrukturen (String, Hash, Liste, Set, Zset). Im Vergleich zur Redis-Speicherspeichermethode kann die Belegung der Serverressourcen erheblich reduziert werden erhöhen Sie die Datensicherheit. Es kann in zwei Modi bereitgestellt werden: Standalone und Cluster. Das Pika-Projekt wurde 2015 gestartet und wurde anschließend auf Github veröffentlicht. Derzeit hat es 3.700 Sterne und 35 Mitwirkende. Die Community verfügt über eine große Anzahl von Online-Unternehmen, die Pika nutzen.
Vergleichen Sie Redis
Speicherkapazität: Redis speichert im Speicher, hat hohe Hardwarekosten und eine hohe Ausfallzeit bei der Wiederherstellung; Pika leiht sich RocksDB aus, um es auf der Festplatte zu speichern, und die von einem einzelnen Server gespeicherte Datenmenge ist Dutzende Male so hoch wie die von Redis und die Wiederherstellungsgeschwindigkeit nach Ausfallzeiten ist schnell.
Durchsatz: Redis QPS ist höher, mit einer Million QPS auf einem einzelnen Server; Pika QPS ist relativ niedrig, Hunderttausende auf einem einzelnen Server, und Redis ist drei- bis fünfmal so hoch wie Pika.
Zugriffslatenz: Redis sollte innerhalb von 1 ms liegen; die Pika-Latenz ist etwas höher, innerhalb von 3 ms.
Betriebs- und Wartungsbereitstellung: Redis unterstützt zwei Methoden: Standalone-Master-Slave und Cluster; Pika unterstützt auch zwei Bereitstellungsmethoden.
Anwendbare Szenarien
Wenn das Datenvolumen des Geschäftsszenarios relativ groß ist (>50 GB) und die Anforderungen an die Datenzuverlässigkeit hoch sind, kann Pika Ihr Problem lösen.
Szenario 1: Zwischenergebnisspeicherung für große Datenverarbeitungssysteme
Szenario 2: Geschäftssysteme, die Redis/Redis-Cluster zur dauerhaften Speicherung verwenden
Szenario 3: Metadatenspeicherung für große verteilte Systeme
Architekturdesign
Pika Sie können Pika im klassischen Modus (Classic) oder im verteilten Modus (Sharding) ausführen, indem Sie das Instanzmodus-Konfigurationselement in der Konfigurationsdatei auf „Klassisch“ und „Sharding“ setzen. Architektur im klassischen Modus Instanz. Eine Instanz unterstützt mehrere DBs. Mit den Konfigurationselementdatenbanken von Pika können Sie die maximale Anzahl von DBs festlegen, die erstellt werden können, standardmäßig beginnend bei 0. Die physische Form der Datenbank auf Pika ist ein Dateiverzeichnis.
Architektur im verteilten Modus
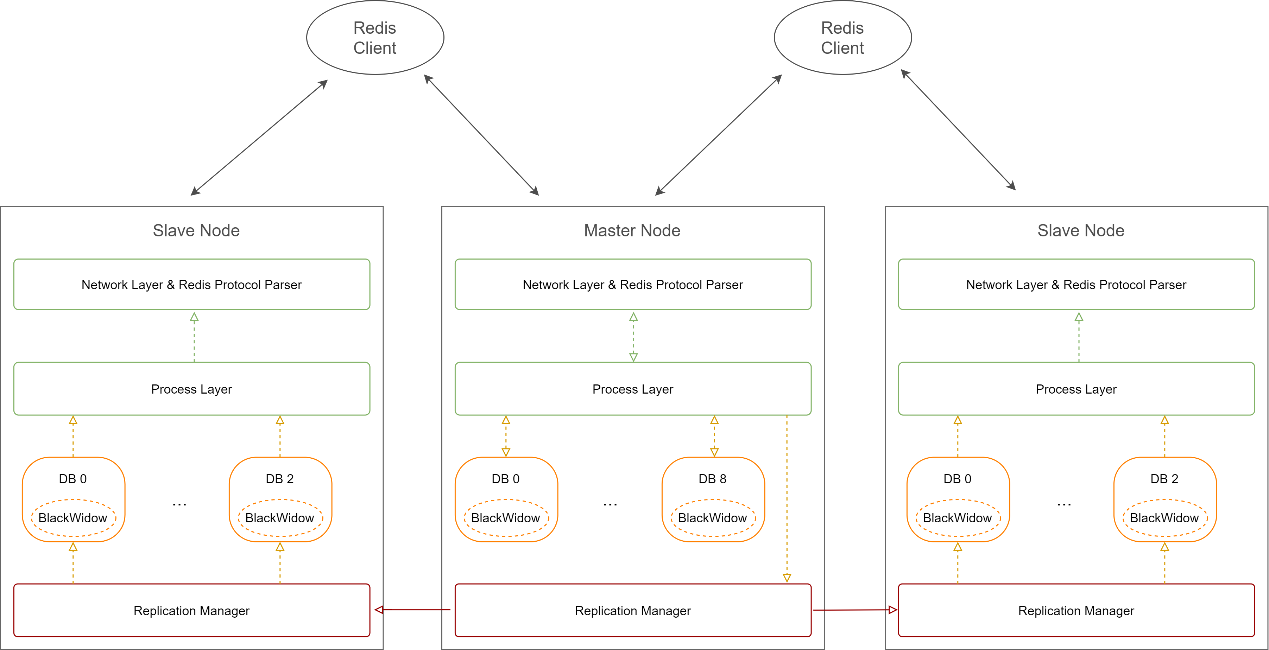
Verteilter Modus (Sharding): Im Sharding-Modus wird die vom Benutzer gespeicherte Datensammlung als Tabelle bezeichnet, und jede Tabelle ist in mehrere Shards unterteilt. Es wird Slot genannt , und die Daten eines bestimmten SCHLÜSSELS werden durch einen Hash-Algorithmus berechnet, um zu bestimmen, zu welchem Slot er gehört. Verteilen Sie alle Slots und ihre Kopien gemäß einer bestimmten Strategie auf alle Pika-Instanzen. Jede Pika-Instanz verfügt über einen Teil des Master-Slots und einen Teil des Slave-Slots. Im Sharding-Modus wird Slot zur Aufteilung von Master und Slave verwendet, und Pika-Instanzen werden nicht mehr verwendet. Die physische Form des Slots auf Pika ist ein Dateiverzeichnis.
Das obige ist der detaillierte Inhalt vonMit welcher Methode wird die Pika-Architektur des Redis-Speichersystems entworfen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!