
Heim >Technologie-Peripheriegeräte >KI >Die Praxis des Graphalgorithmus im Alibaba-Risikokontrollsystem
Die Praxis des Graphalgorithmus im Alibaba-Risikokontrollsystem

- 王林nach vorne
- 2023-05-29 19:28:041434Durchsuche

1. Einführung in Graphalgorithmen in E-Commerce-Risikokontrollszenarien
Lassen Sie uns zunächst kurz die Risikomerkmale des E-Commerce von Alibaba sowie die Anwendungsgeschichte und aktuelle Situation von Graphalgorithmen skizzieren.
1. Alibaba-E-Commerce-Risikomerkmale
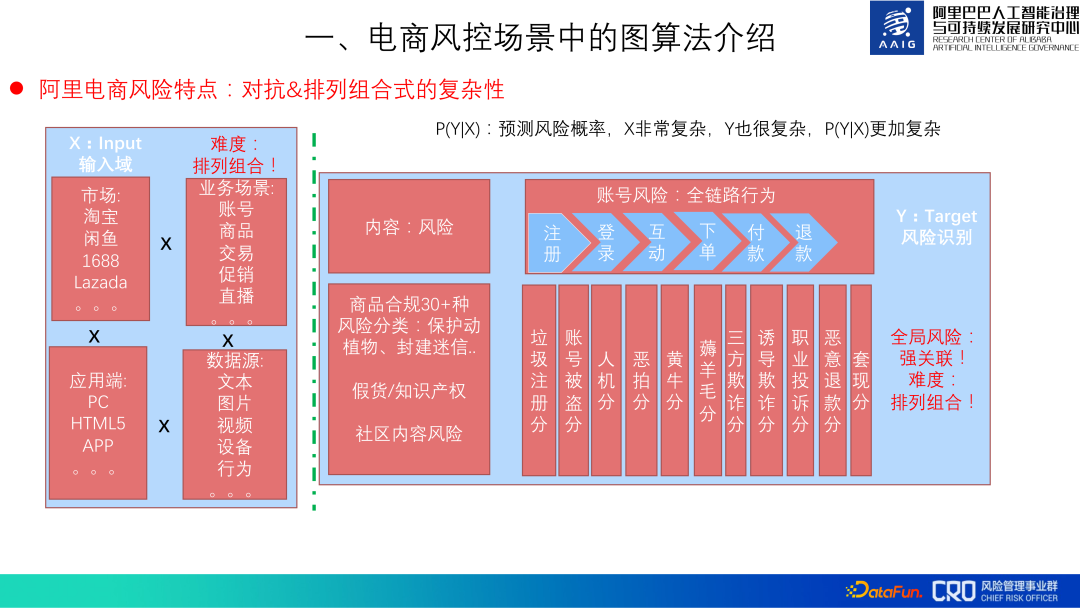
Die Hauptmerkmale von Alibaba-E-Commerce-Risiken: Konfrontation und Permutation sowie Kombinationskomplexität.
Risiken müssen konfrontativ sein, und gleichzeitig sind die Risiken des Alibaba-E-Commerce in ihren Permutationen und Kombinationen auch komplex. Bei der Risikoidentifizierung werden hauptsächlich X (Daten) verwendet, um Y (Risiko) vorherzusagen: P(Y|X). Im Alibaba-E-Commerce sind die Risikomerkmale unterschiedlich; -- PC, H5, APP usw., beide Seiten müssen verhindert und kontrolliert werden.
④ Verschiedene Datenquellen erfordern die Fähigkeit, Daten in unterschiedlichen Modalitäten zu verarbeiten und zu integrieren.
Gleichzeitig ist Y auch sehr kompliziert, was sich hauptsächlich in drei Aspekten widerspiegelt: Es gibt viele Arten von Risiken, Verhaltensrisiken usw. sind nur ein Tropfen auf den heißen Stein. Das zweite besteht darin, dass diese Risiken mit der Registrierung, dem Diebstahl und dem Produktinhalt zusammenhängen. Drittens werden Risiken besser verhindert und die Kosten für die Begehung einer Straftat hoch sind, wird sie auf andere Risiken übertragen oder neue Risiken schaffen.
Die gesamte Risikoprävention und -kontrolle ist also sehr kompliziert, mit Permutationen und Kombinationen von Komplexität.
2. Die Bedeutung von Diagrammalgorithmen
Diagrammalgorithmen können die Konfrontationsfähigkeit von Risikoidentifizierungsmodellen verbessern. Die meisten „schlechten Dinge“ auf der Plattform werden nur von wenigen Leuten begangen. Die „Bösen“ haben viele Westen. Wir können die Hinweise durch „Beziehungen“ herausfinden und sie im Voraus identifizieren und behandeln. Zum Beispiel der gelbe Punkt im Bild unten. Unter der Annahme, dass es sich um einen Benutzer mit abnormalem Verhalten handelt, ist es schwierig, allein aufgrund seines eigenen Verhaltens zu beurteilen, dass es sich um einen betrügerischen Benutzer handelt. Dies kann jedoch durch die Analyse der anderen drei betrügerischen Benutzer analysiert werden mit ihm in Verbindung stehenden Daten (schwarze Punkte) aus, um festzustellen, dass es sich um einen betrügerischen Benutzer handelt. Gleichzeitig haben wir alle Konten gefunden, die in engem Zusammenhang mit diesen vier Konten stehen, und festgestellt, dass es sich um eine Gruppe handelt. Die stapelweise Bearbeitung dieser Konten im Voraus kann die Kosten für die Begehung von Bösem erhöhen.
Darüber hinaus kann der heterogene Graph die Daten jeder Modalität und jedes Risikoobjekts auf natürliche und globale Weise integrieren, die Darstellung jedes einzelnen Objekts berechnen und dann verschiedene Risiken identifizieren, um mit Permutationen umzugehen und Kombinationen. Die Komplexität von
3. Die Geschichte und aktuelle Situation von Diagrammalgorithmen
Basierend auf der Bedeutung von Diagrammalgorithmen verwendet Alibaba E-Commerce-Risikokontrolle seit 2013 Diagrammalgorithmen.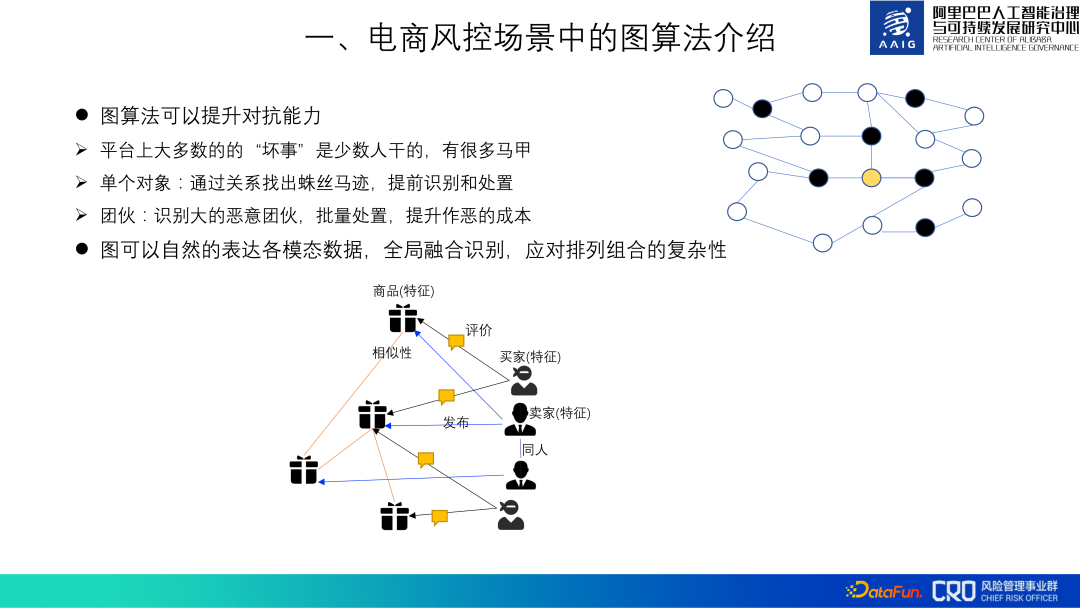
Zunächst wurden Diagrammalgorithmen verwendet, um das Beziehungsnetzwerk der gesamten Kontobibliothek aufzubauen. Bei diesen relationalen Daten handelt es sich um die Basisdaten, die für alle Risikopräventions- und Kontrollszenarien wie Betrug, Kontosicherheit, Betrugsbekämpfung und Produktfälschungen erforderlich sind. Zu den wichtigsten verwendeten Daten gehören Mediendaten wie Geräteinformationen und Mobiltelefonnummern. Es beschreibt hauptsächlich die Korrelation zwischen Konten, Beziehungstypen, Gruppenidentifikation usw. Für dieses Beziehungsnetzwerk wurde ein geschlossener Feedbackkanal von der Produktion bis zur Anwendung etabliert. Es liegen viele relationale Daten zugrunde. Die Gesamtkosten für die Aggregation, Bereinigung, Diagrammberechnung und Speicherung relationaler Daten sind sehr hoch und müssen später kontinuierlich aktualisiert werden, sodass die Kosten für den Aufbau eines relationalen Netzwerks sehr hoch sind Aber weil viele unserer Risikomodelle und -strategien auf diesem Beziehungsnetzwerk basieren, lohnt es sich trotzdem. 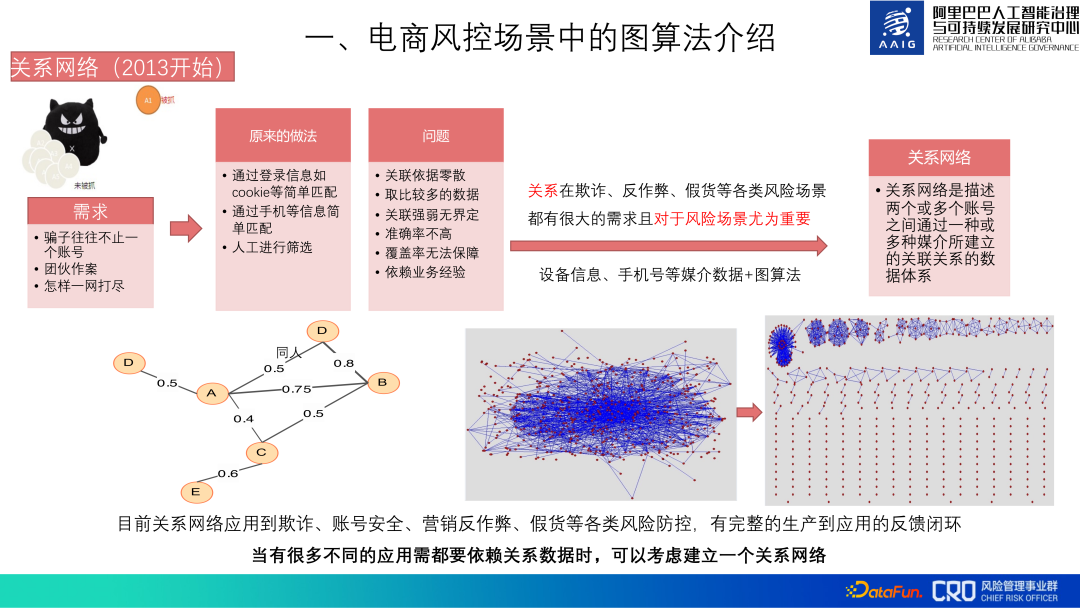
Was graphische neuronale Netze betrifft, haben wir 2016 begonnen, Anwendungen zu erforschen. Damals hießen wir noch GGL (Geometrisches Graphenlernen, geometrisches Graphenlernen). Kein direkt verfügbares Netzwerkalgorithmus-Framework, daher haben wir ein GGL-Algorithmus-Framework in C++ implementiert. Im Jahr 2018 wurde es auf Graph Learn umgestellt, das von Alibaba Computing Platform bereitgestellt wird. Dieses Framework ist ebenfalls Open Source. Wir haben auch einige Graph-Algorithmus-Codes zu diesem Framework beigetragen.
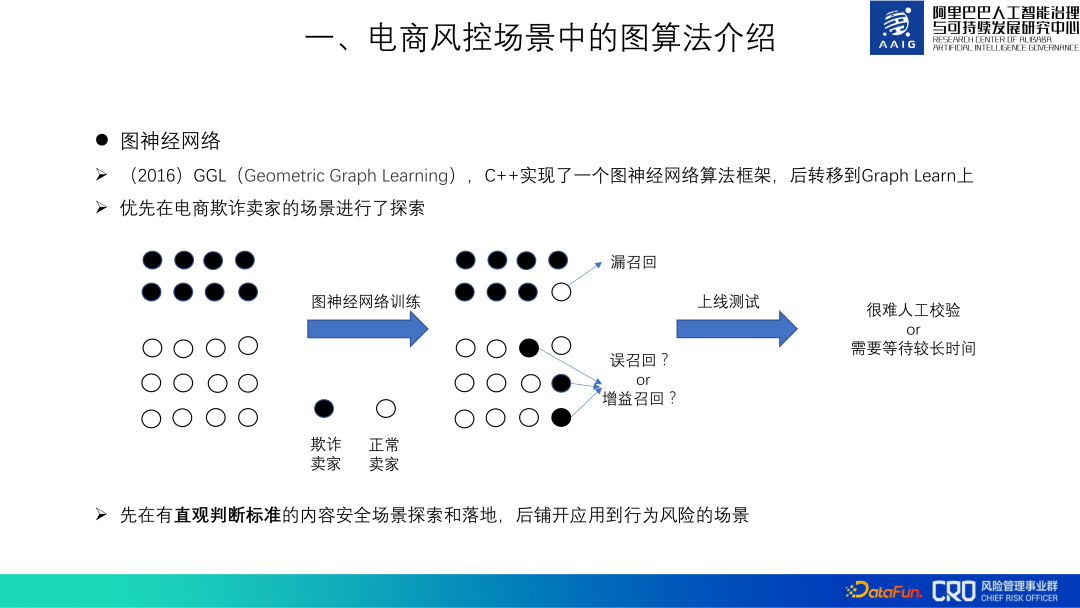
Es gibt viele Szenarien zur Risikokontrolle im E-Commerce, und es ist besonders wichtig, während der Verifizierungsphase des Diagrammalgorithmus das geeignete Szenario auszuwählen. Die „Beurteilungskriterien“ für Verhaltensrisiken, die in Risikoszenarien einen großen Anteil ausmachen, sind nicht intuitiv. In Industrieszenarien werden weiße Stichproben von Verhaltensrisiken mit vielen unentdeckten schwarzen Stichproben vermischt, wenn der Diagrammalgorithmus die weißen Stichproben als schwarz beurteilt Bei Proben ist es schwierig zu beurteilen, ob es sich um schwarze Proben handelt oder nicht. Unabhängig davon, ob es sich um einen falschen Rückruf oder einen Verstärkungsrückruf handelt, wirkt sich dies auf die Abstimmung des Modells und die Beurteilung des Online-Effekts aus. Im Gegenteil, Inhaltssicherheitsszenarien wie Spam und Beleidigungen sind Szenarien mit „intuitiven Beurteilungskriterien“ und eignen sich besser zur Überprüfung der Wirksamkeit von Diagrammalgorithmen. Daher untersuchen wir den Algorithmus zunächst in Inhaltssicherheitsszenarien, überprüfen seine Wirksamkeit, sammeln Best Practices und wenden ihn dann auf Verhaltensrisikoszenarien an.
Bisher werden Graph-Algorithmen in verschiedenen Risikogeschäften des Alibaba-E-Commerce eingesetzt. Das gesamte Anwendungsframework für Diagrammalgorithmen sieht wie folgt aus: Zunächst wird unten eine relationale Datenschicht verwaltet, um verschiedene relationale Daten zu sammeln und zu bereinigen, um die Anwendung der oberen Schicht zu erleichtern Die nächste Schicht nutzt die relationale Datenschicht und die Algorithmusschicht, um ein Kontobeziehungsnetzwerk aufzubauen, das die Prävention und Kontrolle verschiedener Risikoszenarien auf der obersten Geschäftsschicht unterstützt Mithilfe dieser Diagrammalgorithmen und relationalen Daten erstellen wir ein Diagrammmodell zur Identifizierung verschiedener Geschäftsrisiken.
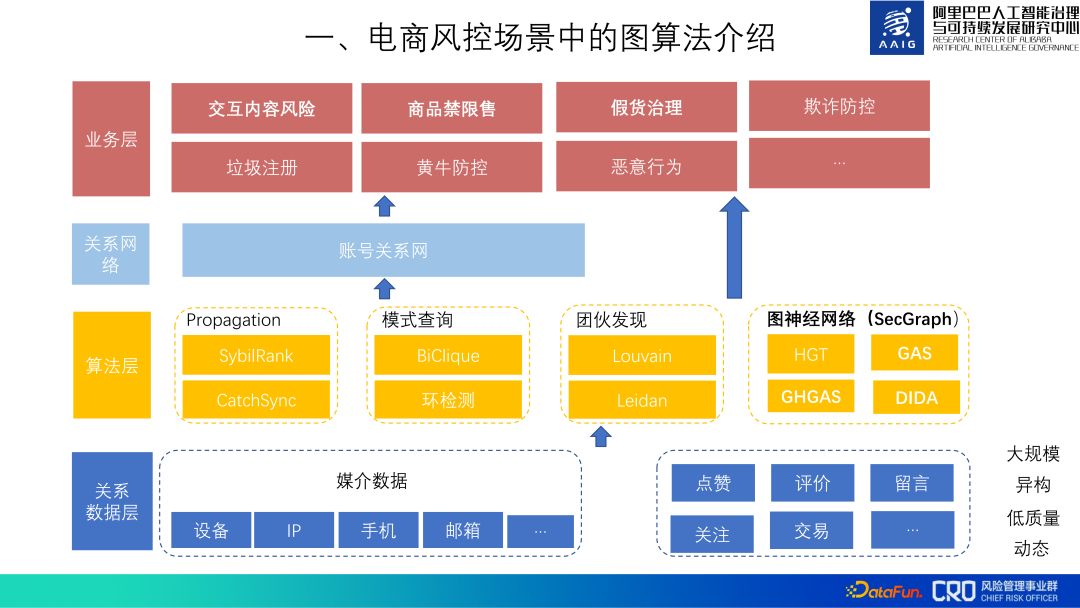
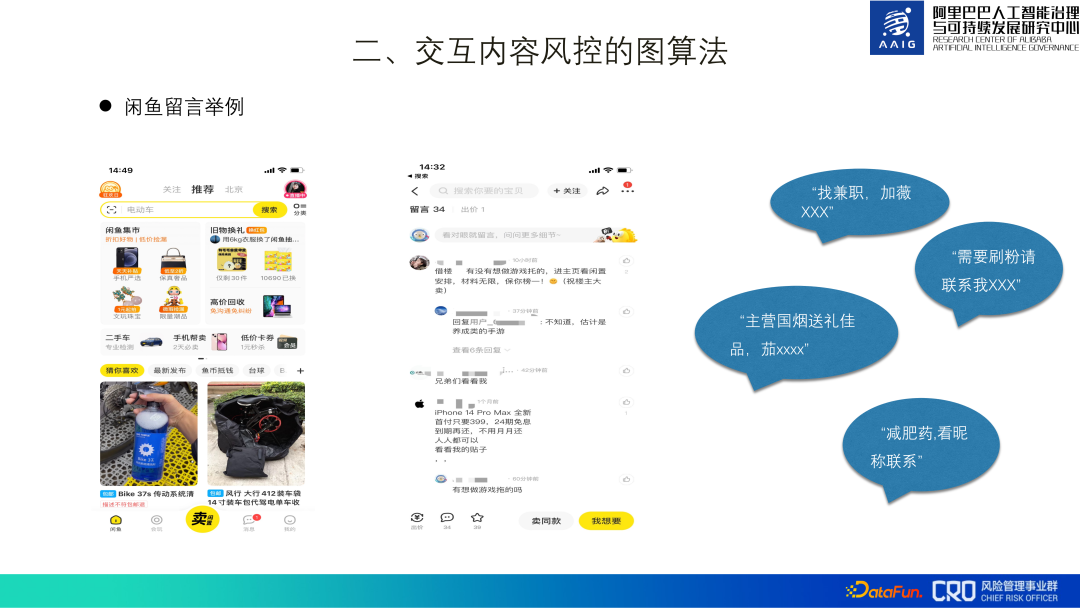
In der folgenden Freigabe werden hauptsächlich einige Diagrammalgorithmen für die drei Arten von Risikoanwendungen vorgestellt: „Interaktives Inhaltsrisiko“, „Warenverkaufsverbot und -beschränkung“ und „Verwaltung gefälschter Waren“. 2. Diagrammalgorithmus zur interaktiven Risikokontrolle von Inhalten usw. Im Folgenden wird die Identifizierung von Spam-Werbung in Xianyu-Nachrichten als Beispiel verwendet, um den Diagrammalgorithmus zur Inhaltsrisikokontrolle vorzustellen.
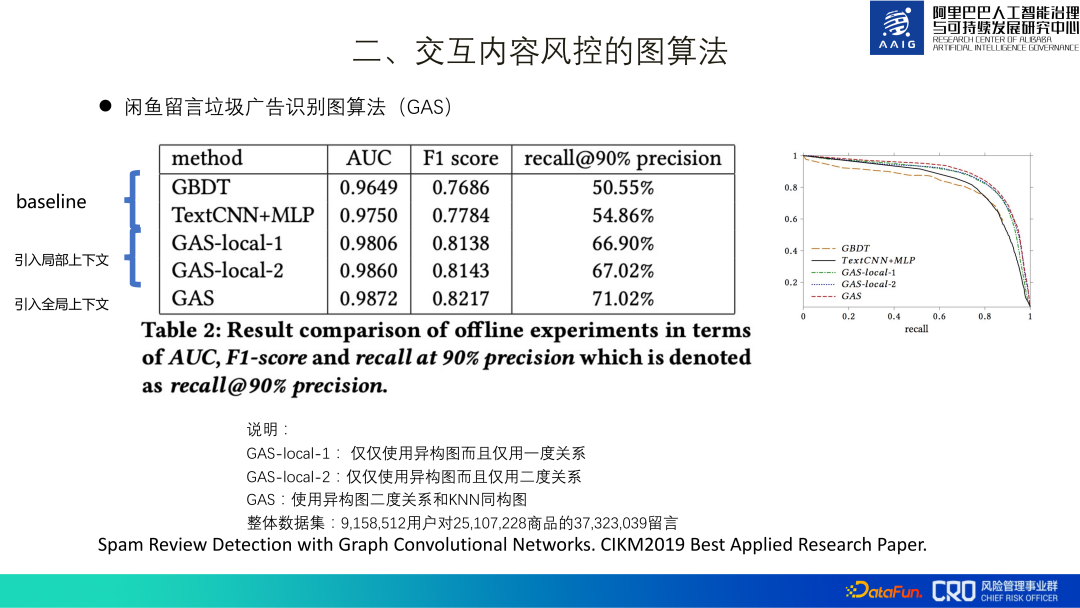
... , und sie sind sehr konfrontativ. Im obigen Screenshot von „Schau mich an, Bruder“ befindet sich die eigentliche Werbung nicht im Text selbst, sondern auf der Homepage des Benutzers.Die Identifizierung von Spam-Anzeigen in Xianyu-Nachrichten ist das erste Anwendungsszenario unseres Graph-Neuronalen-Netzwerk-Algorithmus. Wir nennen dieses Identifizierungsmodell kurz GAS. Das gesamte Modell besteht aus einem heterogenen Graphen und einem homogenen Graphen. Der heterogene Graph lernt die lokale Darstellung jedes Knotens, einschließlich Produkte, Kommentare und Benutzer. Der homogene Graph ist ein Kommentargraph, der die globale Darstellung verschiedener Kommentare lernt. Schließlich werden diese vier Darstellungen für das Training des binären Klassifizierungsmodells zusammengeführt.
Der gesamte Trainingsdatensatz umfasst mehr als 3 kW Kommentare, mehr als 2 kW Produkte und mehr als 9 Millionen Benutzer. Nach der Online-Bereitstellung wurden 30 % mehr Risiken als beim ursprünglichen MLP-Modell festgestellt. Darüber hinaus haben Ablationsexperimente auch bestätigt, dass das Hinzufügen globaler Informationen erheblich verbessert wird. Dies ist auf die Eigenschaften der Spam-Werbung selbst zurückzuführen – sie erfordert eine große Anzahl von Weiterleitungen, um bessere Renditen zu erzielen. Diese Arbeit wurde schließlich zusammengestellt und in Papierform veröffentlicht[1] und gewann die Auszeichnung „Best Applied Research Paper“ des CIKM2019. 3. Diagrammalgorithmus für die Risikokontrolle von Produktinhalten Produktgraph Integration von Struktur- und Fachwissensgraph.
Warenrisikomanagement dient hauptsächlich der Kontrolle des Risikos von „verbotenen und eingeschränkten Verkäufen“. Viele Arten von Waren dürfen gemäß den nationalen Gesetzen und Vorschriften, wie zum Beispiel dem nationalen Tier- und Pflanzenschutz, nicht verkauft werden und Fälschungen, kontrollierte medizinische Geräte usw.
Die Verwaltung und Steuerung von Produkten ist sehr komplex:

Titel , Beschreibung, Hauptbild, Untertitel Bilder, Detailbilder, SKU;
② Mehrkanal:
der Ton, die Form und die Bedeutung des Textes, das RGB des Bildes; ③ Multimodal:
Text, Bilder, Metainformationen (Preis, Verkaufsvolumen). Gleichzeitig sind die Risiken des Produktinhalts auch komplex, vielfältig und hart umkämpft. Auf dem Bild oben sieht es beispielsweise so aus, als würde es sich um den Verkauf von Perlen handeln, in Wirklichkeit handelt es sich jedoch um den Verkauf von Elfenbein.
Es gibt zwei Haupttypen von Algorithmen zur Risikokontrollkarte für Produktinhalte: Einer ist ein multimodales Fusionsmodell, das ein tiefes Modell zum Aufbau eines neuronalen Produktnetzwerks verwendet und durch multimodale Fusion Multitasking-Lernen durchführt Die andere besteht darin, die Erinnerung an Risiken zu verbessern, indem heterogene Diagramme verwendet werden, um die Beziehung zwischen Produkten und Produkten, Produkten und Verkäufern, Verkäufern und Verkäufern herzustellen und das Fusionslernen globaler Informationen durchzuführen. 1. Diagrammstrukturlernen von Produktdiagrammen
Das Wesentliche von GCN ist die Merkmalsglättung benachbarter Merkmale. Daher stellt das Lernen von Diagrammneuronalen Netzen bestimmte Anforderungen an die Qualität der Diagrammstruktur Ein guter Netzwerkgraph ist dicht und die Homogenitätsrate ist hoch. Allerdings ist das Risikoproduktdiagramm spärlich und die Homogenitätsrate relativ niedrig (0,15, und Statistiken zu öffentlichen Datensätzen haben ergeben, dass 0,6 oder mehr besser ist), daher müssen wir die Diagrammstruktur lernen.
Es gibt drei Arten von Kanten im Produktdiagramm, die drei Arten von Diagrammen darstellen, wie im Rahmen auf der rechten Seite der Abbildung unten dargestellt: Bei einem handelt es sich um zwei Produkte, die vom selben Verkäufer verkauft werden und derselbe Verkäufer, der zweite ist zwei. Das gleich durchsuchte Bild zeigt, dass das Produkt von demselben Verbraucher angesehen wurde. Die dritte Kategorie ist das zugehörige Verkäuferbild, bei dem die Verkäufer zweier Produkte eng miteinander verbunden sind.
Das Wesentliche beim Erlernen der Produktdiagrammstruktur ist der Prozess des Hinzufügens und Löschens von Kanten: Verwenden Sie zunächst KNN Graph, um ein KNN-Diagramm basierend auf der Produkteinbettung zu erstellen, und fügen Sie dann die oben genannten vier Arten von Kanten und Produkteinbettungen in HGT ein Lernen Sie die neue Einbettung des Produkts kennen und achten Sie darauf. Die Kanten mit niedrigeren Werten werden als Rauschen gelöscht, und die neue Produkteinbettung kann zum Aktualisieren des KNN-Diagramms verwendet werden, bis der Verlust konvergiert . Die Praxis in realen Daten zeigt, dass dieses Lernframework für die Graphenstruktur SOTA-Ergebnisse im Vergleich zu homogenen Graphen/heterogenen Graphen erzielt.
2. Integration von Graph Computing und Risk Knowledge Graph
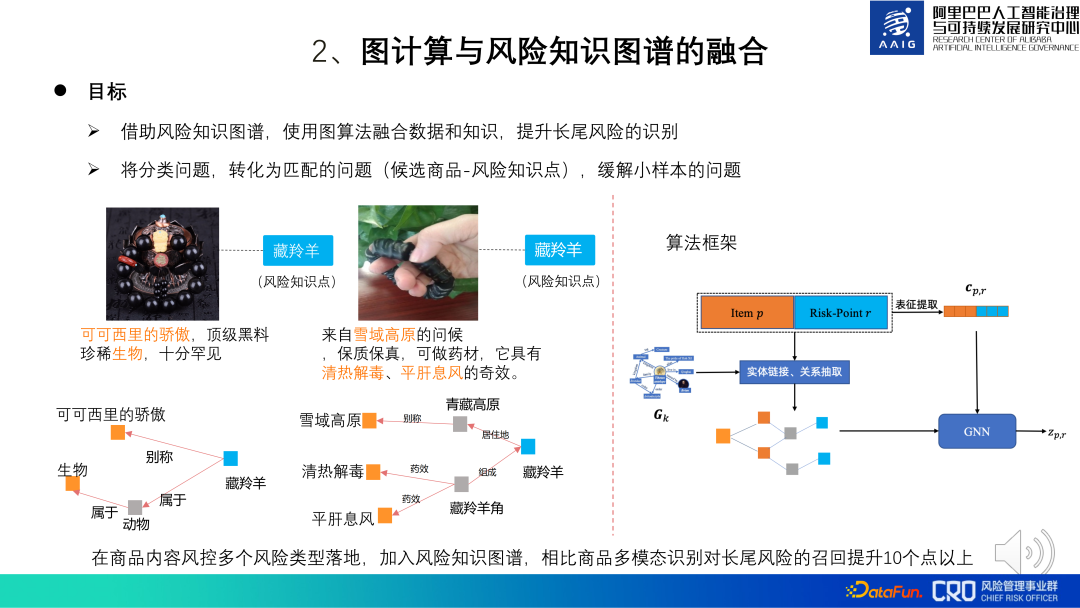
Der Verbesserungsalgorithmus des Produktgraph-Algorithmus ist die Fusion von Graph Computing und Risk Knowledge Graph. Manche Rohstoffrisiken sind mit gesundem Menschenverstand schwer zu beurteilen und erfordern eine Kombination bestimmter Fachkenntnisse. Daher wurden für diese spezifischen Risikodomänen-Wissenspunkte spezifische Wissensgraphen erstellt, um die Modellidentifizierung und manuelle Überprüfung zu unterstützen.
Zum Beispiel scheinen die beiden auf der linken Seite des Bildes unten gezeigten Produkte einfache Accessoires zu verkaufen, in Wirklichkeit handelt es sich jedoch um tibetische Antilopenhörner. Die tibetische Antilope ist ein landesweit geschütztes Tier der ersten Stufe Der Verkauf der damit verbundenen Produkte ist verboten. Wir können das Risiko dieses Produkts ermitteln, indem wir es mit dem Wissen über tibetische Antilopen abgleichen. Das Fusionsalgorithmus-Framework ist auf der rechten Seite der folgenden Abbildung dargestellt: Das Ziel des Modells besteht darin, zu bestimmen, ob Kandidatenprodukte und Risikowissenspunkte übereinstimmen. Element p ist die grafische Darstellung des Produkts und Risikopunkt R ist die Darstellung des Wissenspunkts. Durch Entitätserkennung, Entitätsverknüpfung und Beziehungsextraktion werden der Untergraph des Produkts und der Wissenspunkt erhalten und dann GNN verwendet Um die Darstellung des Untergraphen zu berechnen, wird diese Darstellung schließlich verwendet. Führen Sie eine Risikoklassifizierung und -identifizierung durch. Unter diesen ist CPR eine Kombination aus Produktdarstellung und Wissenspunktdarstellung. Es wird hauptsächlich zur Steuerung der Diagrammdarstellung zum Erlernen einiger globaler Informationen verwendet. Die Praxis zeigt, dass im Vergleich zur multimodalen Produkterkennung die Erinnerung an Long-Tail-Risiken durch das Hinzufügen von Risikowissensdiagrammen um mehr als 10 Punkte verbessert wird.
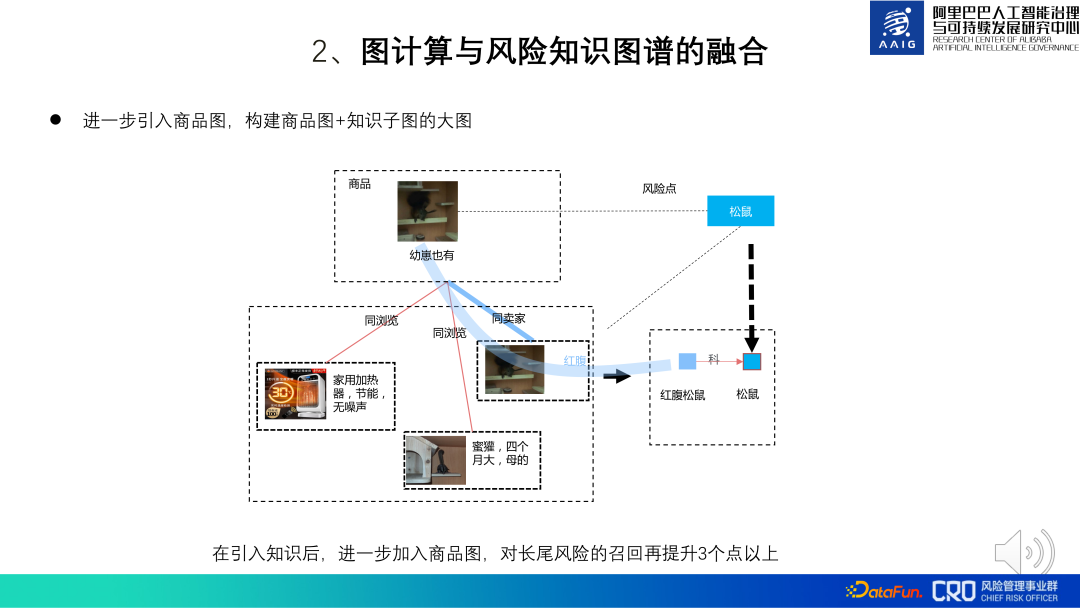
Auf dieser Basis haben wir auch versucht, eine globale Produktkarte einzuführen. Wenn der Produktinhalt in direktem Zusammenhang mit der Wissenskarte steht und das Risiko nicht identifiziert werden kann, kann die Assoziation zwischen dem Produkt und dem Produkt weiter eingeführt werden, um die Beurteilung zu erleichtern. Im Bild unten ist beispielsweise ein Produkt mit der Aufschrift „Es gibt auch.“ Cubs“ verfügt nicht über umfassende Kenntnisse über „Rotbauchhörnchen“. Es besteht eine übereinstimmende Beziehung, aber dieses Produkt stimmt mit den Kenntnissen des Verkäufers über ein anderes Produkt „Rotbauchhörnchen“ und „Rotbauchhörnchen“ überein, sodass darauf geschlossen werden kann Das Produkt verkauft tatsächlich Rotbauchhörnchen (sekundär geschützte Tiere, deren Verkauf verboten ist). Die Praxis hat gezeigt, dass die Einführung des gesamten großen Produktdiagramms bei der Wissensbegründung die Long-Tail-Risikoerinnerung um mehr als 3 % steigern kann.
4. Risikokontrollpraxis dynamischer heterogener Diagramme
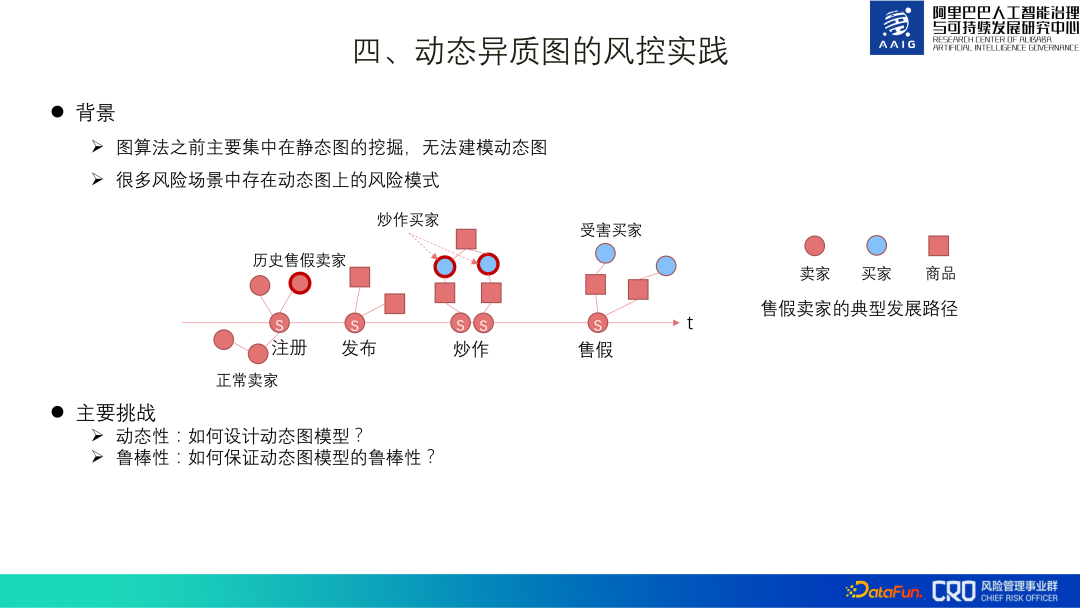
Die zuvor eingeführten Diagrammalgorithmen sind hauptsächlich statische Diagramm-Mining-Anwendungen, aber viele Risikoszenarien weisen Risikomuster dynamischer Diagramme auf.
Zum Beispiel registriert sich ein Händler, der gefälschte Waren verkauft, dann gibt er eine große Anzahl von Produkten in Chargen frei, wirbt sie, um Kunden anzulocken, und verkauft dann schnell gefälschte Waren Die Graphstruktur der Zeitdimension ist für unsere Risikoidentifikation sehr wichtig, daher sind dynamische Graphen auch eine Schlüsselrichtung für die Erforschung und Anwendung von Graphalgorithmen.
Die größte Herausforderung bei dynamischen Diagrammen besteht darin, eine gute Diagrammstruktur zu entwerfen und zu suchen. Einerseits führen dynamische Diagramme die Zeitdimension basierend auf dem ursprünglichen heterogenen Diagramm ein. Wenn es beispielsweise 30 Momente gibt, sind die Parameter (Informationsmenge) des dynamischen Diagramms 30-mal höher als die des heterogenen Diagramms, was große Vorteile bringt Lerndruck; Andererseits müssen dynamische Diagramme aufgrund der kontroversen Natur von Risiken äußerst robust sein.
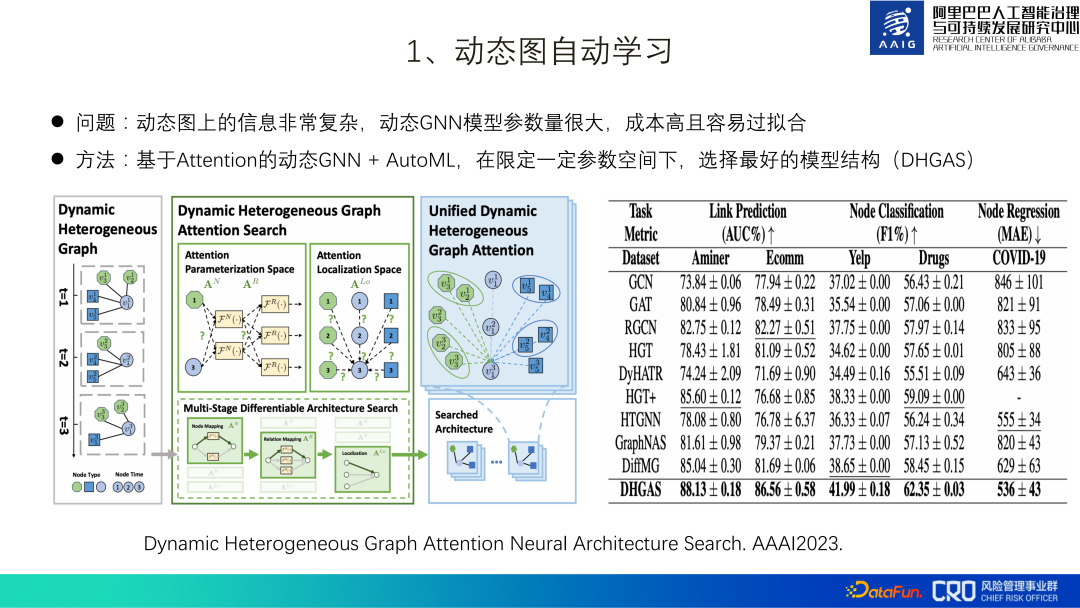
1. Automatisches Lernen mit dynamischem Diagramm
Dementsprechend schlagen wir ein dynamisches GNN + AutoML basierend auf Aufmerksamkeit vor und wählen die beste Modellstruktur (DHGAS) unter einem bestimmten Parameterraum aus. Der Kern dieses Modells besteht darin, die Modellstruktur durch automatisches Lernen zu optimieren, wie in der folgenden Abbildung dargestellt: Zunächst wird bevorzugt, den dynamischen Graphen zu unterschiedlichen Zeitpunkten in heterogene Graphen zu zerlegen und zu unterschiedlichen Zeitpunkten unterschiedliche Funktionsräume und unterschiedliche Knoten festzulegen stellen Änderungen in der Produktdarstellung dar (N*T-Typen, N: Knotentyp; T: Zeitraum), es werden auch verschiedene Funktionsräume für verschiedene Momente und verschiedene Kantentypen eingerichtet, um den Pfadraum der Informationsausbreitung darzustellen (R*T). Typen, R: Kantentyp; T: Zeit und Raum), und schließlich gibt es R*T*T-Aggregationsmethoden, wenn Knoten und Nachbarn aggregiert werden (die beiden T sind die Zeitstempel der Knoten an beiden Enden der Kante.
Natürlich ist der gesamte Suchraum riesig. Wir versuchen, den Parameterraum zu begrenzen und verwenden automatische maschinelle Lerntechnologie, um ein Supernetz aufzubauen, damit das Modell automatisch nach der optimalen Netzwerkarchitektur suchen kann. Spezifische Methode: Begrenzen Sie die Anzahl der Funktionsräume von N*T auf K_N, die Funktionsraumdaten von R*T auf K_R und die Modullänge von R*T*T auf K_Lo. Beispiel: N=6, T=30 , die Theorie ist N*T=180 Funktionsraum, die tatsächliche Grenze ist K_N=10.
Dieser Algorithmus wurde derzeit in Szenarien wie „Identifizierung gefälschter Verkäufer“ und „Identifizierung böswilliger Händler mit eingeschränktem Warenverkauf“ implementiert und mit gängigen Algorithmen in der Branche verglichen. Weitere Informationen erhalten Sie siehe Papier [2].
2. Robustes Lernen dynamischer Diagramme
Aufgrund der konfrontativen Natur von Risiken müssen dynamische Diagramme eine starke Robustheit aufweisen: Ich hoffe, dass dynamische Diagramme einige wesentliche Dinge lernen können Muster Das wesentliche Muster des Beispiel-Unterdiagramms in der Abbildung unten besteht beispielsweise darin, dass der Anstieg der Eisverkäufe auf das heißere Wetter und nicht auf die Zunahme der Zahl der Ertrinkenden zurückzuführen ist.
Wir hoffen, dass robustes Lernen einige Verteilungsverschiebungsprobleme dynamischer Diagramme zur E-Commerce-Risikokontrolle lösen kann:
(1) Funktionsverschiebung : Wenn Sie sich beispielsweise zu sehr verlassen auf Informationen zu historischen Verstößen. Diese Art von Funktion eignet sich nicht zum Rückruf neu registrierter problematischer Mitglieder. (2) Struktureller Versatz: Zum Beispiel übermäßiges Vertrauen in die Grad-Dichte-Unterstruktur von Spam. Werbemitglieder führen dazu, dass sehr aktive normale Mitglieder fälschlicherweise zurückgerufen werden. (3) Zeitversatz: Böswillige Benutzer werden durch Prävention und Kontrolle offensichtliche Verhaltensänderungen erfahren.
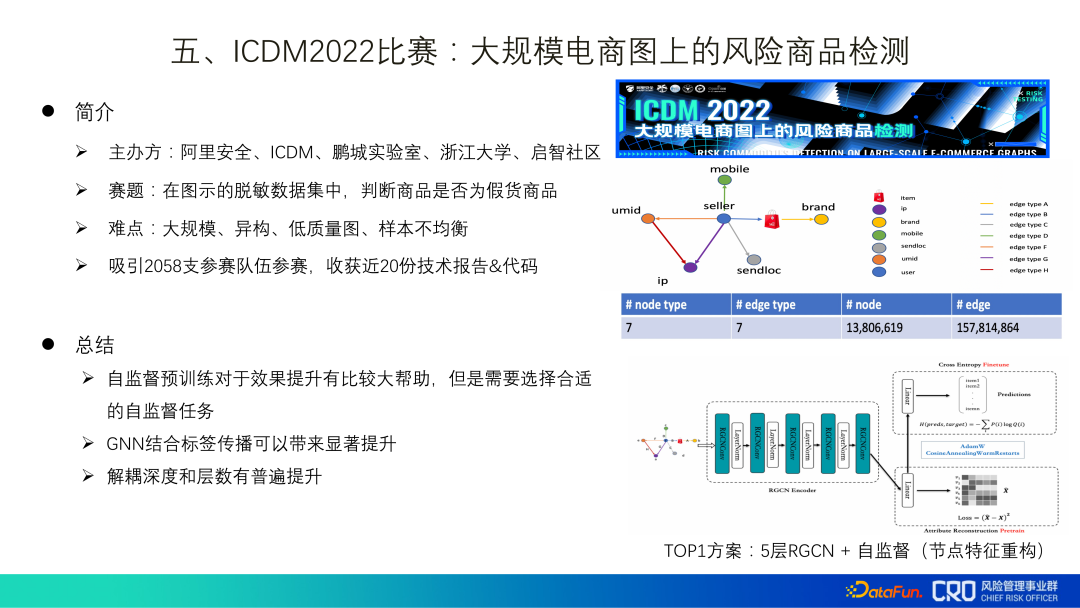
In diesem Zusammenhang haben wir einen DIDA-Algorithmus vorgeschlagen. Die Kernidee ist in der folgenden Abbildung dargestellt: Lernen Sie beim Lernen dynamischer Diagramme zwei Muster – das durch Orange dargestellte wesentliche Muster und das durch Orange dargestellte nicht wesentliche Muster von Green. Verwenden Sie einfach den Verlust (L) des wesentlichen Musters + die Verlustvarianz (Ldo) der Kombination nicht wesentlicher Muster als endgültigen Verlust, den das Modell erlernt. Die Entwurfsidee für die Verlustvarianz (Ldo) der Kombination nicht wesentlicher Muster lautet: Angenommen, das grüne A3 im Bild ist ein nicht wesentliches Muster, und dann wird dieses grüne A3 durch andere nicht wesentliche Muster ersetzt, z b3, c3 usw. sollten den Verlust (Diskriminierungsfähigkeit) des Modells kaum beeinflussen. Daher können wir die Verlustvarianz nicht wesentlicher Muster zum Modelllernen hinzufügen und in der letzten Vorhersagephase nur wesentliche Muster zur Klassifizierung verwenden. Derzeit wurde dieser Algorithmus in Szenarien zur Risikokontrolle von Produktinhalten implementiert und ein Papier[3] wurde ebenfalls erstellt. 5. ICDM2022-Wettbewerb: Erkennung riskanter Produkte in groß angelegten E-Commerce-Diagrammen Bei der diesjährigen Veranstaltung handelt es sich bei den bereitgestellten Daten um desensibilisierte Daten realer Szenen. Letztendlich habe ich auch einige Inspirationen aus den eingereichten technischen Codes und Berichten gewonnen:
(1) Selbstüberwachtes Vortraining ist eine große Hilfe bei der Verbesserung der Wirkung, aber es ist notwendig, das geeignete Selbst auszuwählen -Überwachte Aufgabe;(2) GNN in Kombination mit Label-Propagierung kann in früheren Graph-Algorithmus-Anwendungen aufgrund von Bedenken hinsichtlich Label-Lecks verworfen werden, aber nach der Übung in realen Daten, Es wurde festgestellt, dass es nicht offensichtlich war. Als Grund wird spekuliert, dass das aktuelle Graphennetzwerk nur eine Informationsfusion erreicht, aber noch keine Argumentation erreicht hat oder über schwache Argumentationsfähigkeiten verfügt Einmal übertragen und mehrmals gleichzeitig aggregiert. 6. Zusammenfassung und Ausblick auf die Implementierungsmethoden für Graphalgorithmen : sollte Es gibt ein Diagrammalgorithmus-Framework, das Technologien und Best Practices sammelt, um die Wiederverwendbarkeit von Technologien zu verbessern.
(2) Halbautomatische Modellierung: Um die Effizienz der Modellierung zu verbessern, sollten wir auf Datenebene die zugrunde liegenden relationalen Mediendaten besser bereinigen und zusammenfassen, und auf Modellierungsebene können wir einige Komponenten bereitstellen (MetaPath/MetaGraph-Auswahlkomponente, Graph-Sampling-Komponente, Vektorabrufkomponente usw.) zur Verbesserung der Modellierungseffizienz.
(3) Automatisierter Aufruf: Es kann automatisch Diagrammalgorithmen oder Diagrammmodelle aufrufen, die nur auf Eingabebeispielen basieren. Es ist nicht erforderlich, Diagrammmodelle zu verstehen, was für andere Risikokontrollstudenten, die nicht damit vertraut sind, praktisch ist Diagrammalgorithmen zur Optimierung der Verwendung von Modellen, z. B. Bandenidentifizierung, Produktwiederherstellung, Risikobenutzerwiederherstellung usw.
(4) Produktionsdiagrammdarstellung (selbstüberwacht): Wird als separate modale Eingabe in das Modell verwendet, ohne die ursprüngliche Modellierungsmethode zu beeinträchtigen, wodurch die Anwendungsszenarien von Diagrammen erheblich verbessert werden.
Aussichten für Folgearbeiten:
(1) Selbstüberwachtes Repräsentationslernen in großem Maßstab. Wir verfügen über Tausende von Risikomodellen, von denen viele den oben genannten Diagrammalgorithmus nicht anwenden. Daher besteht unser nächster Schritt darin, eine selbstüberwachte Diagrammdarstellung in großem Maßstab durchzuführen, um den Anwendungsbereich von Diagrammfunktionen zu erweitern und zur Verbesserung der Geschäftsergebnisse beizutragen. Diese Arbeit bringt zwei Herausforderungen in Bezug auf Technik und Algorithmen mit sich: Erstens haben wir in Bezug auf die Technik mindestens Milliarden von Knoten und Dutzende von Milliarden Kanten für groß angelegtes Lernen. Zweitens muss die Graphdarstellung in Bezug auf Algorithmen nicht nur allgemein abdecken Wenn Sie Beziehungsdarstellungen verwenden, müssen Sie auch die Eigenschaften von Diagrammstrukturen höherer Ordnung erlernen, die äußerst vielseitig sind und auf verschiedene Szenarien angewendet werden können.(2) Erkunden Sie die Argumentationsfähigkeiten von Diagrammen in bestimmten Risikokontrollszenarien. Derzeit geht es bei Diagrammalgorithmen eher um die Verschmelzung von Wissen, und die Argumentationsfähigkeiten sind relativ schwach und können der hohen Konfrontation mit Risiken nicht gerecht werden . Objektiv gesehen benötigen wir eine starke Intelligenz unseres Modells, daher ist die Argumentationsfähigkeit von Diagrammen sehr wichtig. Derzeit ist geplant, sich bei der Erforschung des Algorithmus auf die umfangreichen interaktiven Szenarien und Inhalte der Xianyu-Community zu verlassen.

(3) Mehr Erforschung und Implementierung in der Frequenzbereichsforschung und Interpretierbarkeit dynamischer heterogener Graphen. Der Zweck der Frequenzbereichsforschung besteht darin, mehr Details über Änderungen der Graphenstruktur in dynamischen Graphen zu erfahren. Die Interpretierbarkeit hilft uns zu verstehen, ob der Algorithmus die wesentlichen Eigenschaften wirklich gelernt hat. Einerseits hilft sie uns, den Algorithmus zu verbessern, andererseits kann er BWL-Studenten auch besser für die Anwendungsimplementierung zur Verfügung gestellt werden.
Wir suchen auch eine akademische Zusammenarbeit in den oben genannten Forschungsrichtungen, insbesondere in Richtung Graph Reasoning. Gleichzeitig rekrutieren wir auch Studierende für Graphalgorithmen. Interessierte Studierende können sich bei mir melden.
7. Referenz: Spam-Review-Erkennung mit Graph Convolutional Networks.
2

3. Dynamische graphische neuronale Netze unter räumlich-zeitlicher Verteilungsverschiebung. A1: Die drei Hauptherausforderungen sind: Erstens ist die Diagrammstruktur schlecht und die Homogenitätsrate ist niedrig; zweitens ist die Stabilität des Diagramms, insbesondere des dynamischen Diagramms, immer noch sehr Im Ernst, es gibt ein weiteres Problem, das nicht 1:10 oder 1:20 beträgt. In unserem Diagrammalgorithmus liegen einige Risikokonzentrationen über 1:1w extrem unausgeglichen, was wir lösen müssen. A2: Wir nutzen es immer noch hauptsächlich in unseren E-Commerce-Szenarien. Natürlich haben wir auch einige Nicht-E-Commerce-Unternehmen, aber diese Daten sind unsere eigenen und wir können sie trotzdem direkt zur Risikokontrolle verwenden Bisher wurde Föderiertes Lernen noch nicht verwendet, aber es wird später notwendig sein, Föderiertes Lernen zu verwenden, da Daten aus verschiedenen Domänen nicht verbunden und verwendet werden können, daher sollte Föderiertes Lernen später verwendet werden eine Anwendungsrichtung, die wir erkunden können. 8. Frage- und Antwortsitzung
F1: Was sind die besonderen Herausforderungen bei der grafischen Darstellung von Risikokontrollszenarien im Vergleich zur grafischen Darstellung in anderen Bereichen?
F2: Was ist das aktuelle Algorithmusmodell des Graph-Föderierten Lernens? Gibt es eine ausgereifte Lösung in der Branche? Haben Sie Anwendungen oder Überlegungen zum Graph-Föderierten Lernen?
Das obige ist der detaillierte Inhalt vonDie Praxis des Graphalgorithmus im Alibaba-Risikokontrollsystem. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr