
Heim >Technologie-Peripheriegeräte >KI >Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-28 14:12:441278Durchsuche
Deep-Learning-Modelle für visuelle Aufgaben (z. B. Bildklassifizierung) werden normalerweise durchgängig mit Daten aus einer einzelnen visuellen Domäne (z. B. natürlichen Bildern oder computergenerierten Bildern) trainiert.
Im Allgemeinen muss eine Anwendung, die visuelle Aufgaben für mehrere Felder ausführt, mehrere Modelle für jedes einzelne Feld erstellen und diese unabhängig voneinander trainieren. Während der Inferenz werden die feldspezifischen Eingabedaten jedes Modells verarbeitet .
Auch wenn sie auf unterschiedliche Bereiche ausgerichtet sind, sind einige Merkmale der frühen Schichten zwischen diesen Modellen ähnlich, sodass das gemeinsame Training dieser Modelle effizienter ist. Dies reduziert die Latenz und den Stromverbrauch und reduziert die Speicherkosten für die Speicherung jedes Modellparameters. Dieser Ansatz wird als Multi-Domain-Learning (MDL) bezeichnet.
Darüber hinaus können MDL-Modelle auch besser sein als Einzeldomänenmodelle. Zusätzliches Training in einer Domäne kann die Leistung des Modells in einer anderen Domäne verbessern, es kann jedoch auch zu negativen Ergebnissen führen Auswirkungen auf den Wissenstransfer, der von der Trainingsmethode und der spezifischen Domänenkombination abhängt. Obwohl frühere Arbeiten zu MDL die Wirksamkeit domänenübergreifender gemeinsamer Lernaufgaben gezeigt haben, handelt es sich dabei um eine handgefertigte Modellarchitektur, die bei der Anwendung auf andere Arbeiten ineffizient ist.

Link zum Papier: https://arxiv.org/pdf/2010.04904.pdf
Um dieses Problem zu lösen, wird in „Multi-path Neural Networks for On-device Multi -domain Im Artikel „Visual Classification“ schlugen Google-Forscher ein allgemeines MDL-Modell vor.
Der Artikel besagt, dass dieses Modell effektiv eine hohe Genauigkeit erreichen, den negativen Wissenstransfer reduzieren und lernen kann, den positiven Wissenstransfer beim Umgang mit Schwierigkeiten in verschiedenen spezifischen Bereichen zu verbessern.
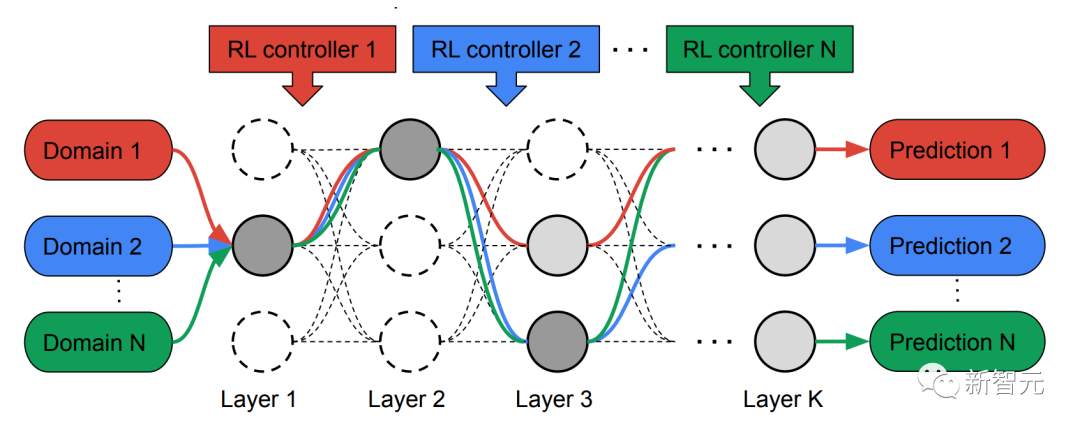
Zu diesem Zweck schlugen die Forscher eine MPNAS-Methode (Multi-Path Neural Architecture Search) vor, um ein einheitliches Modell mit heterogener Netzwerkarchitektur für mehrere Felder zu erstellen.
Diese Methode erweitert die effiziente Neural Architecture Search (NAS)-Methode von der Einzelpfadsuche auf die Mehrpfadsuche, um gemeinsam einen optimalen Pfad für jedes Feld zu finden. Außerdem wird eine neue Verlustfunktion namens Adaptive Balanced Domain Prioritization (ABDP) eingeführt, die sich an domänenspezifische Schwierigkeiten anpasst, um Modelle effizient zu trainieren. Die resultierende MPNAS-Methode ist effizient und skalierbar.
Obwohl keine Leistungseinbußen auftreten, reduziert das neue Modell die Modellgröße und FLOPS im Vergleich zu Einzeldomänenmethoden um 78 % bzw. 32 %.
Multipfad-Suche nach neuronalen Strukturen
Um einen positiven Wissenstransfer zu fördern und einen negativen Transfer zu vermeiden, besteht die traditionelle Lösung darin, ein MDL-Modell zu erstellen, sodass jede Domäne die meisten Schichten teilt und die gemeinsamen Funktionen jeder Domäne lernt (Feature-Extraktion genannt) und dann einige domänenspezifische Ebenen darauf aufbauen. Diese Merkmalsextraktionsmethode kann jedoch keine Domänen mit deutlich unterschiedlichen Merkmalen verarbeiten (z. B. Objekte in natürlichen Bildern und künstlerischen Gemälden). Andererseits ist der Aufbau einer einheitlichen heterogenen Struktur für jedes MDL-Modell zeitaufwändig und erfordert domänenspezifisches Wissen.
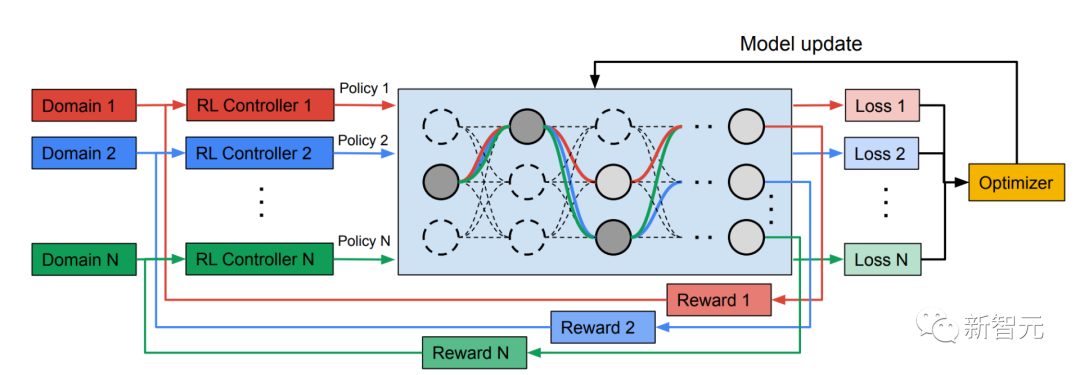
Multi-path Neural Search Architecture Framework NAS ist ein leistungsstarkes Paradigma für die automatische Gestaltung von Deep-Learning-Architekturen. Es definiert einen Suchraum, der aus verschiedenen potenziellen Bausteinen besteht, die Teil des endgültigen Modells werden können.
Der Suchalgorithmus findet die beste Kandidatenarchitektur aus dem Suchraum, um Modellziele wie Klassifizierungsgenauigkeit zu optimieren. Neuere NAS-Methoden wie TuNAS verbessern die Sucheffizienz durch die Verwendung von End-to-End-Path-Sampling.
Inspiriert von TuNAS erstellt MPNAS die MDL-Modellarchitektur in zwei Phasen: Suche und Training.
Um gemeinsam einen optimalen Pfad für jede Domäne zu finden, erstellt MPNAS in der Suchphase einen separaten Reinforcement Learning (RL)-Controller für jede Domäne, der im Supernetzwerk (d. h. zwischen den durch die Suche definierten Kandidatenknoten) beginnt Beispiel für End-to-End-Pfade (von der Eingabeschicht zur Ausgabeschicht) innerhalb einer Obermenge aller möglichen Teilnetzwerke.
Über mehrere Iterationen hinweg aktualisieren alle RL-Controller die Pfade, um die RL-Belohnungen in allen Bereichen zu optimieren. Am Ende der Suchphase erhalten wir für jede Domain ein Subnetzwerk. Abschließend werden alle Teilnetzwerke zusammengefasst, um eine heterogene Struktur für das MDL-Modell zu erstellen, wie in der folgenden Abbildung dargestellt.
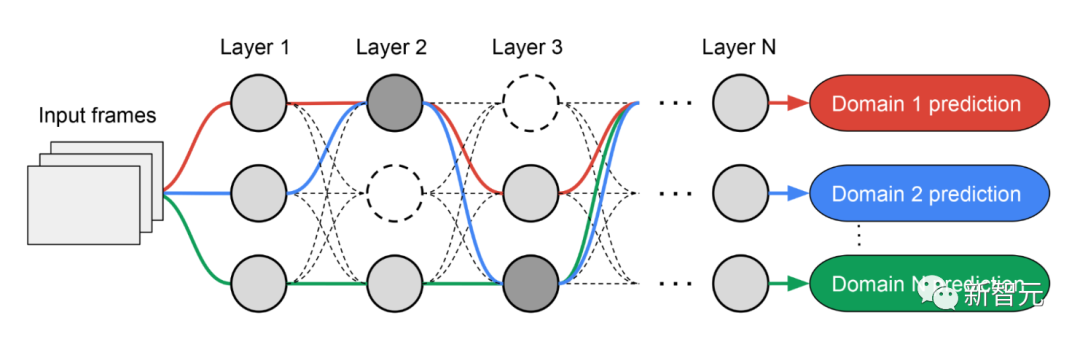
Da das Subnetzwerk jeder Domäne unabhängig durchsucht wird, können die Komponenten jeder Schicht von mehreren Domänen gemeinsam genutzt werden (d. h. dunkelgraue Knoten) und von einer einzelnen Domäne (d. h. hellgrau) verwendet werden Knoten) oder von keinem Subnetz verwendet wird (d. h. Punktknoten).
Der Pfad jeder Domain kann während des Suchvorgangs auch jede Ebene überspringen. Das Ausgabenetzwerk ist sowohl heterogen als auch effizient, da die Subnetzwerke frei wählen können, welche Blöcke sie unterwegs verwenden möchten, um die Leistung zu optimieren.
Die folgende Abbildung zeigt die Sucharchitektur von zwei Bereichen des Visual Domain Decathlon.
Visual Domain Decathlon ist Teil der PASCAL in Detail Workshop Challenge beim CVPR 2017 und testet die Fähigkeit visueller Erkennungsalgorithmen, viele verschiedene visuelle Domänen zu verarbeiten (oder auszunutzen). Wie man sehen kann, haben die Teilnetze dieser beiden stark verwandten Domänen (eine rote, die andere grüne) die meisten Bausteine ihrer überlappenden Pfade gemeinsam, es gibt jedoch immer noch Unterschiede zwischen ihnen.
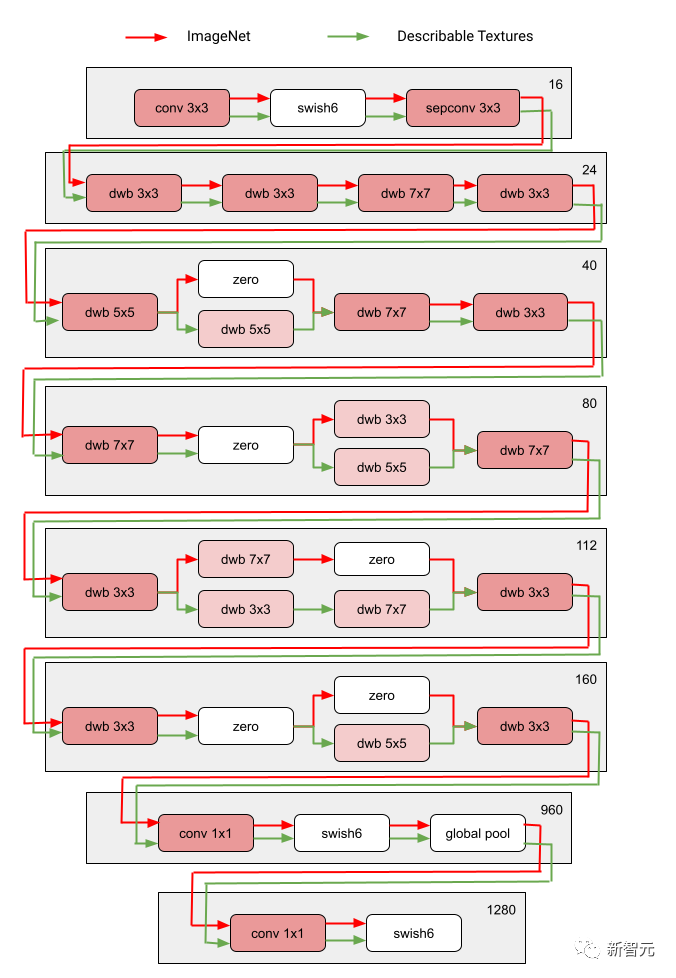
Die roten und grünen Pfade in der Abbildung stellen die Subnetzwerke von ImageNet bzw. Describable Textures dar, die dunkelrosa Knoten stellen Blöcke dar, die von mehreren Domänen gemeinsam genutzt werden, und die hellrosa Knoten stellen die Blöcke dar, die von jedem Pfad verwendet werden. Der „dwb“-Block im Diagramm stellt den dwbottleneck-Block dar. Der Nullblock in der Abbildung zeigt an, dass das Subnetz den Block überspringt Die folgende Abbildung zeigt die Pfadähnlichkeit in den beiden oben genannten Bereichen. Die Ähnlichkeit wird anhand des Jaccard-Ähnlichkeitswerts zwischen Subnetzen für jede Domäne gemessen, wobei ein höherer Wert mehr ähnliche Pfade bedeutet.

Das Bild zeigt die Verwirrungsmatrix der Jaccard-Ähnlichkeitswerte zwischen Pfaden in zehn Domänen. Der Wert liegt zwischen 0 und 1. Je höher der Wert, desto mehr Knoten teilen sich die beiden Pfade.
Heterogene Multidomänenmodelle trainieren
In der zweiten Phase werden die von MPNAS generierten Modelle für alle Domänen von Grund auf trainiert. Dazu ist es notwendig, eine einheitliche Zielfunktion für alle Domänen zu definieren. Um erfolgreich mit einer Vielzahl von Domänen umgehen zu können, haben die Forscher einen Algorithmus namens Adaptive Balanced Domain Prioritization (ABDP) entwickelt, der sich während des gesamten Lernprozesses anpasst, um Verluste zwischen den Domänen auszugleichen. Nachfolgend werden die Genauigkeit, Modellgröße und FLOPS von Modellen angezeigt, die unter verschiedenen Einstellungen trainiert wurden. Wir vergleichen MPNAS mit drei anderen Methoden:
Domänenunabhängiges NAS: Modelle werden für jede Domäne separat gesucht und trainiert.
Single Path Multi-Head: Verwenden Sie ein vorab trainiertes Modell als gemeinsames Rückgrat für alle Domänen mit separaten Klassifizierungsköpfen für jede Domäne.
Multi-Head-NAS: Durchsuchen Sie eine einheitliche Backbone-Architektur für alle Domänen mit separaten Klassifizierungsköpfen für jede Domäne.
Aus den Ergebnissen können wir erkennen, dass NAS für jede Domäne eine Reihe von Modellen erstellen muss, was zu großen Modellen führt. Obwohl Single-Path-Multi-Head- und Multi-Head-NAS die Modellgröße und FLOPS erheblich reduzieren können, führt die Erzwingung der gemeinsamen Nutzung desselben Backbones durch Domänen zu einem negativen Wissenstransfer und verringert dadurch die Gesamtgenauigkeit.

Im Gegensatz dazu kann MPNAS kleine und effiziente Modelle erstellen und dabei dennoch eine hohe Gesamtgenauigkeit beibehalten. Die durchschnittliche Genauigkeit von MPNAS ist sogar 1,9 % höher als die domänenunabhängige NAS-Methode, da das Modell einen aktiven Wissenstransfer erreichen kann. Die folgende Abbildung vergleicht die Top-1-Genauigkeit pro Domäne dieser Methoden.
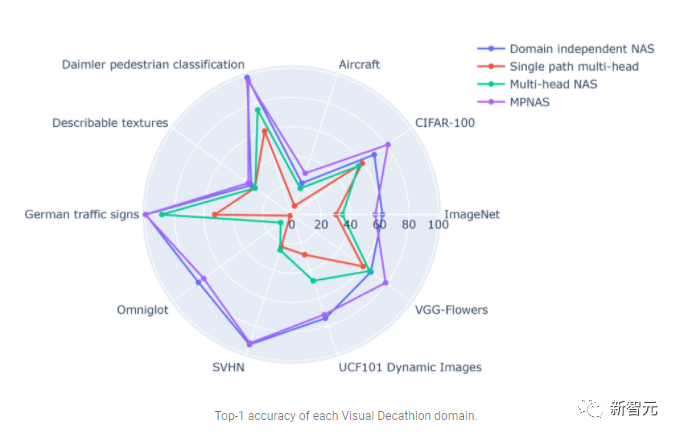
Die Auswertung zeigt, dass durch die Verwendung von ABDP als Teil der Such- und Trainingsphasen die Top-1-Genauigkeit von 69,96 % auf 71,78 % steigt (Delta: +1,81 %).
Zukünftige Richtungen
MPNAS ist eine effektive Lösung für den Aufbau heterogener Netzwerke, um Datenungleichgewicht, Domänenvielfalt, negative Migration, Domänenskalierbarkeit und großen Suchraum für mögliche Strategien zur Parameterfreigabe in MDL anzugehen. Durch die Verwendung eines MobileNet-ähnlichen Suchraums ist das generierte Modell auch mobilfreundlich. Für Aufgaben, die mit vorhandenen Suchalgorithmen nicht kompatibel sind, erweitern Forscher MPNAS weiterhin für das Lernen mit mehreren Aufgaben und hoffen, MPNAS zum Aufbau einheitlicher Multidomänenmodelle verwenden zu können.
Das obige ist der detaillierte Inhalt vonMultipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr