
Heim >Datenbank >MySQL-Tutorial >Welche Methoden gibt es zum Entfernen doppelter Abfragen in MySQL?
Welche Methoden gibt es zum Entfernen doppelter Abfragen in MySQL?

- 王林nach vorne
- 2023-05-27 21:23:0612772Durchsuche
1. Testdaten einfügen
In den Testdaten im Bild unten sind die Benutzer, deren Benutzernamen lilei und zhaofeng sind, doppelte Daten.
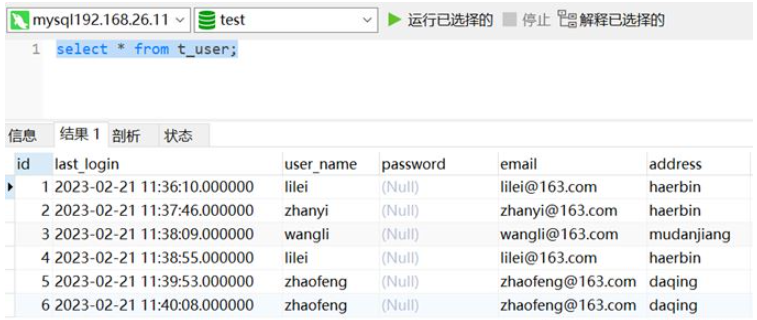
2. Methode zum Entfernen doppelter Daten
1. Methode 1: Verwenden Sie eindeutige
Der Code lautet wie folgt (Beispiel):
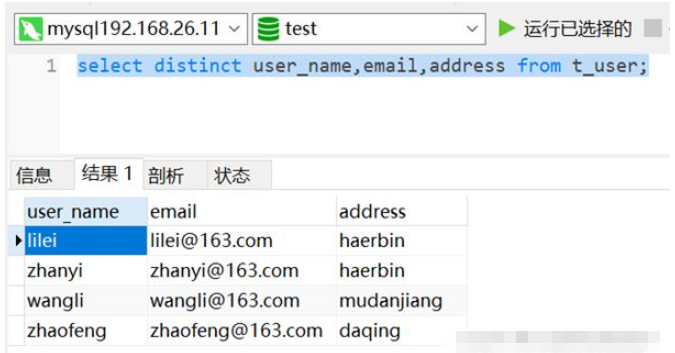
select distinct user_name,email,address from t_user;
Wie unten gezeigt, wurden die Daten entfernt und nur 1 Stück der doppelten Daten bleiben erhalten.
2. Methode 2: Gruppe nach verwenden
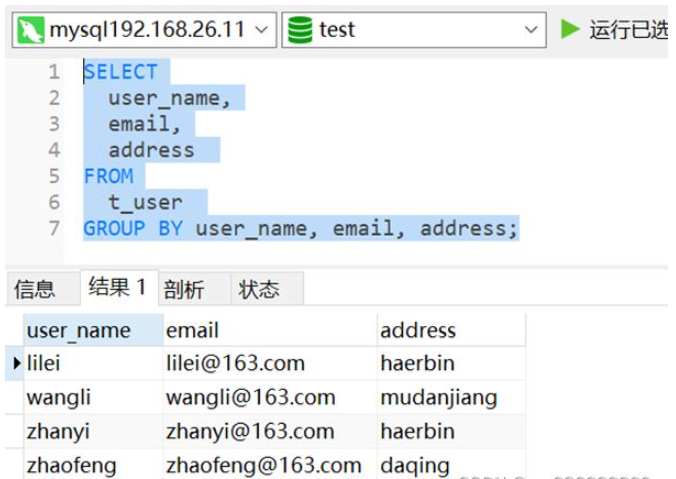
SELECT user_name,email,address FROM t_user GROUP BY user_name, email, address;
Wie im Bild unten gezeigt, wurden die Daten dedupliziert und nur 1 Duplikatdaten bleiben erhalten.
3. Methode 3: Fensterfunktion verwenden
(1) Wenn Ihre Datenbank MySQL8 oder höher ist, können Sie direkt die Fensterfunktion row_number() verwenden
SELECT *
FROM(
SELECT t.*,
ROW_NUMBER() OVER(PARTITION BY user_name
ORDER BY last_login DESC) rn
FROM table AS t
) AS t_user
WHERE rn = 1;(2) Wenn Ihre Datenbankversion niedriger als MySQL8 ist Mit der Klassenmethode row_number()
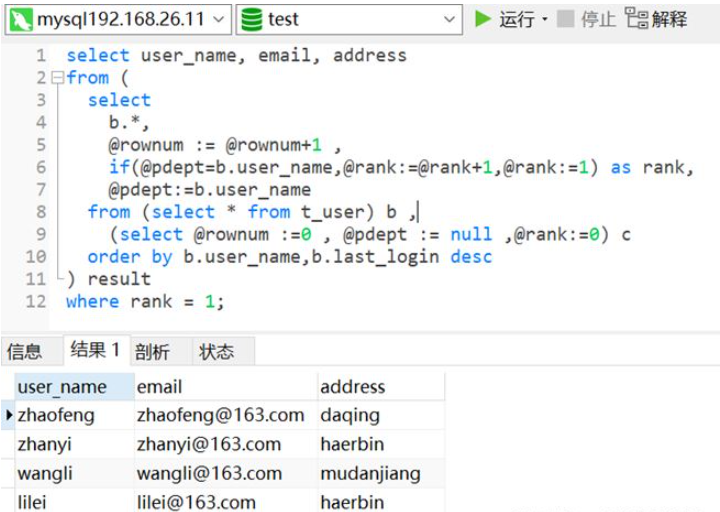
select user_name, email, address from ( select b.*, @rownum := @rownum+1 ,-- 定义用户变量@rownum来记录数据的行号 if(@pdept=b.user_name,@rank:=@rank+1,@rank:=1) as rank,-- 如果当前分组user_name和上一次分组user_name相同,则@rank(对每一组的数据进行编号)值加1,否则表示为新的分组,从1开始 @pdept:=b.user_name -- 定义变量@pdept用来保存上一次的分组id from (select * from t_user) b , (select @rownum :=0 , @pdept := null ,@rank:=0) c -- 初始化自定义变量值 order by b.user_name,b.last_login desc -- 该排序必须,否则结果会不对 ) result where rank = 1;
, wie unten gezeigt, wurden die Daten dedupliziert und es werden nur 1 Duplikatdaten beibehalten.
Das obige ist der detaillierte Inhalt vonWelche Methoden gibt es zum Entfernen doppelter Abfragen in MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!