
Heim >Technologie-Peripheriegeräte >KI >Cache-Optimierungspraxis für umfangreiches Deep-Learning-Training
Cache-Optimierungspraxis für umfangreiches Deep-Learning-Training

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-27 20:49:041377Durchsuche

1. Projekthintergrund und Caching-Strategie
Lassen Sie uns zunächst den relevanten Hintergrund teilen.
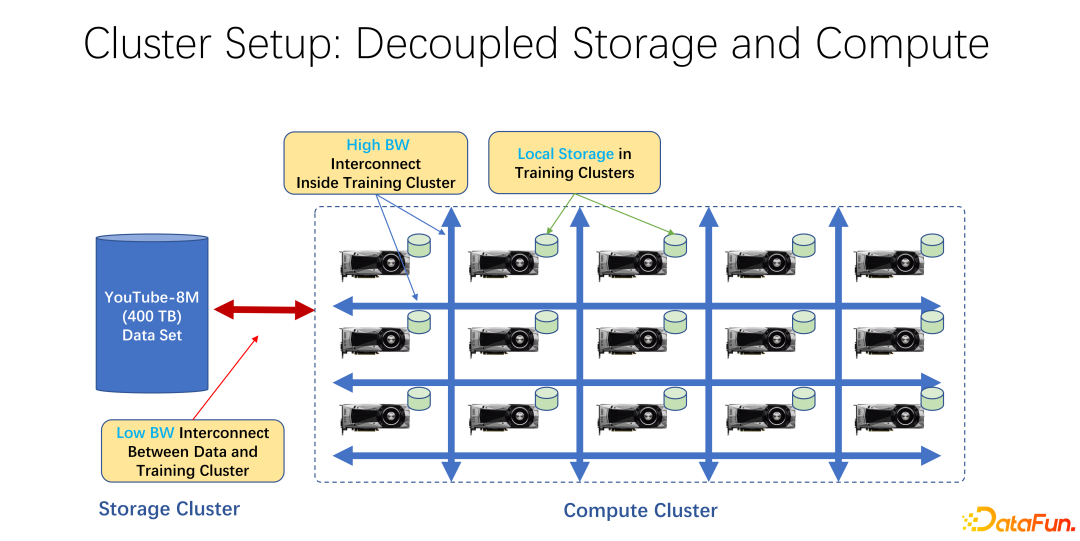
In den letzten Jahren haben KI-Trainingsanwendungen immer mehr Verbreitung gefunden. Aus infrastruktureller Sicht verwenden die meisten von ihnen eine Architektur, die Speicher und Rechenleistung trennt, egal ob es sich um Big Data oder KI-Trainingscluster handelt. Beispielsweise werden viele GPU-Arrays in einem großen Rechencluster platziert, und der andere Cluster dient der Speicherung. Möglicherweise wird auch ein Cloud-Speicher verwendet, z. B. Azure von Microsoft oder S3 von Amazon.
Die Merkmale einer solchen Infrastruktur bestehen darin, dass es zunächst viele sehr teure GPUs im Rechencluster gibt und jede GPU häufig über eine bestimmte Menge an lokalem Speicher verfügt, beispielsweise Dutzende TB Speicher SSD. In einer solchen Reihe von Maschinen wird häufig ein Hochgeschwindigkeitsnetzwerk verwendet, um eine Verbindung zum entfernten Ende herzustellen. Beispielsweise werden sehr große Trainingsdaten wie Coco, Image Net und YouTube 8M über das Netzwerk verbunden.
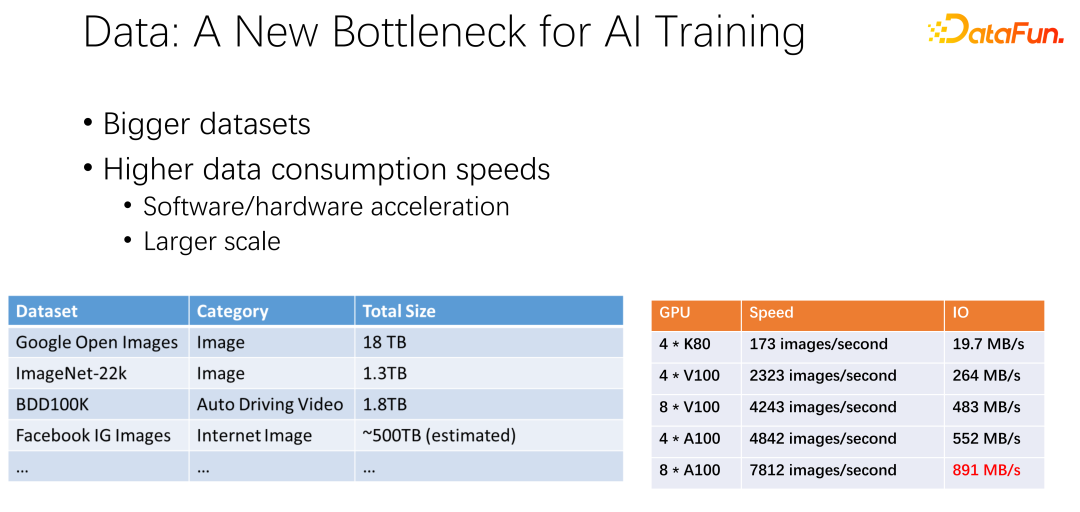
Wie in der Abbildung oben gezeigt, können Daten zum Flaschenhals des nächsten KI-Trainings werden. Wir haben beobachtet, dass die Datensätze immer größer werden und mit der zunehmenden Verbreitung von KI auch mehr Trainingsdaten gesammelt werden. Gleichzeitig ist die GPU-Spur sehr volumetrisch. Beispielsweise haben Hersteller wie AMD und TPU viel Energie in die Optimierung von Hardware und Software gesteckt, um Beschleuniger wie GPUs und TPUs immer schneller zu machen. Da Beschleuniger im Unternehmen weit verbreitet sind, werden Cluster-Bereitstellungen immer umfangreicher. Die beiden Tabellen hier zeigen einige Unterschiede zwischen Datensätzen und GPU-Geschwindigkeiten. Vom vorherigen K80 bis zum V100, P100 und A100 ist die Geschwindigkeit sehr hoch. Allerdings werden GPUs mit zunehmender Geschwindigkeit immer teurer. Ob unsere Daten, wie zum Beispiel die IO-Geschwindigkeit, mit der Geschwindigkeit der GPU mithalten können, ist eine große Herausforderung.

Wie im Bild oben gezeigt, haben wir in vielen großen Unternehmensanwendungen ein solches Phänomen beobachtet: Beim Lesen von Remote-Daten ist die GPU im Leerlauf. Da die GPU auf das Lesen von Remote-Daten wartet, bedeutet dies, dass E/A zu einem Engpass wird und teure GPU verschwendet wird. Es wird viel Optimierungsarbeit geleistet, um diesen Engpass zu beseitigen, und Caching ist eine der wichtigsten Optimierungsrichtungen. Hier gibt es zwei Möglichkeiten.

Der erste Grund ist, dass in vielen Anwendungsszenarien, insbesondere in grundlegenden KI-Trainingsarchitekturen wie K8s und Docker, viele lokale Festplatten verwendet werden. Wie bereits erwähnt, verfügt die GPU-Maschine über einen bestimmten lokalen Speicher. Sie können die lokale Festplatte zunächst zum Zwischenspeichern und Zwischenspeichern der Daten verwenden.
Nach dem Starten eines GPU-Dockers laden Sie, anstatt sofort mit dem GPU-KI-Training zu beginnen, zunächst die Daten herunter und laden die Daten vom Remote-Ende auf Docker herunter, oder Sie können sie mounten. Beginnen Sie mit dem Training, nachdem Sie es auf Docker heruntergeladen haben. Auf diese Weise kann das anschließende Lesen der Trainingsdaten so weit wie möglich in das Lesen lokaler Daten umgewandelt werden. Die Leistung lokaler E/A reicht derzeit aus, um das GPU-Training zu unterstützen. Zu VLDB 2020 gibt es einen Artikel, CoorDL, der auf DALI für das Daten-Caching basiert.
Diese Methode bringt auch viele Probleme mit sich. Erstens ist der lokale Speicherplatz begrenzt, was bedeutet, dass auch die zwischengespeicherten Daten begrenzt sind. Wenn der Datensatz immer größer wird, ist es schwierig, alle Daten zwischenzuspeichern. Darüber hinaus besteht ein großer Unterschied zwischen KI-Szenarien und Big-Data-Szenarien darin, dass die Datensätze in KI-Szenarien relativ begrenzt sind. Im Gegensatz zu Big-Data-Szenarien mit vielen Tabellen und verschiedenen Unternehmen ist die inhaltliche Lücke zwischen den Datentabellen der einzelnen Unternehmen sehr groß. In KI-Szenarien sind Größe und Anzahl der Datensätze weitaus kleiner als in Big-Data-Szenarien. Daher wird häufig festgestellt, dass viele im Unternehmen eingereichte Aufgaben dieselben Daten lesen. Wenn jeder die Daten auf seinen eigenen lokalen Computer herunterlädt, können sie nicht geteilt werden und viele Kopien der Daten werden wiederholt auf dem lokalen Computer gespeichert. Dieser Ansatz weist offensichtlich viele Probleme auf und ist nicht effizient genug.
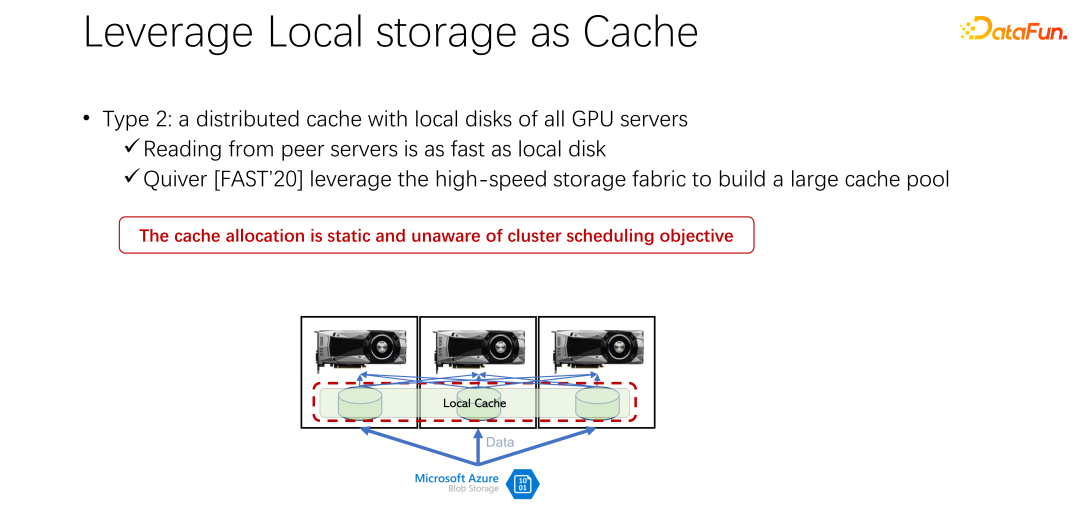
Als nächstes wird die zweite Methode vorgestellt. Können wir jetzt einen verteilten Cache wie Alluxio verwenden, um das Problem zu lösen, da der lokale Speicher nicht sehr gut ist? Der verteilte Cache hat eine sehr große Kapazität zum Laden von Daten. Darüber hinaus ist Alluxio als verteilter Cache einfach zu teilen. Die Daten werden auf Alluxio heruntergeladen und auch andere Clients können diese Daten aus dem Cache lesen. Es scheint, dass die Verwendung von Alluxio die oben genannten Probleme leicht lösen und die Leistung des KI-Trainings erheblich verbessern kann. In einem von Microsoft India Research auf der FAST2020 veröffentlichten Artikel mit dem Titel Quiver wurde diese Lösung erwähnt. Unsere Analyse ergab jedoch, dass ein solch scheinbar perfekter Allokationsplan immer noch relativ statisch und nicht effizient ist. Gleichzeitig ist auch die Frage, welche Art von Cache-Eliminierungsalgorithmus verwendet werden soll, eine Diskussion wert. Wie im Bild oben gezeigt , ja Eine Anwendung, die Alluxio als Cache für das KI-Training verwendet. Verwenden Sie K8s, um die gesamte Clusteraufgabe zu planen und Ressourcen wie GPU, CPU und Speicher zu verwalten. Wenn ein Benutzer eine Aufgabe an K8s sendet, erstellt K8s zunächst ein Plug-In und benachrichtigt den Alluxio-Master, diesen Teil der Daten herunterzuladen. Das heißt, machen Sie sich zunächst etwas warm und versuchen Sie, einige Aufgaben zwischenzuspeichern, die für den Job möglicherweise erforderlich sind. Natürlich muss es nicht vollständig zwischengespeichert werden, da Alluxio genauso viele Daten verbraucht, wie es hat. Der Rest wird, sofern er noch nicht zwischengespeichert wurde, vom entfernten Ende gelesen. Darüber hinaus kann der Alluxio-Master, nachdem er einen solchen Befehl erhalten hat, seinen Worker auffordern, zum Remote-Ende zu gehen. Es kann sich um einen Cloud-Speicher oder einen Hadoop-Cluster handeln, der die Daten herunterlädt. Zu diesem Zeitpunkt plant K8s den Job auch für den GPU-Cluster. In der obigen Abbildung werden beispielsweise in einem solchen Cluster der erste Knoten und der dritte Knoten ausgewählt, um die Trainingsaufgabe zu starten. Nach dem Start der Trainingsaufgabe müssen die Daten gelesen werden. In den aktuellen Mainstream-Frameworks wie PyTorch und Tensorflow ist auch Prefetch integriert, was das Vorlesen von Daten bedeutet. Es liest die zwischengespeicherten Daten in Alluxio, die zuvor zwischengespeichert wurden, um Unterstützung für Trainingsdaten-E/A bereitzustellen. Wenn sich herausstellt, dass einige Daten nicht gelesen wurden, kann Alluxio diese natürlich auch aus der Ferne lesen. Alluxio eignet sich hervorragend als einheitliche Schnittstelle. Gleichzeitig können Daten auch auftragsübergreifend ausgetauscht werden.
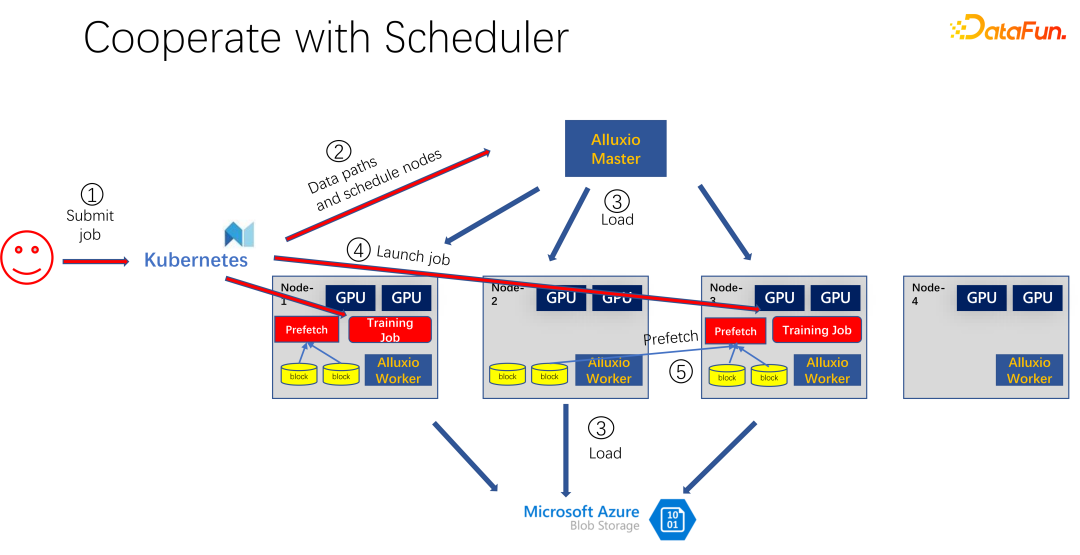
Wie im Bild oben gezeigt, hat beispielsweise eine andere Person das eingereicht Dieselben Daten. Zu diesem Zeitpunkt weiß Alluxio bei der Übermittlung des Jobs an K8s, dass dieser Teil der Daten bereits vorhanden ist. Wenn Alluxio es noch besser machen möchte, kann es sogar wissen, auf welcher Maschine die Daten geplant werden. Beispielsweise ist es zu diesem Zeitpunkt für Knoten 1, Knoten 3 und Knoten 4 geplant. Sie können sogar einige Kopien der Knoten-4-Daten erstellen. Auf diese Weise müssen alle Daten, auch innerhalb von Alluxio, nicht maschinenübergreifend ausgelesen werden, sondern werden lokal gelesen. Es scheint also, dass Alluxio das IO-Problem beim KI-Training erheblich gemildert und optimiert hat. Doch wer genau hinschaut, erkennt zwei Probleme.
Das erste Problem besteht darin, dass der Cache-Eliminierungsalgorithmus sehr ineffizient ist, da sich in KI-Szenarien die Art des Datenzugriffs stark von der Vergangenheit unterscheidet. Das zweite Problem besteht darin, dass der Cache als Ressource eine antagonistische Beziehung zur Bandbreite hat (d. h. der Lesegeschwindigkeit des Remote-Speichers). Wenn der Cache groß ist, besteht eine geringere Chance, Daten vom entfernten Ende zu lesen. Wenn der Cache klein ist, müssen viele Daten vom entfernten Ende gelesen werden. Wie diese Ressourcen gut geplant und zugewiesen werden können, ist ebenfalls ein Thema, das berücksichtigt werden muss.
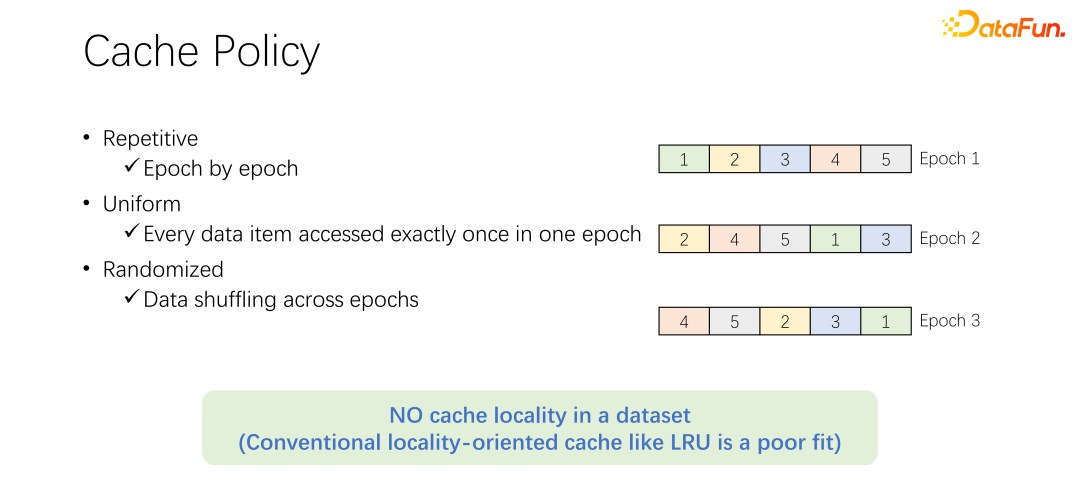 Bevor wir den Cache-Eliminierungsalgorithmus besprechen, werfen wir zunächst einen Blick auf den Prozess des Datenzugriffs im KI-Training. Beim KI-Training wird es in viele Epochen unterteilt und iterativ trainiert. In jeder Trainingsepoche wird jedes Datenelement nur einmal gelesen. Um eine Überanpassung des Trainings zu verhindern, wird nach dem Ende jeder Epoche in der nächsten Epoche die Lesereihenfolge geändert und ein Shuffle durchgeführt. Das heißt, alle Daten werden einmal pro Epoche gelesen, die Reihenfolge ist jedoch unterschiedlich.
Bevor wir den Cache-Eliminierungsalgorithmus besprechen, werfen wir zunächst einen Blick auf den Prozess des Datenzugriffs im KI-Training. Beim KI-Training wird es in viele Epochen unterteilt und iterativ trainiert. In jeder Trainingsepoche wird jedes Datenelement nur einmal gelesen. Um eine Überanpassung des Trainings zu verhindern, wird nach dem Ende jeder Epoche in der nächsten Epoche die Lesereihenfolge geändert und ein Shuffle durchgeführt. Das heißt, alle Daten werden einmal pro Epoche gelesen, die Reihenfolge ist jedoch unterschiedlich.
Der standardmäßige LRU-Eliminierungsalgorithmus in Alluxio kann offensichtlich nicht gut auf KI-Trainingsszenarien angewendet werden. Weil LRU die Cache-Lokalität nutzt. Die Lokalität ist in zwei Aspekte unterteilt: Der erste ist die Zeitlokalität, das heißt, auf die Daten, auf die jetzt zugegriffen wird, kann bald zugegriffen werden. Dies gibt es im KI-Training nicht. Denn auf die Daten, auf die jetzt zugegriffen wird, wird erst in der nächsten Runde zugegriffen, und zwar in der nächsten Runde. Es besteht keine besondere Wahrscheinlichkeit, dass Daten besser zugänglich sind als andere Daten. Auf der anderen Seite steht die Datenlokalität und auch die räumliche Lokalität. Mit anderen Worten: Alluxio verwendet relativ große Blöcke zum Zwischenspeichern von Daten, weil beim Lesen eines bestimmten Datenelements möglicherweise auch umgebende Daten gelesen werden. Beispielsweise scannen OLA
P-Anwendungen in Big-Data-Szenarien häufig Tabellen, was bedeutet, dass sofort auf die umgebenden Daten zugegriffen wird. Es kann jedoch nicht in KI-Trainingsszenarien angewendet werden. Da es jedes Mal neu gemischt wird, ist die Lesereihenfolge jedes Mal anders. Daher ist der LRU-Eliminierungsalgorithmus nicht für KI-Trainingsszenarien geeignet.

Nicht nur LRU, wie LFU Ein solches Problem besteht bei gängigen Eliminierungsalgorithmen. Denn das gesamte KI-Training hat einen sehr gleichberechtigten Zugriff auf Daten. Daher können Sie den einfachsten Caching-Algorithmus verwenden, der nur einen Teil der Daten zwischenspeichern und nie berühren muss. Nach Eintreffen eines Auftrags wird immer nur ein Teil der Daten zwischengespeichert. Beseitigen Sie es niemals. Es ist kein Eliminierungsalgorithmus erforderlich. Dies ist wahrscheinlich der beste Eliminierungsmechanismus, den es gibt.
Wie im obigen Beispiel gezeigt. Oben ist der LRU-Algorithmus und unten die Ausgleichsmethode. Zu Beginn können nur zwei Daten zwischengespeichert werden. Vereinfachen wir das Problem. Es gibt nur zwei Kapazitäten, Cache D und B, und die Mitte ist die Zugriffssequenz. Der erste, auf den zugegriffen wird, ist beispielsweise B. Wenn es sich um LRU handelt, wird B im Cache gefunden. Der nächste Zugriff ist C. C befindet sich nicht im Cache von D und B. Daher wird D basierend auf der LRU-Richtlinie ersetzt und C beibehalten. Das heißt, die Caches sind zu diesem Zeitpunkt C und B. Der nächste besuchte Ort ist A, der ebenfalls nicht in C und B enthalten ist. Also wird B eliminiert und durch C und A ersetzt. Das nächste ist D, und D befindet sich nicht im Cache, daher wird es durch D und A ersetzt. Analog dazu werden Sie feststellen, dass alle nachfolgenden Zugriffe nicht auf den Cache treffen. Der Grund dafür ist, dass beim Durchführen von LRU-Caching diese zwar ersetzt werden, aber tatsächlich einmal in einer Epoche darauf zugegriffen wurde und in dieser Epoche nie wieder darauf zugegriffen wird. LRU speichert es stattdessen nicht nur nicht, es macht es sogar noch schlimmer. Es ist besser, eine einheitliche Methode zu verwenden, z. B. die folgende.
Die folgende einheitliche Methode speichert D und B immer im Cache und führt niemals einen Ersatz durch. In diesem Fall liegt die Trefferquote bei mindestens 50 %. Sie sehen also, dass der Caching-Algorithmus nicht kompliziert sein muss. Verwenden Sie einfach keine Algorithmen wie LRU und LFU.
Zur zweiten Frage, bei der es um die Beziehung zwischen Cache und Remote-Bandbreite geht. Das Vorauslesen von Daten ist jetzt in alle gängigen KI-Frameworks integriert, um zu verhindern, dass die GPU auf Daten wartet. Wenn die GPU also trainiert, veranlasst sie tatsächlich die CPU, Daten vorzubereiten, die in der nächsten Runde verwendet werden können. Dadurch kann die Rechenleistung der GPU voll ausgenutzt werden. Wenn jedoch die E/A des Remote-Speichers zu einem Engpass wird, bedeutet dies, dass die GPU auf die CPU warten muss. Daher hat die GPU viel Leerlaufzeit, was zu einer Verschwendung von Ressourcen führt. Ich hoffe, dass es eine bessere Planungsverwaltungsmethode geben kann, um E/A-Probleme zu lindern.

Cache und Remote IO haben einen großen Einfluss auf den Durchsatz des Ganzen Aufgabe von. Daher müssen neben GPU, CPU und Speicher auch Cache und Netzwerk geplant werden. Im vergangenen Entwicklungsprozess von Big Data wie Hadoop, Yarn, My Source, K8s usw. wurden hauptsächlich CPU, Speicher und GPU geplant. Die Kontrolle über das Netzwerk, insbesondere den Cache, ist nicht sehr gut. Daher glauben wir, dass sie in KI-Szenarien gut geplant und zugewiesen werden müssen, um die Optimierung des gesamten Clusters zu erreichen. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#2. Silod Framework#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜 🎜# hat auf der EuroSys 2023 einen solchen Artikel veröffentlicht, der ein einheitliches Framework zur Planung von Rechenressourcen und Speicherressourcen darstellt.
Die Gesamtarchitektur ist im Bild oben dargestellt. In der unteren linken Ecke befinden sich die CPU- und GPU-Hardware-Rechenressourcen im Cluster sowie Speicherressourcen wie NFS, Cloud-Speicher HDFS usw. Auf der oberen Ebene gibt es einige KI-Trainings-Frameworks wie TensorFlow, PyTorch usw. Wir glauben, dass wir ein Plug-in hinzufügen müssen, das Rechen- und Speicherressourcen einheitlich verwaltet und zuweist, und genau das haben wir SiloD vorgeschlagen. 
Wie in der Abbildung oben gezeigt, welchen Durchsatz kann ein Job erzielen Erzielung und Leistung werden durch den Mindestwert von GPU und IO bestimmt. Wie viele Remote-IOs werden verwendet, wie viel Remote-Netzwerk wird verwendet. Mit einer solchen Formel kann die Zugriffsgeschwindigkeit berechnet werden. Die Auftragsgeschwindigkeit wird mit der Cache-Fehlerrate multipliziert, die (1-c/d) beträgt. Dabei ist c die Größe des Caches und d der Datensatz. Das bedeutet, dass, wenn Daten nur E/A berücksichtigen und zu einem Engpass werden können, der ungefähre Durchsatz gleich (b/(1-c/d)) ist, wobei b die Remote-Bandbreite ist. Durch die Kombination der oben genannten drei Formeln können wir die Formel rechts ableiten, die angibt, welche Art von Leistung ein Job letztendlich erreichen möchte. Sie können die Formel verwenden, um die Leistung zu berechnen, wenn kein E/A-Engpass vorliegt, und die Leistung, wenn es einen gibt IO-Engpass. Nehmen Sie den Wert zwischen den beiden. Nachdem Sie die obige Formel erhalten haben, können Sie durch Differenzieren die Effektivität des Caches oder die Cache-Effizienz ermitteln. Das heißt, obwohl es viele Jobs gibt, können sie bei der Cache-Zuweisung nicht gleich behandelt werden. Bei jedem Job, der auf unterschiedlichen Datensätzen und Geschwindigkeiten basiert, wird sehr genau festgelegt, wie viel Cache zugewiesen wird. Hier ist ein Beispiel, wenn Sie diese Formel als Beispiel nehmen. Wenn Sie einen Job finden, der sehr schnell ist und sehr schnell trainiert, und der Datensatz klein ist, bedeutet dies, dass Sie einen größeren Cache zuweisen und die Vorteile größer sind. 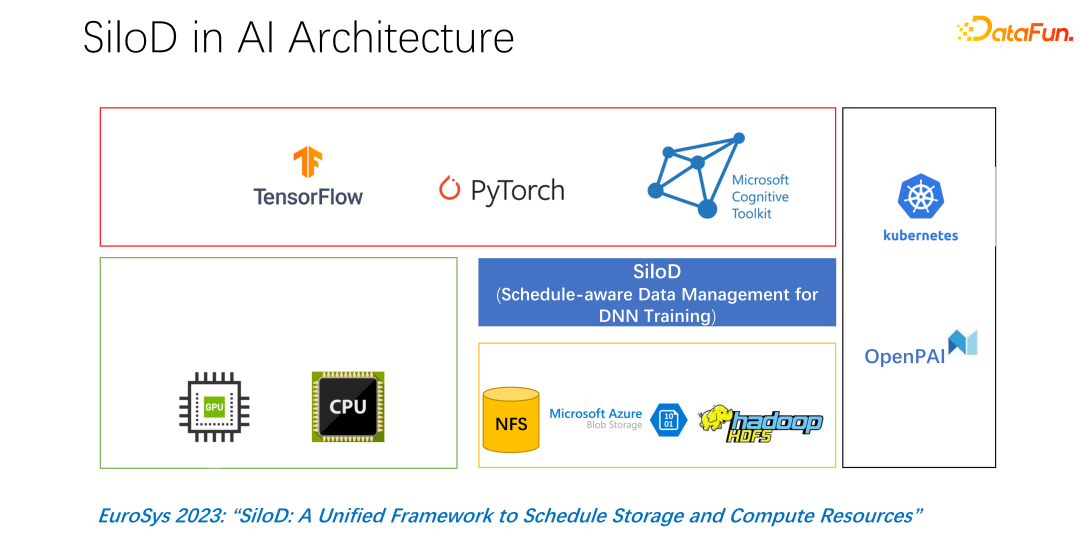
Basierend auf den obigen Beobachtungen kann SiloD für die Cache- und Netzwerkzuweisung verwendet werden. Darüber hinaus wird die Größe des Caches basierend auf der Geschwindigkeit jedes Jobs und der Gesamtgröße des Datensatzes zugewiesen. Das Gleiche gilt auch für das Web. Die gesamte Architektur sieht also so aus: Zusätzlich zur Mainstream-Jobplanung wie bei K8s gibt es auch Datenverwaltung. Auf der linken Seite der Abbildung erfordert die Cache-Verwaltung beispielsweise Statistiken oder Überwachung der Größe des dem gesamten Cluster zugewiesenen Caches, der Größe jedes Job-Caches und der Größe der von jedem Job verwendeten Remote-IO. Die folgenden Vorgänge sind der Alluxio-Methode sehr ähnlich und beide können APIs für das Datentraining verwenden. Verwenden Sie den Cache für jeden Worker, um Caching-Unterstützung für lokale Jobs bereitzustellen. Natürlich kann es auch Knoten in einem Cluster umfassen und auch gemeinsam genutzt werden.
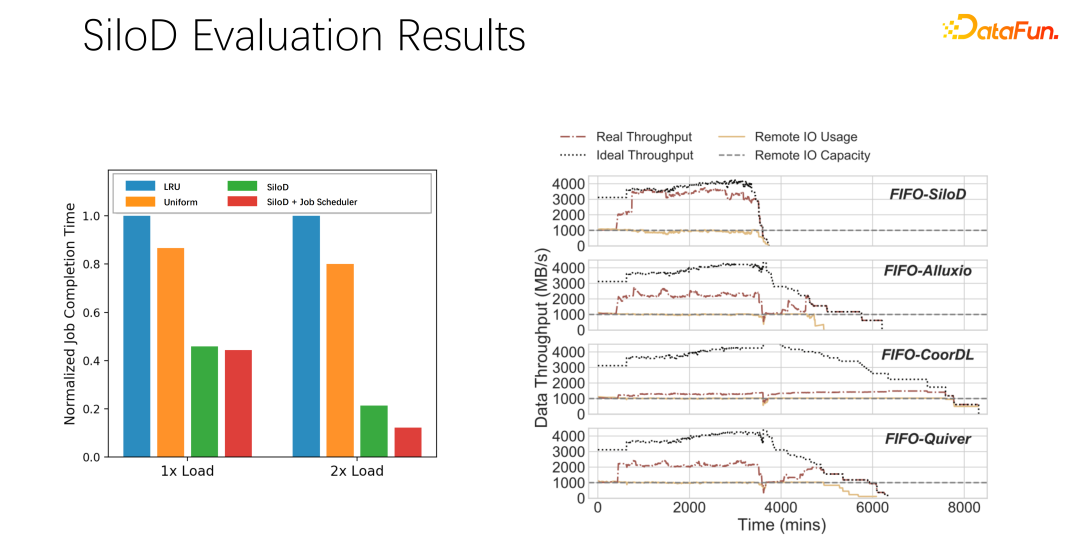
Nach vorläufigen Tests und Experimenten wurde festgestellt, dass eine solche Zuweisungsmethode die Auslastung und den Durchsatz des gesamten Clusters erheblich verbessern kann, bis zu einer Leistungssteigerung um das Achtfache. Es kann offensichtlich den Status des Jobwartens und der GPU-Leerlaufzeit lindern.

Fassen wir die obige Einführung zusammen:
First, in AI oder Deep -Learning -Trainingsszenarien, traditionelle Caching -Strategien wie LRU und LFU sind nicht geeignet, es ist es besser, Uniform direkt zu verwenden.
Zweitens sind Caching und Remote-Bandbreite zwei Partner, die eine sehr große Rolle für die Gesamtleistung spielen.
Drittens: Wichtige Planungsframeworks wie K8s und Yarn können problemlos von SiloD geerbt werden.
Abschließend Wir haben in der Arbeit einige Experimente durchgeführt, die zu offensichtlichen Durchsatzverbesserungen führen können.
3. Verteilte Caching-Strategie und Kopierverwaltung
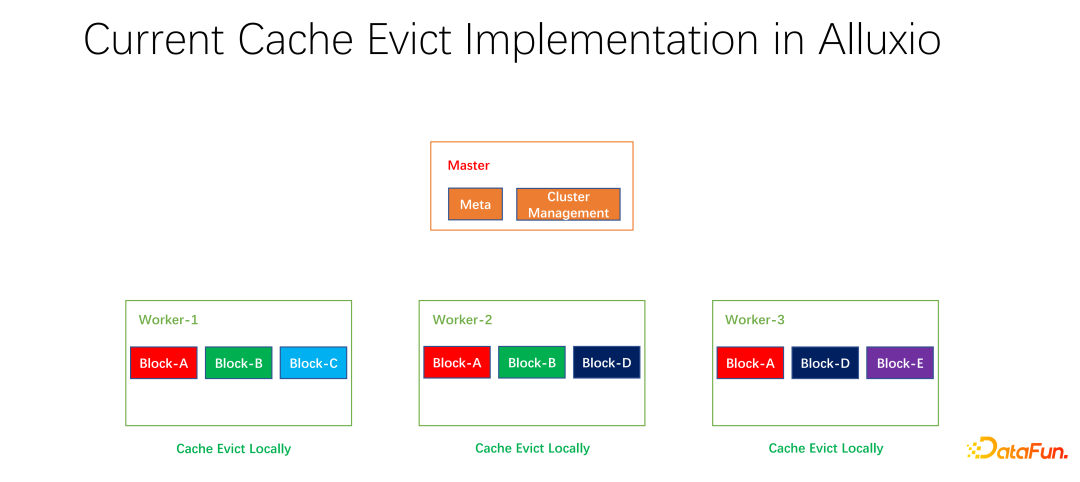
Wir haben auch einige Open-Source-Arbeiten durchgeführt. Diese Arbeit zur verteilten Caching-Strategie und Replikatverwaltung wurde der Community vorgelegt und befindet sich derzeit in der PR-Phase. Der Alluxio-Master ist hauptsächlich für die Verwaltung von Meta und die Verwaltung des gesamten Worker-Clusters verantwortlich. Es ist der Worker, der die Daten tatsächlich zwischenspeichert. Es gibt viele Blöcke in Blockeinheiten zum Zwischenspeichern von Daten. Ein Problem besteht darin, dass die aktuellen Caching-Strategien für einen einzelnen Worker gelten. Bei der Berechnung, ob alle Daten innerhalb des Workers gelöscht werden sollen, müssen sie nur für einen Worker berechnet und lokalisiert werden.
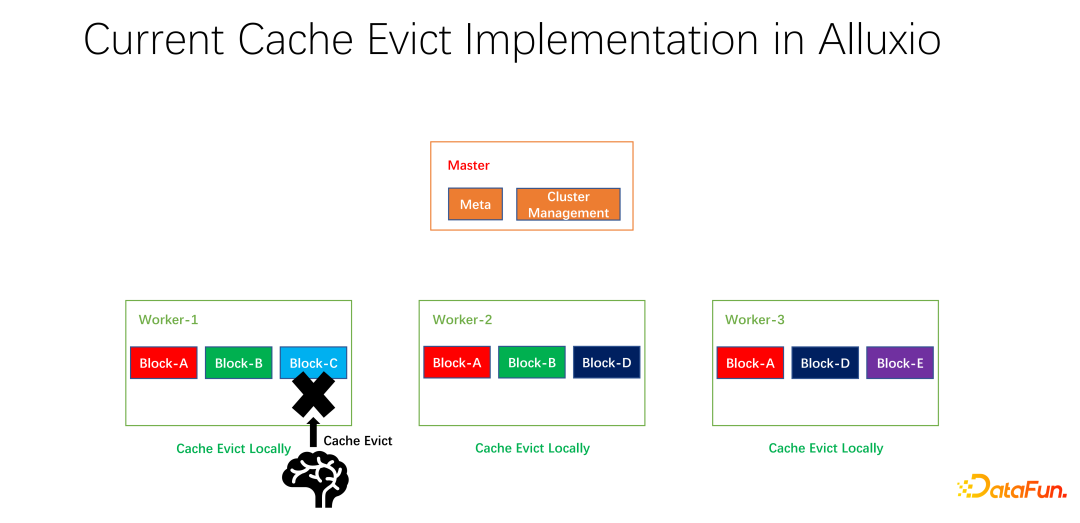
Wenn Block A, Block B und Block C auf Worker 1 vorhanden sind, wird anhand der LRU berechnet, dass Block C die längste Zeit nicht verwendet wurde , und der Block wird entfernt. Wenn man sich die Gesamtsituation anschaut, wird man feststellen, dass das nicht gut ist. Weil Block C im gesamten Cluster nur eine Kopie hat. Wenn jemand anderes nach der Beseitigung auf Block C zugreifen möchte, kann er nur Daten vom entfernten Ende abrufen, was zu Leistungs- und Kostenverlusten führt. Wir schlagen eine globale Eliminierungsstrategie vor. In diesem Fall sollte nicht Block C entfernt werden, sondern der Block mit den meisten Kopien. In diesem Beispiel sollte Block A eliminiert werden, da er noch zwei Kopien auf anderen Knoten hat, was im Hinblick auf Kosten und Leistung besser ist.
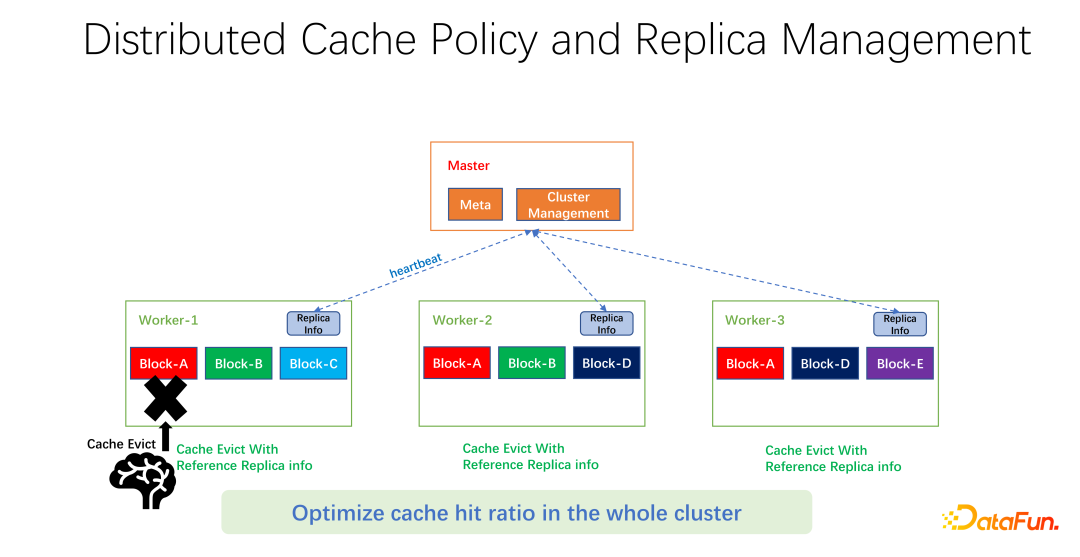
Wie in der Abbildung oben gezeigt, pflegen wir Replikatinformationen zu jedem Arbeiter. Wenn ein Worker beispielsweise eine Kopie hinzufügt oder eine Kopie entfernt, meldet er sich zunächst beim Master, und der Master verwendet diese Informationen als Heartbeat-Rückgabewert und gibt sie an andere zugehörige Worker zurück. Andere Mitarbeiter können die Echtzeitänderungen der gesamten globalen Kopie kennen. Gleichzeitig werden die Kopieinformationen aktualisiert. Daher können Sie beim Eliminieren interner Arbeiter wissen, wie viele Kopien jeder Arbeiter auf der ganzen Welt hat, und Sie können einige Gewichtungen entwerfen. LRU wird beispielsweise immer noch verwendet, aber die Gewichtung der Anzahl der Replikate wird hinzugefügt, um umfassend zu berücksichtigen, welche Daten entfernt und ersetzt werden müssen.
Nach unseren vorläufigen Tests kann es in vielen Bereichen große Verbesserungen bringen, sei es Big Data oder KI-Training. Es geht also nicht nur darum, Cache-Treffer für einen Worker auf einer Maschine zu optimieren. Unser Ziel ist es, die Cache-Trefferquote des gesamten Clusters zu verbessern.

Zum Schluss fassen wir den vollständigen Text zusammen. Erstens ist in KI-Trainingsszenarien der einheitliche Cache-Eliminierungsalgorithmus besser als die herkömmliche LRU und LFU. Zweitens sind Cache und Remote-Netzwerk ebenfalls Ressourcen, die zugewiesen und geplant werden müssen. Drittens: Beschränken Sie den Cache nicht nur auf einen Job oder einen Worker, sondern berücksichtigen Sie die gesamten globalen End-to-End-Parameter, damit die Effizienz und Leistung des gesamten Clusters besser verbessert werden kann.
Das obige ist der detaillierte Inhalt vonCache-Optimierungspraxis für umfangreiches Deep-Learning-Training. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr