
Heim >Technologie-Peripheriegeräte >KI >Die LLM-Inferenz ist dreimal schneller! Microsoft veröffentlicht LLM Accelerator: Verwendung von Referenztext zur Erzielung verlustfreier Beschleunigung
Die LLM-Inferenz ist dreimal schneller! Microsoft veröffentlicht LLM Accelerator: Verwendung von Referenztext zur Erzielung verlustfreier Beschleunigung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-27 10:40:061603Durchsuche
Mit der rasanten Entwicklung der Technologie der künstlichen Intelligenz werden nach und nach neue Produkte und Technologien wie ChatGPT, New Bing und GPT-4 veröffentlicht. Grundlegende große Modelle werden in vielen Anwendungen eine immer wichtigere Rolle spielen.
Die meisten aktuellen großen Sprachmodelle sind autoregressive Modelle. Autoregression bedeutet, dass das Modell bei der Ausgabe häufig eine wortweise Ausgabe verwendet, dh bei der Ausgabe jedes Wortes muss das Modell die zuvor ausgegebenen Wörter als Eingabe verwenden. Dieser autoregressive Modus schränkt normalerweise die volle Nutzung paralleler Beschleuniger während der Ausgabe ein.
In vielen Anwendungsszenarien weist die Ausgabe eines großen Modells häufig große Ähnlichkeit mit einigen Referenztexten auf, beispielsweise in den folgenden drei häufigen Szenarien:
1. Retrieval-Enhanced-Generierung
Wenn Suchanwendungen wie New Bing reagieren auf Benutzereingaben. Sie geben zunächst einige Informationen im Zusammenhang mit der Benutzereingabe zurück, fassen dann die abgerufenen Informationen mithilfe eines Sprachmodells zusammen und beantworten dann die Benutzereingaben. In diesem Szenario enthält die Ausgabe des Modells häufig eine große Anzahl von Textfragmenten aus den Suchergebnissen.
2. Zwischengespeicherte Generierung verwenden
Beim groß angelegten Einsatz von Sprachmodellen werden historische Eingaben und Ausgaben zwischengespeichert. Bei der Verarbeitung neuer Eingaben sucht die Abrufanwendung im Cache nach ähnlichen Eingaben. Daher ist die Ausgabe des Modells häufig der entsprechenden Ausgabe im Cache sehr ähnlich.
3. Generierung in Multi-Turn-Konversationen
Bei der Verwendung von Anwendungen wie ChatGPT stellen Benutzer häufig wiederholte Änderungsanfragen basierend auf der Ausgabe des Modells. In diesem Dialogszenario mit mehreren Runden weisen die mehreren Ausgaben des Modells häufig nur geringe Änderungen und einen hohen Wiederholungsgrad auf.
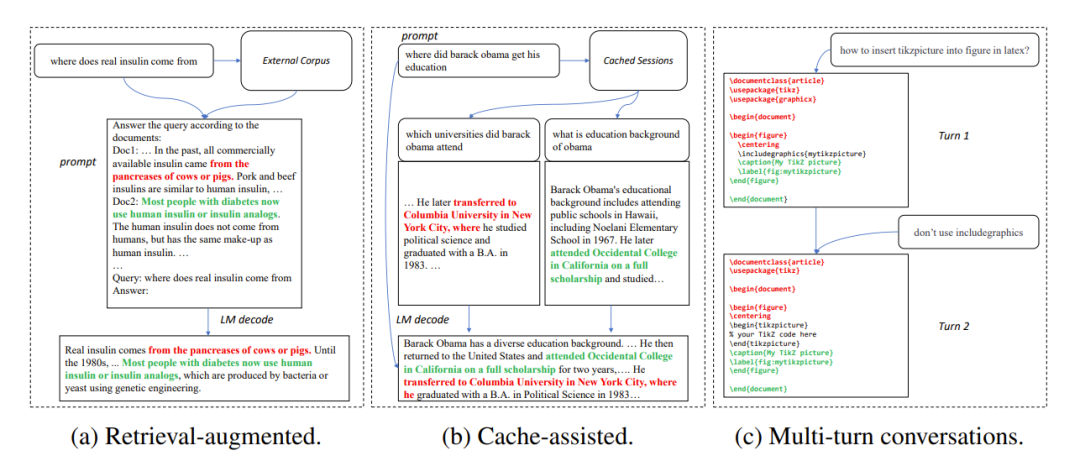
Abbildung 1: Häufige Szenarien, in denen die Ausgabe eines großen Modells dem Referenztext ähnelt
Basierend auf den obigen Beobachtungen verwendeten die Forscher die Wiederholbarkeit des Referenztextes und des Referenzmodells Ausgabe als Durchbruch in der Autoregression Wir konzentrieren uns auf den Engpass und hoffen, die Nutzung paralleler Beschleuniger zu verbessern und das Denken großer Sprachmodelle zu beschleunigen. Anschließend schlagen wir eine LLM Accelerator-Methode vor, die die Wiederholung von Ausgabe und Referenztext verwendet, um mehrere Wörter in einem Schritt auszugeben .
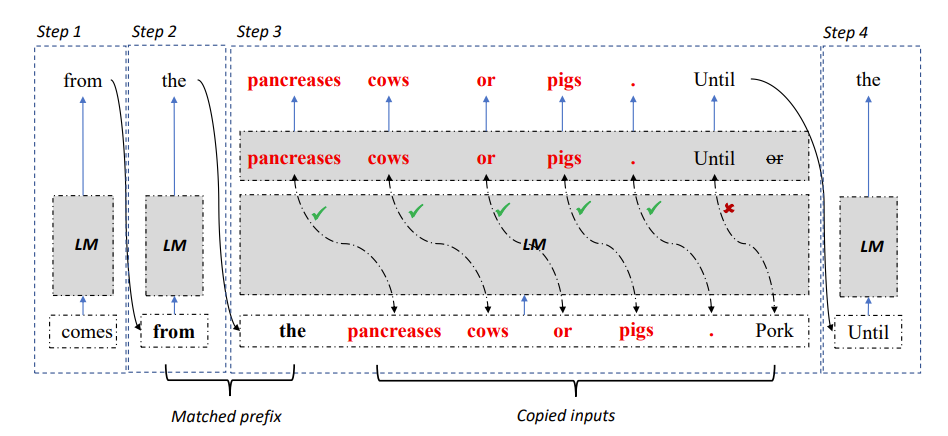
Abbildung 2: LLM Accelerator-Dekodierungsalgorithmus
Konkret muss das Modell bei jedem Dekodierungsschritt zunächst mit den vorhandenen Ausgabeergebnissen und dem Referenztext abgeglichen werden, wenn eine Referenz im Text gefunden wird Wenn der Wert mit der vorhandenen Ausgabe übereinstimmt, wird das Modell wahrscheinlich weiterhin den vorhandenen Referenztext ausgeben.
Daher fügten die Forscher nachfolgende Wörter des Referenztextes als Eingabe in das Modell hinzu, sodass ein Dekodierungsschritt mehrere Wörter ausgeben kann.
Um sicherzustellen, dass die Eingabe und Ausgabe korrekt sind, verglichen die Forscher die vom Modell ausgegebenen Wörter weiter mit den eingegebenen Wörtern aus dem Referenzdokument. Wenn die beiden inkonsistent sind, werden die falschen Eingabe- und Ausgabeergebnisse verworfen.
Die obige Methode kann sicherstellen, dass die Dekodierungsergebnisse vollständig mit der Basismethode übereinstimmen, und kann die Anzahl der Ausgabewörter in jedem Dekodierungsschritt erhöhen, wodurch eine verlustfreie Beschleunigung großer Modellinferenzen erreicht wird.
LLM Accelerator erfordert keine zusätzlichen Hilfsmodelle, ist einfach zu verwenden und kann problemlos in verschiedenen Anwendungsszenarien eingesetzt werden.
Papierlink: https://arxiv.org/pdf/2304.04487.pdf
Projektlink: https://github.com/microsoft/LMOps
Mit LLM Accelerator, Es gibt zwei Hyperparameter, die angepasst werden müssen.
Erstens die Anzahl der übereinstimmenden Wörter zwischen der Ausgabe, die zum Auslösen des Übereinstimmungsmechanismus und dem Referenztext erforderlich ist: Je länger die Anzahl der übereinstimmenden Wörter ist, desto genauer ist sie, wodurch besser sichergestellt werden kann, dass die Wörter aus dem Referenztext kopiert werden korrekte Ausgabe, Reduzierung unnötiger Trigger und Berechnungen; kürzere Übereinstimmungen, weniger Decodierungsschritte, möglicherweise schnellere Beschleunigung.
Das zweite ist die Anzahl der jedes Mal kopierten Wörter: Je mehr Wörter kopiert werden, desto größer ist das Beschleunigungspotenzial, aber es kann auch dazu führen, dass mehr falsche Ausgaben verworfen werden, was Rechenressourcen verschwendet. Forscher haben durch Experimente herausgefunden, dass aggressivere Strategien (Abgleich einzelner Wortauslöser, gleichzeitiges Kopieren von 15 bis 20 Wörtern) häufig bessere Beschleunigungsverhältnisse erzielen können.
Um die Wirksamkeit des LLM Accelerator zu überprüfen, führten die Forscher Experimente zur Abrufverbesserung und Cache-unterstützten Generierung durch und erstellten experimentelle Proben unter Verwendung des MS-MARCO-Absatzabrufdatensatzes.
Im Experiment zur Abrufverbesserung verwendeten die Forscher das Abrufmodell, um die 10 relevantesten Dokumente für jede Abfrage zurückzugeben, und fügten sie dann als Eingabe für das Modell in die Abfrage ein, wobei sie diese 10 Dokumente als Referenztext verwendeten.
Im Experiment zur Cache-unterstützten Generierung generiert jede Abfrage vier ähnliche Abfragen und verwendet dann das Modell, um die entsprechende Abfrage als Referenztext auszugeben.
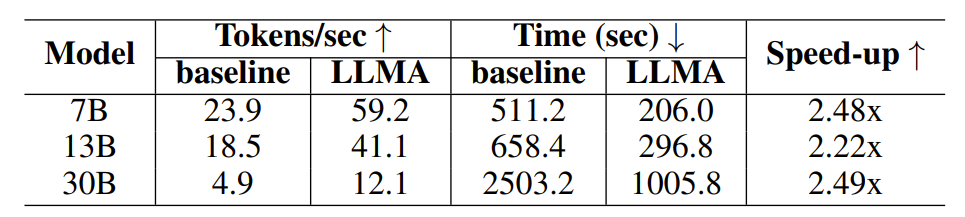
Tabelle 1: Zeitvergleich im Szenario der Retrieval-Enhanced-Generierung
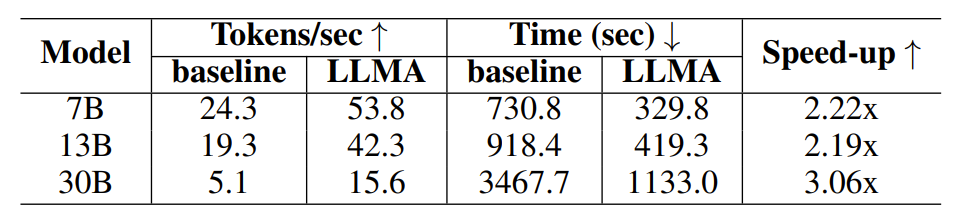
Tabelle 2: Zeitvergleich im Szenario der Generierung mit Cache
Die Die Forscher verwendeten die über die OpenAI-Schnittstelle erhaltene Ausgabe des Davinci-003-Modells als Zielausgabe, um eine qualitativ hochwertige Ausgabe zu erhalten. Nachdem die Forscher den erforderlichen Eingabe-, Ausgabe- und Referenztext erhalten hatten, führten sie Experimente mit dem Open-Source-Sprachmodell LLaMA durch.
Da die Ausgabe des LLaMA-Modells nicht mit der Davinci-003-Ausgabe übereinstimmt, verwendeten die Forscher eine zielorientierte Dekodierungsmethode, um das Beschleunigungsverhältnis unter der idealen Ausgabe (Davinci-003-Modellergebnis) zu testen.
Die Forscher verwendeten Algorithmus 2, um die Dekodierungsschritte zu erhalten, die zum Generieren der Zielausgabe während der gierigen Dekodierung erforderlich sind, und zwangen das LLaMA-Modell, gemäß den erhaltenen Dekodierungsschritten zu dekodieren.

Abbildung 3: Verwendung von Algorithmus 2, um die Dekodierungsschritte zu erhalten, die zum Generieren der Zielausgabe während der gierigen Dekodierung erforderlich sind
Für Modelle mit Parametermengen von 7B und 13B verwendeten die Forscher einen einzigen 32G NVIDIA-Experimente werden auf einer V100-GPU durchgeführt; für ein Modell mit 30B-Parametern werden Experimente auf vier identischen GPUs durchgeführt. Alle Experimente verwenden Gleitkommazahlen mit halber Genauigkeit, die Dekodierung ist eine gierige Dekodierung und die Stapelgröße beträgt 1.
Experimentelle Ergebnisse zeigen, dass LLM Accelerator in verschiedenen Modellgrößen (7B, 13B, 30B) und verschiedenen Anwendungsszenarien (Abrufverbesserung, Cache-Unterstützung) das zwei- bis dreifache Beschleunigungsverhältnis erreicht hat.
Weitere experimentelle Analysen ergaben, dass LLM Accelertator die erforderlichen Decodierungsschritte erheblich reduzieren kann und das Beschleunigungsverhältnis positiv mit dem Reduktionsverhältnis der Decodierungsschritte korreliert.
Einerseits bedeuten weniger Decodierungsschritte, dass jeder Decodierungsschritt mehr Ausgabewörter generiert, was die Recheneffizienz von GPU-Berechnungen verbessern kann; andererseits bedeutet dies für das 30B-Modell, das Multikartenparallelität erfordert mehr Weniger Synchronisierung mehrerer Karten, wodurch eine schnellere Geschwindigkeitsverbesserung erreicht wird.
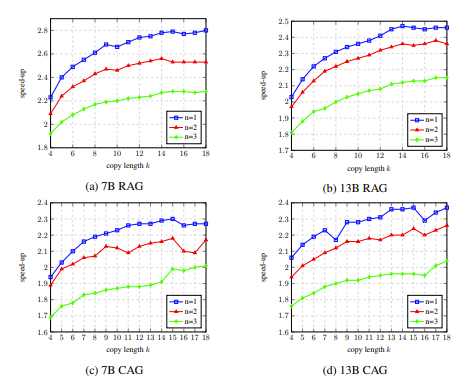
Im Ablationsexperiment zeigten die Ergebnisse der Analyse der Hyperparameter von LLM Accelertator am Entwicklungssatz, dass beim Abgleichen eines einzelnen Wortes (d. h. Auslösen des Kopiermechanismus) das Beschleunigungsverhältnis beim Kopieren 15 bis maximal erreichen kann 20 Wörter gleichzeitig (dargestellt in Abbildung 4).
In Abbildung 5 können wir sehen, dass die Anzahl der übereinstimmenden Wörter 1 beträgt, was den Kopiermechanismus stärker auslösen kann. Mit zunehmender Kopierlänge nehmen die von jedem Decodierungsschritt akzeptierten Ausgabewörter zu und die Decodierungsschritte nehmen somit ab Erreichen eines höheren Beschleunigungsverhältnisses. Abbildung 4: Im Ablationsexperiment die Analyseergebnisse der Hyperparameter des LLM Accelertator am Entwicklungssatz. Abbildung 5: Am Entwicklungssatz , mit statistischen Daten der Dekodierungsschritte für unterschiedliche Anzahl übereinstimmender Wörter n und Anzahl kopierter Wörter k
 LLM Accelertator ist Teil der Arbeitsreihe der Microsoft Research Asia Natural Language Computing Group zur Beschleunigung großer Sprachmodelle. Forscher werden sich weiterhin mit verwandten Themen befassen und diese tiefer erforschen.
LLM Accelertator ist Teil der Arbeitsreihe der Microsoft Research Asia Natural Language Computing Group zur Beschleunigung großer Sprachmodelle. Forscher werden sich weiterhin mit verwandten Themen befassen und diese tiefer erforschen.
Das obige ist der detaillierte Inhalt vonDie LLM-Inferenz ist dreimal schneller! Microsoft veröffentlicht LLM Accelerator: Verwendung von Referenztext zur Erzielung verlustfreier Beschleunigung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr