
Was ist das zugrunde liegende Prinzip von Redis?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-26 22:21:131342Durchsuche
Redis-Kernobjekt
In Redis gibt es ein „Kernobjekt“ namens redisObject, das zur Darstellung aller Schlüssel und Werte verwendet wird. Die redisObject-Struktur wird zur Darstellung von fünf Datentypen verwendet: String, Hash, List, Set, und ZSet-Typ.
Der Quellcode von redisObject ist in redis.h und in der Sprache C geschrieben. Wenn Sie interessiert sind, können Sie es sich selbst ansehen. Ich habe hier ein Bild gezeichnet, das zeigt, dass die Struktur von redisObject wie folgt ist Folgendes:
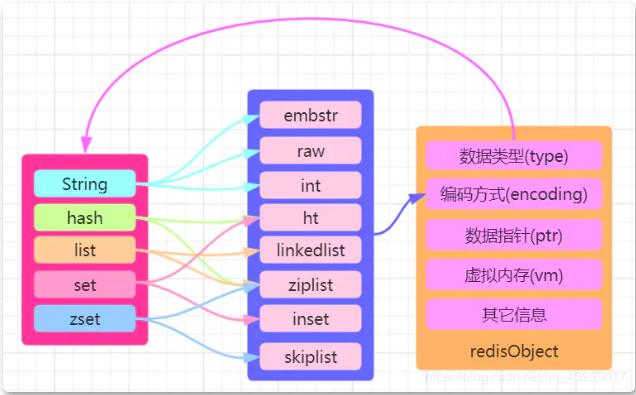
In redisObject In „Typ gibt an, zu welchem Datentyp es gehört, und Codierung gibt an, wie die Daten gespeichert werden“ , was die zugrunde liegende Datenstruktur des implementierten Datentyps ist. Daher wird in diesem Artikel speziell der entsprechende Teil der Codierung vorgestellt.
Was bedeuten also die Speichertypen bei der Kodierung? Die Bedeutung des spezifischen Datentyps ist in der folgenden Abbildung dargestellt:
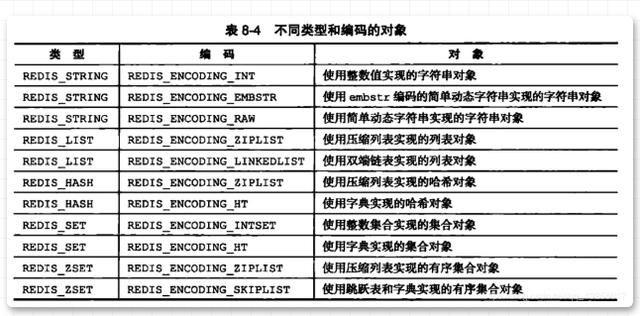
Nach dem Lesen dieses Bildes sind Sie möglicherweise immer noch verwirrt. Keine Panik, wir geben eine detaillierte Einführung in die fünf Datenstrukturen. Dieses Bild ermöglicht es Ihnen nur, die Speichertypen zu finden, die jeder Datenstruktur entsprechen, und wahrscheinlich einen Eindruck in Ihrem Kopf zu bekommen.
Um ein einfaches Beispiel zu geben: Sie legen in Redis einen Zeichenfolgenschlüssel fest und überprüfen dann den Speichertyp dieser Zeichenfolge. Sie werden feststellen, dass es sich um einen int-Typ handelt, der den Speichertyp „emstr“ verwendet wie folgt:
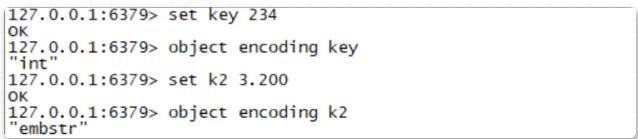
String-Typ
String ist der grundlegendste Datentyp von Redis. In der obigen Einführung wurde auch erwähnt, dass Redis in der Sprache C entwickelt wurde. Es gibt jedoch offensichtliche Unterschiede zwischen String-Typen in Redis und String-Typen in der C-Sprache.
Es gibt drei Möglichkeiten, Datenstrukturen vom Typ String zu speichern: int, raw und embstr. Was sind also die Unterschiede zwischen diesen drei Speichermethoden?
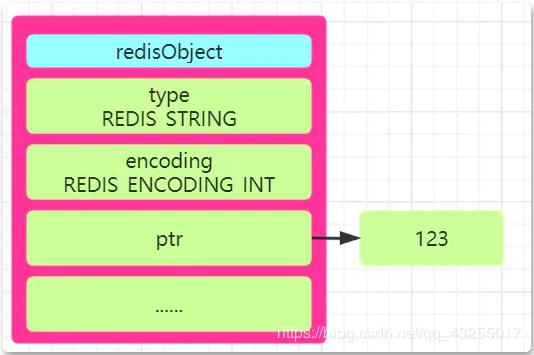
int
Redis legt fest, dass, wenn der gespeicherte „Ganzzahlwert“ , z. B. die Satznummer 123, mit der int-Speichermethode gespeichert wird, diese im „ptr-Attribut“ von redisObject gespeichert wird. Speichern Sie diesen Wert .
SDS
Wenn der gespeicherte "String ein String-Wert ist und die Länge größer als 32 Bytes ist", wird er mit SDS (einfacher dynamischer String) gespeichert und die Codierung wird auf „Raw“ gesetzt „Die Zeichenfolgenlänge ist kleiner oder gleich 32 Bytes“ ändert die Codierung in „emstr“, um die Zeichenfolge zu speichern.
SDS heißt "Simple Dynamic String". In SDS sind im Redis-Quellcode drei Attribute definiert: int len, int free und char buf[].
len speichert die Länge der Zeichenfolge, free stellt die Anzahl der nicht verwendeten Bytes im Buf-Array dar und das Buf-Array speichert jedes Zeichenelement der Zeichenfolge.
Wenn Sie also eine Zeichenfolge „Hallo“ in Redsi speichern, können Sie gemäß der Beschreibung des Redis-Quellcodes das Strukturdiagramm von redisObject in Form von SDS zeichnen, wie unten gezeigt:
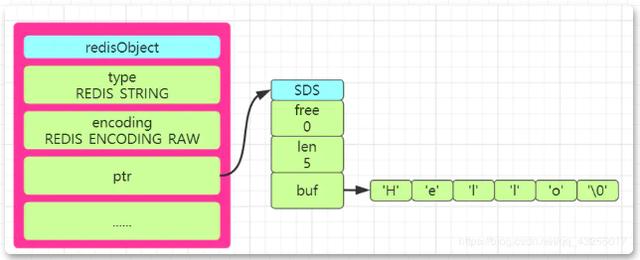
Vergleich zwischen SDS- und C-Sprachzeichenfolgen
Redis hat definitiv seine eigenen Vorteile bei der Verwendung von SDS als String-Speichertyp. Im Vergleich zu Strings in C-Sprache verfügt SDS über ein eigenes Design und eine eigene Optimierung für Strings in C-Sprache. Die spezifischen Vorteile sind wie folgt:
(1) Zeichenfolgen in der C-Sprache zeichnen daher nicht ihre eigene Länge auf Wert von len, und die Zeitkomplexität wird O(1). (2) Wenn beim Verketten von zwei Zeichenfolgen in
"c-Sprache"kein ausreichend langer Speicherplatz zugewiesen wird, "Pufferüberlauf"; und "SDS" verwendet zuerst das len-Attribut. Bestimmen Sie, ob Wenn der Speicherplatz nicht ausreicht, wird der entsprechende Speicherplatz erweitert, sodass „kein Pufferüberlauf auftritt“ . (3) SDS bietet außerdem zwei Strategien:
„Space Pre-allocation“und „Lazy Space Release“. Wenn Sie Speicherplatz für eine Zeichenfolge zuweisen, weisen Sie mehr Speicherplatz als den tatsächlichen Speicherplatz zu, was „die Anzahl der Speicherneuzuweisungen reduzieren kann, die durch die kontinuierliche Ausführung des String-Wachstums verursacht werden“ . Wenn die Zeichenfolge gekürzt wird, fordert SDS den ungenutzten Speicherplatz nicht sofort zurück, sondern zeichnet den ungenutzten Speicherplatz über das Attribut „Frei“ auf und gibt ihn frei, wenn er später verwendet wird.
Das spezifische Prinzip der Speicherplatzvorzuweisung lautet:
"Wenn die Länge len der geänderten Zeichenfolge weniger als 1 MB beträgt, wird Speicherplatz mit der gleichen Länge wie len vorab zugewiesen, d. h. len = frei; wenn len größer ist als 1 MB beträgt der von Free Will zugewiesene Speicherplatz 1 MB". (4) SDS ist nicht nur binär, sondern kann auch Binärdateien speichern (z. B. Binärdaten von Bildern, Audios, Videos usw.); einige davon enden mit einer leeren Zeichenfolge Bilder enthalten Terminatoren und sind daher nicht binärsicher. Um das Verständnis zu erleichtern, haben wir eine Tabelle erstellt, in der C-Sprachzeichenfolgen und SDS verglichen werden, wie unten gezeigt: C-Sprachzeichenfolge SDS Die zeitliche Komplexität zum Ermitteln der Länge beträgt O(n) Get the Länge Die Zeitkomplexität ist nicht binärsicher. Es kann nur Zeichenfolgen speichern, und eine Erhöhung der Zeichenfolge um das N-fache führt zwangsläufig dazu Erhöhen Sie die Anzahl der Speicherzuweisungen der Zeichenfolge Die Theorie muss noch in die Praxis umgesetzt werden. Wie oben erwähnt, kann String zum Speichern von Bildern verwendet werden. Nehmen wir nun die Bildspeicherung als Fallimplementierung. Kopieren Sie den Code (2). Der zweite Schritt besteht darin, das verarbeitete Bildzeichenfolgenformat in Redis zu speichern. Der implementierte Code lautet wie folgt: (1) Zunächst müssen Sie das hochgeladene Bild kodieren. Hier ist eine Toolklasse, um das Bild in die Base64-Kodierung zu verarbeiten. Der spezifische Implementierungscode lautet wie folgt:
/** * 将图片内容处理成Base64编码格式 * @param file * @return */ public static String encodeImg(MultipartFile file) { byte[] imgBytes = null; try { imgBytes = file.getBytes(); } catch (IOException e) { e.printStackTrace(); } BASE64Encoder encoder = new BASE64Encoder(); return imgBytes==null?null:encoder.encode(imgBytes );
/** * Redis存储图片 * @param file * @return */ public void uploadImageServiceImpl(MultipartFile image) { String imgId = UUID.randomUUID().toString(); String imgStr= ImageUtils.encodeImg(image); redisUtils.set(imgId , imgStr); // 后续操作可以把imgId存进数据库对应的字段,如果需要从redis中取出,只要获取到这个字段后从redis中取出即可。 }
"Statistik". Anzahl der Weibos, Statistiken zur Anzahl der Fans" usw.
Hash-TypEs gibt zwei Möglichkeiten, Hash-Objekte zu implementieren: ziplist und hashtable. Die Speichermethode von hashtable ist vom Typ String, und der Wert wird auch in Form eines Schlüsselwerts gespeichert.
Die unterste Ebene des Wörterbuchtyps wird durch Hashtable implementiert. Wenn Sie das zugrunde liegende Implementierungsprinzip von Hashtable verstehen, können Sie das Implementierungsprinzip von Hashtable mit dem zugrunde liegenden Prinzip von HashMap vergleichen.
Dictionary
Beide berechnen den Array-Index über den Schlüssel, wenn sie hinzugefügt werden. Der Unterschied besteht darin, dass die Berechnungsmethode die Hash-Funktion verwendet, während in Hashtable dies auch nach der Berechnung des Hash-Werts erforderlich ist Verwenden Sie sizemask. Attribute und Hashes erhalten erneut Array-Indizes.
Wir wissen, dass das größte Problem bei Hash-Tabellen Hash-Konflikte sind, wenn verschiedene Schlüssel in der Hash-Tabelle durch Berechnung den gleichen Index erhalten (
„Kettenadressmethode“). wird gebildet, wie in der folgenden Abbildung gezeigt:
rehash
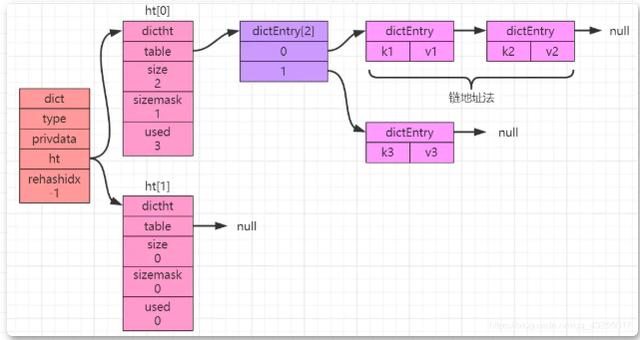 In der zugrunde liegenden Implementierung des Wörterbuchs wird das Wertobjekt in jedem dictEntry-Objekt gespeichert, wenn die Schlüssel-Wert-Paare in der Hash-Tabelle gespeichert werden Wenn sich die Hash-Tabelle weiter erhöht oder verringert, muss sie erweitert oder verkleinert werden.
In der zugrunde liegenden Implementierung des Wörterbuchs wird das Wertobjekt in jedem dictEntry-Objekt gespeichert, wenn die Schlüssel-Wert-Paare in der Hash-Tabelle gespeichert werden Wenn sich die Hash-Tabelle weiter erhöht oder verringert, muss sie erweitert oder verkleinert werden.
Genau wie bei HashMap wird auch hier eine Rehash-Operation durchgeführt, also eine Rehash-Anordnung. Wie aus der obigen Abbildung ersichtlich ist, sind ht[0] und ht[1] zwei Objekte. Im Folgenden konzentrieren wir uns auf die Rolle ihrer Attribute.
In der Definition der Hash-Tabellenstruktur gibt es vier Attribute: dictEntry **table, unsigned long size, unsigned long sizemask, unsigned long used, was jeweils bedeutet
"Hash-Tabellenarray, Hash-Tabellengröße, für die Berechnung verwendet Der Indexwert ist immer gleich size-1 und der Anzahl der Knoten in der Hash-Tabelle.“.
ht[0] wird zum anfänglichen Speichern von Daten verwendet. Wenn diese erweitert oder verkleinert werden sollen, bestimmt die Größe von ht[0] die Größe von ht[1] und alle Schlüssel-Wert-Paare in ht[0] Es wird in ht[1] wiederaufbereitet. Erweiterungsoperation: Die erweiterte Größe von ht[1] ist die erste ganzzahlige Potenz von 2, die doppelt so groß ist wie der aktuelle Wert von ht[0].used; Verkleinerungsoperation: Die erste ganzzahlige Potenz von ht[0].used ist größer größer oder gleich einer ganzzahligen Potenz von 2.
Wenn alle Schlüssel-Wert-Paare auf ht[0] auf ht[1] umgeleitet werden, werden alle Array-Indexwerte neu berechnet. Wenn die Datenmigration abgeschlossen ist, wird ht[0] freigegeben und dann ht [. 1] wird in ht[0] geändert und ht[1] wird neu erstellt, um sich auf die nächste Erweiterung und Kontraktion vorzubereiten.
Progressive Aufbereitung
Wenn die Datenmenge während des Aufbereitungsprozesses sehr groß ist, kann Redis nicht alle Daten auf einmal erfolgreich aufbereiten, was dazu führt, dass der externe Dienst von Redis angehalten wird. Um diese Situation zu bewältigen, übernimmt Redis intern
„Progressive Aufwärmung“ „.
Redis unterteilt alle Rehash-Vorgänge in mehrere Schritte, bis alle Rehash-Vorgänge abgeschlossen sind. Die spezifische Implementierung hängt mit dem Rehashindex-Attribut im Objekt zusammen: „Wenn Rehashindex als -1 ausgedrückt wird, bedeutet dies, dass es keinen Rehash-Vorgang gibt.“
Wenn der Rehash-Vorgang beginnt, wird der Wert auf 0 geändert. Im Prozess des progressiven Rehash„Aktualisieren, Löschen und Abfragen werden sowohl in ht[0] als auch in ht[1] durchgeführt“, zum Beispiel: Aktualisieren Sie zuerst einen Wert. Aktualisieren Sie ht[0] und dann ht[1].
Die neue Operation wird direkt zur ht[1]-Tabelle hinzugefügt und ht[0] fügt keine Daten hinzu. Dadurch wird sichergestellt, dass"ht[0] nur abnimmt, aber nicht zunimmt, bis es sich im letzten Moment ändert . in eine leere Tabelle", und der Aufwärmvorgang ist abgeschlossen.
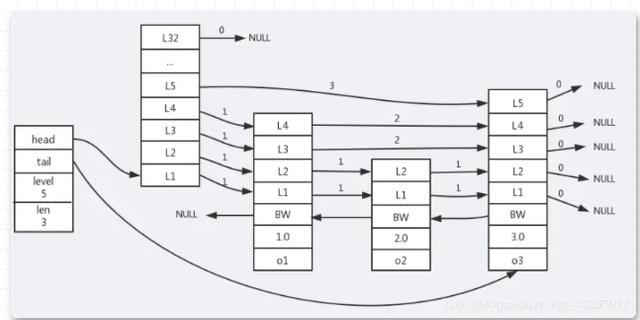
Das Obige ist das Implementierungsprinzip der zugrunde liegenden Hashtabelle des Wörterbuchs. Nachdem wir über das Implementierungsprinzip der Hashtabelle gesprochen haben, werfen wir einen Blick auf die beiden Speichermethoden der Hash-Datenstruktur: „ziplist (komprimierte Liste)“压缩列表(ziplist)是一组连续内存块组成的顺序的数据结构,压缩列表能够节省空间,压缩列表中使用多个节点来存储数据。 压缩列表是列表键和哈希键底层实现的原理之一,「压缩列表并不是以某种压缩算法进行压缩存储数据,而是它表示一组连续的内存空间的使用,节省空间」,压缩列表的内存结构图如下: 压缩列表中每一个节点表示的含义如下所示: zlbytes:4个字节的大小,记录压缩列表占用内存的字节数。 zltail:4个字节大小,记录表尾节点距离起始地址的偏移量,用于快速定位到尾节点的地址。 zllen:2个字节的大小,记录压缩列表中的节点数。 entry:表示列表中的每一个节点。 zlend:表示压缩列表的特殊结束符号'0xFF'。 再压缩列表中每一个entry节点又有三部分组成,包括previous_entry_ength、encoding、content。 previous_entry_ength表示前一个节点entry的长度,可用于计算前一个节点的其实地址,因为他们的地址是连续的。 encoding:这里保存的是content的内容类型和长度。 content:content保存的是每一个节点的内容。 说到这里相信大家已经都hash这种数据结构已经非常了解,若是第一次接触Redis五种基本数据结构的底层实现的话,建议多看几遍,下面来说一说hash的应用场景。 哈希表相对于String类型存储信息更加直观,擦欧总更加方便,经常会用来做用户数据的管理,存储用户的信息。 hash也可以用作高并发场景下使用Redis生成唯一的id。下面我们就以这两种场景用作案例编码实现。 第一个场景比如我们要储存用户信息,一般使用用户的ID作为key值,保持唯一性,用户的其他信息(地址、年龄、生日、电话号码等)作为value值存储。 若是传统的实现就是将用户的信息封装成为一个对象,通过序列化存储数据,当需要获取用户信息的时候,就会通过反序列化得到用户信息。 但是这样必然会造成序列化和反序列化的性能的开销,并且若是只修改其中的一个属性值,就需要把整个对象序列化出来,操作的动作太大,造成不必要的性能开销。 若是使用Redis的hash来存储用户数据,就会将原来的value值又看成了一个k v形式的存储容器,这样就不会带来序列化的性能开销的问题。 第二个场景就是生成分布式的唯一ID,这个场景下就是把redis封装成了一个工具类进行实现,实现的代码如下: (2)第二步创建redis的配置类,叫做RedisConfig,并标注上@Configuration注解,表明他是一个配置类。 (3)第三步就是创建Redis的工具类RedisUtil,自从学了面向对象后,就喜欢把一些通用的东西拆成工具类,好像一个一个零件,需要的时候,就把它组装起来。 这样就完成了Redis消息队列工具类的创建,在后面的代码中就可以直接使用。 Redis中列表和集合都可以用来存储字符串,但是「Set是不可重复的集合,而List列表可以存储相同的字符串」,Set集合是无序的这个和后面讲的ZSet有序集合相对。 Set的底层实现是「ht和intset」,ht(哈希表)前面已经详细了解过,下面我们来看看inset类型的存储结构。 inset也叫做整数集合,用于保存整数值的数据结构类型,它可以保存int16_t、int32_t 或者int64_t 的整数值。 在整数集合中,有三个属性值encoding、length、contents[],分别表示编码方式、整数集合的长度、以及元素内容,length就是记录contents里面的大小。 在整数集合新增元素的时候,若是超出了原集合的长度大小,就会对集合进行升级,具体的升级过程如下: 首先扩展底层数组的大小,并且数组的类型为新元素的类型。 然后将原来的数组中的元素转为新元素的类型,并放到扩展后数组对应的位置。 整数集合升级后就不会再降级,编码会一直保持升级后的状态。 Set集合的应用场景可以用来「去重、抽奖、共同好友、二度好友」等业务类型。接下来模拟一个添加好友的案例实现: 举一反三,还可以实现A用户自己的好友,或者B用户自己的好友等,都可以进行实现。 ZSet是有序集合,从上面的图中可以看到ZSet的底层实现是ziplist和skiplist实现的,ziplist上面已经详细讲过,这里来讲解skiplist的结构实现。 skiplist也叫做「跳跃表」,跳跃表是一种有序的数据结构,它通过每一个节点维持多个指向其它节点的指针,从而达到快速访问的目的。 skiplist由如下几个特点: 有很多层组成,由上到下节点数逐渐密集,最上层的节点最稀疏,跨度也最大。 每一层都是一个有序链表,只扫包含两个节点,头节点和尾节点。 每一层的每一个每一个节点都含有指向同一层下一个节点和下一层同一个位置节点的指针。 如果一个节点在某一层出现,那么该以下的所有链表同一个位置都会出现该节点。 具体实现的结构图如下所示: 跳跃表的结构中包含指向头节点和尾节点的指针head和tail,能够快速进行定位。当在跳跃表中从尾向前遍历时,层数用 level 表示,跳跃表长度用 len 表示,同时也会使用后退指针 BW。 BW下面还有两个值分别表示分值(score)和成员对象(各个节点保存的成员对象)。 跳跃表的实现中,除了最底层的一层保存的是原始链表的完整数据,上层的节点数会越来越少,并且跨度会越来越大。 跳跃表的上面层就相当于索引层,都是为了找到最后的数据而服务的,数据量越大,条表所体现的查询的效率就越高,和平衡树的查询效率相差无几。 因为ZSet是有序的集合,因此ZSet在实现排序类型的业务是比较常见的,比如在首页推荐10个最热门的帖子,也就是阅读量由高到低,排行榜的实现等业务。 下面就选用获取排行榜前前10名的选手作为案例实现,实现的代码如下所示: 以上的代码实现大致逻辑就是根据score分数值获取前10名的数据,然后封装成lawyerVO对象的列表进行返回。ziplist


应用场景
存储用户数据
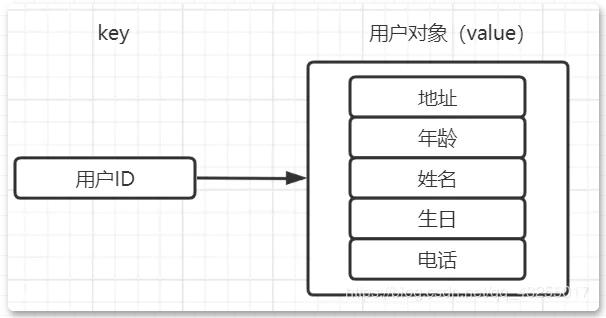
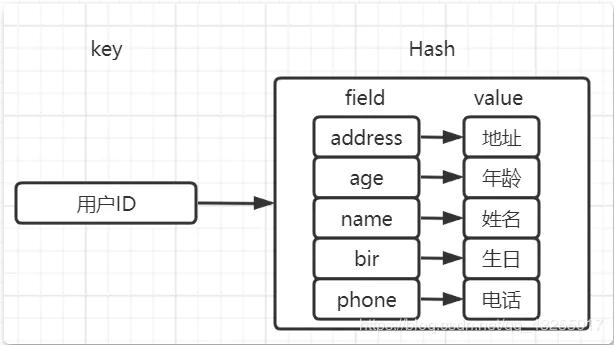
分布式生成唯一ID
// offset表示的是id的递增梯度值 public Long getId(String key,String hashKey,Long offset) throws BusinessException{ try { if (null == offset) { offset=1L; } // 生成唯一id return redisUtil.increment(key, hashKey, offset); } catch (Exception e) { //若是出现异常就是用uuid来生成唯一的id值 int randNo=UUID.randomUUID().toString().hashCode(); if (randNo <h3>List类型</h3><p>在 Redis 3.2 之前的版本,Redis 的列表是通过结合使用 ziplist 和 linkedlist 实现的。在3.2之后的版本就是引入了quicklist。</p><p>ziplist压缩列表上面已经讲过了,我们来看看linkedlist和quicklist的结构是怎么样的。</p><p>Linkedlist有双向链接,和普通的链表一样,都由指向前后节点的指针构成。时间复杂度为O(1)的操作包括插入、修改和更新,而时间复杂度为O(n)的操作是查询。</p><p>linkedlist和quicklist的底层实现是采用链表进行实现,在c语言中并没有内置的链表这种数据结构,Redis实现了自己的链表结构。</p><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/168511087742882.jpg" class="lazy" alt="Was ist das zugrunde liegende Prinzip von Redis?"></p><p>Redis中链表的特性:</p><ol class=" list-paddingleft-2">
<li><p>每一个节点都有指向前一个节点和后一个节点的指针。</p></li>
<li><p>头节点和尾节点的prev和next指针指向为null,所以链表是无环的。</p></li>
<li><p>链表有自己长度的信息,获取长度的时间复杂度为O(1)。</p></li>
</ol><p>Redis中List的实现比较简单,下面我们就来看看它的应用场景。</p><h3>应用场景</h3><p>Redis中的列表可以实现<strong>「阻塞队列」</strong>,结合lpush和brpop命令就可以实现。生产者使用lupsh从列表的左侧插入元素,消费者使用brpop命令从队列的右侧获取元素进行消费。</p><p>(1)首先配置redis的配置,为了方便我就直接放在application.yml配置文件中,实际中可以把redis的配置文件放在一个redis.properties文件单独放置,具体配置如下:</p><pre class="brush:php;toolbar:false">spring redis: host: 127.0.0.1 port: 6379 password: user timeout: 0 database: 2 pool: max-active: 100 max-idle: 10 min-idle: 0 max-wait: 100000@Configuration public class RedisConfiguration { @Value("{spring.redis.port}") private int port; @Value("{spring.redis.pool.max-active}") private int maxActive; @Value("{spring.redis.pool.min-idle}") private int minIdle; @Value("{spring.redis.database}") private int database; @Value("${spring.redis.timeout}") private int timeout; @Bean public JedisPoolConfig getRedisConfiguration(){ JedisPoolConfig jedisPoolConfig= new JedisPoolConfig(); jedisPoolConfig.setMaxTotal(maxActive); jedisPoolConfig.setMaxIdle(maxIdle); jedisPoolConfig.setMinIdle(minIdle); jedisPoolConfig.setMaxWaitMillis(maxWait); return jedisPoolConfig; } @Bean public JedisConnectionFactory getConnectionFactory() { JedisConnectionFactory factory = new JedisConnectionFactory(); factory.setHostName(host); factory.setPort(port); factory.setPassword(password); factory.setDatabase(database); JedisPoolConfig jedisPoolConfig= getRedisConfiguration(); factory.setPoolConfig(jedisPoolConfig); return factory; } @Bean public RedisTemplate, ?> getRedisTemplate() { JedisConnectionFactory factory = getConnectionFactory(); RedisTemplate, ?> redisTemplate = new StringRedisTemplate(factory); return redisTemplate; } }@Component public class RedisUtil { @Autowired private RedisTemplate<string> redisTemplate; /** 存消息到消息队列中 @param key 键 @param value 值 @return */ public boolean lPushMessage(String key, Object value) { try { redisTemplate.opsForList().leftPush(key, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** 从消息队列中弹出消息 - <rpop> @param key 键 @return */ public Object rPopMessage(String key) { try { return redisTemplate.opsForList().rightPop(key); } catch (Exception e) { e.printStackTrace(); return null; } } /** 查看消息 @param key 键 @param start 开始 @param end 结束 0 到 -1代表所有值 复制代码@return */ public List<object> getMessage(String key, long start, long end) { try { return redisTemplate.opsForList().range(key, start, end); } catch (Exception e) { e.printStackTrace(); return null; } }</object></rpop></string>Set集合
应用场景
@RequestMapping(value = "/addFriend", method = RequestMethod.POST) public Long addFriend(User user, String friend) { String currentKey = null; // 判断是否是当前用户的好友 if (AppContext.getCurrentUser().getId().equals(user.getId)) { currentKey = user.getId.toString(); } //若是返回0则表示不是该用户好友 return currentKey==null?0l:setOperations.add(currentKey, friend); }
假如两个用户A和B都是用上上面的这个接口添加了很多的自己的好友,那么有一个需求就是要实现获取A和B的共同好友,那么可以进行如下操作:public Set intersectFriend(User userA, User userB) { return setOperations.intersect(userA.getId.toString(), userB.getId.toString()); }ZSet集合
应用场景
@Autowired private RedisTemplate redisTemplate; /** * 获取前10排名 * @return */ public static List<levelvo> getZset(String key, long baseNum, LevelService levelService){ ZSetOperations<serializable> operations = redisTemplate.opsForZSet(); // 根据score分数值获取前10名的数据 Set<zsetoperations.typedtuple>> set = operations.reverseRangeWithScores(key,0,9); List<levelvo> list= new ArrayList<levelvo>(); int i=1; for (ZSetOperations.TypedTuple<object> o:set){ int uid = (int) o.getValue(); LevelCache levelCache = levelService.getLevelCache(uid); LevelVO levelVO = levelCache.getLevelVO(); long score = (o.getScore().longValue() - baseNum + levelVO .getCtime())/CommonUtil.multiplier; levelVO .setScore(score); levelVO .setRank(i); list.add( levelVO ); i++; } return list; }</object></levelvo></levelvo></zsetoperations.typedtuple></serializable></levelvo>
Das obige ist der detaillierte Inhalt vonWas ist das zugrunde liegende Prinzip von Redis?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!