
Welche Möglichkeiten gibt es, die Redis-Master-Slave-Architektur zu etablieren?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-26 16:23:071236Durchsuche
Master-Slave-Umgebungskonstruktion
Redis-Instanzen sind standardmäßig alle Master-Knoten, daher müssen wir einige Konfigurationen ändern, um eine Master-Slave-Architektur zu erstellen. Die Master-Slave-Architektur von Redis bietet drei Möglichkeiten zum Erstellen Erstellen Sie eine Master-Slave-Architektur, die wir später vorstellen werden. Bevor wir sie vorstellen, müssen wir zunächst die Merkmale der Master-Slave-Architektur verstehen: In der Master-Slave-Architektur gibt es einen Masterknoten (Master) und mindestens einen Slave Knoten (Slave), und die Datenreplikation erfolgt in eine Richtung. Sie kann nur vom Master-Knoten auf den Slave-Knoten kopiert werden, nicht vom Slave-Knoten auf den Master-Knoten.
So richten Sie die Master-Slave-Architektur ein
Es gibt drei Möglichkeiten, die Master-Slave-Architektur einzurichten:
Fügen Sie den Befehl „slaveof {masterHost} {masterPort} zur Konfigurationsdatei Redis.conf hinzu und erstellen Sie ihn wird wirksam, wenn die Redis-Instanz gestartet wird.
Fügen Sie den Parameter --slaveof {masterHost} {masterPort} nach dem Redis-Server-Startbefehl hinzu.
Verwenden Sie den Befehl direkt im interaktiven Fenster von redis-cli: Slaveof {masterHost} {masterPort}
Die oben genannten drei Redis-Master-Slave-Architekturen können auf jede dieser Arten erstellt werden. Wir werden die erste Methode demonstrieren und die anderen beiden Methoden selbst ausprobieren Starten Sie zwei Redis-Instanzen lokal, anstatt Redis-Instanzen auf mehreren Maschinen zu starten. Jetzt bereiten wir eine Master-Knoten-Instanz mit Port 6379 und eine Slave-Knoten-Instanz mit Port 6480 vor. Die Redis-Instanz-Konfigurationsdatei von Port 6480 heißt 6480.conf und fügt hinzu Fügen Sie die folgende Anweisung am Ende der Konfigurationsdatei hinzu.
slaveof 127.0.0.1 6379
Nach dem Start stellen sie automatisch eine Master-Slave-Beziehung her. Über das Prinzip dahinter sprechen wir zunächst im Detail Fügen Sie zuerst ein neues Datenelement auf dem 6379-Master-Knoten hinzu:

Der Master-Knoten fügt Daten hinzu
Rufen Sie dann die Daten auf dem 6480-Slave-Knoten ab:
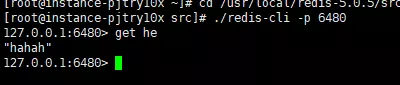
Slave-Knoten erhält die Daten
Sie können sehen Dass wir uns auf dem Slave-Knoten befinden Der neu hinzugefügte Wert wurde erfolgreich auf dem Master-Knoten abgerufen, was darauf hinweist, dass die Master-Slave-Architektur erfolgreich eingerichtet wurde. Wir verwenden den Info-Replikationsbefehl, um die Informationen der beiden Knoten anzuzeigen an den Informationen des Masterknotens.
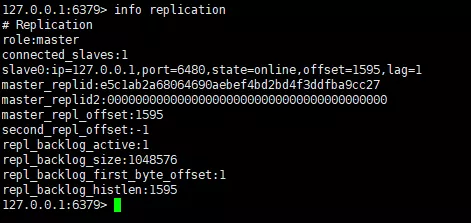
Master-Info-Replikation
Sie können sehen, dass die Instanzrolle von Port 6379 Master ist, dass eine Instanz verbunden ist und andere laufende Informationen werfen wir einen Blick auf die Redis-Instanzinformationen von Port 6480.
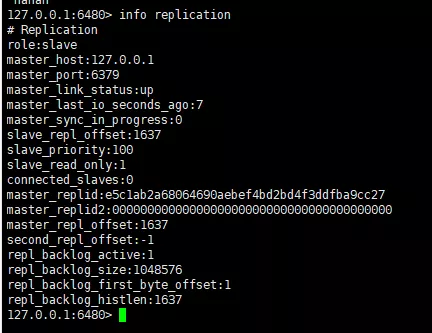
Slave-Informationsreplikation
Sie können beobachten, dass die beiden Knoten Objektinformationen miteinander aufzeichnen und diese Informationen während der Datenreplikation verwendet werden. Eines muss hier erklärt werden: Der Slave-Knoten ist standardmäßig schreibgeschützt und unterstützt das Schreiben nicht. Wir können dies überprüfen und Daten auf die 6480-Instanz schreiben.
127.0.0.1:6480> set x 3 (error) READONLY You can't write against a read only replica. 127.0.0.1:6480>
Die Eingabeaufforderung ist schreibgeschützt und unterstützt keine Schreibvorgänge. Natürlich können wir auch das Konfigurationselement „replica-read-only“ in der Konfigurationsdatei verwenden, um den schreibgeschützten Zugriff vom Server aus zu steuern. Warum kann es nur schreibgeschützt sein? Da wir wissen, dass die Replikation nur in eine Richtung erfolgt, können Daten nur vom Master zum Slave-Knoten gesendet werden. Wenn das Schreiben auf dem Slave-Knoten aktiviert ist, werden die Daten des Slave-Knotens geändert . Der Master-Knoten kann dies nicht erkennen und die Daten des Slave-Knotens können nicht auf den Master-Knoten kopiert werden. Dies führt zu Dateninkonsistenzen. Daher wird empfohlen, dass der Slave-Knoten schreibgeschützt ist.
Trennen der Master-Slave-Architektur
Das Ausführen des Slaveof-Befehls auf dem Slave-Knoten kann die folgende Beziehung vom Master-Knoten trennen auf dem 6480-Knoten.
127.0.0.1:6480> slaveof no one OK 127.0.0.1:6480> info replication # Replication role:master connected_slaves:0 master_replid:a54f3ba841c67762d6c1e33456c97b94c62f6ac0 master_replid2:e5c1ab2a68064690aebef4bd2bd4f3ddfba9cc27 master_repl_offset:4367 second_repl_offset:4368 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:4367 127.0.0.1:6480>
Nachdem der Befehl „slaveof no one“ ausgeführt wurde, wurde die Rolle des 6480-Knotens sofort auf „master“ zurückgesetzt. Schauen wir uns noch einmal an, dass er immer noch mit der 6379-Instanz verbunden ist Knoten.
127.0.0.1:6379> set y 3 OK
y auf dem 6480-Knoten abrufen
127.0.0.1:6480> get y (nil) 127.0.0.1:6480>
y kann auf dem 6480-Knoten nicht abgerufen werden, da der 6480-Knoten vom 6379-Knoten getrennt wurde und keine Master-Slave-Beziehung besteht. Der Befehl „slaveof“ kann nicht nur die Verbindung trennen, sondern auch Um den Master-Server zu wechseln, verwenden Sie den Befehl „slaveof“ {newMasterIp} „{newMasterPort}“. Lassen Sie 6379 zum Slave-Knoten von 6480 werden. Führen Sie den Befehl „slaveof 127.0.0.1 6480“ auf dem 6379-Knoten aus .
127.0.0.1:6379> info replication # Replication role:slave master_host:127.0.0.1 master_port:6480 master_link_status:up master_last_io_seconds_ago:2 master_sync_in_progress:0 slave_repl_offset:4367 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:99624d4b402b5091552b9cb3dd9a793a3005e2ea master_replid2:0000000000000000000000000000000000000000 master_repl_offset:4367 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:4368 repl_backlog_histlen:0 127.0.0.1:6379>
Die Rolle des Knotens 6379 ist bereits Slave und der Masterknoten ist 6480. Wir können uns die Informationsreplikation von Knoten 6480 ansehen.
127.0.0.1:6480> info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6379,state=online,offset=4479,lag=1 master_replid:99624d4b402b5091552b9cb3dd9a793a3005e2ea master_replid2:a54f3ba841c67762d6c1e33456c97b94c62f6ac0 master_repl_offset:4479 second_repl_offset:4368 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:4479 127.0.0.1:6480>
Es gibt 6379 Slave-Knoteninformationen auf dem 6480-Knoten. Es ist ersichtlich, dass der Befehl „slaveof“ uns dabei geholfen hat, den Master-Server-Wechsel abzuschließen.
复制技术的原理
redis 的主从架构好像很简单一样,我们就执行了一条命令就成功搭建了主从架构,并且数据复制也没有问题,使用起来确实简单,但是这背后 redis 还是帮我们做了很多的事情,比如主从服务器之间的数据同步、主从服务器的状态检测等,这背后 redis 是如何实现的呢?接下来我们就一起看看。
数据复制原理
我们执行完 slaveof 命令之后,我们的主从关系就建立好了,在这个过程中, master 服务器与 slave 服务器之间需要经历多个步骤,如下图所示:

redis 复制原理
slaveof 命令背后,主从服务器大致经历了七步,其中权限验证这一步不是必须的,为了能够更好的理解这些步骤,就以我们上面搭建的 redis 实例为例来详细聊一聊各步骤。
1、保存主节点信息
在 6480 的客户端向 6480 节点服务器发送 slaveof 127.0.0.1 6379 命令时,我们会立马得到一个 OK。
127.0.0.1:6480> slaveof 127.0.0.1 6379 OK 127.0.0.1:6480>
这时候数据复制工作并没有开始,数据复制工作是在返回 OK 之后才开始执行的,这时候 6480 从节点做的事情是将给定的主服务器 IP 地址 127.0.0.1 以及端口 6379 保存到服务器状态的 masterhost 属性和 masterport 属性里面。
2、建立 socket 连接
在 slaveof 命令执行完之后,从服务器会根据命令设置的 IP 地址和端口,跟主服务器创建套接字连接, 如果从服务器能够跟主服务器成功的建立 socket 连接,那么从服务器将会为这个 socket 关联一个专门用于处理复制工作的文件事件处理器,这个处理器将负责后续的复制工作,比如接受全量复制的 RDB 文件以及服务器传来的写命令。同样主服务器在接受从服务器的 socket 连接之后,将为该 socket 创建一个客户端状态,这时候的从服务器同时具有服务器和客户端两个身份,从服务器可以向主服务器发送命令请求而主服务器则会向从服务器返回命令回复。
3、发送 ping 命令
从服务器与主服务器连接成功后,做的第一件事情就是向主服务器发送一个 ping 命令,发送 ping 命令主要有以下目的:
检测主从之间网络套接字是否可用
检测主节点当前是否可接受处理命令
在发送 ping 命令之后,正常情况下主服务器会返回 pong 命令,接受到主服务器返回的 pong 回复之后就会进行下一步工作,如果没有收到主节点的 pong 回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从服务器会断开复制连接,等待下一次定时任务的调度。
4、身份验证
从服务器在接收到主服务器返回的 pong 回复之后,下一步要做的事情就是根据配置信息决定是否需要身份验证:
如果从服务器设置了 masterauth 参数,则进行身份验证
如果从服务器没有设置 masterauth 参数,则不进行身份验证
在需要身份验证的情况下,从服务器将就向主服务器发送一条 auth 命令,命令参数为从服务器 masterauth 选项的值,举个例子,如果从服务器的配置里将 masterauth 参数设置为:123456,那么从服务器将向主服务器发送 auth 123456 命令,身份验证的过程也不是一帆风顺的,可能会遇到以下几种情况:
从服务器通过 auth 命令发送的密码与主服务器的 requirepass 参数值一致,那么将继续进行后续操作,如果密码不一致,主服务将返回一个 invalid password 错误
如果主服务器没有设置 requirepass 参数,那么主服务器将返回一个 no password is set 错误
所有的错误情况都会令从服务器中止当前的复制工作,并且要从建立 socket 开始重新发起复制流程,直到身份验证通过或者从服务器放弃执行复制为止。
5. Portinformationen senden
Nachdem die Authentifizierung bestanden wurde, führt der Slave-Server den Abhörbefehl REPLCONF aus und sendet die Abhörportnummer des Slave-Servers an den Master-Server des Slave-Servers ist 6480, dann sendet der Slave-Server den REPLCONF-Listenbefehl 6480 an den Master-Server. Nachdem der Master-Server diesen Befehl empfangen hat, zeichnet er die Portnummer im Attribut „slave_listening_port“ des Client-Status auf, der dem Slave-Server entspricht Das heißt, wir können es in der Informationsreplikation des Master-Servers auf den Portwert sehen.
6. Die Datenreplikation ist der komplizierteste Teil. Der Slave-Server sendet einen psync-Befehl zur Datensynchronisierung Neben unterschiedlichen Befehlen gab es auch große Unterschiede in den Replikationsmethoden. Vor der Redis-Version 2.8 wurde die vollständige Replikation verwendet, was einen großen Overhead auf dem Masterknoten und im Netzwerk verursachen würde. Die Datensynchronisierung wird in vollständige Synchronisierung und teilweise Synchronisierung unterteilt.
Vollständige Replikation: Wird im Allgemeinen in anfänglichen Replikationsszenarien verwendet. Unabhängig von der alten oder neuen Version von Redis wird eine vollständige Replikation durchgeführt, wenn sich der Slave-Server zum ersten Mal mit dem Master-Dienst verbindet Wenn die Datenmenge vom Master-Knoten zum Slave-Knoten groß ist, verursacht dies einen hohen Overhead für den Master-Knoten und das Netzwerk. Frühe Versionen von Redis unterstützen nur die vollständige Replikation, was keine effiziente Datenreplikationsmethode ist- Teilweise Replikation: Wird verwendet, um Datenverluste aufgrund von Netzwerkunterbrechungen und anderen Gründen bei der Master-Slave-Replikation zu verarbeiten. Wenn der Slave-Knoten erneut eine Verbindung zum Master-Knoten herstellt und die Bedingungen dies zulassen, sendet der Master-Knoten die verlorenen Daten erneut zum Slave-Knoten. Da die neu ausgegebenen Daten weitaus kleiner sind als die gesamte Datenmenge, kann der übermäßige Aufwand des vollständigen Kopierens effektiv vermieden werden. Das teilweise Kopieren ist eine wesentliche Optimierung der alten Version des Kopierens und vermeidet effektiv unnötige vollständige Kopiervorgänge Unterstützung für vollständiges Kopieren und teilweises Kopieren. Nach Redis-Version 2.8 wird ein neuer psync-Befehl verwendet. Das Befehlsformat lautet: psync {runId} {offset} runId: Die ID des Master-Knotens, der ausgeführt wird
- Offset: Der Offset der aktuell vom Slave-Knoten kopierten Daten
- 1. Replikations-Offset
- Die an der Replikation beteiligten Master- und Slave-Knoten behalten jeweils ihre eigenen Replikations-Offsets bei: Jedes Mal, wenn der Master-Server N Bytes an Daten an den Slave-Server überträgt Addiert N zum Wert, jedes Mal, wenn der Slave-Server N Bytes an vom Master-Server übertragenen Daten empfängt, addiert er N zu seinem eigenen Offset-Wert. Durch den Vergleich der Replikationsoffsets der Master- und Slave-Server können Sie feststellen, ob die Daten der Master- und Slave-Server konsistent sind. Wenn die Offsets der Master- und Slave-Server immer gleich sind, sind die Master- und Slave-Daten konsistent. Im Gegenteil, wenn die Offsets der Master- und Slave-Server konsistent sind. Wenn der Verschiebungsbetrag nicht gleich ist, bedeutet dies, dass sich die Master- und Slave-Server nicht in einem konsistenten Datenzustand befinden, wenn beispielsweise mehrere Slave-Server vorhanden sind , geht ein bestimmter Server während des Übertragungsvorgangs offline, wie in der folgenden Abbildung dargestellt:
- Offset-Inkonsistenz
Da Slave-Server A während der Datenübertragung aus Netzwerkgründen getrennt wurde, stimmt der Offset nicht mit dem Master-Server überein Wenn Slave-Server A neu startet und erfolgreich eine Verbindung zum Master-Server herstellt, sendet er den psync-Befehl erneut an den Master-Server. Wie erfolgt die Datenreplikation zu diesem Zeitpunkt? Der Master-Server kompensiert den Teil der Daten, die Slave-Server A während der Trennung verloren hat. Die Antworten auf diese Fragen befinden sich alle im Replikations-Backlog-Puffer.
2. Replikations-Backlog-Puffer
Der Replikations-Backlog-Puffer ist eine Warteschlange mit fester Länge, die auf dem Master-Knoten gespeichert ist. Die Standardgröße beträgt 1 MB Reagiert auf einen Schreibbefehl, sendet er den Befehl nicht nur an den Slave-Knoten, sondern schreibt ihn auch in den Replikations-Backlog-Puffer, wie in der folgenden Abbildung dargestellt:
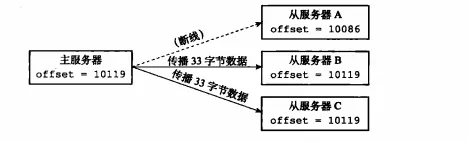
Replikations-Backlog-Puffer
Daher ist die Replikation von Der Backlog-Puffer des Master-Servers speichert einen Teil der kürzlich weitergeleiteten Schreibbefehle, und der Copy-Backlog-Puffer zeichnet den entsprechenden Copy-Offset für jedes Byte in der Warteschlange auf. Wenn sich der Slave-Server also wieder mit dem Master-Server verbindet, sendet der Slave-Server seinen Replikations-Offset-Offset über den psync-Befehl an den Master-Server. Der Master-Server verwendet diesen Replikations-Offset, um zu entscheiden, welcher Datensynchronisierungsvorgang auf dem Slave-Server durchgeführt werden soll:
Wenn die Daten nach dem Replikationsoffset des Slave-Servers noch im Replikations-Backlog-Puffer vorhanden sind, führt der Master-Server teilweise Replikationsvorgänge auf dem Slave-Server aus
如果从服务器的复制偏移量之后的数据不存在于复制积压缓冲区里面,那么主服务器将对从服务器执行全量复制操作
3、服务器运行ID
每个 Redis 节点启动后都会动态分配一个 40 位的十六进制字符串作为运行 ID,运行 ID 的主要作用是用来唯一识别 Redis 节点,我们可以使用 info server 命令来查看
127.0.0.1:6379> info server # Server redis_version:5.0.5 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:2ef1d58592147923 redis_mode:standalone os:Linux 3.10.0-957.27.2.el7.x86_64 x86_64 arch_bits:64 multiplexing_api:epoll atomicvar_api:atomic-builtin gcc_version:4.8.5 process_id:25214 run_id:7b987673dfb4dfc10dd8d65b9a198e239d20d2b1 tcp_port:6379 uptime_in_seconds:14382 uptime_in_days:0 hz:10 configured_hz:10 lru_clock:14554933 executable:/usr/local/redis-5.0.5/src/./redis-server config_file:/usr/local/redis-5.0.5/redis.conf 127.0.0.1:6379>
这里面有一个run_id 字段就是服务器运行的ID
在熟悉这几个概念之后,我们可以一起探讨 psync 命令的运行流程,具体如下图所示:
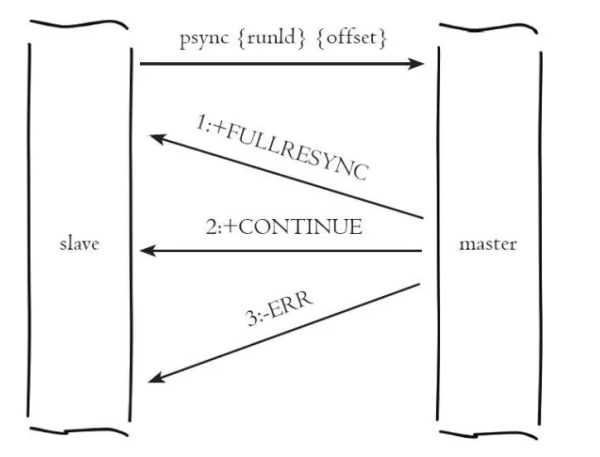
psync 运行流程
psync 命令的逻辑比较简单,整个流程分为两步:
1、从节点发送 psync 命令给主节点,参数 runId 是当前从节点保存的主节点运行ID,参数offset是当前从节点保存的复制偏移量,如果是第一次参与复制则默认值为 -1。
2、主节点接收到 psync 命令之后,会向从服务器返回以下三种回复中的一种:
回复 +FULLRESYNC {runId} {offset}:表示主服务器将与从服务器执行一次全量复制操作,其中 runid 是这个主服务器的运行 id,从服务器会保存这个id,在下一次发送 psync 命令时使用,而 offset 则是主服务器当前的复制偏移量,从服务器会将这个值作为自己的初始化偏移量
回复 +CONTINUE:那么表示主服务器与从服务器将执行部分复制操作,从服务器只要等着主服务器将自己缺少的那部分数据发送过来就可以了
回复 +ERR:那么表示主服务器的版本低于 redis 2.8,它识别不了 psync 命令,从服务器将向主服务器发送 sync 命令,并与主服务器执行全量复制
7、命令持续复制
当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。主从服务器之间的连接不会中断,因为主节点会持续发送写命令到从节点,以确保主从数据的一致性。
经过上面 7 步就完成了主从服务器之间的数据同步,由于这篇文章的篇幅比较长,关于全量复制和部分复制的细节就不介绍了,全量复制就是将主节点的当前的数据生产 RDB 文件,发送给从服务器,从服务器再从本地磁盘加载,这样当文件过大时就需要特别大的网络开销,不然由于数据传输比较慢会导致主从数据延时较大,部分复制就是主服务器将复制积压缓冲区的写命令直接发送给从服务器。
心跳检测
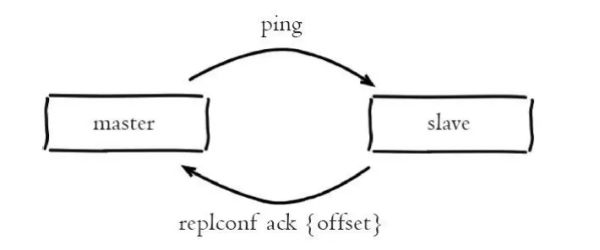
心跳检测是发生在主从节点在建立复制后,它们之间维护着长连接并彼此发送心跳命令,便以后续持续发送写命令,主从心跳检测如下图所示:
主从心跳检测
主从节点彼此都有心跳检测机制,各自模拟成对方的客户端进行通信,主从心跳检测的规则如下:
默认情况下,主节点会每隔 10 秒向从节点发送 ping 命令,以检测从节点的连接状态和是否存活。可通过修改 redis.conf 配置文件里面的 repl-ping-replica-period 参数来控制发送频率
从节点在主线程中每隔 1 秒发送 replconf ack {offset} 命令,给主节点 上报自身当前的复制偏移量,这条命令除了检测主从节点网络之外,还通过发送复制偏移量来保证主从的数据一致
主节点根据 replconf 命令判断从节点超时时间,体现在 info replication 统 计中的 lag 信息中,我们在主服务器上执行 info replication 命令:
127.0.0.1:6379> info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6480,state=online,offset=25774,lag=0 master_replid:c62b6621e3acac55d122556a94f92d8679d93ea0 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:25774 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:25774 127.0.0.1:6379>
可以看出 slave0 字段的值最后面有一个 lag,lag 表示与从节点最后一次通信延迟的秒数,正常延迟应该在 0 和 1 之间。如果超过 repl-timeout 配置的值(默认60秒),则判定从节点下线并断开复制客户端连接,如果从节点重新恢复,心跳检测会继续进行。
主从拓扑架构
Redis 的主从拓扑结构可以支持单层或多层复制关系,根据拓扑复杂性可以分为以下三种:一主一从、一主多从、树状主从架构。
一主一从结构
一主一从结构是最简单的复制拓扑结构,我们前面搭建的就是一主一从的架构,架构如图所示:
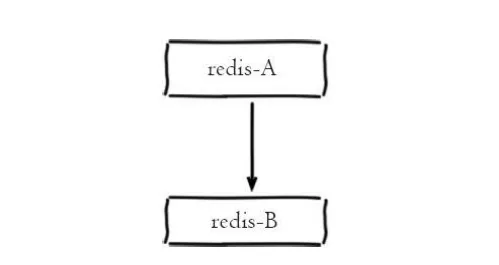
一主一从架构
Eine Master- und eine Slave-Architektur
wird verwendet, um Failover-Unterstützung vom Slave-Knoten bereitzustellen, wenn der Master-Knoten ausfällt hoch und bedarf Bei der Persistenz können Sie AOF nur auf dem Slave-Knoten aktivieren, was nicht nur die Datensicherheit gewährleistet, sondern auch die Leistungsbeeinträchtigung der Persistenz auf dem Master-Knoten vermeidet. Hier gibt es jedoch eine Grube, die Ihre Aufmerksamkeit erfordert: Wenn der Masterknoten die Persistenzfunktion deaktiviert, vermeiden Sie einen automatischen Neustart, wenn der Masterknoten offline geht. Da der Master-Knoten die Persistenzfunktion noch nicht aktiviert hat, ist der Datensatz nach dem automatischen Neustart leer. Wenn der Slave-Knoten zu diesem Zeitpunkt weiterhin den Master-Knoten kopiert, werden auch die Daten des Slave-Knotens gelöscht der Beharrlichkeit geht verloren. Der sichere Ansatz besteht darin, „slaveof noone“ auf dem Slave-Knoten auszuführen, um die Replikationsbeziehung mit dem Master-Knoten zu trennen, und dann den Master-Knoten neu zu starten, um dieses Problem zu vermeiden.
Eine Master- und mehrere Slaves-Architektur Eine Master- und mehrere Slaves-Architektur wird auch als Sterntopologie bezeichnet. Die folgende Abbildung zeigt:
#🎜🎜 ##🎜 🎜# Eine Master- und mehrere Slaves-Architektur
Eine Master- und mehrere Slaves-Architektur
Die Ein-Master- und mehrere Slaves-Architektur kann die Trennung von Lesen und Schreiben realisieren, um den Druck auf den Hauptserver zu verringern Das Leseverhältnis ist relativ groß, und der Lesebefehl kann an gesendet werden. Die Slave-Knoten teilen sich den Druck des Master-Knotens. Wenn Sie während der täglichen Entwicklung einige zeitaufwändige Lesebefehle wie Schlüssel, Sortierung usw. ausführen müssen, können Sie diese gleichzeitig auf einem der Slave-Knoten ausführen, um zu verhindern, dass langsame Abfragen den Master-Knoten blockieren und beeinträchtigen die Stabilität von Online-Diensten. In Szenarien mit hoher Schreibparallelität führen mehrere Slave-Knoten dazu, dass der Master-Knoten Schreibbefehle mehrmals sendet, was die Netzwerkbandbreite übermäßig beansprucht, die Belastung des Master-Knotens erhöht und die Dienststabilität beeinträchtigt.
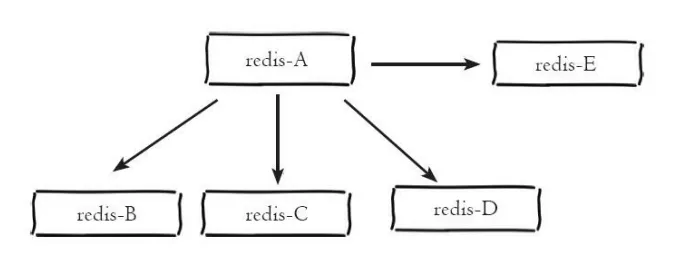
Baum-Master-Slave-ArchitekturBaum-Master-Slave-Architektur wird auch Baumtopologie-Architektur genannt. Die Baum-Master-Slave-Architektur ist wie gezeigt in der Abbildung unten Anzeige:
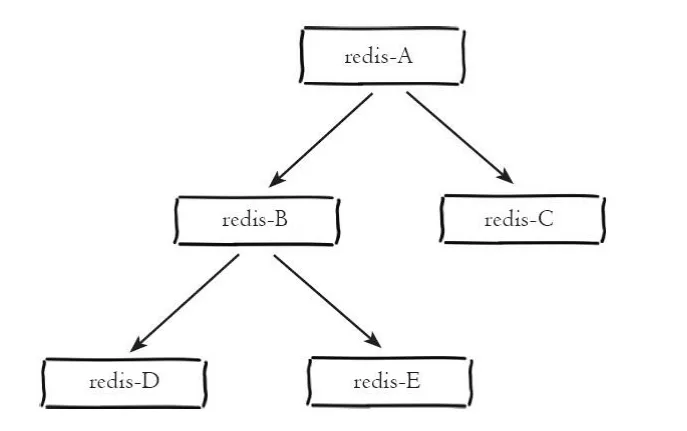 Baumartige Master-Slave-Architektur
Baumartige Master-Slave-Architektur
Die baumartige Master-Slave-Architektur ermöglicht Der Slave-Knoten kopiert nicht nur die Daten des Master-Abschnitts, sondern kann auch weiterhin als Master-Knoten andere Slave-Knoten auf die untere Ebene kopieren. Es behebt die Mängel der Ein-Master-Multi-Slave-Architektur und führt die Replikationszwischenschicht ein, die die Belastung des Master-Knotens und die Datenmenge, die an die Slave-Knoten übertragen werden muss, effektiv reduzieren kann. Wie im Architekturdiagramm dargestellt, werden die Daten, nachdem sie auf Knoten A geschrieben wurden, mit den Knoten B und C synchronisiert. Knoten B synchronisiert die Daten dann mit den Knoten D und E. Die Daten werden Schicht für Schicht repliziert. Um Störungen der Leistung des Master-Knotens zu vermeiden, kann der Master-Knoten eine Baum-Master-Slave-Struktur übernehmen, wenn er mehrere Slave-Knoten montieren muss, um seinen Lastdruck zu reduzieren.
Das obige ist der detaillierte Inhalt vonWelche Möglichkeiten gibt es, die Redis-Master-Slave-Architektur zu etablieren?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!