
Heim >Technologie-Peripheriegeräte >KI >AI Morning Post |. Wie erleben Sie die gegenseitige Generierung von Text, Bild, Audio und Video sowie 3D?
AI Morning Post |. Wie erleben Sie die gegenseitige Generierung von Text, Bild, Audio und Video sowie 3D?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-26 14:29:081669Durchsuche

Am 9. Mai Ortszeit kündigte Meta die Open Source eines neuen KI-Modells ImageBind an, das 6 verschiedene Modalitäten umfassen kann, darunter Sehen (Bild- und Videoformen), Temperatur (Infrarotbild), Text, Audio und Tiefeninformationen, Bewegung Messwerte (erzeugt von einer Trägheitsmesseinheit oder IMU). Derzeit ist der entsprechende Quellcode auf GitHub gehostet.
Was bedeutet es, 6 Modi zu umfassen?
ImageBind nimmt die Vision als Kern und kann 6 Modi frei verstehen und zwischen ihnen konvertieren. Meta zeigte einige Fälle, wie zum Beispiel das Bellen eines Hundes und das Zeichnen eines Hundes und gleichzeitig die entsprechende Tiefenkarte und Textbeschreibung, wie zum Beispiel die Eingabe eines Bildes eines Vogels + des Geräusches von Meereswellen und das Erhalten eines Bildes von ein Vogel am Strand.
Im Vergleich zu Bildgeneratoren wie Midjourney, Stable Diffusion und DALL-E 2, die Text mit Bildern koppeln, ähnelt ImageBind eher dem Auswerfen eines weiten Netzes und kann Text, Bilder/Videos, Audio, 3D-Messungen (Tiefe) und Temperaturdaten (Wärme) verbinden ) und Bewegungsdaten (von der IMU) und sagt die Zusammenhänge zwischen den Daten ohne vorheriges Training für jede Möglichkeit direkt vorher, ähnlich wie Menschen ihre Umgebung wahrnehmen oder sich vorstellen.

Forscher sagen, dass ImageBind mit großen visuellen Sprachmodellen (wie CLIP) initialisiert werden kann und so die reichhaltigen Bild- und Textdarstellungen dieser Modelle nutzt. Daher kann ImageBind mit sehr wenig Schulung an verschiedene Modalitäten und Aufgaben angepasst werden.
ImageBind ist Teil von Metas Engagement für die Entwicklung multimodaler KI-Systeme, die aus allen relevanten Datentypen lernen. Da die Anzahl der Modalitäten zunimmt, öffnet ImageBind den Forschern die Schleusen, neue ganzheitliche Systeme zu entwickeln, beispielsweise die Kombination von 3D- und IMU-Sensoren, um immersive virtuelle Welten zu entwerfen oder zu erleben. Es bietet auch eine umfassende Möglichkeit, Ihr Gedächtnis zu erkunden, indem es eine Kombination aus Text, Video und Bildern verwendet, um nach Bildern, Videos, Audiodateien oder Textinformationen zu suchen.
Dieses Modell ist derzeit nur ein Forschungsprojekt und hat keine direkten Verbraucher- oder praktischen Anwendungen, aber es zeigt, wie generative KI in Zukunft immersive, multisensorische Inhalte generieren kann, und zeigt auch, dass Meta mit OpenAI, Google Wait, zusammenarbeitet dass Wettbewerber unterschiedliche Ansätze verfolgen und einen Weg finden, der zum großen Open-Source-Modell gehört.
Letztendlich glaubt Meta, dass die ImageBind-Technologie irgendwann über die aktuellen sechs „Sinne“ hinausgehen wird, und sagt in seinem Blog: „Während wir in unserer aktuellen Forschung sechs Modi untersucht haben, glauben wir an die Einführung einer Technologie, die so viele Sinne wie möglich verbindet. Neue Modalitäten.“ – wie Berührungs-, Sprach-, Geruchs- und fMRT-Signale des Gehirns – werden umfassendere, auf den Menschen ausgerichtete KI-Modelle ermöglichen ”
Zweck von ImageBind
Wenn ChatGPT als Suchmaschine und Frage-und-Antwort-Community dienen kann und Midjourney als Zeichentool verwendet werden kann, was können Sie dann mit ImageBind tun?
Laut offizieller Demo kann es Audio direkt aus Bildern generieren:
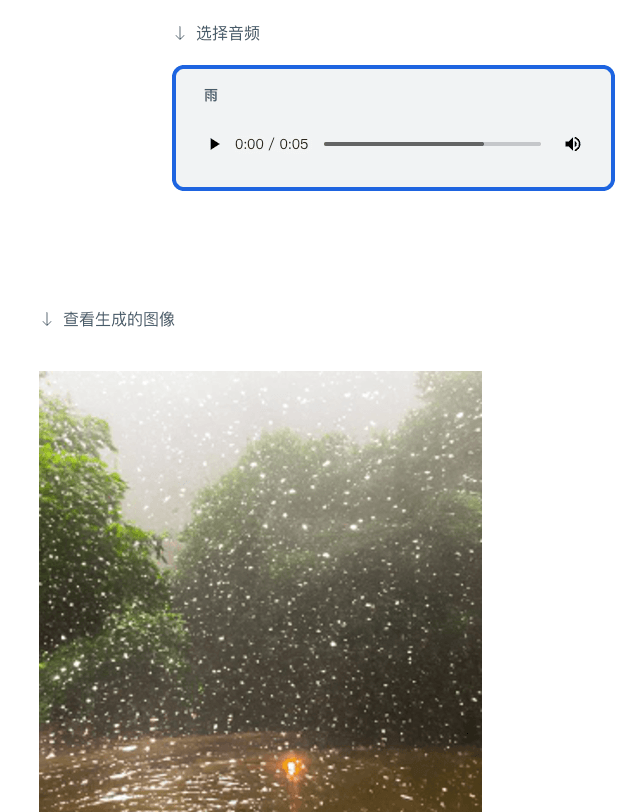
Sie können auch Bilder aus Audio generieren:
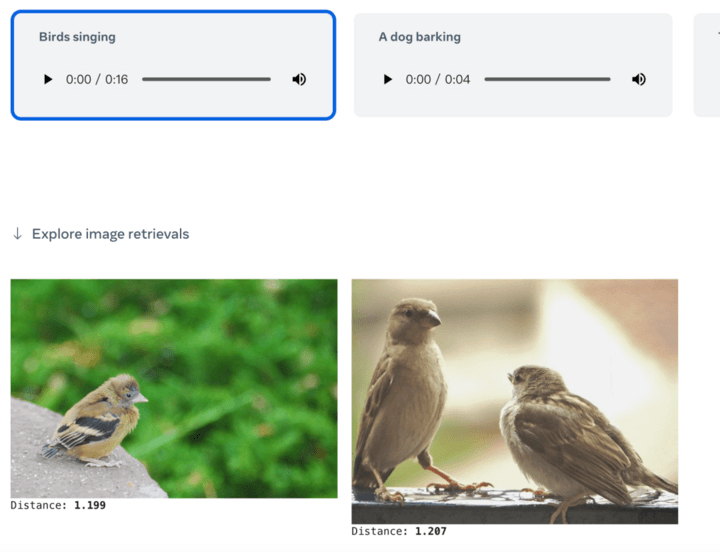
Oder geben Sie einfach einen Text ein, um zugehörige Bilder oder Audioinhalte abzurufen:
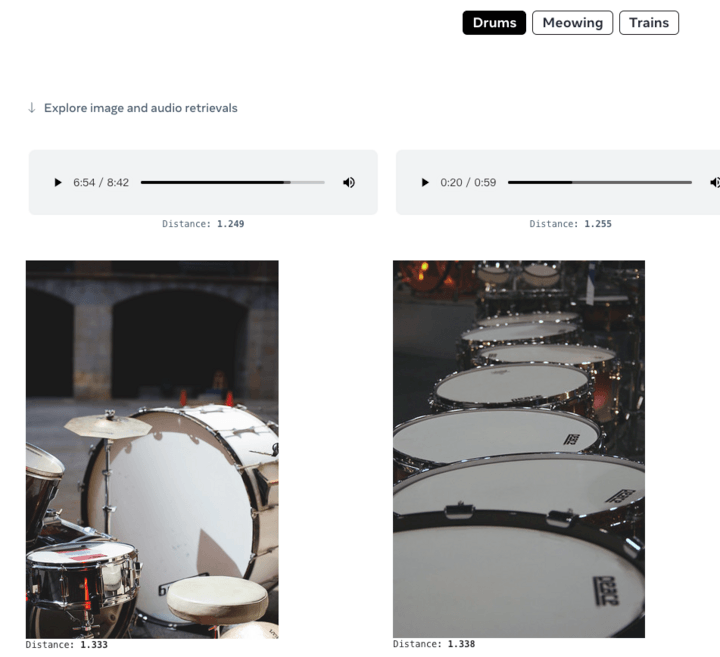
Sie können auch Audio geben und entsprechende Bilder generieren:
Wie oben erwähnt, bietet ImageBind eine Möglichkeit für die Darstellung zukünftiger generativer KI-Systeme in mehreren Modalitäten und gleichzeitig in Kombination mit Technologien und Szenarien wie Virtual Reality, Mixed Reality und Metaverse innerhalb von Meta. Der Einsatz von Tools wie ImageBind wird beispielsweise neue Türen in zugänglichen Räumen öffnen und Multimedia-Beschreibungen in Echtzeit generieren, um Menschen mit Seh- oder Hörbehinderungen dabei zu helfen, ihre unmittelbare Umgebung besser wahrzunehmen.
Über multimodales Lernen gibt es noch viel zu entdecken. Derzeit ist es im Bereich der künstlichen Intelligenz nicht gelungen, Skalierungsverhalten, das nur in größeren Modellen auftritt, effektiv zu quantifizieren und ihre Anwendungen nicht zu verstehen. ImageBind ist ein Schritt zur gründlichen Evaluierung und Demonstration neuer Anwendungen für die Bilderzeugung und den Abruf.
Autor: Ballad
Quelle: First Electric Network (www.d1ev.com)
Das obige ist der detaillierte Inhalt vonAI Morning Post |. Wie erleben Sie die gegenseitige Generierung von Text, Bild, Audio und Video sowie 3D?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr