
Heim >Technologie-Peripheriegeräte >KI >Zusammenfassung des CVPR 2023-Papiers! Der heißeste CV-Bereich wird an multimodale und Diffusionsmodelle vergeben
Zusammenfassung des CVPR 2023-Papiers! Der heißeste CV-Bereich wird an multimodale und Diffusionsmodelle vergeben

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-25 15:10:351425Durchsuche
Das jährliche CVPR wird vom 18. bis 22. Juni in Vancouver, Kanada, offiziell eröffnet.
Jedes Jahr kommen Tausende von CV-Forschern und Ingenieuren aus der ganzen Welt zum Summit zusammen. Diese prestigeträchtige Konferenz geht auf das Jahr 1983 zurück und stellt den Höhepunkt der Computer-Vision-Entwicklung dar.
Derzeit liegt der h5-Index des CVPR unter allen Konferenzen oder Veröffentlichungen an vierter Stelle, nur hinter „Nature“, „Science“ und „New England Journal of Medicine“.

Vor einiger Zeit gab CVPR die Ergebnisse der Papierannahme bekannt. Laut Statistiken auf der offiziellen Website wurden insgesamt 9.155 Beiträge angenommen, 2.359 wurden angenommen und die Annahmequote betrug 25,8 %.
Darüber hinaus wurden auch 12 Gewinnerbeiträge bekannt gegeben. Was sind also die Highlights des diesjährigen CVPR? Welche Trends können wir anhand der akzeptierten Arbeiten im Lebenslaufbereich erkennen?
wird als nächstes bekannt gegeben. 
Das Startup Voxel51 hat die Liste aller angenommenen Beiträge analysiert.
Schauen wir uns zunächst ein zusammenfassendes Diagramm des Titels der Arbeit an. Die Größe jedes Wortes ist proportional zur Häufigkeit des Vorkommens im Datensatz.
Kurze Beschreibung
#🎜 🎜# - 2359 Arbeiten akzeptiert (9155 eingereichte Arbeiten)
- 2359 Arbeiten akzeptiert (9155 eingereichte Arbeiten)
- 1724 Arxiv-Papiere# 🎜🎜## 🎜🎜# - 68 Dokumente, die an andere Adressen eingereicht wurden
Autor jedes Artikels
#🎜 🎜#- Der durchschnittliche Autor eines CVPR-Papiers besteht aus etwa 5,4 Personen
- Die meisten Autoren unter den Papieren sind: „Warum ist der Gewinner.“ das Beste?" Es gibt 125 Autoren
- 13 Artikel haben nur einen Autor.
Hauptkategorie von Arxiv
Unter 1724 Arxiv-Papieren gibt es 1545 Arbeiten oder fast 90 % der Arbeiten, wobei cs.CV als Hauptkategorie aufgeführt ist.
cs.LG belegte mit 101 Artikeln den zweiten Platz. Auch eess.IV (26) und cs.RO (16) erhalten einen Anteil am Kuchen.
Zu den weiteren Kategorien von CVPR-Papieren gehören: cs.HC, cs.CV, cs.AR, cs.DC, cs.NE, cs.SD, cs.CL , cs.IT, cs.CR, cs.AI, cs.MM, cs.GR, eess.SP, eess.AS, math.OC, math.NT,physics.data-an und stat.ML.
「 Metadaten zwei Wörter „Modell“ tauchten zusammen in 567 Abstracts auf. „Datensatz“ erscheint allein in 265 Papierzusammenfassungen, während „Modell“ allein 613 Mal vorkommt. Nur 16,2 % der vom CVPR akzeptierten Arbeiten enthielten diese beiden Wörter nicht.
- Laut CVPR-Papierzusammenfassungen sind die beliebtesten Datensätze in diesem Jahr ImageNet (105), COCO (94), KITTI (55) und CIFAR (36).
- 28 Papiere schlugen einen neuen „Benchmark“ vor.
Abkürzungen gibt es zuhauf
Es scheint kein Akronym zu geben. Es gibt eins Kein maschinelles Lernprojekt ohne Worte. Von den 2.359 Artikeln haben 1.487 Titel mit mehreren Abkürzungen oder zusammengesetzten Wörtern in Großbuchstaben, was 63 % entspricht.
Einige dieser Akronyme sind leicht zu merken und gehen einem sogar von der Zunge:
- CLAMP: Prompt-based Contrastive Learning for Connecting Language und TierhaltungCLAMP
- PATS: Patch-Bereichstransport mit Unterteilung für lokale Merkmalsanpassung
- KREIS: Erfassung in kontextuellen Umgebungen
Einige sind viel komplizierter:
- SIEDOB: Semantische Bildbearbeitung von Objekt und Hintergrund entwirren
- FJMP: Faktorisierte gemeinsame Multi-Agent-Bewegungsvorhersage über gelernte gerichtete azyklische InteraktionsgraphenFJMP
#🎜 🎜##🎜 🎜#Einige von ihnen scheinen in ihrer Akronymkonstruktion Ideen von anderen übernommen zu haben:- SCOTCH and SODA: A Transformer Video Shadow Detection Framework (beliebte niederländische Marke Scotch & Soda)
- EXCALIBUR: Förderung und Bewertung verkörperter Erkundung (Ex-Curry-Stick, lachen)
#🎜🎜 #Was ist das heißeste?
Zusätzlich zu den Papiertiteln für 2023 haben wir alle akzeptierten Papiertitel für 2022 gecrawlt. Aus diesen beiden Listen haben wir die relative Häufigkeit verschiedener Schlüsselwörter berechnet, um Ihnen ein tieferes Verständnis dafür zu vermitteln, was ein Aufwärtstrend und was ein Abwärtstrend ist.
Modell
Im Jahr 2023 dominieren Diffusionsmodelle (Diffusionsmodelle).
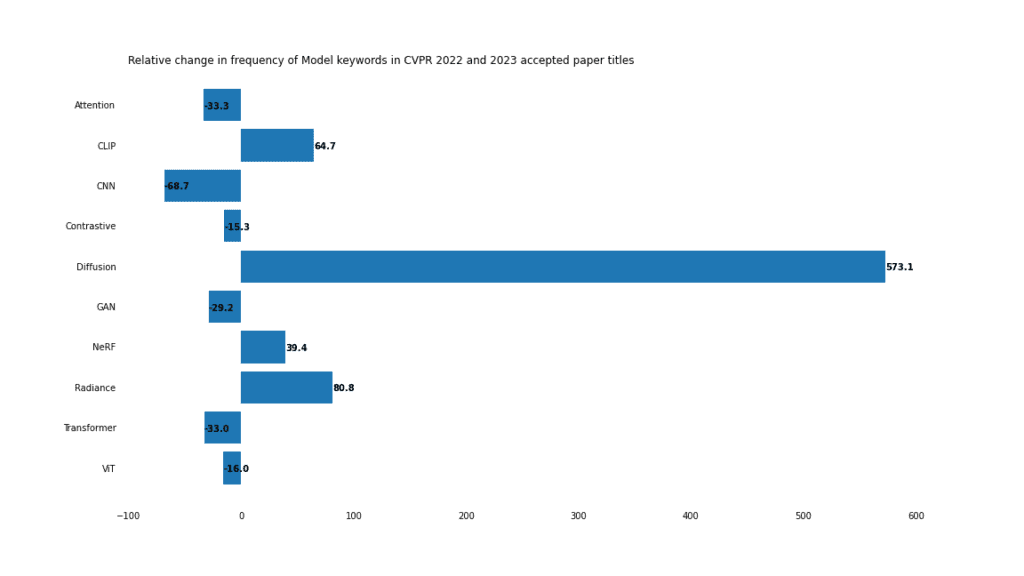
#🎜 🎜# Angesichts der Beliebtheit von Bilderzeugungsmodellen wie Stable Diffusion und Midjourney ist es nicht verwunderlich, dass die Entwicklung von Diffusionsmodellen ein heißer Trend ist.
Diffusionsmodelle finden auch Anwendung bei der Rauschunterdrückung, Bildbearbeitung und Stilübertragung. Alles in allem ist es mit einem Plus von 573 % im Vergleich zum Vorjahr der mit Abstand größte Gewinner in allen Kategorien.
Strahlungsfeld
Das neurale Strahlungsfeld (NERF) ist wird auch immer besser Es ist immer beliebter geworden, wobei die Verwendung des Wortes „Strahlung“ in Zeitungen um 80 % und „NERF“ um 39 % zugenommen hat. NeRF ist vom Proof of Concept zur Optimierung von Bearbeitungs-, Anwendungs- und Schulungsprozessen übergegangen.
Transformers
Verwendung von „Transformer“ und „ViT“ Der Ratenrückgang bedeutet nicht, dass Transformer-Modelle veraltet sind, sondern spiegelt vielmehr die Dominanz dieser Modelle im Jahr 2022 wider. Im Jahr 2021 tauchte das Wort „Transformer“ nur in 37 Artikeln auf. Im Jahr 2022 wird diese Zahl auf 201 ansteigen. Transformers werden so schnell nicht verschwinden.
CNN
CNN war einst der Liebling des Computer Vision. Im Jahr 2023 scheinen sie ihren Vorsprung verloren zu haben, da die Nutzung um 68 % zurückgeht. In vielen Schlagzeilen, in denen CNN erwähnt wird, werden auch andere Modelle erwähnt. In diesen Artikeln werden beispielsweise CNN und Transformer erwähnt:
- Gelernte Bildkomprimierung mit gemischten Transformer-CNN-Architekturen
Aufgabe#🎜🎜 #
Die Kombination aus Maskierungsaufgaben und maskierter Bildmodellierung hat CVPR dominiert.
generieren
# 🎜🎜#Traditionelle Unterscheidungsaufgaben wie Erkennung, Klassifizierung und Segmentierung sind nicht in Ungnade gefallen, aber ihr Anteil am Lebenslauf schrumpft aufgrund einer Reihe von Fortschritten bei generativen Anwendungen, einschließlich der Zunahme von „Bearbeitung“, „Synthese“ und „Generierung“. ". Das.
Maske
Das Schlüsselwort „Maske“ ist im Vergleich zum Vorjahreszeitraum um 263 % gestiegen und erscheint im Jahr 2023 92 Mal in angenommenen Arbeiten, manchmal sogar 2 Mal in einem Titel.
- SIM: Semantikbewusste Instanzmaskengenerierung für Box-Supervised-Instance-SegmentierungSIM
- DynaMask: Dynamische Maskenauswahl für InstanzsegmentierungDynaMask
Aber die Mehrheit (64 %) bezieht sich tatsächlich auf „Masken“-Codierung "Aufgaben, darunter 8 „Mask Image Modeling“- und 15 „Mask Autoencoder“-Aufgaben. Darüber hinaus kommt „Maske“ in 8 Artikeln vor.
Bemerkenswert ist auch, dass sich die drei Papiertitel mit dem Wort „Maske“ tatsächlich auf die Aufgabe „keine Maske“ beziehen.
Zero-Shot vs. Small-Shot
Mit dem Aufkommen von Transferlernen, generativen Methoden, Hinweisen und allgemeinen Modellen gewinnt das „Zero-Shot“-Lernen an Bedeutung. Gleichzeitig ist das Lernen bei „kleinen Stichproben“ im Vergleich zum letzten Jahr zurückgegangen. Rein zahlenmäßig hat die „kleine Stichprobe“ (45) jedoch zumindest vorerst einen leichten Vorteil gegenüber der „Nullstichprobe“ (35).
Modal
Im Jahr 2023 wird sich die Entwicklung multimodaler und modalübergreifender Anwendungen beschleunigen.
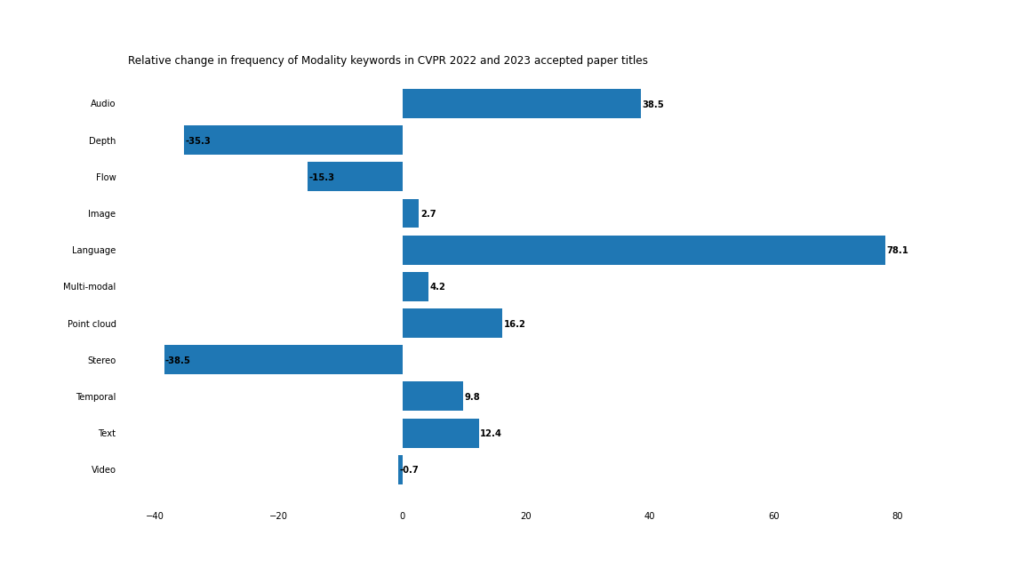
Verschwommene Grenzen
Während die Häufigkeit traditioneller Computer-Vision-Schlüsselwörter wie „Bild“ und „Video“ relativ unverändert bleibt, treten „Text“/„Sprache“ und „Audio“ auf häufiger.
Auch wenn das Wort „multimodal“ selbst nicht im Titel des Papiers vorkommt, lässt sich kaum leugnen, dass Computer Vision auf eine multimodale Zukunft zusteuert.
Dies zeigt sich besonders deutlich bei visuell-verbalen Aufgaben, wie der starke Anstieg von Offenheit, Schnelligkeit und Wortschatz zeigt.
Das extremste Beispiel für diese Situation ist das zusammengesetzte Wort „offener Wortschatz“, das im Jahr 2022 nur 3 Mal vorkam, im Jahr 2023 jedoch 18 Mal.
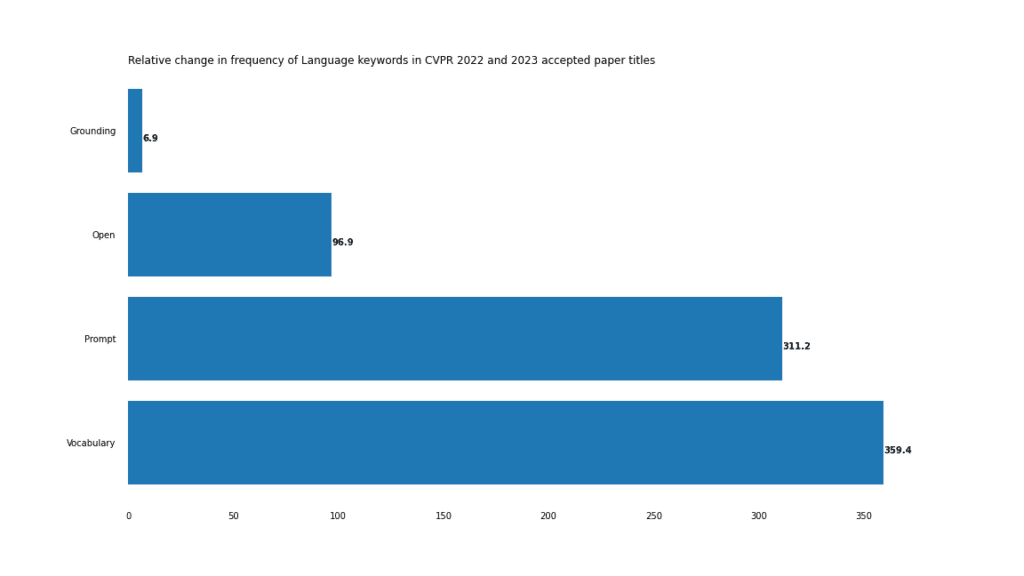
Machen Sie sich eingehend mit den Schlüsselwörtern in den Papiertiteln des CVPR 2023 vertraut.
Punktwolke 9
3D-Computer-Vision-Anwendungen leiten 3D-Informationen („Tiefe“ und „Tiefe“) ab. von 2D-Bildern „Stereoskopisch“) wandte sich Computer-Vision-Systemen zu, die direkt mit 3D-Punktwolkendaten arbeiten.
Kreativität mit Lebenslauftiteln
Jede umfassende Berichterstattung über Themen im Zusammenhang mit maschinellem Lernen im Jahr 2023 wäre unvollständig, ohne ChatGPT in den Mix einzubeziehen. Wir haben beschlossen, die Dinge interessant zu halten und haben ChatGPT verwendet, um die kreativsten Schlagzeilen vom CVPR 2023 zu finden.
Für jedes auf Arxiv hochgeladene Papier haben wir die Zusammenfassung gekratzt und ChatGPT (GPT-3.5 API) gebeten, einen Titel für das entsprechende CVPR-Papier zu generieren.
Dann nehmen wir diese von ChatGPT generierten Titel und die tatsächlichen Papiertitel, generieren Einbettungsvektoren mithilfe des Text-Embedding-ada-002-Modells von OpenAI und berechnen den Kosinus zwischen den von ChatGPT generierten Titeln und den vom Autor generierten Titeln. Ähnlichkeit .
Was kann uns das sagen? Je näher ChatGPT am tatsächlichen Papiertitel liegt, desto vorhersehbarer ist der Titel. Mit anderen Worten: Je „voreingenommener“ die Vorhersagen von ChatGPT sind, desto „kreativer“ ist der Autor bei der Benennung des Artikels.
Einbettung und Kosinusähnlichkeit bieten uns eine interessante, wenn auch alles andere als perfekte Methode zur Quantifizierung.
Wir haben die Papiere nach dieser Metrik sortiert. Hier sind ohne Umschweife die kreativsten Titel:
Tatsächlicher Titel: Tracking Every Thing in the Wild
Voraussichtlicher Titel: Disentangling Classification from Tracking: Introducing TETA for Comprehensive Benchmarking of Multi-Category Multiple Object Tracking
Aktueller Titel: Bootstrap lernen zur Bekämpfung von Label-Rauschen
Voraussichtlicher Titel: Lernbares Verlustziel für gemeinsame Instanz- und Label-Neugewichtung in tiefen neuronalen Netzen
Tatsächlicher Titel: Seeing a Rose in Five Thousand Ways
Vorhergesagter Titel: Erlernen von Objektintrinsiken aus einzelnen Internetbildern für überlegene visuelle Darstellung und Synthese.
Tatsächlicher Titel: Warum ist der Gewinner der Beste? eine multizentrische Studie von IEEE ISBI und MICCAI 2021
Das obige ist der detaillierte Inhalt vonZusammenfassung des CVPR 2023-Papiers! Der heißeste CV-Bereich wird an multimodale und Diffusionsmodelle vergeben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr