
Heim >Technologie-Peripheriegeräte >KI >Beschreiben Sie kurz die fünf Arten von Beschleunigern für maschinelles Lernen
Beschreiben Sie kurz die fünf Arten von Beschleunigern für maschinelles Lernen

- 王林nach vorne
- 2023-05-25 14:55:251712Durchsuche
Übersetzer |. Bugatti
Rezensent |. Die letzten zehn Jahre waren die Ära des tiefen Lernens. Wir freuen uns auf eine Reihe großer Ereignisse, von AlphaGo bis zum DELL-E 2. Unzählige Produkte oder Dienstleistungen, die auf künstlicher Intelligenz (KI) basieren, sind im täglichen Leben aufgetaucht, darunter Alexa-Geräte, Werbeempfehlungen, Lagerroboter und selbstfahrende Autos.
 In den letzten Jahren ist die Größe von Deep-Learning-Modellen exponentiell gewachsen. Das ist keine Neuigkeit: Das Wu Dao 2.0-Modell enthält 1,75 Billionen Parameter und das Training von GPT-3 auf 240 ml.p4d.24xlarge-Instanzen in der SageMaker-Trainingsplattform dauert nur etwa 25 Tage.
In den letzten Jahren ist die Größe von Deep-Learning-Modellen exponentiell gewachsen. Das ist keine Neuigkeit: Das Wu Dao 2.0-Modell enthält 1,75 Billionen Parameter und das Training von GPT-3 auf 240 ml.p4d.24xlarge-Instanzen in der SageMaker-Trainingsplattform dauert nur etwa 25 Tage.
Aber mit der Weiterentwicklung der Deep-Learning-Schulung und -Einführung wird es immer anspruchsvoller. Da sich Deep-Learning-Modelle weiterentwickeln, sind Skalierbarkeit und Effizienz zwei große Herausforderungen bei Schulung und Bereitstellung.
In diesem Artikel werden die fünf wichtigsten Arten von Beschleunigern für maschinelles Lernen (ML) zusammengefasst.
Verstehen Sie den ML-Lebenszyklus in der KI-Technik.
Bevor Sie ML-Beschleuniger umfassend einführen, sollten Sie sich auch den ML-Lebenszyklus ansehen.
ML-Lebenszyklus ist der Lebenszyklus von Daten und Modellen. Man kann sagen, dass Daten die Wurzel von ML sind und die Qualität des Modells bestimmen. Jeder Aspekt des Lebenszyklus bietet Möglichkeiten zur Beschleunigung.
MLOps kann den Prozess der ML-Modellbereitstellung automatisieren. Aufgrund seines operativen Charakters ist es jedoch auf den horizontalen Prozess des KI-Workflows beschränkt und kann Schulung und Einsatz nicht grundlegend verbessern.
KI-Engineering geht weit über den Rahmen von MLOps hinaus. Es kann den Workflow-Prozess für maschinelles Lernen sowie die Trainings- und Bereitstellungsarchitektur als Ganzes (horizontal und vertikal) entwerfen. Darüber hinaus beschleunigt es die Bereitstellung und Schulung durch effiziente Orchestrierung des gesamten ML-Lebenszyklus.
Basierend auf dem ganzheitlichen ML-Lebenszyklus und der KI-Technik gibt es fünf Haupttypen von ML-Beschleunigern (oder Beschleunigungsaspekten): Hardwarebeschleuniger, KI-Computing-Plattformen, KI-Frameworks, ML-Compiler und Cloud-Dienste. Schauen Sie sich zunächst das Beziehungsdiagramm unten an.
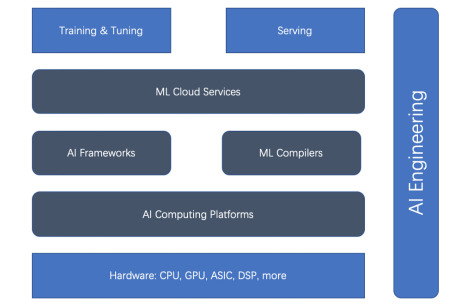 Abbildung 1. Die Beziehung zwischen Training und Bereitstellungsbeschleuniger
Abbildung 1. Die Beziehung zwischen Training und Bereitstellungsbeschleuniger
Wir können sehen, dass Hardwarebeschleuniger und KI-Frameworks der Hauptstrom der Beschleunigung sind. Doch in letzter Zeit haben ML-Compiler, KI-Computing-Plattformen und ML-Cloud-Dienste immer mehr an Bedeutung gewonnen.
Nachfolgend einzeln vorgestellt.
1. KI-Framework
Wenn es um die Beschleunigung des ML-Trainings und -Einsatzes geht, kommt die Wahl des richtigen KI-Frameworks nicht umhin. Leider gibt es kein einheitliches, perfektes oder optimales KI-Framework. Drei in Forschung und Produktion weit verbreitete KI-Frameworks sind TensorFlow, PyTorch und JAX. Sie zeichnen sich jeweils durch unterschiedliche Aspekte aus, beispielsweise Benutzerfreundlichkeit, Produktreife und Skalierbarkeit.
TensorFlow:TensorFlow ist das Flaggschiff-KI-Framework. TensorFlow hat die Deep-Learning-Open-Source-Community von Anfang an dominiert. TensorFlow Serving ist eine klar definierte und ausgereifte Plattform. Für das Internet und IoT sind auch TensorFlow.js und TensorFlow Lite ausgereift.
Aber aufgrund der Einschränkungen bei der frühen Erforschung von Deep Learning wurde TensorFlow 1.x so konzipiert, dass statische Diagramme auf nicht-pythonische Weise erstellt werden. Dies stellt ein Hindernis für eine sofortige Evaluierung im „Eager“-Modus dar, der es PyTorch ermöglicht, sich im Forschungsbereich schnell zu verbessern. TensorFlow 2.x versucht aufzuholen, aber leider ist das Upgrade von TensorFlow 1.x auf 2.x umständlich. TensorFlow führt außerdem Keras ein, um die Verwendung insgesamt zu vereinfachen, und XLA (Accelerated Linear Algebra), einen optimierenden Compiler, um die unterste Ebene zu beschleunigen.
PyTorch:Mit seinem Eager-Modus und dem Python-ähnlichen Ansatz ist PyTorch heute ein Arbeitstier in der Deep-Learning-Community und wird in allen Bereichen von der Forschung bis zur Produktion eingesetzt. Neben TorchServe lässt sich PyTorch auch in Framework-unabhängige Plattformen wie Kubeflow integrieren. Darüber hinaus ist die Popularität von PyTorch untrennbar mit dem Erfolg der Transformers-Bibliothek von Hugging Face verbunden.
JAX: Google hat JAX eingeführt, basierend auf gerätebeschleunigtem NumPy und JIT. Genau wie PyTorch vor einigen Jahren handelt es sich um ein eher natives Deep-Learning-Framework, das in der Forschungsgemeinschaft schnell an Popularität gewinnt. Es handelt sich aber noch nicht um ein „offizielles“ Google-Produkt, wie Google behauptet.
2. HardwarebeschleunigerEs besteht kein Zweifel, dass die GPU von NVIDIA das Deep-Learning-Training beschleunigen kann, aber sie wurde ursprünglich für Grafikkarten entwickelt.
Nach dem Aufkommen von Allzweck-GPUs erfreuen sich Grafikkarten, die für das Training neuronaler Netze verwendet werden, großer Beliebtheit. Diese Allzweck-GPUs können beliebigen Code ausführen und nicht nur Unterroutinen rendern. Die Programmiersprache CUDA von NVIDIA bietet eine Möglichkeit, beliebigen Code in einer C-ähnlichen Sprache zu schreiben. Die Allzweck-GPU verfügt über ein relativ praktisches Programmiermodell, einen umfassenden Parallelitätsmechanismus und eine hohe Speicherbandbreite und bietet jetzt eine ideale Plattform für die Programmierung neuronaler Netzwerke.
Heute unterstützt NVIDIA eine Reihe von GPUs, von Desktops bis hin zu Mobilgeräten, Workstations, mobilen Workstations, Spielekonsolen und Rechenzentren.
Angesichts des großen Erfolgs der NVIDIA-GPU gab es im Laufe der Zeit keinen Mangel an Nachfolgern, wie etwa der GPU von AMD und dem TPU-ASIC von Google.
3. AI Computing Platform
Wie bereits erwähnt, hängt die Geschwindigkeit des ML-Trainings und der Bereitstellung stark von der Hardware (wie GPU und TPU) ab. Diese Treiberplattformen (d. h. KI-Computing-Plattformen) sind entscheidend für die Leistung. Es gibt zwei bekannte KI-Computing-Plattformen: CUDA und OpenCL.
CUDA: CUDA (Compute Unified Device Architecture) ist ein paralleles Programmierparadigma, das 2007 von NVIDIA veröffentlicht wurde. Es ist für zahlreiche allgemeine Anwendungen auf Grafikprozessoren und GPUs konzipiert. CUDA ist eine proprietäre API, die nur NVIDIAs GPUs mit Tesla-Architektur unterstützt. Zu den von CUDA unterstützten Grafikkarten gehören die GeForce 8-Serie, Tesla und Quadro.
OpenCL: OpenCL (Open Computing Language) wurde ursprünglich von Apple entwickelt und wird jetzt vom Khronos-Team für heterogenes Computing, einschließlich CPUs, GPUs, DSPs und andere Arten von Prozessoren, gepflegt. Diese portable Sprache ist anpassungsfähig genug, um eine hohe Leistung auf jeder Hardwareplattform, einschließlich Nvidias GPUs, zu ermöglichen.
NVIDIA ist jetzt OpenCL 3.0-kompatibel für die Verwendung mit R465- und höheren Treibern. Mit der OpenCL-API kann man Rechenkerne starten, die in einer begrenzten Teilmenge der Programmiersprache C geschrieben sind, auf der GPU.
4. ML-Compiler
Der ML-Compiler spielt eine wichtige Rolle bei der Beschleunigung von Training und Bereitstellung. ML-Compiler können die Effizienz der groß angelegten Modellbereitstellung erheblich verbessern. Es gibt viele beliebte Compiler wie Apache TVM, LLVM, Google MLIR, TensorFlow XLA, Meta Glow, PyTorch nvFuser und Intel PlaidML.
5. ML Cloud Services
ML-Cloud-Plattform und -Dienste verwalten die ML-Plattform in der Cloud. Sie können auf verschiedene Arten optimiert werden, um die Effizienz zu steigern.
Nehmen Sie Amazon SageMaker als Beispiel. Dies ist ein führender ML-Cloud-Plattformdienst. SageMaker bietet eine breite Palette von Funktionen für den ML-Lebenszyklus: von der Vorbereitung, Erstellung, Schulung/Optimierung bis hin zur Bereitstellung/Verwaltung.
Es optimiert viele Aspekte, um die Trainings- und Bereitstellungseffizienz zu verbessern, wie z. B. Endpunkte mit mehreren Modellen auf der GPU, kostengünstiges Training mit heterogenen Clustern und einen proprietären Graviton-Prozessor, der für CPU-basierte ML-Inferenz geeignet ist.
Fazit
Da der Umfang der Deep-Learning-Schulung und -Bereitstellung immer weiter zunimmt, werden die Herausforderungen immer größer. Die Verbesserung der Effizienz von Deep-Learning-Training und -Einsatz ist komplex. Basierend auf dem ML-Lebenszyklus gibt es fünf Aspekte, die das ML-Training und die Bereitstellung beschleunigen können: KI-Framework, Hardwarebeschleuniger, Computerplattform, ML-Compiler und Cloud-Service. KI-Engineering kann all dies koordinieren und technische Prinzipien nutzen, um die Effizienz auf breiter Front zu verbessern.
Originaltitel: 5 Arten von ML-Beschleunigern, Autor: Luhui Hu
Das obige ist der detaillierte Inhalt vonBeschreiben Sie kurz die fünf Arten von Beschleunigern für maschinelles Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr