
Heim >Technologie-Peripheriegeräte >KI >Kombinieren Sie regelbasierte und maschinelle Lernansätze, um leistungsstarke Hybridsysteme aufzubauen
Kombinieren Sie regelbasierte und maschinelle Lernansätze, um leistungsstarke Hybridsysteme aufzubauen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-25 09:04:05921Durchsuche
Nach all den Jahren sind wir alle davon überzeugt, dass ML fast überall, wenn nicht sogar besser, zumindest mit Vor-ML-Lösungen mithalten kann. Beispielsweise werden wir alle bei einigen Regelbeschränkungen darüber nachdenken, ob sie durch ein baumbasiertes ML-Modell ersetzt werden können. Aber die Welt ist nicht immer schwarz und weiß, und obwohl maschinelles Lernen sicherlich seinen Platz bei der Lösung von Problemen hat, ist es nicht immer die beste Lösung. Regelbasierte Systeme können maschinelles Lernen sogar übertreffen, insbesondere in Bereichen, in denen Erklärbarkeit, Robustheit und Transparenz von entscheidender Bedeutung sind.
In diesem Artikel werde ich einige praktische Fälle vorstellen und wie die Kombination manueller Regeln und ML unsere Lösung verbessert.
Regelbasiertes System
Ein regelbasiertes System unterstützt die Entscheidungsfindung durch vordefinierte Regeln. Das System wertet Daten basierend auf gespeicherten Regeln aus und führt spezifische Operationen basierend auf Zuordnungen aus.
Hier ein paar Beispiele:
Betrugserkennung: Bei der Betrugserkennung können regelbasierte Systeme eingesetzt werden, um verdächtige Transaktionen anhand vordefinierter Regeln schnell zu erkennen und zu untersuchen.
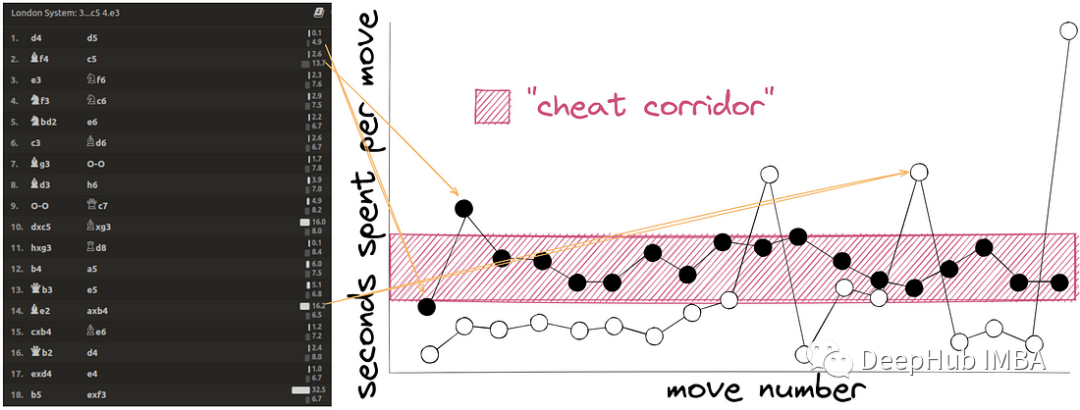
Bei Schach-Cheats besteht die grundlegende Methode darin, eine Computer-Schachanwendung in einem anderen Fenster zu installieren und das Programm zum Schachspielen zu verwenden. Egal wie komplex das Programm ist, es dauert 4-5 Sekunden. Daher wird ein „Schwellenwert“ hinzugefügt, um die Zeit jedes Schritts des Spielers zu berechnen. Wenn die Fluktuation nicht groß ist, kann er als Betrüger eingestuft werden, wie in der folgenden Abbildung dargestellt:
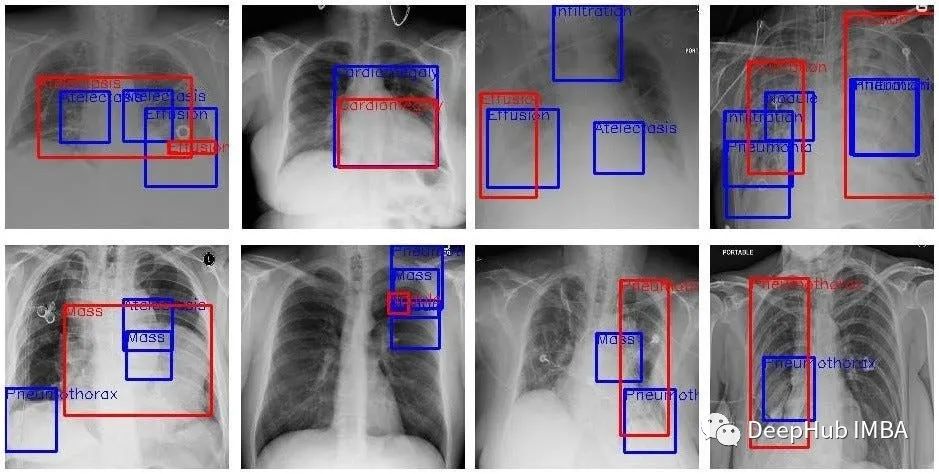
Gesundheitsbranche : Mit regelbasierten Systemen lassen sich Rezepte verwalten und Medikationsfehler verhindern. Sie können auch sehr nützlich sein, um Ärzten dabei zu helfen, Patienten auf der Grundlage früherer Ergebnisse zusätzliche Analysen zu verschreiben.
Supply Chain Management: Im Supply Chain Management können regelbasierte Systeme verwendet werden, um Warnungen bei niedrigen Lagerbeständen zu generieren und bei der Verwaltung von Ablaufdaten oder bei der Einführung neuer Produkte zu helfen.
Auf maschinellem Lernen basierende Systeme
Systeme auf maschinellem Lernen (ML) nutzen Algorithmen, um aus Daten zu lernen und Vorhersagen zu treffen oder Maßnahmen zu ergreifen, ohne dass sie explizit programmiert werden müssen. Maschinelle Lernsysteme nutzen das durch Training an großen Datenmengen gewonnene Wissen, um Vorhersagen und Entscheidungen über neue Daten zu treffen. ML-Algorithmen können ihre Leistung verbessern, da mehr Daten für das Training verwendet werden. Maschinelle Lernsysteme umfassen die Verarbeitung natürlicher Sprache, Bild- und Spracherkennung, prädiktive Analysen und mehr.
Betrugserkennung: Banken können maschinelle Lernsysteme nutzen, um aus vergangenen betrügerischen Transaktionen zu lernen und potenzielle betrügerische Aktivitäten in Echtzeit zu erkennen. Oder es könnte das System zurückentwickeln und nach Transaktionen suchen, die sehr „unnormal“ aussehen.
Gesundheitswesen: Krankenhäuser können ML-Systeme verwenden, um Patientendaten zu analysieren und anhand bestimmter Röntgenbilder die Wahrscheinlichkeit eines Patienten, eine bestimmte Krankheit zu entwickeln, vorherzusagen.
Vergleich
Sowohl regelbasierte Systeme als auch ML-Systeme haben ihre eigenen Vor- und Nachteile
Die Vorteile regelbasierter Systeme liegen auf der Hand:
- Einfach zu verstehen und zu erklären
- Schnell umzusetzen
- Einfach zu ändern
- Robust
Nachteile:
- Probleme mit vielen Variablen
- Probleme mit vielen Einschränkungen
- Begrenzt auf bestehende Regeln
Die Vorteile ML-basierter Systeme liegen ebenfalls auf der Hand
- Autonom lernendes System
- Die Fähigkeit, komplexere Probleme zu lösen
- Reduzierter menschlicher Eingriff und verbesserte Effizienz im Vergleich zu regelbasierten Systemen
- Flexible Anpassung an Änderungen in Daten und Umgebung durch kontinuierliches Lernen
Nachteile:
- Erforderliche Daten, Manchmal ist vieles
- auf die Daten-ML beschränkt, die wir zuvor gesehen haben
- Begrenzte kognitive Fähigkeit
Durch Vergleich haben wir festgestellt, dass die Vor- und Nachteile der beiden Systeme nicht im Widerspruch stehen und sich ergänzen. Gibt es also einen Weg? um sie zu kombinieren? Wie kann man ihre Vorteile kombinieren?
Hybride Systeme
Hybride Systeme, die regelbasierte Systeme und maschinelle Lernalgorithmen kombinieren, erfreuen sich in letzter Zeit immer größerer Beliebtheit. Sie können insbesondere bei der Bearbeitung komplexer Probleme robustere, genauere und effizientere Ergebnisse liefern.
Werfen wir einen Blick auf ein Hybridsystem, das mithilfe des Mietdatensatzes implementiert werden kann:
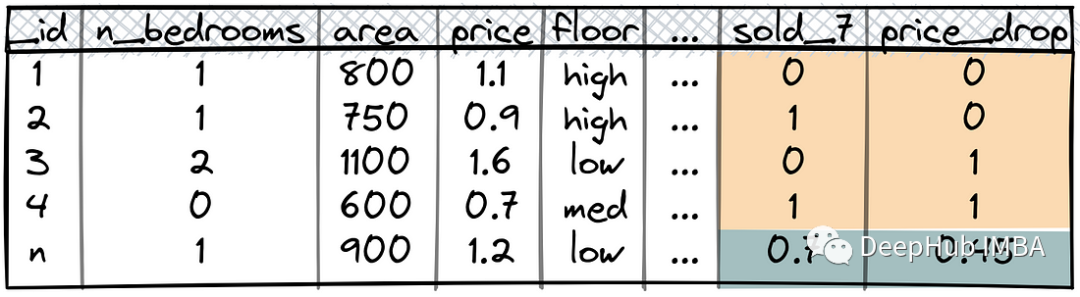
Feature Engineering: Wandeln Sie Böden in eine von drei Kategorien um: hoch, mittel oder niedrig, abhängig von der Etage des Gebäudes Nummer. Dies kann die Effizienz von ML-Modellen verbessern
Fest codierte Regeln können im Rahmen des Feature-Engineering-Prozesses verwendet werden, um wichtige Features in den Eingabedaten zu identifizieren und zu extrahieren. Wenn beispielsweise die Problemdomäne klar und eindeutig ist, können die Regeln einfach und genau definiert werden und hartcodierte Regeln können verwendet werden, um neue Features zu erstellen oder vorhandene Features zu ändern, um die Leistung des maschinellen Lernmodells zu verbessern. Obwohl Hardcoding-Regeln und Feature-Engineering zwei unterschiedliche Techniken sind, können sie zusammen verwendet werden, um die Leistung von Modellen für maschinelles Lernen zu verbessern. Mit hartcodierten Regeln können neue Features erstellt oder vorhandene Features geändert werden, während Feature Engineering zum Extrahieren von Features verwendet werden kann, die durch hartcodierte Regeln nicht einfach erfasst werden können.
Nachbearbeitung: Das Endergebnis runden oder normalisieren.
Fest codierte Regeln können als Teil der Nachbearbeitungsphase verwendet werden, um die Ausgabe des maschinellen Lernmodells zu ändern. Wenn beispielsweise ein Modell für maschinelles Lernen eine Reihe von Vorhersagen ausgibt, die nicht mit einigen bekannten Regeln oder Einschränkungen übereinstimmen, können hartcodierte Regeln verwendet werden, um die Vorhersagen so zu ändern, dass sie den Regeln oder Einschränkungen entsprechen. Nachbearbeitungstechniken wie Filtern oder Glätten können die Ausgabe eines maschinellen Lernmodells verfeinern, indem sie Rauschen oder Fehler entfernen oder die Gesamtgenauigkeit von Vorhersagen verbessern. Diese Techniken sind besonders effektiv, wenn Unsicherheit in den probabilistischen Ausgabevorhersagen des maschinellen Lernmodells oder in den Eingabedaten besteht. In einigen Fällen können auch Nachbearbeitungstechniken eingesetzt werden, um die Eingabedaten mit zusätzlichen Informationen anzureichern. Wenn beispielsweise ein Modell für maschinelles Lernen auf einem begrenzten Datensatz trainiert wird, können Nachbearbeitungstechniken verwendet werden, um zusätzliche Funktionen aus externen Quellen (z. B. sozialen Medien oder Newsfeeds) zu extrahieren und so die Genauigkeit von Vorhersagen zu verbessern.
Fall
Gesundheitswesen
Werfen wir einen Blick auf die Daten zu Herzerkrankungen:
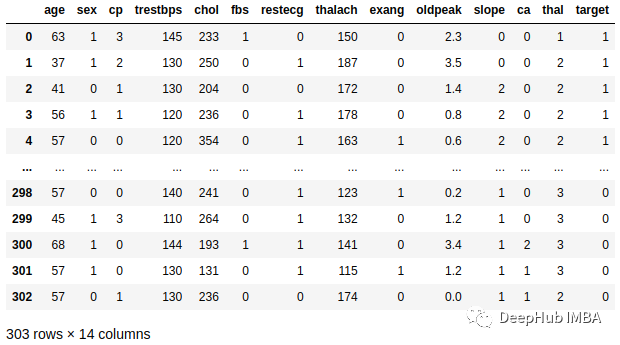
Wenn wir Random Forest verwenden, um die Zielklasse vorherzusagen:
clf = RandomForestClassifier(n_estimators=100, random_state=random_seed X_train, X_test, y_train, y_test = train_test_split( df.iloc[:, :-1], df.iloc[:, -1], test_size=0.30, random_state=random_seed ) clf.fit(X_train, y_train))
Einer der Gründe für die Wahl von Random Forest ist hier seine Build-Feature-Wichtigkeitsfunktionen. Die Bedeutung der für das Training verwendeten Funktionen können Sie unten sehen:
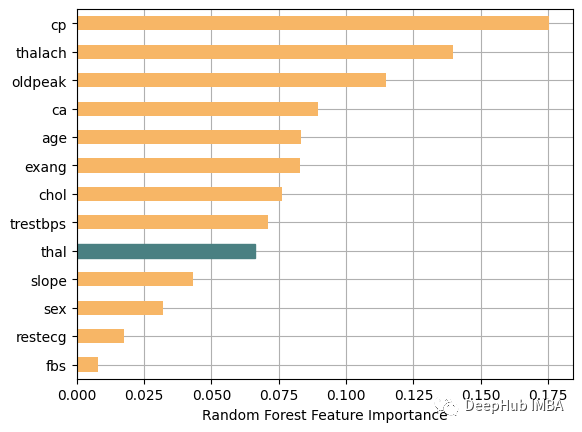
Sehen Sie sich die Ergebnisse an:
y_pred = pd.Series(clf.predict(X_test), index=y_test.index cm = confusion_matrix(y_test, y_pred, labels=clf.classes_) conf_matrix = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=clf.classes_) conf_matrix.plot())
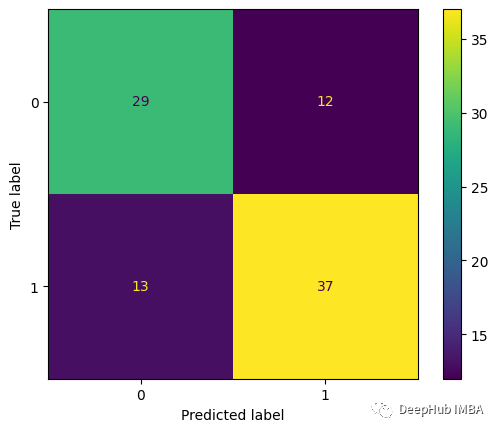
f1_score(y_test, y_pred): 0.74 recall_score(y_test, y_pred): 0.747
Dann sieht ein Kardiologe Ihr Modell. Aufgrund seiner Erfahrung und seines Fachwissens glaubt er, dass das Thalassämie-Merkmal (Thal) viel wichtiger ist als oben gezeigt. Deshalb haben wir beschlossen, ein Histogramm zu erstellen und die Ergebnisse anzusehen.
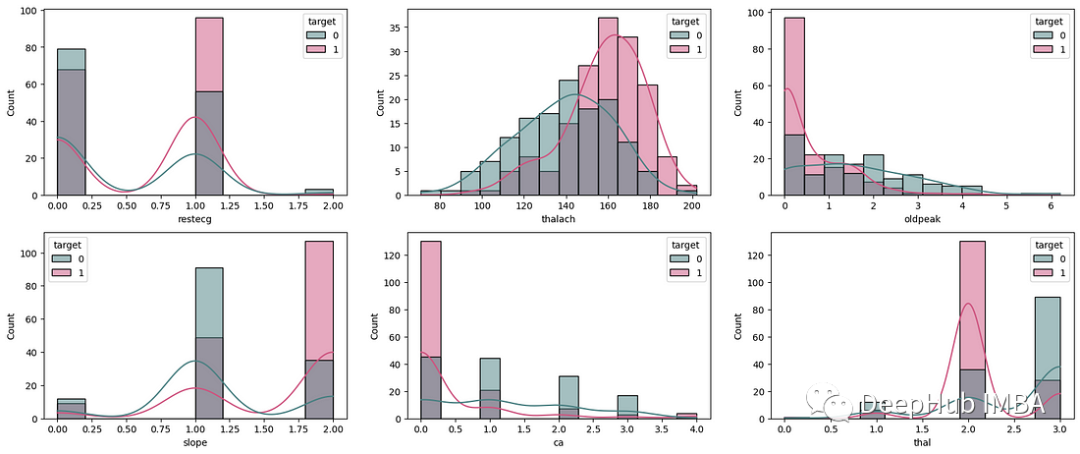
Geben Sie dann eine verbindliche Regel an
y_pred[X_test[X_test["thal"] == 2].index] = 1
Die resultierende Verwirrungsmatrix sieht folgendermaßen aus:
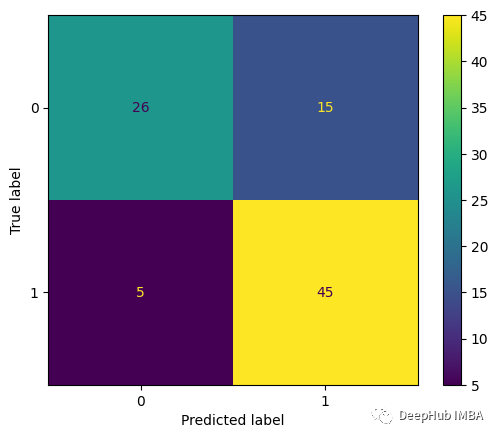
f1_score(y_test, y_pred): 0.818 recall_score(y_test, y_pred): 0.9
Das Ergebnis wurde erheblich verbessert. Hier spielt Domänenwissen eine wichtige Rolle bei der Beurteilung von Patientenscores.
Betrügerische Transaktionen
Der folgende Datensatz enthält Bankbetrugstransaktionen. Der Datensatz ist stark unausgeglichen: dient als unser Prädiktor für manuelle Regeln:
df["Class"].value_counts() 0 28431 1 4925
Wir können die Ergebnisse eines rein regelbasierten Systems und der kNN-Methode vergleichen. Der Grund für die Verwendung von kNN besteht darin, dass es unausgeglichene Daten verarbeiten kann:
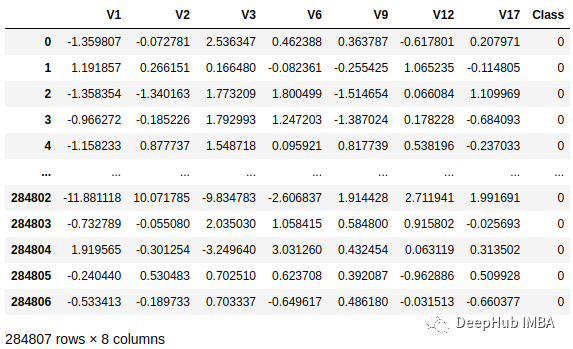
Wie wir sehen können, haben wir mit nur drei geschriebenen Regeln eine bessere Leistung als das KNN-Modell Implementierung, gute Reaktion auf Ausreißer, Robustheit und erhöhte Transparenz. Sie sind von Vorteil, wenn Geschäftslogik mit maschinellem Lernen kombiniert wird. Beispielsweise können hybride Regel-ML-Systeme im Gesundheitswesen Krankheiten diagnostizieren, indem sie klinische Regeln mit Algorithmen für maschinelles Lernen kombinieren, die Patientendaten analysieren. Maschinelles Lernen kann bei vielen Aufgaben hervorragende Ergebnisse erzielen, erfordert aber auch ergänzende Domänenkenntnisse. Domänenwissen kann Modellen des maschinellen Lernens dabei helfen, Daten besser zu verstehen und genauere Vorhersagen und Klassifizierungen vorzunehmen.
Hybridmodelle können uns helfen, Domänenwissen und Modelle für maschinelles Lernen zu kombinieren. Hybridmodelle bestehen in der Regel aus mehreren Untermodellen, die jeweils für bestimmte Domänenkenntnisse optimiert sind. Diese Untermodelle können Modelle sein, die auf fest codierten Regeln basieren, Modelle, die auf statistischen Methoden basieren, oder sogar Modelle, die auf Deep Learning basieren.
Hybridmodelle können Domänenwissen nutzen, um den Lernprozess von Modellen für maschinelles Lernen zu steuern und so die Genauigkeit und Zuverlässigkeit des Modells zu verbessern. Im medizinischen Bereich können Hybridmodelle beispielsweise das Fachwissen eines Arztes mit der Leistungsfähigkeit eines Modells für maschinelles Lernen kombinieren, um die Krankheit eines Patienten zu diagnostizieren. Im Bereich der Verarbeitung natürlicher Sprache können Hybridmodelle sprachliches Wissen und die Fähigkeiten maschineller Lernmodelle kombinieren, um natürliche Sprache besser zu verstehen und zu generieren.
Kurz gesagt können Hybridmodelle uns dabei helfen, Domänenwissen und Modelle für maschinelles Lernen zu kombinieren, wodurch die Genauigkeit und Zuverlässigkeit des Modells verbessert wird und ein breites Anwendungsspektrum bei verschiedenen Aufgaben möglich ist.
Das obige ist der detaillierte Inhalt vonKombinieren Sie regelbasierte und maschinelle Lernansätze, um leistungsstarke Hybridsysteme aufzubauen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr