
Heim >Technologie-Peripheriegeräte >KI >Meta Voice übertrifft OpenAI in Größe und Leistung doppelt und erreicht einen Meilenstein auf LLaMA-Niveau! Das Open-Source-MMS-Modell erkennt über 1100 Sprachen
Meta Voice übertrifft OpenAI in Größe und Leistung doppelt und erreicht einen Meilenstein auf LLaMA-Niveau! Das Open-Source-MMS-Modell erkennt über 1100 Sprachen

- PHPznach vorne
- 2023-05-24 16:25:061326Durchsuche
In Sachen Stimme hat Meta einen weiteren Meilenstein auf LLaMA-Niveau erreicht.
Heute startet Meta ein groß angelegtes mehrsprachiges Sprachprojekt namens MMS, das die Sprachtechnologie revolutionieren wird.
MMS unterstützt mehr als 1000 Sprachen, ist mit der Bibel trainiert und weist eine Fehlerrate auf, die nur halb so hoch ist wie die des Whisper-Datensatzes.
Mit nur einem Modell baute Meta einen Turmbau zu Babel.
Darüber hinaus hat sich Meta dafür entschieden, alle Modelle und Codes als Open Source zu veröffentlichen, in der Hoffnung, zum Schutz der Vielfalt der Weltsprachen beizutragen.

Das Vorgängermodell konnte etwa 100 Sprachen abdecken, aber dieses Mal hat MMS diese Zahl direkt um das 10- bis 40-fache erhöht!
Insbesondere hat Meta mehrsprachige Spracherkennungs-/Synthesemodelle in mehr als 1.100 Sprachen und Spracherkennungsmodelle in mehr als 4.000 Sprachen eröffnet.
Im Vergleich zu OpenAI Whisper unterstützt das mehrsprachige ASR-Modell 11-mal mehr Sprachen, aber die durchschnittliche Fehlerrate bei 54 Sprachen beträgt weniger als die Hälfte von FLEURS.
Und nach der Skalierung von ASR auf so viele Sprachen gibt es nur einen sehr geringen Leistungseinbruch.
Papieradresse: https://research.facebook.com/publications/scaling-speech-technology-to-1000-linguals/
Schützen Sie verschwindende Sprachen, MMS erhöht die Spracherkennung um das 40-fache Durch die Fähigkeit von Maschinen, Sprache zu erkennen und zu erzeugen, können mehr Menschen auf Informationen zugreifen.
Allerdings erfordert die Generierung hochwertiger maschineller Lernmodelle für diese Aufgaben riesige Mengen an gekennzeichneten Daten, wie zum Beispiel Tausende von Stunden Audio und Transkriptionen – Daten, die für die meisten Sprachen einfach nicht vorhanden sind.
Bestehende Spracherkennungsmodelle decken nur etwa 100 Sprachen ab, was nur einen kleinen Teil der mehr als 7.000 bekannten Sprachen auf dem Planeten ausmacht. Besorgniserregend ist, dass die Hälfte dieser Sprachen im Laufe unseres Lebens vom Aussterben bedroht ist.
Im Massively Multilingual Speech (MMS)-Projekt haben Forscher einige Herausforderungen gemeistert, indem sie wav2vec 2.0 (Metas Pionierarbeit im Bereich selbstüberwachtes Lernen) und einen neuen Datensatz kombiniert haben.
Dieser Datensatz bietet beschriftete Daten in mehr als 1100 Sprachen und unbeschriftete Daten in fast 4000 Sprachen.

Einige dieser Sprachen, wie Tatuyo, haben nur ein paar hundert Sprecher, während sie für die meisten Sprachen groß sind , Sprachtechnologie gab es vorher einfach nicht.
Die Ergebnisse zeigen, dass die Leistung des MMS-Modells besser ist als die des bestehenden Modells und die Anzahl der abgedeckten Sprachen zehnmal höher ist als die des bestehenden Modells.
Meta hat sich schon immer auf mehrsprachige Arbeit konzentriert: In Bezug auf Text erweiterte das NLLB-Projekt von Meta die mehrsprachige Übersetzung auf 200 Sprachen, während das MMS-Projekt die Sprachtechnologie auf weitere Sprachen erweiterte.
Die Bibel löst das Rätsel um den Sprachdatensatz
Das Sammeln von Audiodaten in Tausenden von Sprachen ist keine einfache Angelegenheit, und dies war auch die erste Herausforderung, vor der die Forscher bei Meta standen.
Sie müssen wissen, dass der größte vorhandene Sprachdatensatz höchstens 100 Sprachen abdeckt. Um dieses Problem zu lösen, haben Forscher auf religiöse Texte wie die Bibel zurückgegriffen.
Diese Art von Text wurde in viele verschiedene Sprachen übersetzt, in umfangreichen Recherchen verwendet und es wurden verschiedene öffentliche Aufnahmen gemacht.
Zu diesem Zweck haben Meta-Forscher eigens einen Datensatz zum Lesen des Neuen Testaments in mehr als 1.100 Sprachen erstellt, der durchschnittlich 32 Stunden Daten pro Sprache bereitstellt.
In Verbindung mit nicht markierten Aufzeichnungen verschiedener anderer religiöser Lesungen erhöhten die Forscher die Anzahl der verfügbaren Sprachen auf über 4.000.
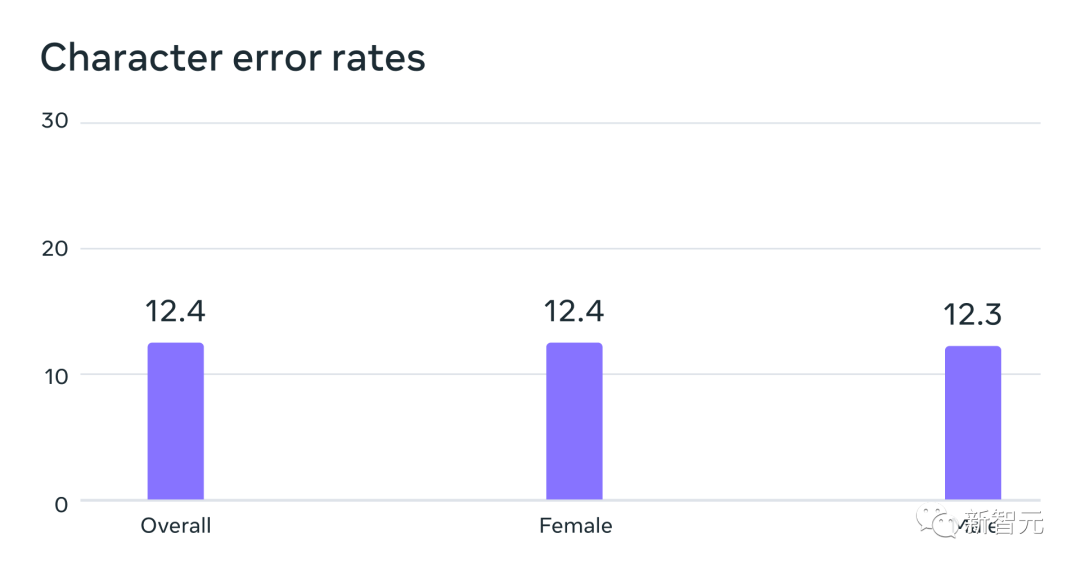
Ein automatisches Spracherkennungsmodell, das auf MMS-Daten trainiert wurde, mit ähnlichen Fehlerraten für männliche und weibliche Sprecher im FLEURS-Benchmark
Diese Daten werden normalerweise von Männern gesprochen, aber das Modell schnitt genauso gut ab auf Männer- und Frauenstimmen.
Und obwohl der Inhalt der Aufnahmen religiös war, hat dies das Modell nicht übermäßig dazu verleitet, eine religiösere Sprache zu produzieren.
Die Forscher glauben, dass dies daran liegt, dass sie eine konnektionistische zeitliche Klassifizierungsmethode verwendeten, die viel restriktiver ist als große Sprachmodelle oder Sequenz-zu-Sequenz-Modelle, die zur Spracherkennung verwendet werden.
Je größer das Modell, desto besser kann es kämpfen?
Die Forscher haben die Daten zunächst vorverarbeitet, um ihre Qualität zu verbessern und die Nutzung durch maschinelle Lernalgorithmen zu ermöglichen.
Dazu trainierten die Forscher ein Alignment-Modell auf vorhandenen Daten in mehr als 100 Sprachen und nutzten dieses Modell mit einem effizienten erzwungenen Alignment-Algorithmus, der die Aufzeichnung in etwa 20 Minuten oder mehr Zeit verarbeiten kann.
Die Forscher wiederholten diesen Vorgang mehrmals und führten einen abschließenden Kreuzvalidierungsfilterungsschritt basierend auf der Genauigkeit des Modells durch, um potenziell falsch ausgerichtete Daten zu entfernen.
Um anderen Forschern die Erstellung neuer Sprachdatensätze zu ermöglichen, haben die Forscher den Ausrichtungsalgorithmus zu PyTorch hinzugefügt und das Ausrichtungsmodell veröffentlicht.
Derzeit gibt es 32 Stunden Daten für jede Sprache, aber das reicht nicht aus, um herkömmliche Modelle zur überwachten Spracherkennung zu trainieren.
Aus diesem Grund trainieren Forscher Modelle auf wav2vec 2.0, wodurch die Menge der zum Trainieren eines Modells erforderlichen annotierten Daten erheblich reduziert werden kann.
Konkret trainierten die Forscher das selbstüberwachte Modell anhand von etwa 500.000 Stunden Sprachdaten in mehr als 1.400 Sprachen – fast fünfmal mehr als in der Vergangenheit.
Dann können Forscher das Modell für bestimmte Sprachaufgaben verfeinern, wie zum Beispiel mehrsprachige Spracherkennung oder Spracherkennung.
Um die Leistung von Modellen, die auf umfangreichen mehrsprachigen Sprachdaten trainiert wurden, besser zu verstehen, haben die Forscher sie anhand vorhandener Benchmark-Datensätze ausgewertet.
Die Forscher verwendeten ein wav2vec 2.0-Modell mit 1B-Parametern, um ein mehrsprachiges Spracherkennungsmodell für mehr als 1100 Sprachen zu trainieren.
Die Leistung nimmt zwar mit zunehmender Anzahl der Sprachen ab, aber dieser Rückgang ist mild – von 61 Sprachen auf 1107 Sprachen steigt die Zeichenfehlerrate nur um etwa 0,4 %, aber die Sprachabdeckung steigt auf mehr als 18 mal.
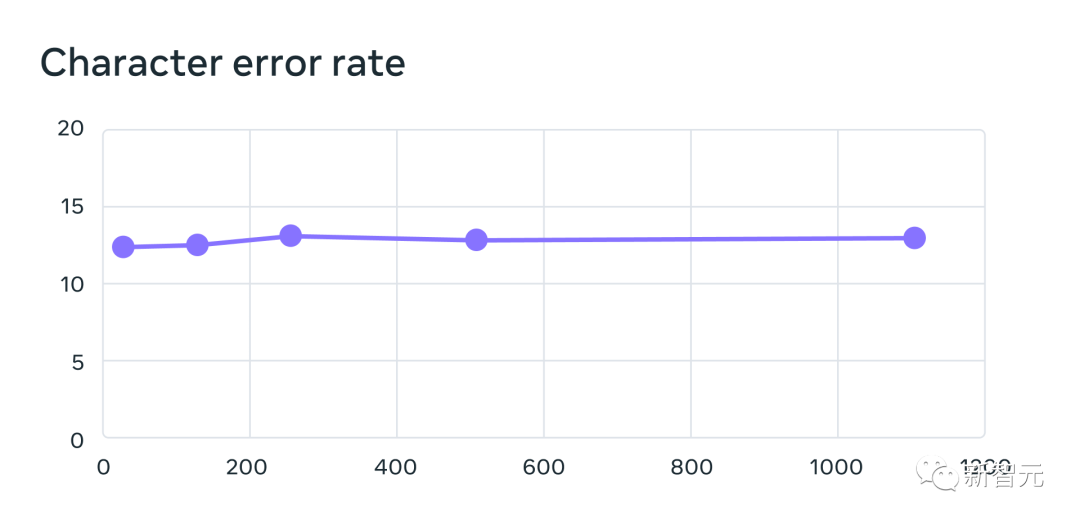
Fehlerraten für 61 FLEURS-Sprachen eines mehrsprachigen Erkennungssystems, das mithilfe von MMS-Daten trainiert wurde, wenn die Anzahl der von jedem System unterstützten Sprachen von 61 auf 1.107 erhöht wurde. Höhere Fehlerraten deuten auf eine geringere Leistung hin
In einem direkten Vergleich mit Whisper von OpenAI stellten die Forscher fest, dass Modelle, die auf Massively Multilingual Speech-Daten trainiert wurden, fast die Hälfte der Wortfehlerrate aufwiesen, Massively Multilingual Speech jedoch elfmal mehr abdeckte Sprachen als Whisper.
Anhand der Daten können wir erkennen, dass Metas Modell im Vergleich zu den aktuell besten Sprachmodellen wirklich gut abschneidet.
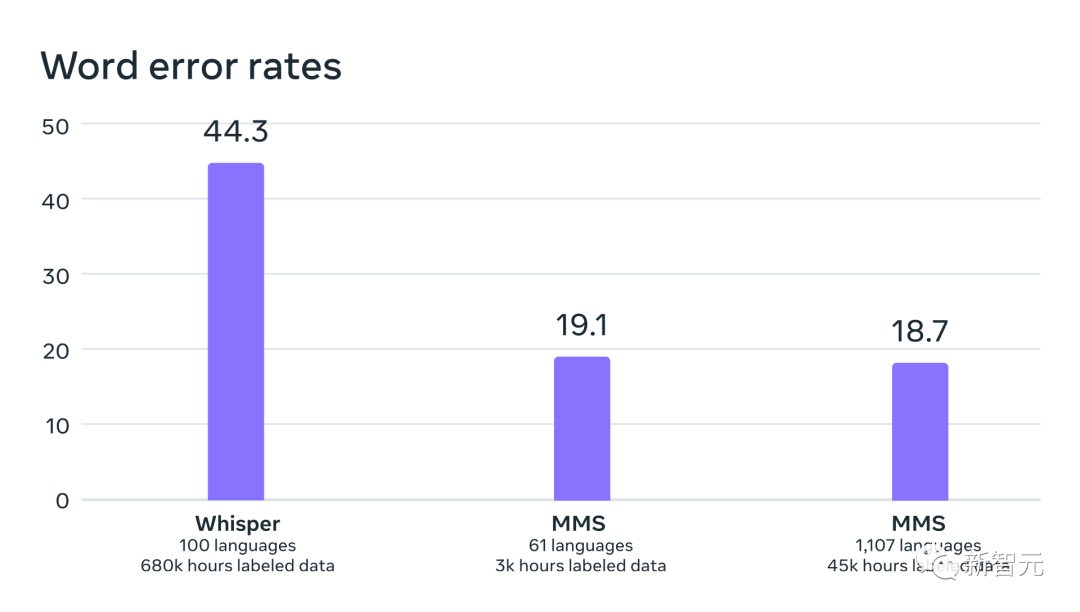
Vergleich der Wortfehlerraten zwischen OpenAI Whisper und Massively Multilingual Speech in 54 FLEURS-Sprachen
Als nächstes verwendeten die Forscher ihre eigenen sowie vorhandene Datensätze wie FLEURS und CommonVoice, um weitere Informationen zu erhalten Als Ein Spracherkennungsmodell (LID) wird auf 4000 Sprachen trainiert und anhand der FLEURS-LID-Aufgabe ausgewertet.
Fakten haben bewiesen, dass die Leistung immer noch sehr gut ist, auch wenn fast 40 Mal so viele Sprachen unterstützt werden.
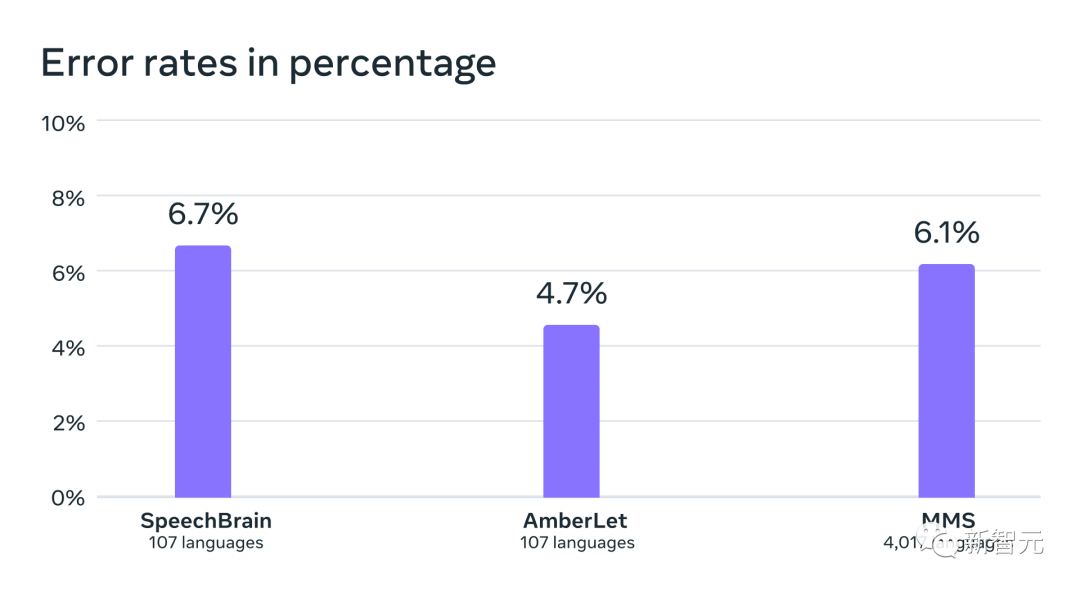
Spracherkennungsgenauigkeit auf dem VoxLingua-107-Benchmark bestehender Arbeiten, der etwas mehr als 100 Sprachen unterstützt, während MMS über 4000 Sprachen unterstützt.
Forscher haben außerdem Text-zu-Sprache-Systeme für mehr als 1.100 Sprachen entwickelt.
Eine Einschränkung umfangreicher mehrsprachiger Sprachdaten besteht darin, dass sie für viele Sprachen eine relativ kleine Anzahl verschiedener Sprecher enthalten, oft nur einen Sprecher.
Diese Funktion ist jedoch für den Aufbau von Text-to-Speech-Systemen von Vorteil, daher haben Forscher ähnliche Systeme für mehr als 1100 Sprachen trainiert.
Die Ergebnisse zeigen, dass die Sprachqualität dieser Systeme nicht schlecht ist.
Die Zukunft gehört einem einzigen Modell
Metas Forscher sind mit den Ergebnissen zufrieden, aber wie alle neuen KI-Technologien ist Metas aktuelles Modell nicht perfekt.
Zum Beispiel kann ein Speech-to-Text-Modell ausgewählte Wörter oder Phrasen falsch schreiben, was möglicherweise zu beleidigenden oder ungenauen Ausgabeergebnissen führt.
Gleichzeitig glaubt Meta, dass die Zusammenarbeit von KI-Giganten für die Entwicklung verantwortungsvoller KI-Technologie von entscheidender Bedeutung ist.
Viele Sprachen der Welt sind vom Aussterben bedroht, und die Einschränkungen der aktuellen Spracherkennungs- und Spracherzeugungstechnologie werden diesen Trend nur beschleunigen.
Forscher stellen sich eine Welt vor, in der Technologie den gegenteiligen Effekt hat und die Menschen dazu ermutigt, ihre Sprachen am Leben zu erhalten, weil sie durch das Sprechen ihrer bevorzugten Sprache auf Informationen zugreifen und Technologie nutzen können.
Das groß angelegte mehrsprachige Sprachprojekt ist ein wichtiger Schritt in diese Richtung.
In Zukunft hoffen Forscher, die Sprachabdeckung weiter zu erhöhen, mehr Sprachen zu unterstützen und sogar Wege zu finden, mit Dialekten umzugehen. Sie wissen, Dialekte sind für die bestehende Sprachtechnologie nicht einfach.
Das ultimative Ziel von Meta ist es, den Menschen den Zugriff auf Informationen und die Nutzung von Geräten in ihrer bevorzugten Sprache zu erleichtern.
Schließlich stellten sich Metaforscher auch ein Zukunftsszenario vor, in dem ein einziges Modell mehrere Sprachaufgaben in allen Sprachen lösen kann.
Obwohl Meta derzeit separate Modelle für Spracherkennung, Sprachsynthese und Spracherkennung trainiert, glauben Forscher, dass in Zukunft nur ein Modell alle diese Aufgaben und mehr erfüllen kann.
Das obige ist der detaillierte Inhalt vonMeta Voice übertrifft OpenAI in Größe und Leistung doppelt und erreicht einen Meilenstein auf LLaMA-Niveau! Das Open-Source-MMS-Modell erkennt über 1100 Sprachen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr