
Heim >Technologie-Peripheriegeräte >KI >Was ist Textklassifizierung?
Was ist Textklassifizierung?

- PHPznach vorne
- 2023-05-23 21:16:041976Durchsuche
Übersetzer |. Li Rui
Rezensent |.
Textklassifizierung ist der Prozess der Klassifizierung von Text in eine oder mehrere verschiedene Kategorien, um ihn nach beliebigen Parametern zu organisieren, zu strukturieren und zu filtern. Beispielsweise wird die Textklassifizierung in juristischen Dokumenten, medizinischen Studien und Dokumenten oder einfach in Produktrezensionen verwendet. Daten sind wichtiger denn je; viele Unternehmen geben riesige Summen aus, um möglichst viele Erkenntnisse zu gewinnen.
Da Text-/Dokumentdaten immer umfangreicher werden als andere Datentypen, ist der Einsatz neuer Methoden unerlässlich. Da Daten von Natur aus unstrukturiert und äußerst umfangreich sind, kann eine leicht verständliche Organisation, um ihnen einen Sinn zu geben, ihren Wert erheblich steigern. Nutzen Sie Textklassifizierung und maschinelles Lernen, um relevante Texte schneller und kostengünstiger automatisch zu erstellen. Im Folgenden werden die Textklassifizierung, ihre Funktionsweise und einige der bekanntesten Algorithmen definiert und Datensätze bereitgestellt, die für den Beginn Ihrer Textklassifizierungsreise nützlich sein können. Warum maschinelles Lernen zur Textklassifizierung nutzen?Skalierung: Manuelle Dateneingabe, -analyse und -organisation sind mühsam und langsam. Maschinelles Lernen ermöglicht eine automatisierte Analyse unabhängig von der Größe des Datensatzes.
- Konsistenz: Menschliches Versagen entsteht aufgrund der Ermüdung des Personals und der Unempfindlichkeit gegenüber dem Material im Datensatz. Maschinelles Lernen verbessert die Skalierbarkeit und erhöht die Genauigkeit aufgrund der unvoreingenommenen und konsistenten Natur des Algorithmus erheblich.
- Geschwindigkeit: Manchmal müssen Sie möglicherweise schnell auf Daten zugreifen und diese organisieren. Algorithmen für maschinelles Lernen können Daten analysieren und Informationen auf leicht verständliche Weise bereitstellen.
- 6 Allgemeine Schritte
Einige grundlegende Methoden können verschiedene Textdokumente bis zu einem gewissen Grad klassifizieren, aber die gebräuchlichste Methode verwendet maschinelles Lernen. Textklassifizierungsmodelle durchlaufen sechs grundlegende Schritte, bevor sie eingesetzt werden können. 
Tag-Wort: Smarter
- Tag-Unterwort: Smart-er
- Tag-Zeichen: S-m-a-r-t-e-r
- Warum ist die Tokenisierung wichtig? Denn Textklassifizierungsmodelle können Daten nur auf tokenbasierter Ebene verarbeiten und keine vollständigen Sätze verstehen und verarbeiten. Das Modell erfordert eine weitere Verarbeitung des gegebenen Rohdatensatzes, um die gegebenen Daten leicht verarbeiten zu können. Entfernen Sie unnötige Funktionen, filtern Sie Null- und Unendlichwerte heraus und vieles mehr. Durch die Neuorganisation des gesamten Datensatzes können Verzerrungen während der Trainingsphase vermieden werden.
- Word2Vec: Dies ist eine von Google entwickelte unbeaufsichtigte Methode zur Worteinbettung. Es nutzt neuronale Netze, um aus großen Textdatensätzen zu lernen. Wie der Name schon sagt, wandelt die Word2Vec-Methode jedes Wort in einen bestimmten Vektor um.
- GloVe: Auch als globaler Vektor bekannt, handelt es sich um ein unbeaufsichtigtes maschinelles Lernmodell, das zum Erhalten von Vektordarstellungen von Wörtern verwendet wird. Ähnlich wie die Word2Vec-Methode ordnet der GloVe-Algorithmus Wörter einem sinnvollen Raum zu, wobei der Abstand zwischen Wörtern mit der semantischen Ähnlichkeit zusammenhängt.
- TF-IDF: TF-IDF ist die Abkürzung für Term Frequency-Inverse Text Frequency, einem Worteinbettungsalgorithmus, der zur Bewertung der Bedeutung von Wörtern in einem bestimmten Dokument verwendet wird. TF-IDF weist jedem Wort eine bestimmte Bewertung zu, um seine Bedeutung in einer Reihe von Dokumenten darzustellen.
Textklassifizierungsalgorithmen
Im Folgenden sind drei der bekanntesten und effektivsten Textklassifizierungsalgorithmen aufgeführt. Es ist wichtig zu bedenken, dass in jede Methode weitere definierte Algorithmen eingebettet sind.
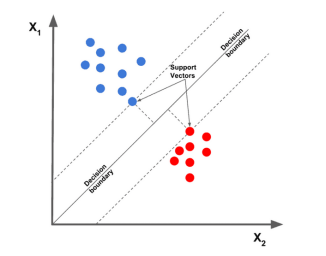
1. Linear Support Vector Machine
Der lineare Support Vector Machine-Algorithmus gilt derzeit als einer der besten Textklassifizierungsalgorithmen. Er zeichnet einen bestimmten Datenpunkt basierend auf einem bestimmten Merkmal und zeichnet dann eine am besten geeignete Linie. Teilen und klassifizieren Sie Daten in verschiedene Kategorien.
2. Logistische Regression
Logistische Regression ist eine Unterkategorie der Regression, die sich hauptsächlich auf Klassifizierungsprobleme konzentriert. Es nutzt Entscheidungsgrenzen, Regression und Distanz, um Datensätze auszuwerten und zu klassifizieren.
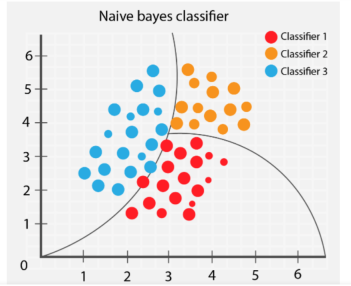
3. Naive Bayes
Der Naive Bayes-Algorithmus klassifiziert verschiedene Objekte basierend auf den von den Objekten bereitgestellten Merkmalen. Anschließend werden Gruppengrenzen gezogen, um diese Gruppenklassifizierungen zur weiteren Auflösung und Klassifizierung abzuleiten.
Welche Probleme sollten beim Einrichten der Textklassifizierung vermieden werden?
1. Überfüllte Trainingsdaten
Das Füttern des Algorithmus mit Daten geringer Qualität führt zu schlechten Zukunftsvorhersagen. Ein häufiges Problem für Praktiker des maschinellen Lernens besteht darin, dass Trainingsmodelle mit zu vielen Datensätzen gefüttert werden und unnötige Funktionen enthalten. Eine übermäßige Verwendung irrelevanter Daten führt zu einer Verschlechterung der Modellleistung. Und wenn es um die Auswahl und Organisation von Datensätzen geht, ist weniger mehr.
Ein falsches Verhältnis von Trainings- zu Testdaten kann die Leistung des Modells stark beeinträchtigen und das Mischen und Filtern von Daten beeinträchtigen. Genaue Datenpunkte werden nicht durch andere unerwünschte Faktoren beeinträchtigt und das trainierte Modell arbeitet effizienter.
Wählen Sie beim Training eines Modells einen Datensatz aus, der die Anforderungen des Modells erfüllt, filtern Sie unnötige Werte, mischen Sie den Datensatz und testen Sie die Genauigkeit des endgültigen Modells. Einfachere Algorithmen erfordern weniger Rechenzeit und Ressourcen, und die besten Modelle sind die einfachsten, die komplexe Probleme lösen können.
2. Überanpassung und Unteranpassung
Wenn das Training seinen Höhepunkt erreicht, nimmt die Genauigkeit des Modells mit fortschreitendem Training allmählich ab. Dies wird als Überanpassung bezeichnet. Da das Training zu lange dauert, beginnt das Modell, unerwartete Muster zu lernen. Seien Sie vorsichtig, wenn Sie eine hohe Genauigkeit des Trainingssatzes erreichen, da das Hauptziel darin besteht, ein Modell zu entwickeln, dessen Genauigkeit auf dem Testsatz basiert (Daten, die das Modell zuvor noch nicht gesehen hat).
Andererseits bedeutet Underfitting, dass das trainierte Modell noch Raum für Verbesserungen hat und sein maximales Potenzial noch nicht erreicht hat. Schlecht trainierte Modelle sind auf die Länge des Trainings oder eine übermäßige Regulierung des Datensatzes zurückzuführen. Dies verdeutlicht, was es bedeutet, über prägnante und präzise Daten zu verfügen.
Beim Training Ihres Modells ist es entscheidend, den Sweet Spot zu finden. Die Aufteilung des Datensatzes im Verhältnis 80/20 ist ein guter Anfang, aber die Anpassung der Parameter kann für ein bestimmtes Modell erforderlich sein, um eine optimale Leistung zu erzielen.
3. Falsches Textformat
Obwohl in diesem Artikel nicht ausführlich erwähnt, führt die Verwendung des richtigen Textformats bei Textklassifizierungsproblemen zu besseren Ergebnissen. Einige Methoden zur Darstellung von Textdaten umfassen GloVe, Word2Vec und Einbettungsmodelle.
Die Verwendung des richtigen Textformats verbessert die Art und Weise, wie das Modell den Datensatz liest und interpretiert, was ihm wiederum hilft, Muster zu verstehen.
Textklassifizierungs-App

- Spam filtern: E-Mails können durch die Suche nach bestimmten Schlüsselwörtern als nützlich oder Spam klassifiziert werden.
- Textklassifizierung: Mithilfe der Textklassifizierung kann die Anwendung verschiedene Elemente (Artikel und Bücher usw.) in verschiedene Kategorien einteilen, indem sie zugehörigen Text (z. B. Elementnamen und Beschreibungen usw.) klassifiziert. Die Verwendung dieser Techniken verbessert das Erlebnis, da sie den Benutzern die Navigation innerhalb der Datenbank erleichtert.
- Hassrede identifizieren: Einige Social-Media-Unternehmen nutzen die Textklassifizierung, um anstößige Kommentare oder Beiträge zu erkennen und zu sperren.
- Marketing und Werbung: Unternehmen können spezifische Änderungen vornehmen, um ihre Kunden zufriedenzustellen, indem sie verstehen, wie Benutzer auf bestimmte Produkte reagieren. Es kann auch bestimmte Produkte basierend auf Benutzerbewertungen ähnlicher Produkte empfehlen. Textklassifizierungsalgorithmen können in Verbindung mit Empfehlungssystemen verwendet werden, einem weiteren Deep-Learning-Algorithmus, der von vielen Online-Websites zur Gewinnung von Folgegeschäften verwendet wird.
Beliebte Textklassifizierungsdatensätze
Mit einer großen Anzahl beschrifteter und gebrauchsfertiger Datensätze können Sie jederzeit nach dem perfekten Datensatz suchen, der Ihren Modellanforderungen entspricht.
Während Sie möglicherweise Schwierigkeiten bei der Entscheidung haben, welchen Sie verwenden möchten, werden im Folgenden einige der bekanntesten Datensätze empfohlen, die der Öffentlichkeit zur Verfügung stehen.
- IMDB-Datensatz
- Amazon-Bewertungsdatensatz
- Yelp-Bewertungsdatensatz
- SMS-Spam-Sammlung
- Opin-Rank-Bewertungsdatensatz
- Twitter-Sentiment-Datensatz für US-Fluggesellschaften
- Hassreden und beleidigende Sprache-Datensatz
- Clickbait-Daten set
Kaggle usw. Die Website enthält verschiedene Datensätze zu allen Themen. Sie können zum Üben versuchen, das Modell mit mehreren der oben genannten Datensätze auszuführen.
Textklassifizierung beim maschinellen Lernen
Da maschinelles Lernen im letzten Jahrzehnt große Fortschritte gemacht hat, versuchen Unternehmen auf jede erdenkliche Weise, maschinelles Lernen zur Automatisierung von Prozessen zu nutzen. Rezensionen, Beiträge, Artikel, Zeitschriften und Dokumente sind im Text von unschätzbarem Wert. Und durch den Einsatz von Textklassifizierung auf vielfältige Weise zur Extraktion von Benutzereinblicken und -mustern können Unternehmen datengestützte Entscheidungen schneller als je zuvor treffen und wertvolle Informationen abrufen.
Originaltitel:Was ist Textklassifizierung?, Autor: Kevin Vu
Das obige ist der detaillierte Inhalt vonWas ist Textklassifizierung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr