
Heim >Technologie-Peripheriegeräte >KI >Beim Training großer Models wird auf „Energie' geachtet! Tao Dacheng leitet das Team: Alle Lösungen für „effizientes Training' werden in einem Artikel behandelt. Hören Sie auf zu sagen, dass Hardware der einzige Engpass ist
Beim Training großer Models wird auf „Energie' geachtet! Tao Dacheng leitet das Team: Alle Lösungen für „effizientes Training' werden in einem Artikel behandelt. Hören Sie auf zu sagen, dass Hardware der einzige Engpass ist

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-23 17:04:08802Durchsuche
Der Bereich Deep Learning hat erhebliche Fortschritte gemacht, insbesondere in Aspekten wie Computer Vision, Verarbeitung natürlicher Sprache und Sprache. Groß angelegte Modelle, die mithilfe von Big Data trainiert werden, haben enorme Auswirkungen auf praktische Anwendungen, verbessern die industrielle Produktivität und fördern die Aussichten für die soziale Entwicklung .
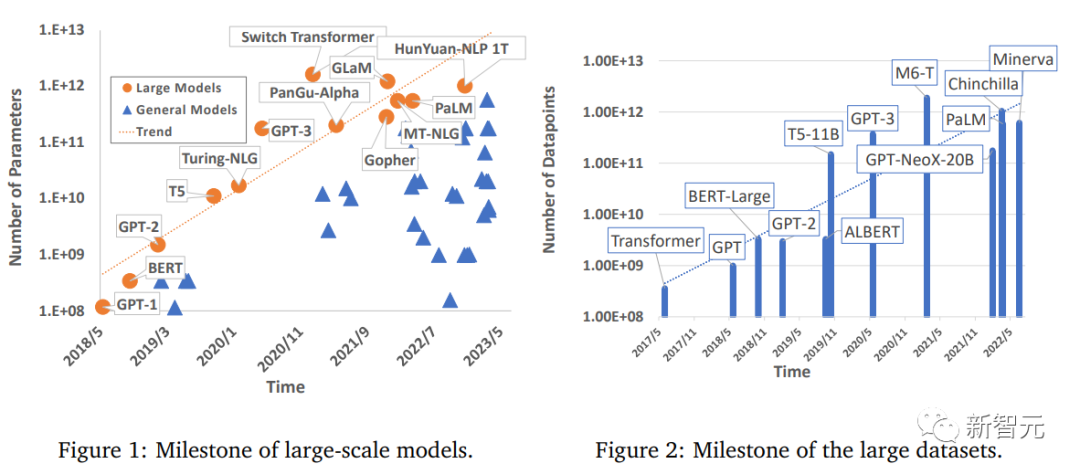
Allerdings erfordern große Modelle auch eine große Rechenleistung, um trainiert zu werden. Da die Anforderungen der Menschen an die Rechenleistung weiter steigen, gibt es zwar viele Studien, die sich mit effizienten Trainingsmethoden befassen, aber es gibt immer noch kein Deep Learning A umfassender Überblick über Modellbeschleunigungstechniken.
Kürzlich haben Forscher der University of Sydney, der University of Science and Technology of China und anderer Institutionen eine Übersicht veröffentlicht, in der effiziente Trainingstechniken für groß angelegte Deep-Learning-Modelle umfassend zusammengefasst und die gemeinsamen Mechanismen innerhalb jeder Komponente des Trainings aufgezeigt werden Verfahren .

Link zum Papier: https://arxiv.org/pdf/2304.03589.pdf
Die Forscher betrachteten die grundlegendste Formel zur Gewichtsaktualisierung und unterteilten ihre Grundkomponenten in fünf Hauptaspekte:
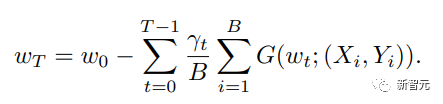
1. Datenzentriert (datenzentriert), einschließlich Datensatz-Regularisierung, Datenstichprobe und datenzentrierter Kurslerntechniken, die die rechnerische Komplexität von Stichproben erheblich reduzieren können; 2,
modellzentriert, einschließlich Beschleunigung von Grundmodulen, Komprimierungstraining, Modellinitialisierung und modellzentrierter Kurslerntechnologie, mit Schwerpunkt auf der Reduzierung von Parametern. Berechnung zur Beschleunigung des Trainings 3 die Auswahl der Lernrate, die Verwendung großer Batch-Größen, das Design effizienter Zielfunktionen, modellgewichteter Durchschnittstechnologie usw.; der Schwerpunkt liegt auf Trainingsstrategien, um die Vielseitigkeit von Großmodellen zu verbessern; Schulung
, einschließlich einiger Beschleunigungstechniken, die bei begrenzter Hardware verwendet werden;5, systemzentriert (systemzentriert)
, einschließlich einiger effizienter verteilter Frameworks und Open-Source-Bibliotheken, die ausreichende Hardwareunterstützung für die Implementierung beschleunigter Algorithmen bieten .Effizientes datenzentriertes Training
In letzter Zeit haben groß angelegte Modelle große Fortschritte gemacht, während ihre Anforderungen an Datensätze dramatisch gestiegen sind. Riesige Datenproben werden verwendet, um den Trainingsprozess voranzutreiben und eine hervorragende Leistung zu erzielen. Daher ist datenzentrierte Forschung für die tatsächliche Beschleunigung von entscheidender Bedeutung.Die Grundfunktion der Datenverarbeitung besteht darin, die Vielfalt der Datenproben effizient zu erhöhen, ohne die Kosten für die Kennzeichnung zu erhöhen. Da die Kosten für die Datenkennzeichnung oft zu hoch sind, können sich einige Entwicklungsinstitutionen diese auch nicht leisten Bedeutung der Forschung in datenzentrierten Bereichen; gleichzeitig konzentriert sich die Datenverarbeitung auch auf die Verbesserung der Effizienz des parallelen Ladens von Datenproben.
Forscher nennen all diese effiziente Datenverarbeitung einen „datenzentrierten“ Ansatz, der die Leistung beim Training groß angelegter Modelle erheblich verbessern kann.In diesem Artikel werden Technologien unter folgenden Aspekten besprochen und untersucht:
Datenregulierung
Datenregulierung ist eine Vorverarbeitungstechnologie, die durch eine Reihe von Datentransformationen verbessert wird kann die äquivalente Darstellung von Trainingsmustern im Merkmalsraum verbessern, ohne dass zusätzliche Beschriftungsinformationen erforderlich sind.
Effiziente Methoden zur Datenregulierung werden häufig im Trainingsprozess eingesetzt und können die Generalisierungsleistung großer Modelle erheblich verbessern. Daten-Sampling: Daten-Sampling ist auch eine effektive Methode, um den Gradienten in kleinen Chargen zu trainieren Die Auswirkungen unwichtiger oder schlechter Proben in der aktuellen Charge können reduziert werden.
Datenzentriertes Lehrplan-Lernen Lehrplan-Lernen untersucht progressive Trainingseinstellungen in verschiedenen Phasen des Trainingsprozesses, um den gesamten Rechenaufwand zu reduzieren. Modellzentriertes effizientes Training Der Entwurf einer effizienten Modellarchitektur ist immer eine der wichtigsten Studien im Bereich Deep Learning. Ein hervorragendes Modell sollte ein effizienter Feature-Extraktor sein, der auf Komponenten auf hoher Ebene projiziert werden kann sind leicht zu trennen. Fast alle Großmodelle bestehen aus kleinen Modulen oder Schichten, sodass die Untersuchung von Modellen als Leitfaden für ein effizientes Training von Großmodellen dienen kann:
Architektur Effizienz Der starke Anstieg der Parameteranzahl in tiefen Modellen bringt auch einen enormen Rechenaufwand mit sich, sodass eine effiziente Alternative implementiert werden muss, um die Leistung der Originalversion der Modellarchitektur anzunähern Die Richtung hat nach und nach auch die Aufmerksamkeit der akademischen Gemeinschaft auf sich gezogen; dieser Ersatz ist nicht nur eine Annäherung an numerische Berechnungen, sondern umfasst auch strukturelle Vereinfachung und Fusion in tiefen Modellen.
Kompressionstrainingseffizienz Kompression war schon immer eine der Forschungsrichtungen in der Rechenbeschleunigung und spielt eine Schlüsselrolle in der digitalen Signalverarbeitung (Multimedia-Computing/Bildverarbeitung).
Initialisierungseffizienz Die Initialisierung von Modellparametern ist ein sehr wichtiger Faktor in bestehenden theoretischen Analysen und tatsächlichen Szenarien.
Modellzentriertes Lehrplanlernen Aus modellzentrierter Sicht beginnt das Kurslernen normalerweise mit dem Training von einem kleinen Modell oder Teilparametern in einem großen Modell und stellt dann nach und nach die gesamte Architektur wieder her, was größere Vorteile bei der Beschleunigung des Trainingsprozesses zeigt Der Artikel untersucht die Implementierung und Effizienz dieser Methode im Trainingsprozess, da sie offensichtlich negative Auswirkungen hat. Das Beschleunigungsschema von Optimierungsmethoden war schon immer eine wichtige Forschungsrichtung im Bereich des maschinellen Lernens. Die Reduzierung der Komplexität bei gleichzeitiger Erzielung optimaler Bedingungen war schon immer das von der akademischen Gemeinschaft verfolgte Ziel. In den letzten Jahren haben effiziente und leistungsstarke Optimierungsmethoden wichtige Durchbrüche beim Training tiefer neuronaler Netze erzielt. Als grundlegender Optimierer, der im maschinellen Lernen weit verbreitet ist, haben tiefe Modelle jedoch erfolgreich dabei geholfen, verschiedene praktische Anwendungen zu erreichen Das Problem wird immer komplexer, der SGD fällt eher in lokale Minima und kann nicht stabil verallgemeinert werden. Um diese Schwierigkeiten zu lösen, wurde vorgeschlagen, dass Adam und seine Varianten Anpassungsfähigkeit in Aktualisierungen einführen. Dieser Ansatz hat bei groß angelegten Netzwerktrainings gute Ergebnisse erzielt, beispielsweise bei BERT-, Transformer- und ViT-Modellen. Neben der Eigenleistung des konzipierten Optimierers ist auch die Kombination beschleunigter Trainingstechniken wichtig. Basierend auf der Perspektive der Optimierung fassten Forscher die aktuellen Überlegungen zum beschleunigten Training in die folgenden Aspekte zusammen: Lernrate Lernrate Die Lernrate ist ein wichtiger Faktor bei nicht-konvexen Optimierung Hyperparameter sind auch im aktuellen Deep-Network-Training von entscheidender Bedeutung, und adaptive Methoden wie Adam und seine Varianten haben erfolgreich bemerkenswerte Fortschritte bei Deep-Modellen erzielt. Einige Strategien zur Anpassung der Lernrate basierend auf Gradienten höherer Ordnung erzielen auch effektiv ein beschleunigtes Training, und die Implementierung einer Lernratenabschwächung wirkt sich auch auf die Leistung während des Trainingsprozesses aus. Große Batchgröße Die Verwendung einer größeren Batchgröße verbessert effektiv die Trainingseffizienz und kann die Anzahl der zum Abschließen eines Epochentrainings erforderlichen Iterationen direkt reduzieren; in diesem Fall ist die Gesamtstichprobengröße festgelegt Die Verarbeitung einer größeren Chargengröße ist kostengünstiger als die Verarbeitung mehrerer Proben in kleineren Chargengrößen, da die Speichernutzung verbessert und Kommunikationsengpässe reduziert werden können. Effiziente Zielsetzung Das grundlegendste ERM spielt eine Schlüsselrolle bei der Minimierung von Problemen und macht viele Aufgaben praktisch. Mit der Vertiefung der Forschung zu großen Netzwerken widmen einige Arbeiten der Lücke zwischen Optimierung und Generalisierung mehr Aufmerksamkeit und schlagen wirksame Ziele vor, um Testfehler aus verschiedenen Perspektiven zu reduzieren und die gemeinsame Optimierung des Trainings zu verbessern Sie können die Genauigkeit des Tests erheblich beschleunigen. Gemittelte Gewichtungen Der gewichtete Durchschnitt ist eine praktische Technik, die die Allgemeingültigkeit des Modells verbessern kann, da ein gewichteter Durchschnitt historischer Zustände berücksichtigt wird, mit einem Satz eingefrorener oder erlernbarer Koeffizienten, die dies können Beschleunigen Sie den Trainingsprozess erheblich. Mehrere aktuelle Bemühungen haben sich darauf konzentriert, Deep-Learning-Modelle mit weniger Ressourcen zu trainieren und eine möglichst hohe Genauigkeit zu erreichen. Diese Art von Problem wird als budgetiertes Training definiert, d. h. als Training unter einem bestimmten Budget (einer Grenze messbarer Kosten), um die höchste Modellleistung zu erzielen. Um die Hardwareunterstützung systematisch zu berücksichtigen und näher an die reale Situation heranzukommen, definierten die Forscher Budgettraining als Training auf einem bestimmten Gerät und mit begrenzter Zeit, zum Beispiel das Training auf einem einzelnen Low-End-Deep-Learning Servertag, um das Modell mit der besten Leistung zu erhalten. Effizientes Lernen mit Fokus auf Optimierung
Budgetbasiertes und effizientes Training
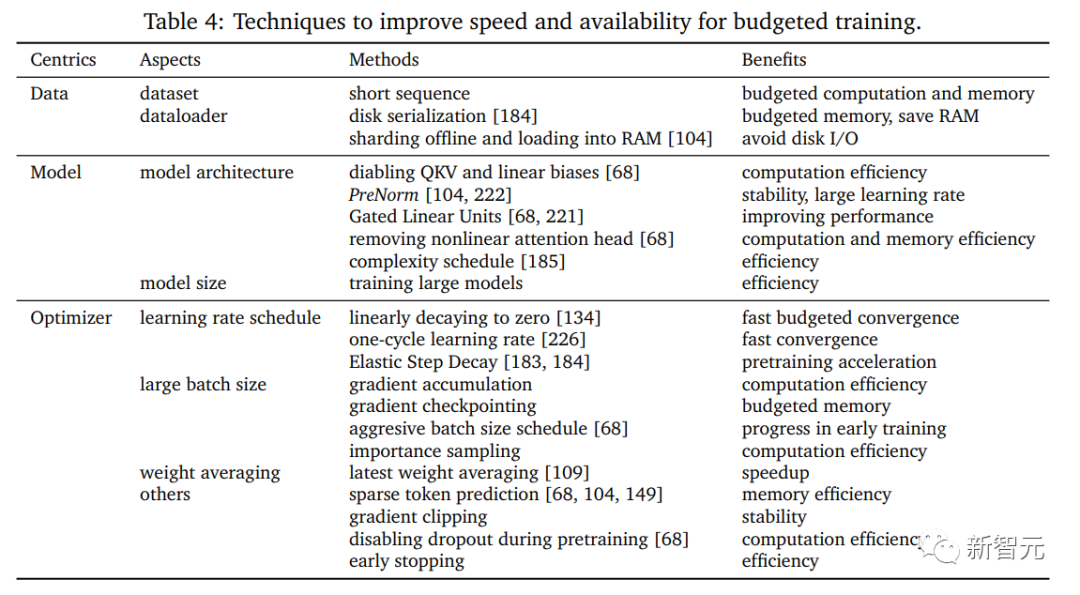
Eine Studie über Schulungen mit kleinem Budget kann Aufschluss darüber geben, wie man etwas schafft Ein Training mit kleinem Budget. Trainingsrezepte, einschließlich der Bestimmung der Konfiguration der Modellgröße, der Modellstruktur, des Lernratenplans und mehrerer anderer einstellbarer Faktoren, die sich auf die Leistung auswirken, sowie die Kombination effizienter Trainingstechniken, die für das verfügbare Budget geeignet sind. In diesem Artikel werden hauptsächlich einige fortgeschrittene Techniken besprochen Techniken für das Budgettraining.
Systemzentriertes effizientes TrainingSystemzentrierte Forschung besteht darin, spezifische Implementierungsmethoden für die entworfenen Algorithmen bereitzustellen, und Forschung ist erforderlich die effektive und praktische Ausführung von Hardware, die wirklich ein effizientes Training ermöglichen kann.
Forscher konzentrieren sich auf die Implementierung von Allzweck-Computergeräten, wie CPU- und GPU-Geräten in Clustern mit mehreren Knoten, und auf die Lösung potenzieller Konflikte bei Entwurfsalgorithmen einer Hardware Perspektive ist ein Anliegen Kern.
In diesem Artikel werden hauptsächlich die Hardware-Implementierungstechnologien in vorhandenen Frameworks und Bibliotheken von Drittanbietern untersucht. Diese Technologien unterstützen effektiv die Datenverarbeitung, Modelle und Optimierung und stellen einige vor Die bestehende Open-Source-Plattform bietet einen soliden Rahmen für die Modellerstellung, die effektive Nutzung von Daten für das Training, das gemischte Präzisionstraining und das verteilte Training.
Systemzentrierte Dateneffizienz
#🎜 🎜## 🎜🎜#Effiziente Datenverarbeitung und Datenparallelität sind zwei wichtige Anliegen bei der Systemimplementierung.
Mit dem rasanten Anstieg des Datenvolumens ist ineffiziente Datenverarbeitung nach und nach zu einem Engpass für die Trainingseffizienz geworden, insbesondere bei groß angelegtem Training auf mehreren Knoten, und immer mehr Designs sind es Durch Hardware-freundliche Rechenmethoden und Parallelisierung kann effektiv Zeitverschwendung beim Training vermieden werden.
Systemzentrierte Modelleffizienz
#🎜 🎜#Mit der schnellen Expansion von Aufgrund der Anzahl der Modellparameter ist die Systemeffizienz aus Sicht des Modells zu einem wichtigen Engpass geworden. Die Speicher- und Recheneffizienz großer Modelle hat die Hardware-Implementierung vor große Herausforderungen gestellt.In diesem Artikel wird hauptsächlich untersucht, wie eine effiziente E/A der Bereitstellung und eine optimierte Implementierung der Modellparallelität erreicht werden können, um das eigentliche Training zu beschleunigen.
Systemzentrierte Optimierungseffizienz#🎜 🎜#Der Optimierungsprozess repräsentiert die Backpropagation und Aktualisierung in jeder Iteration sind auch die zeitaufwändigsten Berechnungen im Training. Daher bestimmt die Implementierung der systemzentrierten Optimierung direkt die Effizienz des Trainings.
Um die Merkmale der Systemoptimierung klar zu interpretieren, konzentriert sich der Artikel auf die Effizienz verschiedener Berechnungsstufen und überprüft die Verbesserungen jedes Prozesses.
Open Source Frameworks# 🎜 🎜 #Effiziente Open-Source-Frameworks können das Training erleichtern. Als Brücke zwischen Grafting-Algorithmus-Design und Hardware-Unterstützung untersuchten die Forscher eine Reihe von Open-Source-Frameworks und analysierten die Vor- und Nachteile jedes Designs.
Schlussfolgerung
Der Artikel schlägt außerdem eine neuartige Taxonomie vor, die diese Technologien in fünf Hauptrichtungen zusammenfasst: datenzentriert, modellzentriert, optimierungszentriert, Budgettraining und systemzentriert.
Die ersten vier Teile führen hauptsächlich umfassende Forschung aus der Perspektive des Algorithmusdesigns und der Methodik durch, während im Teil „Systemzentriertes effizientes Training“ die eigentliche Umsetzung aus der Perspektive der Paradigmeninnovation und Hardwareunterstützung zusammengefasst wird.
Der Artikel bespricht und fasst häufig verwendete oder neu entwickelte Technologien für jeden Teil sowie die Vorteile und Kompromisse jeder Technologie zusammen und erörtert Einschränkungen und vielversprechende zukünftige Forschungsrichtungen, bevor er einen umfassenden technischen Überblick gibt und gleichzeitig Anleitungen gibt. In dieser Überprüfung werden auch die aktuellen Durchbrüche und Engpässe bei der effizienten Ausbildung dargelegt.
Die Forscher hoffen, den Forschern dabei zu helfen, eine allgemeine Trainingsbeschleunigung zu erreichen und zusätzlich zu einigen potenziellen Fortschritten, die am Ende jedes Abschnitts erwähnt werden, einige sinnvolle und vielversprechende Auswirkungen zu erzielen vielversprechende Gesichtspunkte sind wie folgt:
1. Effiziente Profilsuche
Effizientes Training kann aus den Perspektiven der Datenverbesserungskombination, Modellstruktur, Optimiererdesign usw. beginnen, um Modellen einige Fortschritte zu ermöglichen wurde bei der Entwicklung vorgefertigter und anpassbarer Profilsuchstrategien durchgeführt.
Neue Modellarchitekturen und Komprimierungsmodi, neue Aufgaben vor dem Training und die Nutzung von „Model-Edge“-Wissen sind ebenfalls eine Erkundung wert.
2. Mit einem auf die Optimierung des Kurses, der Lernrate und der Stapelgröße sowie der Modellkomplexität ausgerichteten Planer ist es möglich, eine bessere Leistung zu erzielen Der Scheduler kann sich dynamisch an das verbleibende Budget anpassen und so die Kosten für den manuellen Entwurf reduzieren. Mit dem adaptiven Scheduler können Parallelität und Kommunikationsmethoden untersucht und gleichzeitig allgemeinere und praktischere Situationen berücksichtigt werden, z. B. wenn mehrere Regionen und Daten in großem Maßstab dezentralisiert werden Ausbildung in einem zentralisierten heterogenen Netzwerk.
Das obige ist der detaillierte Inhalt vonBeim Training großer Models wird auf „Energie' geachtet! Tao Dacheng leitet das Team: Alle Lösungen für „effizientes Training' werden in einem Artikel behandelt. Hören Sie auf zu sagen, dass Hardware der einzige Engpass ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr