
Heim >Technologie-Peripheriegeräte >KI >Finale der Videosegmentierung! Die Universität Zhejiang hat kürzlich SAM-Track veröffentlicht: universelle intelligente Videosegmentierung mit einem Klick
Finale der Videosegmentierung! Die Universität Zhejiang hat kürzlich SAM-Track veröffentlicht: universelle intelligente Videosegmentierung mit einem Klick

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-23 14:07:061496Durchsuche
Kürzlich hat das ReLER-Labor der Zhejiang-Universität SAM intensiv mit Videosegmentierung kombiniert und Segment-and-Track Anything (SAM-Track) veröffentlicht.
SAM-Track gibt SAM die Möglichkeit, Videoziele zu verfolgen und unterstützt mehrere Arten der Interaktion (Punkte, Pinsel, Text).
Auf dieser Basis vereint SAM-Track mehrere herkömmliche Videosegmentierungsaufgaben und erreicht eine Ein-Klick-Segmentierung, um jedes Ziel in jedem Video zu verfolgen und traditionelle Videos zu segmentieren Videosegmentierung.
SAM-Track verfügt über eine hervorragende Leistung und kann Hunderte von Zielen in komplexen Szenarien mit nur einer einzigen Karte stabil und mit hoher Qualität verfolgen.

Projektadresse: https://github.com /z-x-yang/Segment-and-Track-Anything
Papieradresse: https://arxiv.org/abs/2305.06558
Effektanzeige
SAM-Track unterstützt die Spracheingabe als Eingabeaufforderung. Wenn beispielsweise der Kategorietext „Panda“ angegeben ist, kann die Segmentierung auf Instanzebene mit einem Klick verwendet werden, um alle Ziele zu verfolgen, die zur Kategorie „Panda“ gehören.

Sie können auch eine detailliertere Beschreibung angeben, z. B. die Eingabe von Text " „Panda ganz links“, SAM-Track kann bestimmte Ziele für die Segmentierungsverfolgung lokalisieren.

Im Vergleich zu herkömmlichen Video-Tracking-Algorithmen ist SAM-Track eine weitere Stärke besteht darin, dass es eine große Anzahl von Zielen gleichzeitig verfolgen und segmentieren und auftauchende Objekte automatisch erkennen kann.

SAM-Track unterstützt auch die Kombination mehrerer interaktiver Methoden, die Benutzer können Passend zu den tatsächlichen Bedürfnissen. Verwenden Sie beispielsweise einen Pinsel, um ein Skateboard einzurahmen, das eng mit dem menschlichen Körper verbunden ist, um die Segmentierung überflüssiger Objekte zu verhindern, und wählen Sie dann mit Klicks den menschlichen Körper aus.
Vollautomatische Videozielsegmentierung und -verfolgung sind natürlich ein Kinderspiel. Verschiedene Anwendungsszenarien umfassen Straßenansichten, Luftaufnahmen, AR, Animationen, medizinische Bilder usw., alles mit Mit einem Klick segmentieren und auftauchende Objekte automatisch erkennen.

Wenn Sie mit den automatischen Segmentierungsergebnissen nicht zufrieden sind, kann der Benutzer dies tun Nehmen Sie Bearbeitungskorrekturen vor, z. B. die Verwendung von Klicks, um eine übersegmentierte Straßenbahn zu reparieren.

Gleichzeitig unterstützt die neueste Version von SAM-Track online Beim Durchsuchen der Tracking-Ergebnisse können Sie das Segmentierungsergebnis eines beliebigen Frames in der Mitte auswählen, um es zu ändern, ein Ziel hinzuzufügen und es erneut zu verfolgen.

Um das Online-Erlebnis der Benutzer zu erleichtern, stellt das Projekt eine WebUI bereit, die mit einem Klick bereitgestellt werden kann Colab: #🎜🎜 #
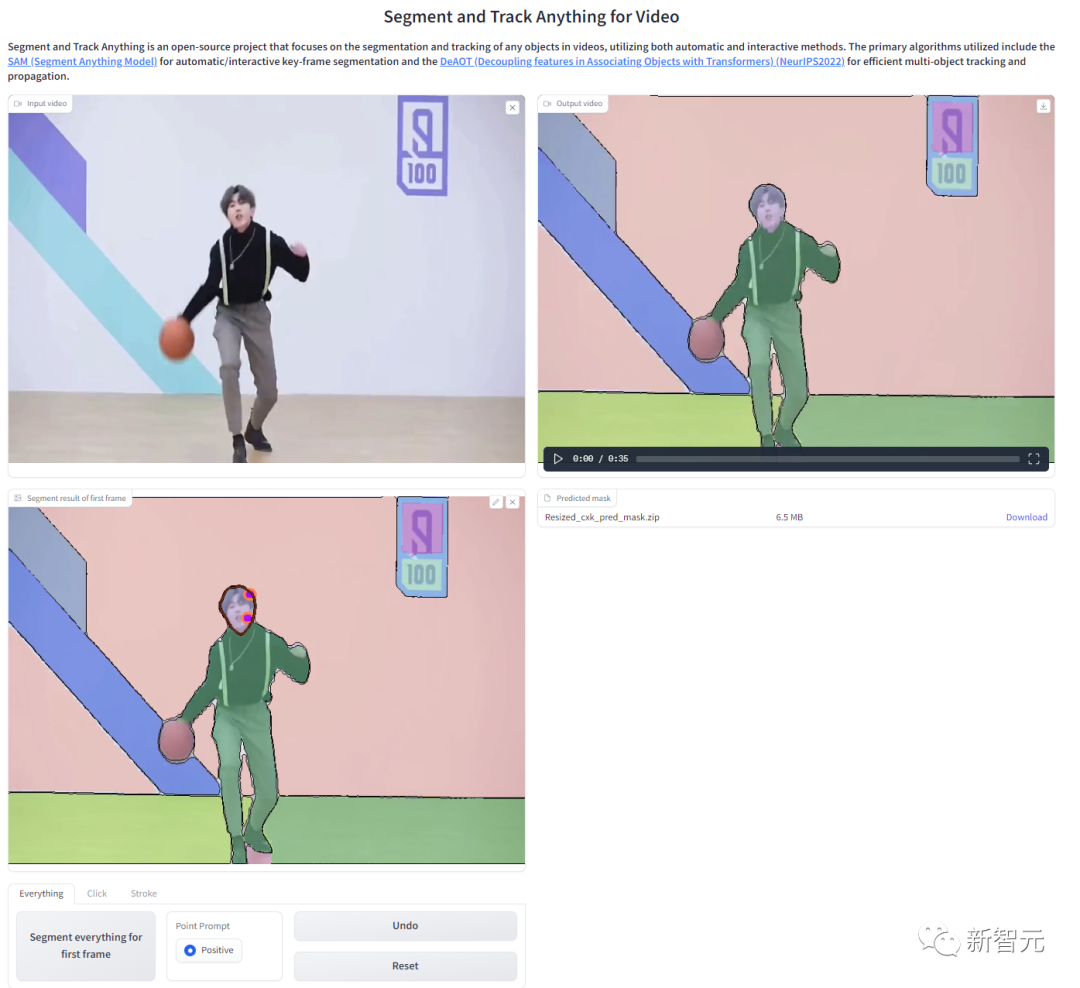
Modellzusammensetzung
Das SAM-Track-Modell basiert auf DeAOT, dem Meisterschaftsschema der vier Tracks des ECCV'22 VOT Workshop.
DeAOT ist ein effizientes VOS-Modell mit mehreren Zielen. Basierend auf der Objektanmerkung des ersten Frames kann es Objekte in den verbleibenden Frames des Videos verfolgen und segmentieren.
DeAOT nutzt einen Erkennungsmechanismus, um mehrere Ziele in einem Video in denselben hochdimensionalen Raum einzubetten und so eine gleichzeitige Verfolgung mehrerer Objekte zu erreichen.
Die Geschwindigkeitsleistung von DeAOT bei der Verfolgung mehrerer Objekte ist vergleichbar mit anderen VOS-Methoden zur Verfolgung einzelner Objekte.
Darüber hinaus aggregiert DeAOT durch den auf Layered Transformer basierenden Ausbreitungsmechanismus besser langfristige und kurzfristige Informationen und zeigt eine hervorragende Tracking-Leistung.
Da DeAOT für die Initialisierung Referenzrahmenanmerkungen erfordert, verwendet SAM-Track zur Verbesserung der Benutzerfreundlichkeit das Segment Anything Model (SAM)-Modell, das in letzter Zeit im Bereich der Bildsegmentierung populär geworden ist, um Anmerkungsinformationen zu erhalten.
Mit den hervorragenden Zero-Sample-Migrationsfähigkeiten und mehreren Interaktionsmethoden von SAM kann SAM-Track effizient hochwertige Referenzrahmen-Annotationsinformationen für DeAOT erhalten.
Obwohl das SAM-Modell im Bereich der Bildsegmentierung eine gute Leistung erbringt, kann es keine semantischen Beschriftungen ausgeben und Texthinweise können die Segmentierung verweisender Objekte und andere Aufgaben, die auf einem tiefen semantischen Verständnis beruhen, nicht gut unterstützen.
Daher integriert das SAM-Track-Modell Grounding-DINO weiter, um eine hochpräzise sprachgesteuerte Videosegmentierung zu erreichen. Grounding DINO ist ein offenes Objekterkennungsmodell mit guten Sprachverständnisfähigkeiten.
Basierend auf der Eingabekategorie oder der detaillierten Beschreibung des Zielobjekts kann Grounding-DINO das Ziel erkennen und das Standortfeld zurückgeben.
SAM-Track-Modellarchitektur
Wie in der Abbildung unten gezeigt, unterstützt das SAM-Track-Modell drei Objektverfolgungsmodi, nämlich den interaktiven Verfolgungsmodus, den automatischen Verfolgungsmodus und den Fusionsmodus.
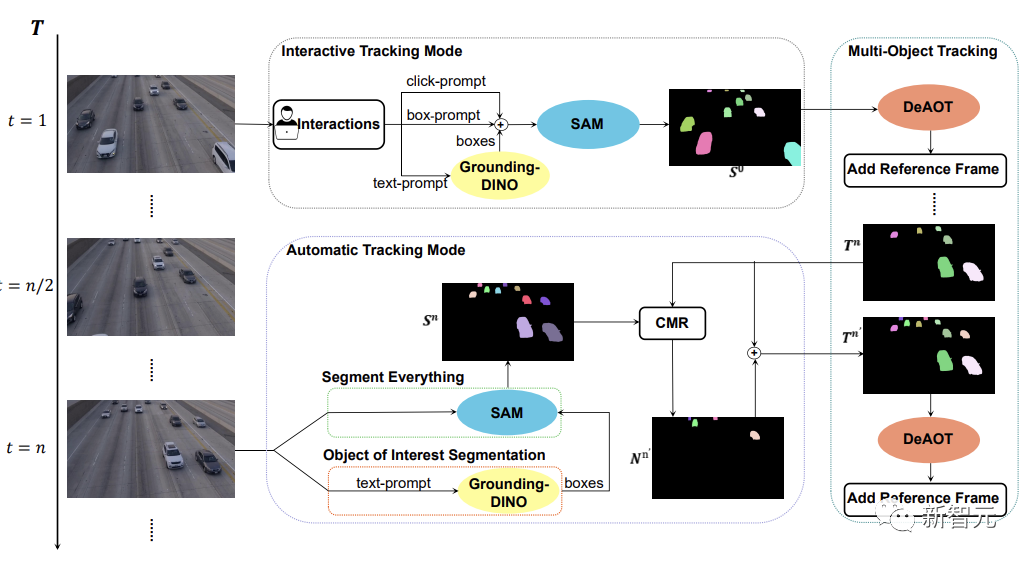
Für den interaktiven Tracking-Modus wendet das SAM-Track-Modell zunächst SAM an und wählt das Ziel im Referenzrahmen durch Klicken oder Zeichnen eines Rahmens aus, bis ein interaktives Segmentierungsergebnis vorliegt, das für den Benutzer zufriedenstellend ist erhalten.
Wenn Sie eine sprachgesteuerte Segmentierung von Videoobjekten implementieren möchten, ruft SAM-Track Grounding-DINO auf, um zunächst den Positionsrahmen des Zielobjekts basierend auf dem Eingabetext zu ermitteln und auf dieser Grundlage die Segmentierung des Zielobjekts zu ermitteln Objekt von Interesse durch SAM-Ergebnis.
Abschließend verwendet DeAOT das Ergebnis der interaktiven Segmentierung als Referenzrahmen, um das ausgewählte Ziel zu verfolgen. Während des Tracking-Prozesses überträgt DeAOT die visuelle Einbettung und die hochdimensionale ID-Einbettung in vergangenen Frames hierarchisch auf den aktuellen Frame, um eine Frame-für-Frame-Verfolgung und Segmentierung mehrerer Zielobjekte zu erreichen. Daher kann SAM-Track durch die Unterstützung multimodaler Interaktionen interessante Objekte in segmentierten Videos verfolgen.
Der interaktive Tracking-Modus kann jedoch nicht mit neu aufgetauchten Objekten umgehen, die im Video erscheinen. Beschränkt die Anwendung von SAM-Track in bestimmten Bereichen, wie autonomes Fahren, Smart Cities usw.
Um den Anwendungsbereich und die Leistung von SAM-Track weiter zu erweitern, implementiert SAM-Track den automatischen Tracking-Modus, um neue Objekte zu verfolgen, die im Video erscheinen.
Der automatische Tracking-Modus verwendet „Alles segmentieren“ und „Objekt von Interesse“-Segmentierung, um Anmerkungen zu neuen Objekten zu erhalten, die alle n Frames erscheinen. Für das ID-Zuordnungsproblem neu entstehender Objekte nutzt SAM-Track das Vergleichsmaskenmodul (CMR), um die ID des neuen Objekts zu ermitteln.
Der Fusionsmodus kombiniert den interaktiven Tracking-Modus und den automatischen Tracking-Modus. Der interaktive Tracking-Modus ermöglicht Benutzern das einfache Abrufen von Anmerkungen für das erste Bild eines Videos, während der automatische Tracking-Modus neue, nicht ausgewählte Objekte verarbeitet, die in nachfolgenden Bildern des Videos erscheinen. Die Kombination von Tracking-Methoden erweitert den Anwendungsbereich von SAM-Track und erhöht die Praktikabilität von SAM-Track.
Das obige ist der detaillierte Inhalt vonFinale der Videosegmentierung! Die Universität Zhejiang hat kürzlich SAM-Track veröffentlicht: universelle intelligente Videosegmentierung mit einem Klick. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr