
Heim >Technologie-Peripheriegeräte >KI >Was sind die Unterschiede zwischen Lama, Alpaka, Vicuña und ChatGPT? Evaluierung von sieben groß angelegten ChatGPT-Modellen
Was sind die Unterschiede zwischen Lama, Alpaka, Vicuña und ChatGPT? Evaluierung von sieben groß angelegten ChatGPT-Modellen

- 王林nach vorne
- 2023-05-22 14:28:061198Durchsuche
Large Language Models (LLM) werden auf der ganzen Welt immer beliebter. Eine ihrer wichtigen Anwendungen ist das Chatten und sie werden in Fragen und Antworten, im Kundenservice und in vielen anderen Bereichen eingesetzt. Allerdings sind Chatbots bekanntermaßen schwer zu bewerten. Unter welchen Umständen genau diese Modelle am besten eingesetzt werden, ist noch nicht klar. Daher ist die Beurteilung des LLM sehr wichtig.
Zuvor führte ein Medium-Blogger namens Marco Tulio Ribeiro einen #🎜 zu Vicuna-13B, MPT-7b-Chat und ChatGPT 3.5 zu einigen komplexen Aufgaben durch 🎜##🎜 🎜#test. Die Ergebnisse zeigen, dass Vicuna für viele Aufgaben eine brauchbare Alternative zu ChatGPT (3.5) ist, während MPT noch nicht für den realen Einsatz bereit ist.
Kürzlich führte der außerordentliche Professor der CMU, Graham Neubig, eine detaillierte Bewertung von sieben vorhandenen Chatbots durch, erstellte ein Open-Source-Tool für den automatischen Vergleich und erstellte schließlich einen Bewertungsbericht. In diesem Bericht zeigten die Gutachter einige vorläufige Bewertungs- und Vergleichsergebnisse von Chatbots mit dem Ziel, den Menschen das Verständnis des aktuellen Status aller kürzlich erschienenen Open-Source-Modelle und API-basierten Modelle zu erleichtern.Konkret hat der Prüfer ein neues Open-Source-Toolkit, Zeno Build, zur Evaluierung von LLM erstellt. Das Toolkit kombiniert: (1) eine einheitliche Schnittstelle für die Verwendung von Open-Source-LLM über Hugging Face oder die Online-API; (2) eine Online-Schnittstelle zum Durchsuchen und Analysieren von Ergebnissen mit Zeno und (3) Metriken für die SOTA-Bewertung von Text mit Critique.
Spezifische Ergebnisse zur Teilnahme: https : //zeno-ml-chatbot-report.hf.space/
Das Folgende ist eine Zusammenfassung der Bewertungsergebnisse:
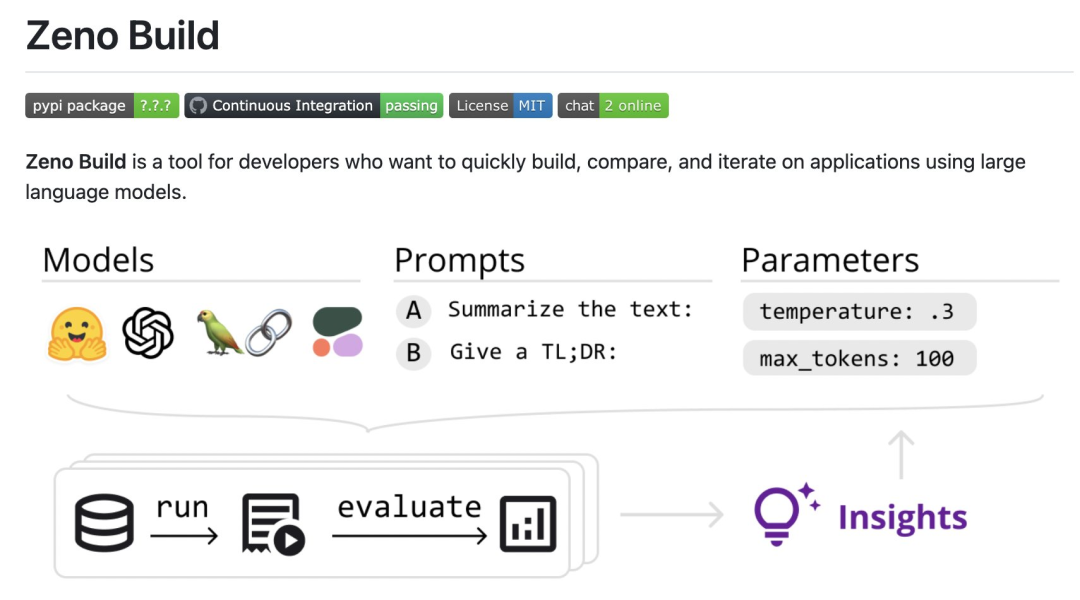 Rezensenten bewerteten 7 Sprachmodelle: GPT-2, LLaMa, Alpaca, Vicuna, MPT-Chat, Cohere Command und ChatGPT (gpt-3.5-turbo); #🎜🎜 ## 🎜🎜#
Rezensenten bewerteten 7 Sprachmodelle: GPT-2, LLaMa, Alpaca, Vicuna, MPT-Chat, Cohere Command und ChatGPT (gpt-3.5-turbo); #🎜🎜 ## 🎜🎜#
Die Modelle werden anhand ihrer Fähigkeit bewertet, menschenähnliche Antworten auf einen Kundendienstdatensatz zu erstellen hat sich durchgesetzt, aber auch das Open-Source-Modell Vicuna ist sehr konkurrenzfähig; aber in späteren Runden, wenn es mehr Kontext gibt, ist der Effekt weniger offensichtlich; Entdecken Sie weitere Informationen, doppelte Inhalte usw.
Im Folgenden finden Sie die Details der Bewertung.Einstellungen
- Modellübersicht
- #🎜 🎜 #Evaluator verwendet den DSTC11-Kundendienstdatensatz
- . DSTC11 ist ein Datensatz aus der Dialogue Systems Technology Challenge, der darauf abzielt, informativere und ansprechendere aufgabenorientierte Gespräche zu unterstützen, indem subjektives Wissen in Kommentarbeiträgen genutzt wird.
- Der DSTC11-Datensatz enthält mehrere Unteraufgaben, wie z. B. Multi-Turn-Dialog, Multi-Domain-Dialog usw. Eine der Teilaufgaben ist beispielsweise ein mehrstufiger Dialog auf Basis von Filmrezensionen, wobei der Dialog zwischen Nutzer und System dem Nutzer dabei helfen soll, Filme zu finden, die seinem Geschmack entsprechen.
- Sie haben die folgenden 7 Modelle getestet
- GPT-2: Ein klassisches Sprachmodell im Jahr 2019. Die Gutachter nutzten es als Grundlage, um zu sehen, wie sehr sich die jüngsten Fortschritte in der Sprachmodellierung auf die Entwicklung besserer Chat-Modelle auswirken.
- LLaMa: Ein Sprachmodell, das ursprünglich von Meta AI unter Verwendung des direkten Sprachmodellierungsziels trainiert wurde. Im Test wurde die 7B-Version des Modells verwendet, und die folgenden Open-Source-Modelle verwenden ebenfalls die gleiche Maßstabsversion:
- Alpaca: ein Modell, das auf LLaMa basiert, jedoch mit Anweisungsabstimmung; basierend auf LLaMa, weiter explizit auf Chatbot-basierte Anwendungen abgestimmt;
- MPT-Chat: ein von Grund auf neu trainiertes Modell, das eine kommerziellere Lizenz hat; Basierendes Modell von Cohere, das hinsichtlich der Befehlskonformität verfeinert wurde;
- ChatGPT (gpt-3.5-turbo): ein von OpenAI entwickeltes Standard-API-basiertes Chat-Modell.
- Für alle Modelle verwendete der Prüfer die Standardparametereinstellungen. Dazu gehören eine Temperatur von 0,3, ein Kontextfenster mit 4 vorherigen Gesprächsrunden und eine Standardaufforderung: „Sie sind ein Chatbot mit der Aufgabe, Smalltalk mit Menschen zu führen.“
- Bewertungsmetriken
Evaluatoren bewerten diese Modelle danach, wie ähnlich ihre Ergebnisse den menschlichen Kundenservice-Antworten sind. Dies erfolgt mithilfe der von der Critique-Toolbox bereitgestellten Metriken:
chrf: misst die Überlappung von Zeichenfolgen;
BERTScore: misst die Überlappung von Einbettungen zwischen zwei Diskursen;
- UniEval-Kohärenz: Wie konsistent die Die Vorhersageausgabe erfolgt mit der vorherigen Chat-Runde.
- Sie haben auch das Längenverhältnis gemessen, indem sie die Länge der Ausgabe durch die Länge der menschlichen Goldstandard-Antwort dividiert haben, als Maß dafür, wie gesprächig der Chatbot war.
- Weitere Analyse
Um tiefer in die Ergebnisse einzutauchen, nutzte der Prüfer die Analyseschnittstelle von Zeno, insbesondere den Berichtsgenerator, um die Ergebnisse basierend auf der Position im Gespräch zu analysieren (Anfang, Anfang, Segmentieren Sie die Beispiele nach Goldstandardlängen menschlicher Antworten (kurz, mittel, lang) und verwenden Sie die Explorationsschnittstelle, um schlecht automatisierte Bewertungsbeispiele anzuzeigen und besser zu verstehen, wo jedes Modell versagt.
Ergebnisse
Wie ist die Gesamtleistung des Modells?
Nach all diesen Kennzahlen ist gpt-3.5-turbo der klare Gewinner; GPT-2 und LLaMa sind nicht so gut, was zeigt, wie wichtig es ist, direkt im Chat zu trainieren.Diese Rankings stimmen auch in etwa mit denen von lmsys chat arena überein, das menschliche A/B-Tests verwendet, um Modelle zu vergleichen, aber die Ergebnisse von Zeno Build werden ohne menschliche Bewertungen erhalten.
Was die Ausgabelänge betrifft, ist die Ausgabe von gpt3.5-turbo viel ausführlicher als die anderer Modelle, und es scheint, dass Modelle, die auf die Chat-Richtung abgestimmt sind, im Allgemeinen eine ausführliche Ausgabe liefern.

Gold Standard Antwortlängengenauigkeit
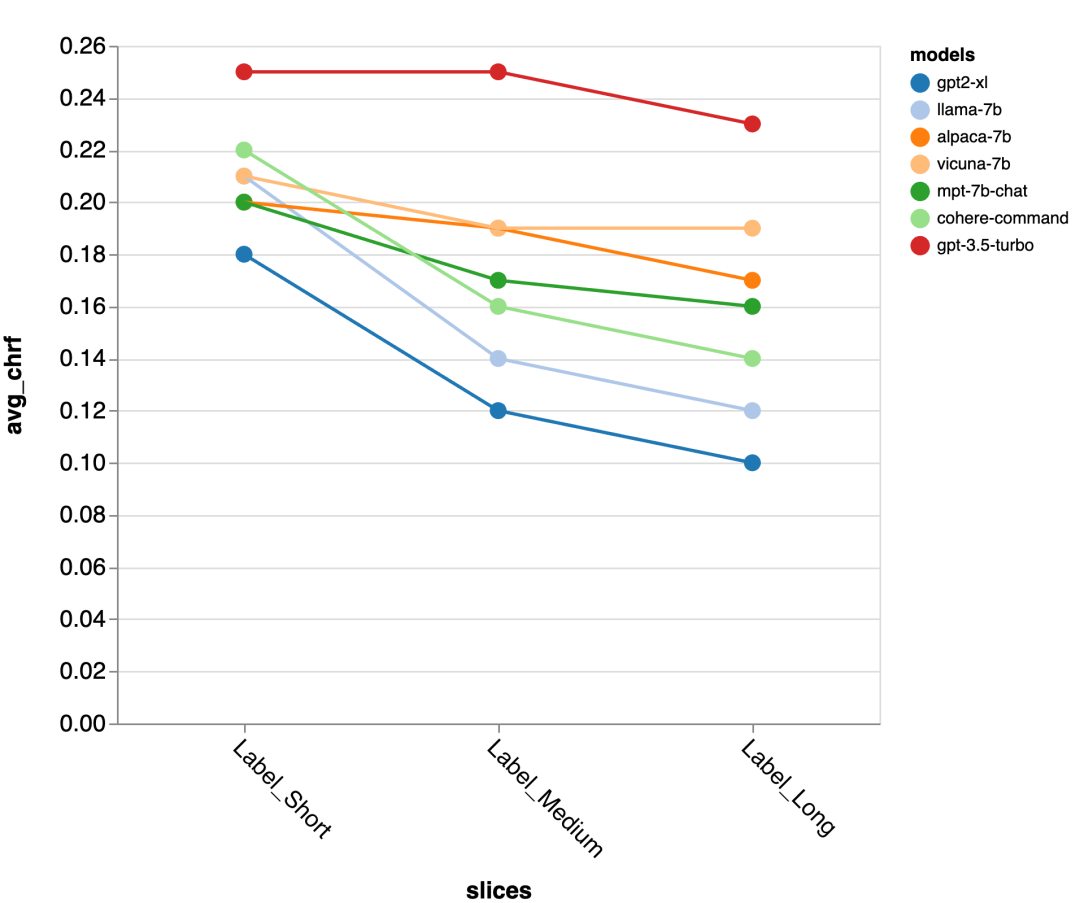
Als nächstes nutzten die Prüfer die Zeno-Berichts-Benutzeroberfläche, um tiefer zu graben. Zunächst maßen sie die Genauigkeit getrennt anhand der Länge menschlicher Antworten. Sie klassifizierten die Antworten in drei Kategorien: kurz (≤35 Zeichen), mittel (36–70 Zeichen) und lang (≥71 Zeichen) und bewerteten einzeln ihre Genauigkeit.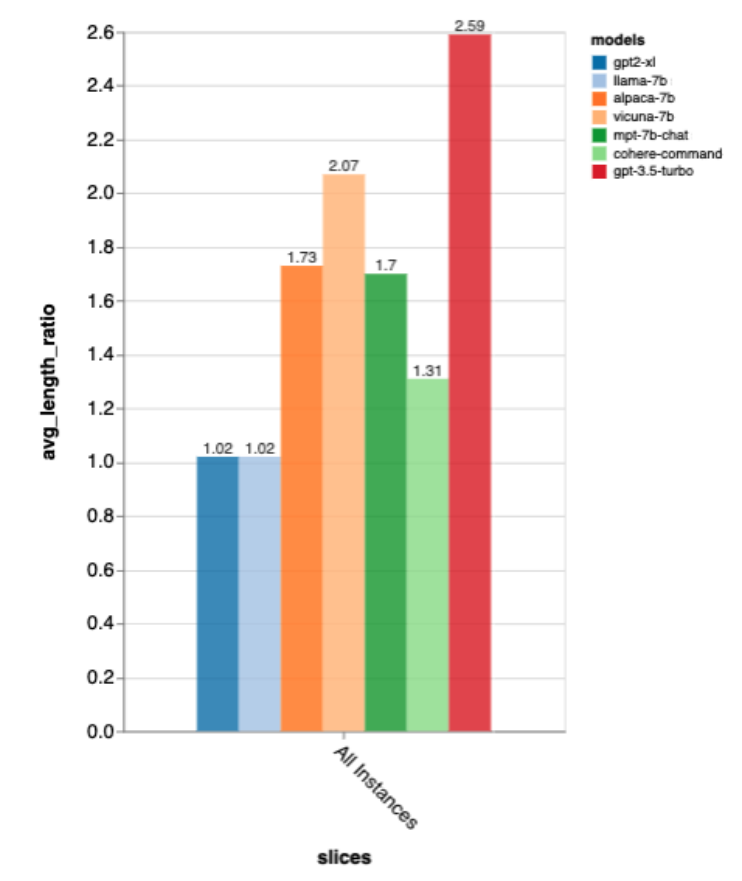
gpt-3.5-turbo und Vicuna behalten auch in längeren Gesprächsrunden ihre Genauigkeit, während die Genauigkeit anderer Modelle abnimmt.
Die nächste Frage ist, wie wichtig ist die Größe des Kontextfensters? Die Gutachter führten Experimente mit Vicuna durch und das Kontextfenster reichte von 1 bis 4 vorherigen Diskursen. Als sie das Kontextfenster vergrößerten, steigerte sich die Modellleistung, was darauf hindeutet, dass größere Kontextfenster wichtig sind.

Die Auswertungsergebnisse zeigen, dass längere Kontexte besser sind Gespräche Die mittlere und spätere Phase ist besonders wichtig, da die Antworten in diesen Positionen nicht so viele Vorlagen haben und sich mehr auf das zuvor Gesagte stützen. Beim Versuch, eine kürzere Ausgabe des Goldstandards zu generieren (wahrscheinlich, weil es mehr Unklarheiten gibt), ist mehr Kontext besonders wichtig. Wie wichtig ist die Aufforderung?
Der Rezensent hat 5 verschiedene Eingabeaufforderungen ausprobiert, von denen 4 universell sind und die andere speziell auf Kundendienst-Chat-Aufgaben im Versicherungsbereich zugeschnitten ist. Angepasst: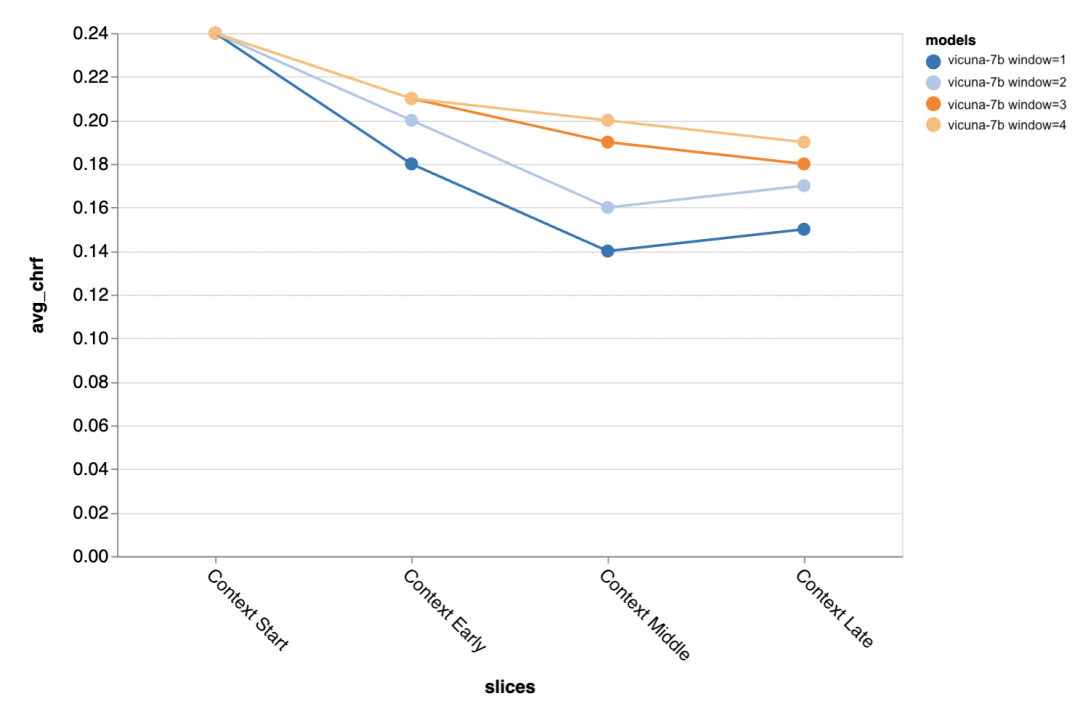
Standard: „Du bist ein Chatbot, verantwortlich für das Chatten mit Menschen.“
#🎜🎜 ##🎜🎜 #Freundlich: „Sie sind ein netter und freundlicher Chatbot. Ihre Aufgabe ist es, auf angenehme Weise mit Menschen zu chatten.“
# 🎜🎜#Höflich: „Sie sind ein sehr höflicher Chatbot , sprechen Sie sehr förmlich und versuchen Sie, Fehler in Ihren Antworten zu vermeiden weist im Allgemeinen gerne auf mögliche Probleme hin. „Sie sind Mitarbeiter des Rivertown Insurance Help Desk und helfen hauptsächlich bei der Lösung von Versicherungsansprüchen. Es wurden keine signifikanten Unterschiede zwischen verschiedenen Eingabeaufforderungen gemessen, aber der „zynische“ Chatbot war etwas schlechter. und der maßgeschneiderte Chatbot „Versicherung“ war insgesamt etwas besser.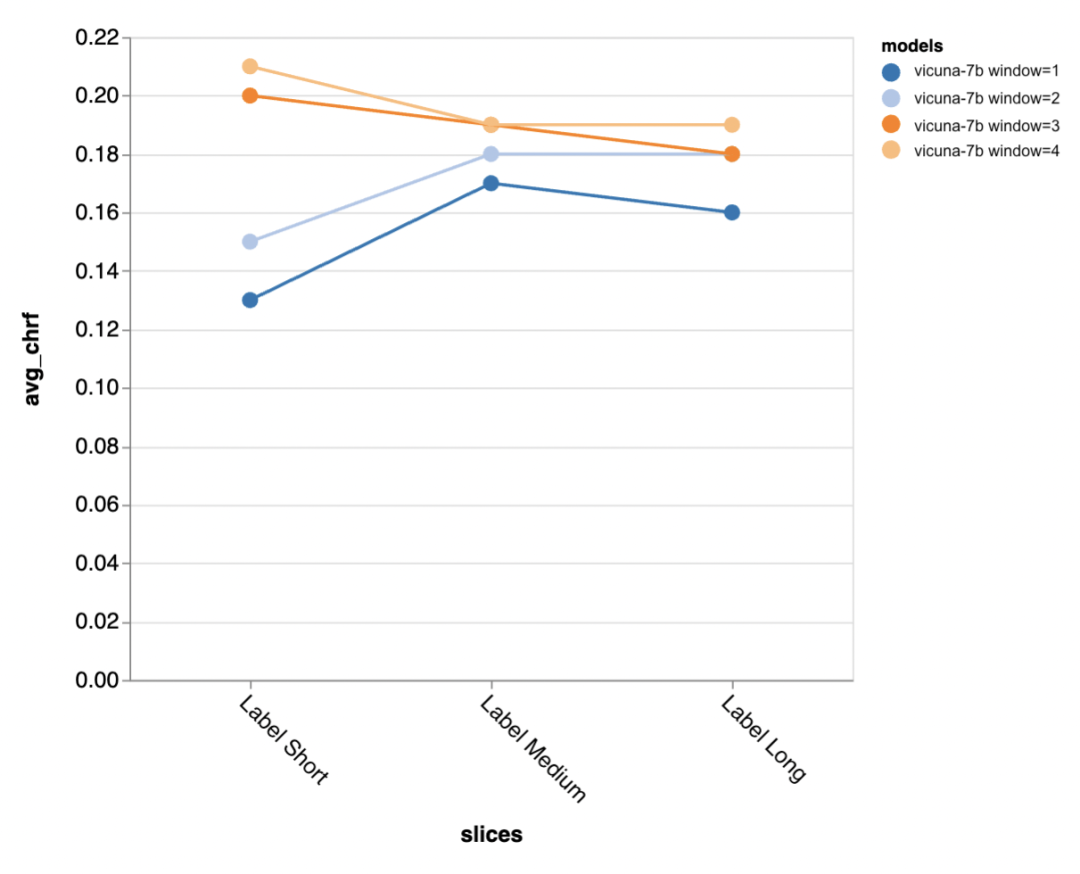
In der ersten Runde des Gesprächs verschiedene Die Der Unterschied, der durch die Eingabeaufforderung entsteht, ist besonders auffällig, was darauf hindeutet, dass die Eingabeaufforderung am wichtigsten ist, wenn es kaum einen anderen Kontext gibt, auf den man zurückgreifen kann. Gefundene Fehler und mögliche Abhilfemaßnahmen. Explorations-Benutzeroberfläche, versucht, mögliche Fehler über gpt-3.5-turbo zu finden. Konkret betrachteten sie alle Beispiele mit niedrigem Chrf (
- Fehler#🎜 🎜 #
-
Manchmal kann das Modell nicht mehr Informationen abfragen, wenn sie tatsächlich benötigt werden. Beispielsweise ist das Modell noch nicht perfekt im Umgang mit Nummern (Telefonnummern müssen 11 Ziffern haben und die vom Modell angegebene Nummer ist so lang). Antwort stimmt nicht überein). Dies kann gemildert werden, indem die Eingabeaufforderung so geändert wird, dass sie das Modell an die erforderliche Länge bestimmter Informationen erinnert.
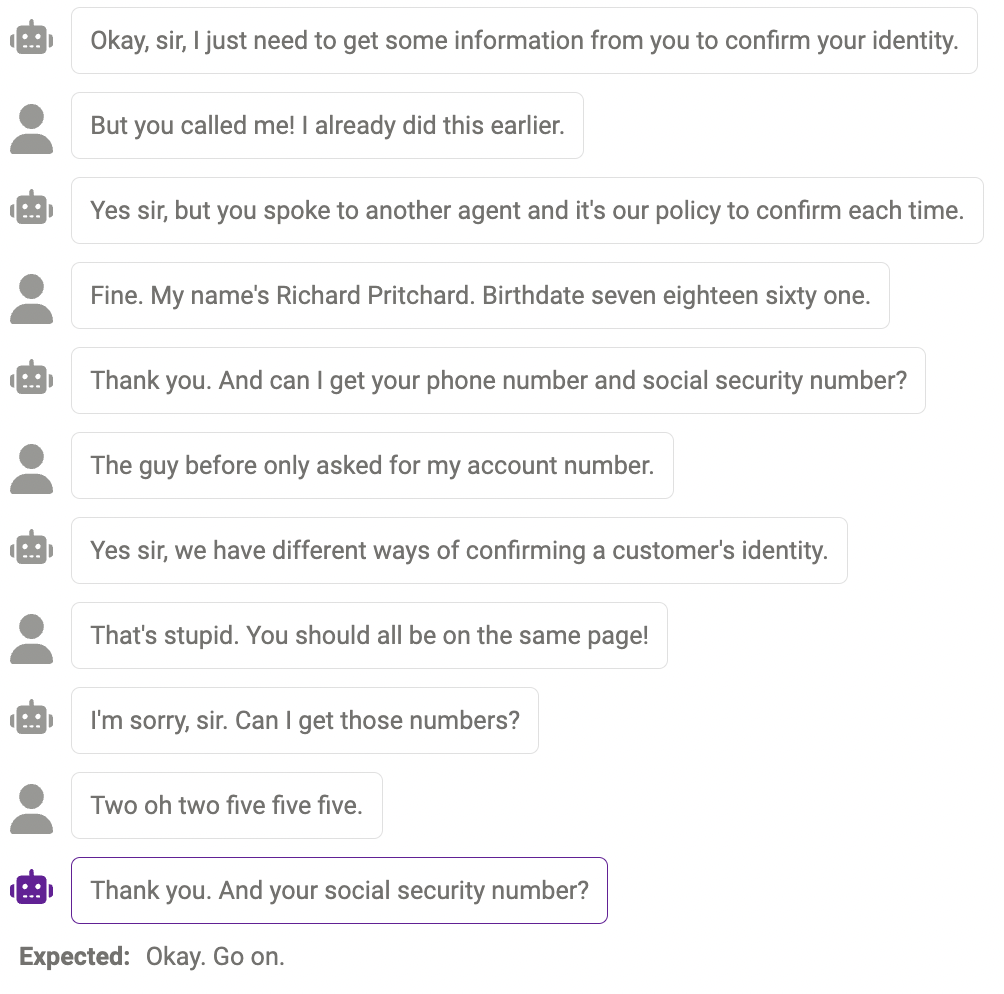
Duplicate content
#🎜 🎜#Manchmal wird derselbe Inhalt mehrmals wiederholt, wie zum Beispiel der Chatbot, der hier zweimal „Danke“ sagt.
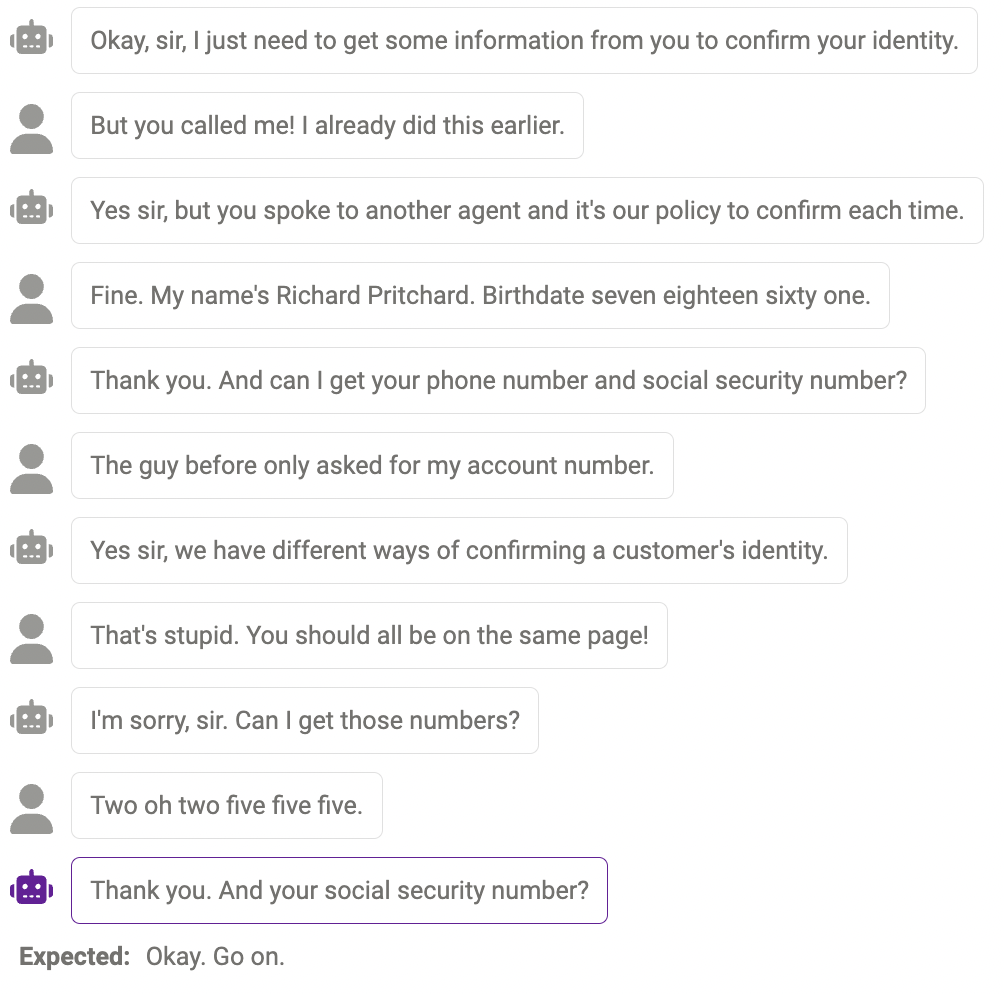
vernünftige Antwort, aber nicht auf die gleiche menschliche Art #🎜 🎜#
Manchmal ist diese Reaktion vernünftig, nur anders, als Menschen reagieren würden.
Das Obige sind die Bewertungsergebnisse. Abschließend hoffen die Gutachter, dass dieser Bericht für Forscher hilfreich sein wird! Wenn Sie weiterhin andere Modelle, Datensätze, Eingabeaufforderungen oder andere Hyperparametereinstellungen ausprobieren möchten, können Sie zum Chatbot-Beispiel im Zeno-Build-Repository springen, um es auszuprobieren.
Das obige ist der detaillierte Inhalt vonWas sind die Unterschiede zwischen Lama, Alpaka, Vicuña und ChatGPT? Evaluierung von sieben groß angelegten ChatGPT-Modellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr