
Heim >Technologie-Peripheriegeräte >KI >Mit 3,6 Billionen Token und 340 Milliarden Parametern wurden Details von Googles großem Modell PaLM 2 offengelegt
Mit 3,6 Billionen Token und 340 Milliarden Parametern wurden Details von Googles großem Modell PaLM 2 offengelegt

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-21 08:07:201007Durchsuche
Letzten Donnerstag kündigte Google-CEO Pichai auf der Google I/O-Konferenz 2023 die Einführung von PaLM 2 an, einem großen Modell zum Benchmarking von GPT-4, und veröffentlichte offiziell eine Vorschauversion, die Mathematik, Code, Argumentation und Multi verbessert -Sprachübersetzung und Möglichkeiten zur Erzeugung natürlicher Sprache.

Das PaLM 2-Modell ist in vier Versionen unterschiedlicher Größe erhältlich, von klein bis groß, Gecko, Otter, Bison und Einhorn, was den Einsatz für verschiedene Anwendungsfälle erleichtert. Unter anderem kann das leichte Gecko-Modell sehr schnell auf mobilen Geräten ausgeführt werden, und hervorragende interaktive Anwendungen können auf dem Gerät ausgeführt werden, ohne dass eine Verbindung zum Internet besteht.
Allerdings gab Google bei dem Treffen keine spezifischen technischen Details zu PaLM 2 bekannt, sondern gab lediglich an, dass es auf Googles neuestem JAX und TPU v4 basiert.

Gestern wurde PaLM 2 auf 3,6 Billionen Token trainiert, wie aus internen Dokumenten der ausländischen Medien CNBC hervorgeht. Zum Vergleich: Das PaLM der vorherigen Generation wurde mit 780 Milliarden Token trainiert.
Darüber hinaus hat Google zuvor erklärt, dass PaLM 2 kleiner als frühere LLMs ist, was bedeutet, dass es bei der Erledigung komplexerer Aufgaben effizienter werden kann. Dies wurde auch in internen Dokumenten bestätigt. Die Trainingsparametergröße von PaLM 2 beträgt 340 Milliarden, was viel kleiner ist als die 540 Milliarden von PaLM. 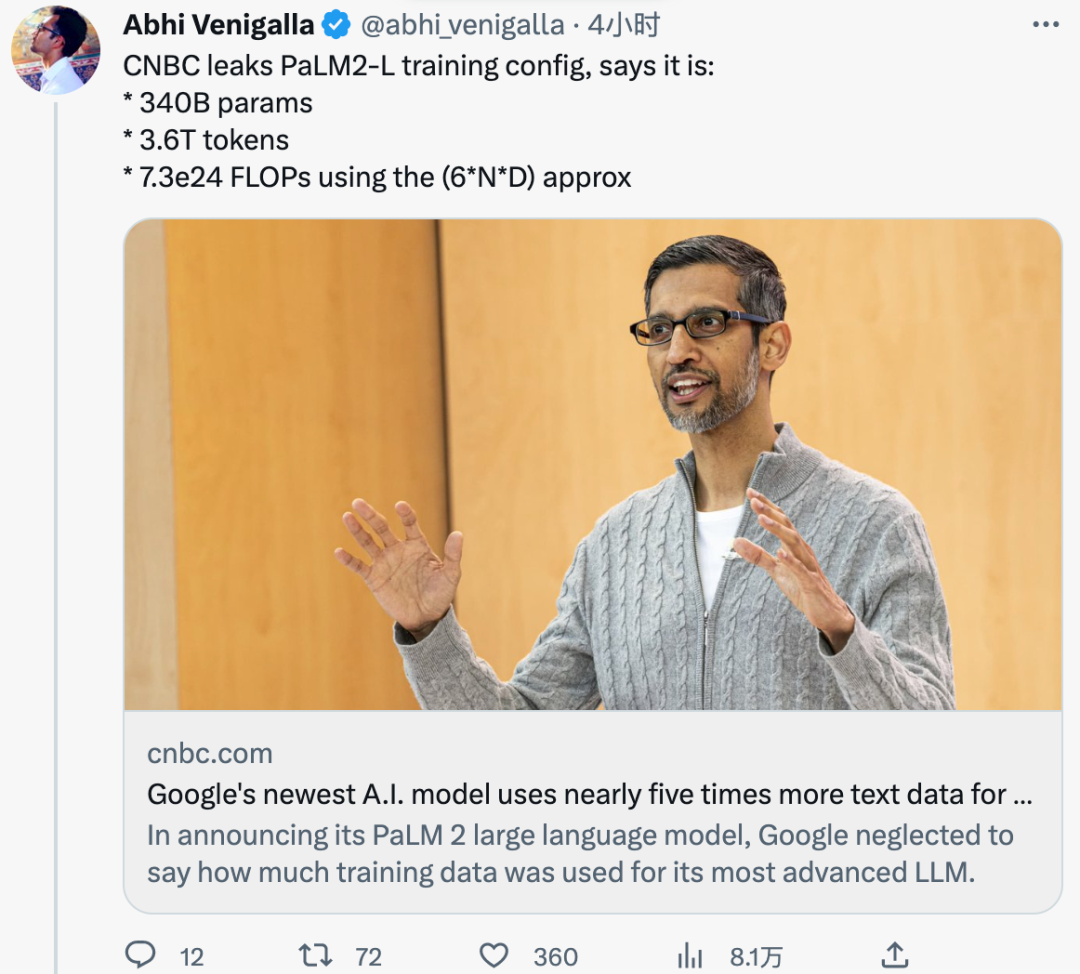
Wie sind die Trainingstokens und Parameter von PaLM 2 im Vergleich zu anderen LLMs? Zum Vergleich: LLaMA, das im Februar von Meta veröffentlicht wurde, wurde auf 1,4 Billionen Token trainiert. Der 175 Milliarden Parameter umfassende GPT-3 von OpenAI wurde auf 300 Milliarden Token trainiert.
Während Google bestrebt war, die Leistungsfähigkeit seiner KI-Technologie zu demonstrieren und zu zeigen, wie sie in die Suche, E-Mail, Dokumentenverarbeitung und Tabellenkalkulationen eingebettet werden kann, zögerte das Unternehmen auch, den Umfang seiner Trainingsdaten oder andere Details preiszugeben . Tatsächlich ist Google nicht der einzige, der dies tut. Auch OpenAI schweigt zu den Details seines neuesten multimodalen Großmodells GPT-4. Sie alle sagten, die Geheimhaltung von Details sei auf den Wettbewerbscharakter des Unternehmens zurückzuführen.
Da sich das KI-Wettrüsten jedoch weiter verschärft, fordert die Forschungsgemeinschaft zunehmend mehr Transparenz. Und in einem vor einiger Zeit durchgesickerten internen Google-Dokument äußerten Google-interne Forscher diese Ansicht: Obwohl es oberflächlich betrachtet so aussieht, als ob OpenAI und Google einander bei großen KI-Modellen nachjagen, muss der wahre Gewinner nicht unbedingt von diesen beiden kommen Zuhause, weil die Drittanbieter-Kraft „Open Source“ stillschweigend auf dem Vormarsch ist.
Derzeit wurde die Echtheit dieses internen Dokuments nicht überprüft und Google hat den relevanten Inhalt nicht kommentiert.
Netizen-Kommentare
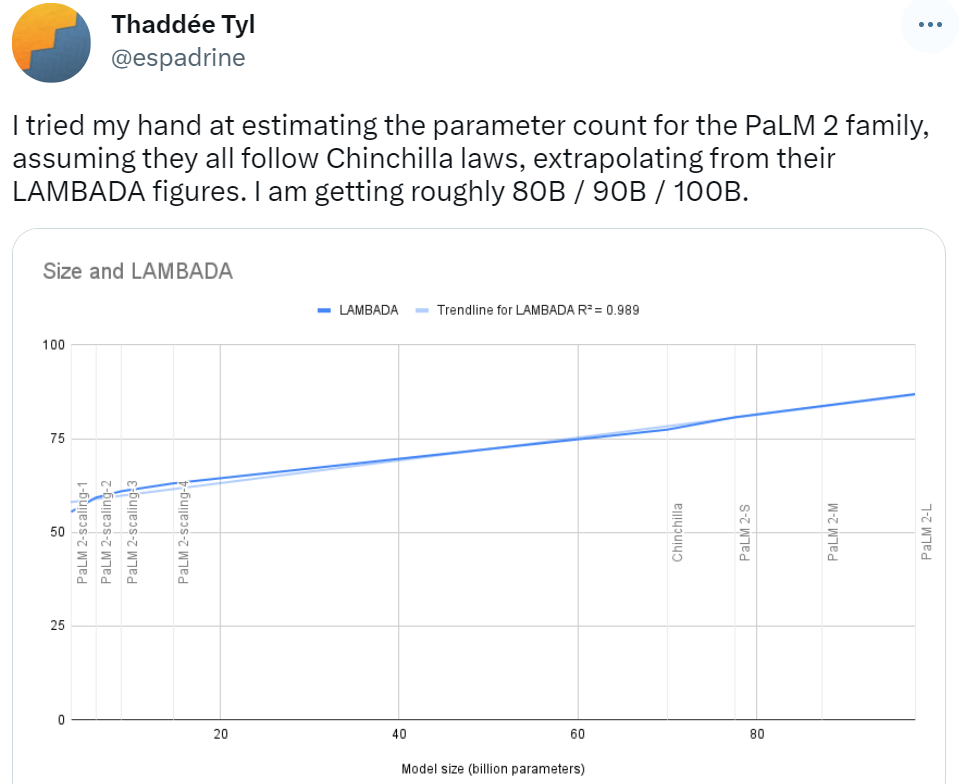
Zu Beginn der offiziellen Ankündigung von PaLM 2 sagten einige Netizens die Parametermenge basierend auf dem Chinchilla-Gesetz voraus. Sie sagten voraus, dass die Parameterergebnisse der PaLM 2-Modellfamilie zwischen 80B / 90B / 100B liegen. was sich von dem unterscheidet, was dieses Mal enthüllt wurde, liegt noch weit zurück.
Jemand hat auch eine Welle von Vorhersagen über die Trainingskosten von PaLM 2 gemacht. Basierend auf der Entwicklung großer Modelle in der Vergangenheit sagte dieser Internetnutzer, dass der Bau von PaLM 2 100 Millionen US-Dollar kosten wird.

PaLM 2-Parameter sind durchgesickert, Sie können versuchen, Bard zu erraten, dieser Internetnutzer sagte:
Angesichts des Durchsickerns der Anzahl der PaLM 2-Token kommen Internetnutzer nicht umhin, sich zu fragen: Wie viele Token werden für einen großen Wendepunkt vor der Ankunft von AGI nötig sein?

Das obige ist der detaillierte Inhalt vonMit 3,6 Billionen Token und 340 Milliarden Parametern wurden Details von Googles großem Modell PaLM 2 offengelegt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr