
Heim >Technologie-Peripheriegeräte >KI >Das Erstellen von Videos ist so einfach, geben Sie einfach einen Hinweis, und Sie können es auch online ausprobieren
Das Erstellen von Videos ist so einfach, geben Sie einfach einen Hinweis, und Sie können es auch online ausprobieren

- 王林nach vorne
- 2023-05-20 17:16:191687Durchsuche
Sie geben Text ein und lassen die KI ein Video erstellen. Diese Idee erschien bisher nur in der Fantasie der Menschen. Mit der Entwicklung der Technologie wurde diese Funktion nun realisiert.
In den letzten Jahren hat generative künstliche Intelligenz im Bereich Computer Vision große Aufmerksamkeit erregt. Mit dem Aufkommen von Diffusionsmodellen ist die Generierung hochwertiger Bilder aus Textaufforderungen, d. h. die Text-zu-Bild-Synthese, sehr beliebt und erfolgreich geworden.
Neueste Forschungsversuche versuchen, das Text-zu-Bild-Diffusionsmodell erfolgreich auf die Aufgabe der Text-zu-Video-Generierung und -Bearbeitung zu erweitern, indem es im Videobereich wiederverwendet wird. Obwohl solche Methoden vielversprechende Ergebnisse erzielt haben, erfordern die meisten von ihnen eine umfangreiche Schulung unter Verwendung großer Mengen gekennzeichneter Daten, was für viele Benutzer möglicherweise zu teuer ist.
Um die Videoerzeugung kostengünstiger zu machen, hat Tune-A-Video letztes Jahr einen Mechanismus zur Anwendung des Stable Diffusion (SD)-Modells auf den Videobereich eingeführt. Es muss nur ein Video angepasst werden, was den Schulungsaufwand erheblich reduziert. Obwohl dies wesentlich effizienter ist als frühere Methoden, bedarf es dennoch einer Optimierung. Darüber hinaus sind die Generierungsfunktionen von Tune-A-Video auf textgesteuerte Videobearbeitungsanwendungen beschränkt, und das Zusammenstellen von Videos von Grund auf übersteigt seine Möglichkeiten.
In diesem Artikel haben Forscher von Picsart AI Resarch (PAIR), der University of Texas in Austin und anderen Institutionen einen Schritt nach vorne bei dem neuen Problem der Text-zu-Video-Synthese im Null-Aufnahme-Modus und ohne Training gemacht. die Videos basierend auf Textaufforderungen ohne jegliche Optimierung oder Feinabstimmung generiert.

- Papieradresse: https://arxiv.org/pdf/2303.13439.pdf
- Projektadresse: https://github.com/Picsart-AI- Research/Text2Video-Zero
- Testadresse: https://huggingface.co/spaces/PAIR/Text2Video-Zero
Mal sehen, wie es funktioniert. Zum Beispiel surft ein Panda; ein Bär tanzt auf dem Times Square:

Die Forschung kann auch Aktionen basierend auf dem Ziel generieren:

Zusätzlich Kantenerkennung kann durchgeführt werden:

Ein Schlüsselkonzept des in diesem Artikel vorgeschlagenen Ansatzes besteht darin, ein vorab trainiertes Text-zu-Bild-Modell (z. B. Stable Diffusion) zu modifizieren, um es mit zeitkonsistenter Generierung anzureichern . Indem wir auf bereits trainierten Text-zu-Bild-Modellen aufbauen, nutzt unser Ansatz deren hervorragende Bilderzeugungsqualität und verbessert ihre Anwendbarkeit auf den Videobereich, ohne dass zusätzliches Training erforderlich ist.
Um die zeitliche Konsistenz zu verbessern, schlägt dieses Papier zwei innovative Modifikationen vor: (1) zunächst die latente Kodierung des generierten Frames mit Bewegungsinformationen anreichern, um die globale Szene und den Hintergrund zeitlich konsistent zu halten; (2) dann ein Kreuz verwenden; -Frame-Aufmerksamkeitsmechanismus, um den Kontext, das Erscheinungsbild und die Identität von Vordergrundobjekten während der gesamten Sequenz zu bewahren. Experimente zeigen, dass diese einfachen Modifikationen qualitativ hochwertige und zeitlich konsistente Videos erzeugen können (siehe Abbildung 1).

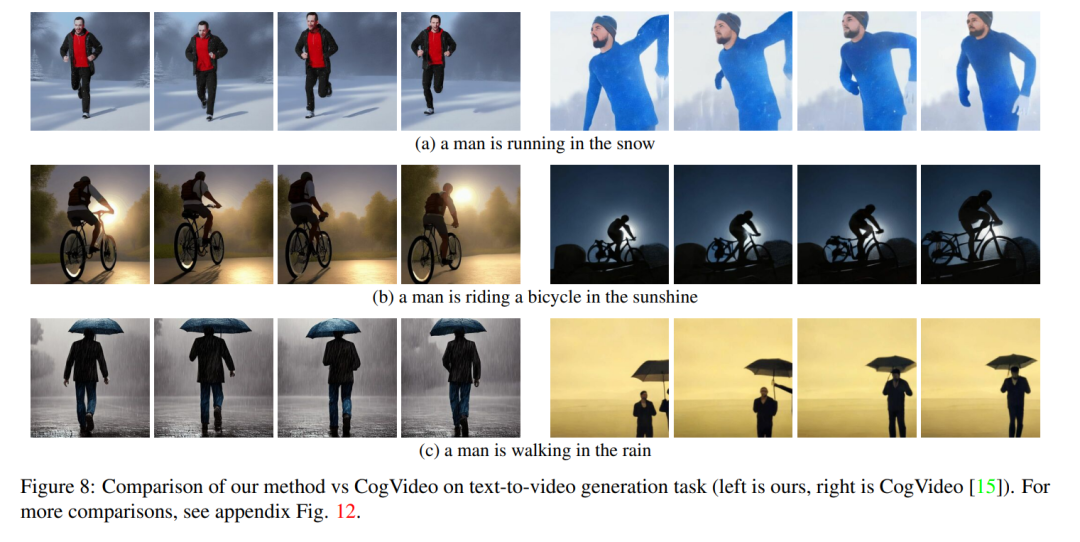
Obwohl die Arbeit anderer Leute auf großen Videodaten trainiert wird, erzielt unsere Methode eine ähnliche und manchmal bessere Leistung (dargestellt in den Abbildungen 8, 9).
# 🎜 🎜#
Die Methode in diesem Artikel ist nicht auf die Text-zu-Video-Synthese beschränkt, sondern ist auch auf bedingte Verfahren anwendbar (siehe Abbildungen 6 und 5). ) und die Erzeugung spezialisierter Videos (siehe Abbildung 7) sowie die anweisungsgeführte Videobearbeitung können als Video Instruct-Pix2Pix bezeichnet werden, das von Instruct-Pix2Pix gesteuert wird (siehe Abbildung 9).

# 🎜 🎜#
In diesem Artikel wird die Text-zu-Bild-Synthesefunktion von Stable Diffusion (SD) genutzt, um die Text-zu-Video-Aufgabe im Nulldurchgang zu bewältigen -Shot-Situationen. Für die Anforderungen der Videogenerierung und nicht der Bildgenerierung sollte sich SD auf den Betrieb der zugrunde liegenden Codesequenzen konzentrieren. Der naive Ansatz besteht darin, m potenzielle Codes unabhängig aus einer Standard-Gauß-Verteilung abzutasten, d ( 0, I) und wenden DDIM-Sampling an, um den entsprechenden Tensor #
zu erhalten, wobei k = 1,...,m, und werden dann dekodiert, um die generierte Videosequenz # zu erhalten 🎜🎜#
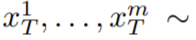
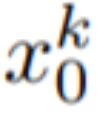
Um dieses Problem zu lösen, empfiehlt dieser Artikel die folgenden zwei Methoden : (i) Bewegungsdynamik zwischen latenten Kodierungen einführen, um die zeitliche Konsistenz der globalen Szene aufrechtzuerhalten; (ii) einen rahmenübergreifenden Aufmerksamkeitsmechanismus verwenden, um das Erscheinungsbild und die Identität von Vordergrundobjekten zu bewahren; Jede Komponente der in diesem Dokument verwendeten Methode wird im Folgenden ausführlich beschrieben. Eine Übersicht über die Methode finden Sie in Abbildung 2.
Experiment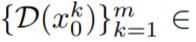 Beachten Sie, dass dieser Artikel zur Vereinfachung der Notation die gesamte mögliche Codesequenz wie folgt darstellt:
Beachten Sie, dass dieser Artikel zur Vereinfachung der Notation die gesamte mögliche Codesequenz wie folgt darstellt: 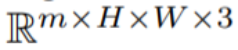

Bei Text-to-Video lässt sich beobachten, dass qualitativ hochwertige Videos generiert werden, die gut auf die Textansagen abgestimmt sind (siehe Abbildung 3). Beispielsweise wird ein Panda dazu gezeichnet, auf natürliche Weise auf der Straße zu laufen. Ebenso wurden unter Verwendung zusätzlicher Kanten- oder Posenführung (siehe Abbildungen 5, 6 und 7) hochwertige Videos mit passenden Eingabeaufforderungen und Anleitungen generiert, die eine gute zeitliche Konsistenz und Identitätswahrung zeigten. #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜# Im Fall von Abbildung 1) das generierte Video hat eine hohe Wiedergabetreue im Verhältnis zum Eingangsvideo und befolgt dabei strikt die Anweisungen. Vergleich mit Baseline Dieser Artikel vergleicht seine Methode mit zwei Öffentlich verfügbare Basislinien zum Vergleich: CogVideo und Tune-A-Video. Da es sich bei CogVideo um eine Text-zu-Video-Methode handelt, wird sie in diesem Artikel in einem rein textgesteuerten Videosyntheseszenario unter Verwendung von Video Instruct-Pix2Pix mit Tune-A-Video verglichen. Für den quantitativen Vergleich verwendet dieser Artikel den CLIP-Score zur Bewertung des Modells, der den Grad der Videotextausrichtung darstellt. Durch zufälliges Abrufen von 25 von CogVideo generierten Videos und Synthetisieren der entsprechenden Videos mit denselben Tipps gemäß der Methode in diesem Artikel. Die CLIP-Werte unserer Methode und von CogVideo liegen bei 31,19 bzw. 29,63. Daher ist unsere Methode etwas besser als CogVideo, obwohl letztere 9,4 Milliarden Parameter hat und umfangreiches Training für Videos erfordert. Abbildung 8 zeigt mehrere Ergebnisse der in diesem Dokument vorgeschlagenen Methode und bietet einen qualitativen Vergleich mit CogVideo. Beide Methoden weisen über die gesamte Sequenz hinweg eine gute zeitliche Konsistenz auf und bewahren sowohl die Identität des Objekts als auch seinen Kontext. Unsere Methode zeigt bessere Möglichkeiten zur Text-Video-Ausrichtung. Beispielsweise generiert unsere Methode in Abbildung 8 (b) korrekt ein Video einer Person, die in der Sonne Fahrrad fährt, während CogVideo den Hintergrund auf Mondlicht setzt. Auch in Abbildung 8 (a) zeigt unsere Methode korrekt eine im Schnee laufende Person, während der Schnee und die laufende Person in dem von CogVideo generierten Video nicht deutlich sichtbar sind. Video Die qualitativen Ergebnisse von Instruct-Pix2Pix und der visuelle Vergleich mit Instruct-Pix2Pix und Tune-AVideo pro Frame sind in Abbildung 9 dargestellt. Während Instruct-Pix2Pix eine gute Bearbeitungsleistung pro Frame zeigt, mangelt es ihm an zeitlicher Konsistenz. Dies macht sich besonders bei Videos mit Skifahrern bemerkbar, in denen Schnee und Himmel in unterschiedlichen Stilen und Farben gezeichnet sind. Diese Probleme wurden mit der Video Instruct-Pix2Pix-Methode gelöst, was zu einer zeitlich konsistenten Videobearbeitung während der gesamten Sequenz führte. Obwohl Tune-A-Video im Vergleich zur Methode in diesem Artikel eine zeitkonsistente Videogenerierung erstellt, entspricht sie weniger der Anleitung und ist schwierig zu erstellen. Lokal bearbeitet , und die Details der Eingabesequenz gehen verloren. Dies wird deutlich, wenn man sich den Schnitt des Videos des Tänzers ansieht, der in Abbildung 9 links dargestellt ist. Im Vergleich zu Tune-A-Video stellt unsere Methode das gesamte Outfit heller dar, während der Hintergrund besser erhalten bleibt, z. B. die Wand hinter dem Tänzer, die nahezu unverändert bleibt. Tune-A-Video hat eine stark deformierte Wand bemalt. Darüber hinaus entspricht unsere Methode den Eingabedetails besser. Im Vergleich zu Tune-A-Video zeichnet Video Instruction-Pix2Pix Tänzer anhand der bereitgestellten Posen (Abbildung 9 links) und zeigt alle im Eingabevideo erscheinenden Skifahrer an. Wie im letzten Bild auf der rechten Seite von Abbildung 9 gezeigt). Alle oben genannten Schwächen von Tune-A-Video sind auch in den Abbildungen 23, 24 zu beobachten.

Das obige ist der detaillierte Inhalt vonDas Erstellen von Videos ist so einfach, geben Sie einfach einen Hinweis, und Sie können es auch online ausprobieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr