
Heim >Technologie-Peripheriegeräte >KI >Auswahl der besten GPU für Deep Learning
Auswahl der besten GPU für Deep Learning

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-20 17:04:061844Durchsuche
Bei der Arbeit an maschinellen Lernprojekten, insbesondere wenn es um Deep Learning und neuronale Netze geht, ist es besser, mit einer GPU statt mit einer CPU zu arbeiten, da selbst eine sehr einfache GPU eine CPU übertrifft, wenn es um neuronale Netze geht.

Aber welche GPU sollten Sie kaufen? In diesem Artikel werden die relevanten Faktoren zusammengefasst, die Sie berücksichtigen sollten, damit Sie basierend auf Ihrem Budget und Ihren spezifischen Modellierungsanforderungen eine fundierte Entscheidung treffen können.
Warum eignet sich die GPU besser für maschinelles Lernen als die CPU?
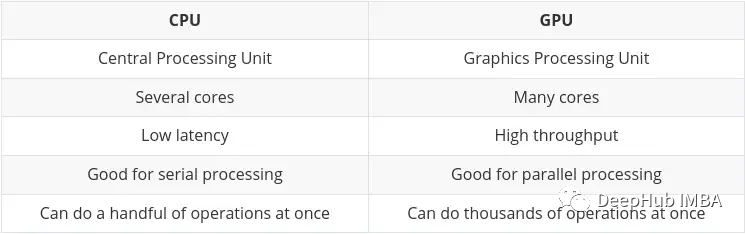
CPU (Central Processing Unit) ist die Hauptaufgabe des Computers. Sie ist sehr flexibel und muss nicht nur Anweisungen von verschiedenen Programmen und Hardware verarbeiten, sondern stellt auch bestimmte Anforderungen an die Verarbeitungsgeschwindigkeit. Um in dieser Multitasking-Umgebung eine gute Leistung zu erbringen, verfügt eine CPU über eine kleine Anzahl flexibler und schneller Verarbeitungseinheiten (auch Kerne genannt).
GPU (Graphics Processing Unit) GPU ist nicht so flexibel, wenn es um Multitasking geht. Aber es kann große Mengen komplexer mathematischer Berechnungen parallel durchführen. Dies wird durch eine größere Anzahl einfacher Kerne (Tausende bis Zehntausende) erreicht, die viele einfache Berechnungen gleichzeitig durchführen können.
Die Anforderung, mehrere Berechnungen parallel durchzuführen, ist ideal für:
- Grafik-Rendering – sich bewegende Grafikobjekte müssen ihre Flugbahnen ständig berechnen, was eine große Anzahl paralleler mathematischer Berechnungen erfordert, die ständig wiederholt werden.
- Maschinelles und tiefes Lernen – Eine große Anzahl von Matrix-/Tensorberechnungen kann die GPU parallel verarbeiten.
- Jede Art mathematischer Berechnung kann aufgeteilt werden, um parallel ausgeführt zu werden.
Die wichtigsten Unterschiede zwischen CPUs und GPUs wurden auf Nvidias eigenem Blog zusammengefasst:
Tensor Processing Unit (TPU)
Mit der Entwicklung von künstlicher Intelligenz und maschinellem/tiefem Lernen gibt es jetzt mehr spezialisierte Verarbeitungskerne , sogenannte Tensorkerne. Sie sind schneller und effizienter bei der Durchführung von Tensor-/Matrixberechnungen. Denn der Datentyp, mit dem wir uns beim maschinellen/tiefen Lernen befassen, sind Tensoren.
Obwohl es dedizierte TPUs gibt, enthalten einige der neuesten GPUs auch viele Tensorkerne, die wir später zusammenfassen.
Nvidia vs. AMD
Dies wird ein ziemlich kurzer Abschnitt sein, da die Antwort auf diese Frage definitiv Nvidia lautet.
Während es möglich ist, AMDs GPUs für maschinelles/tiefes Lernen zu verwenden, waren die GPUs von Nvidia zum Zeitpunkt des Verfassens dieses Artikels höher Kompatibilität und allgemein bessere Integration in Tools wie TensorFlow und PyTorch (z. B. ist die AMD-GPU-Unterstützung von PyTorch derzeit nur unter Linux verfügbar).
Für die Verwendung der AMD-GPU sind zusätzliche Tools (ROCm) erforderlich, die etwas mehr Arbeit erfordern und die Version möglicherweise nicht schnell aktualisiert wird. Diese Situation könnte sich in Zukunft verbessern, aber vorerst ist es besser, bei Nvidia zu bleiben.
Hauptmerkmale der GPU-Auswahl
Die Auswahl einer GPU, die für maschinelle Lernaufgaben geeignet ist und in Ihr Budget passt, hängt im Wesentlichen von vier Hauptfaktoren ab:
- Wie viel Speicher verfügt die GPU?
- Wie viele Verfügt die GPU über CUDA und/oder CUDA?
- Welche Chip-Architektur verwendet die Karte?
- Diese Aspekte werden im Folgenden einzeln besprochen, in der Hoffnung, Ihnen ein besseres Verständnis dafür zu vermitteln, was für Sie wichtig ist.
GPU-Speicher
Die Antwort lautet: Je mehr, desto besser!
Es hängt wirklich von Ihrer Aufgabe ab und davon, wie groß diese Modelle sind. Wenn Sie beispielsweise Bilder, Videos oder Audio verarbeiten, verarbeiten Sie per Definition eine ziemlich große Datenmenge, und der GPU-RAM ist ein sehr wichtiger Gesichtspunkt.
Es gibt immer Möglichkeiten, das Problem des unzureichenden Speichers zu lösen (z. B. durch Reduzierung der Stapelgröße). Dadurch wird jedoch Schulungszeit verschwendet, sodass die Anforderungen gut ausbalanciert werden müssen.
Aus Erfahrung empfehle ich Folgendes:
4 GB: Ich denke, das ist das absolute Minimum, und solange Sie es nicht mit übermäßig komplexen Modellen oder großen Bildern, Videos oder Audiodateien zu tun haben, reicht dies aus Funktioniert in den meisten Fällen, reicht aber für den täglichen Gebrauch nicht aus. Wenn Sie gerade erst anfangen und es ausprobieren möchten, ohne aufs Ganze zu gehen, dann fangen Sie damit an- 8 GB: Dies ist ein toller Start für das tägliche Lernen und kann die meisten Aufgaben erledigen, ohne das RAM-Limit zu überschreiten, aber es ist besser, es zu verwenden mehr Bei komplexen Bild-, Video- oder Audiomodellen können Probleme auftreten.
- 12GB: Ich denke, das ist die grundlegendste Voraussetzung für wissenschaftliche Forschung. Kann mit den meisten größeren Modellen umgehen, auch mit solchen, die mit Bildern, Video oder Audio arbeiten.
- 12 GB+: Je mehr desto besser, Sie können größere Datensätze und größere Stapelgrößen verarbeiten. Ab 12 GB beginnen die Preise wirklich zu steigen.
- Generell gilt: Bei gleichen Kosten ist es besser, eine „langsamere“ Karte mit mehr Speicher zu wählen. Bedenken Sie, dass der Vorteil von GPUs in einem hohen Durchsatz liegt, der stark vom verfügbaren RAM abhängt, um Daten über die GPU zu übertragen.
CUDA-Kerne und Tensor-Kerne
Das ist eigentlich ganz einfach, je mehr, desto besser.
Berücksichtigen Sie zuerst RAM, dann CUDA. Für maschinelles/tiefes Lernen sind Tensorkerne besser (schneller, effizienter) als CUDA-Kerne. Dies liegt daran, dass sie genau für die Berechnungen ausgelegt sind, die im Bereich des maschinellen/tiefen Lernens erforderlich sind.
Aber das spielt keine Rolle, denn CUDA-Kernel sind bereits schnell genug. Wenn Sie eine Karte bekommen können, die Tensor-Kerne enthält, ist das ein schönes Plus, aber lassen Sie sich nicht zu sehr darauf ein.
Sie werden später noch oft sehen, dass „CUDA“ erwähnt wird. Fassen wir es zunächst zusammen:
CUDA-Kerne – das sind die physischen Prozessoren auf der Grafikkarte, normalerweise sind es Tausende davon, 4090 sind bereits 16.000.
CUDA 11 – Zahlen können sich ändern, dies bezieht sich jedoch auf die installierte Software/Treiber, damit die Grafikkarte ordnungsgemäß funktioniert. NV veröffentlicht regelmäßig neue Versionen und kann wie jede andere Software installiert und aktualisiert werden.
CUDA Algebra (oder Rechenleistung) – Dies beschreibt den Codenamen der Grafikkarte in ihrer neueren Version. Dies ist fest in der Hardware verankert und kann daher nur durch ein Upgrade auf eine neue Karte geändert werden. Es wird durch Nummern und einen Codenamen unterschieden. Beispiel: 3. x[Kepler],5. x[Maxwell], 6. x [Pascal], 7. x[Turing] und 8. x(Ampere).
Chip-Architektur
Das ist tatsächlich wichtiger als Sie denken. Wir reden hier nicht über AMD, ich habe nur „Altgelb“ in meinen Augen.
Wir haben oben bereits erwähnt, dass die Karten der 30er-Serie Ampere-Architektur sind und die neuesten Karten der 40er-Serie Ada Lovelace sind. Normalerweise benennt Huang die Architektur nach einem berühmten Wissenschaftler und Mathematiker. Diesmal wählte er Ada Lovelace, die Tochter des berühmten britischen Dichters Byron, der Mathematikerin und Begründerin von Computerprogrammen, die die Konzepte von Schleifen und Unterprogrammen begründete.
Um die Rechenleistung der Karte zu verstehen, müssen wir zwei Aspekte verstehen:
- Signifikante Funktionsverbesserungen
- Eine wichtige Funktion hierbei ist das Training mit gemischter Präzision:
Verwenden Sie Zahlen mit einer Genauigkeit, die niedriger als 32-Bit-Gleitkomma ist Zahlen Das Format hat viele Vorteile. Erstens benötigen sie weniger Speicher, was das Training und den Einsatz größerer neuronaler Netze ermöglicht. Zweitens benötigen sie weniger Speicherbandbreite und beschleunigen so die Datenübertragungsvorgänge. Dritte mathematische Operationen laufen schneller und mit geringerer Präzision, insbesondere auf GPUs mit Tensor-Kernen. Beim gemischten Präzisionstraining werden alle diese Vorteile erreicht, ohne dass dabei die aufgabenspezifische Genauigkeit im Vergleich zum vollständigen Präzisionstraining verloren geht. Dies geschieht durch die Identifizierung von Schritten, die volle Präzision erfordern, und die Verwendung von 32-Bit-Gleitkomma nur für diese Schritte und 16-Bit-Gleitkomma überall sonst.
Hier ist das offizielle Nvidia-Dokument. Wenn Sie interessiert sind, können Sie einen Blick darauf werfen:
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html
Wenn Ihre GPU Hat 7.x (Turing) oder eine höhere Architektur, ist hybrides Präzisionstraining möglich. Das bedeutet RTX 20-Serie oder höher auf dem Desktop oder „T“- oder „A“-Serie auf dem Server.
Der Hauptgrund für die Vorteile des gemischten Präzisionstrainings besteht darin, dass die GPU des Tensor Core das gemischte Präzisionstraining beschleunigt. Wenn nicht, spart die Verwendung von FP16 auch größere Stapelgrößen, was indirekt die Trainingsgeschwindigkeit verbessert .
Wird es veraltet sein?
Wenn Sie besonders hohe Anforderungen an den Arbeitsspeicher haben, aber nicht genug Geld haben, um eine High-End-Karte zu kaufen, dann können Sie sich auf dem Gebrauchtmarkt für eine ältere GPU entscheiden. Das hat einen ziemlich großen Nachteil: Die Lebensdauer der Karte ist abgelaufen.
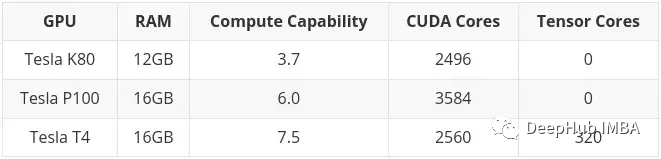
Ein typisches Beispiel ist Tesla K80, der über 4992 CUDA-Kerne und 24 GB RAM verfügt. Im Jahr 2014 kostete es etwa 7.000 US-Dollar. Der aktuelle Preis liegt zwischen 150 und 170 US-Dollar (der Preis für gesalzenen Fisch liegt bei etwa 600-700). Sie müssen sehr aufgeregt sein, einen so großen Speicher zu einem so kleinen Preis zu haben.
Aber es gibt ein sehr großes Problem. Die Computerarchitektur von K80 ist 3.7 (Kepler), die ab CUDA 11 nicht mehr unterstützt wird (die aktuelle CUDA-Version ist 11.7). Das bedeutet, dass die Karte abgelaufen ist, weshalb sie so günstig verkauft wird.
Überprüfen Sie daher bei der Auswahl einer gebrauchten Karte unbedingt, ob diese die neueste Treiber- und CUDA-Version unterstützt. Das ist das Wichtigste.
High-End-Gaming-Karten vs. Workstation-/Server-Karten
Lao Huang hat die Karte grundsätzlich in zwei Teile geteilt. Consumer-Grafikkarten und Workstation-/Server-Grafikkarten (d. h. professionelle Grafikkarten).
Es gibt einen deutlichen Unterschied zwischen den beiden Teilen, denn bei gleichen Spezifikationen (RAM, CUDA-Kerne, Architektur) sind Consumer-Grafikkarten in der Regel günstiger. Aber professionelle Karten haben in der Regel eine bessere Qualität und einen geringeren Energieverbrauch (tatsächlich ist das Geräusch der Turbine ziemlich laut, was in einem Computerraum in Ordnung ist, aber zu Hause oder im Labor etwas laut ist).
Bei hochwertigen (sehr teuren) professionellen Karten stellen Sie möglicherweise fest, dass sie über viel RAM verfügen (z. B. RTX A6000 hat 48 GB, A100 hat 80 GB!). Dies liegt daran, dass sie in der Regel auf die professionellen Märkte 3D-Modellierung, Rendering und maschinelles/tiefes Lernen abzielen, die viel RAM benötigen. Auch hier gilt: Wenn Sie Geld haben, kaufen Sie einfach A100 (H100 ist eine neue Version von A100 und kann derzeit nicht bewertet werden)
Aber ich persönlich denke, dass wir uns für High-End-Spielekarten für Endverbraucher entscheiden sollten, denn wenn es Ihnen nicht an Geld mangelt Geld, du wirst diesen Artikel auch nicht lesen, oder?
Vorschläge auswählen
Am Ende mache ich also einige Vorschläge basierend auf Budget und Bedürfnissen. Ich habe es in drei Teile unterteilt:
- Niedriges Budget
- Mittleres Budget
- Hohes Budget
Hohes Budget berücksichtigt nichts anderes als High-End-Consumer-Grafikkarten. Nochmals: Wenn Sie Geld haben: Kaufen Sie A100 oder H100.
Dieser Artikel enthält Karten, die auf dem Gebrauchtmarkt gekauft wurden. Das liegt vor allem daran, dass ich glaube, dass Second Hand etwas ist, das man in Betracht ziehen sollte, wenn man über ein geringes Budget verfügt. Auch die Karten der Professional Desktop-Serie (T600, A2000 und A4000) sind hier enthalten, da ihre Konfigurationen teilweise etwas schlechter sind als vergleichbare Consumer-Grafikkarten, der Stromverbrauch jedoch deutlich besser ist.
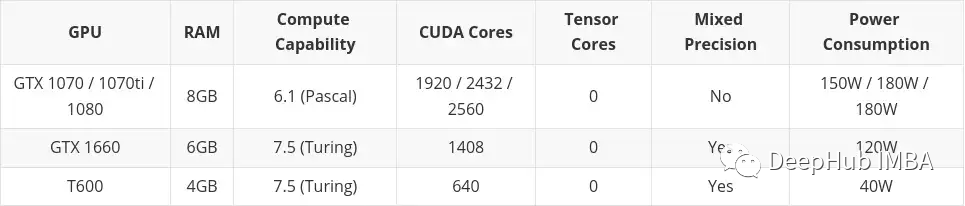
low budget
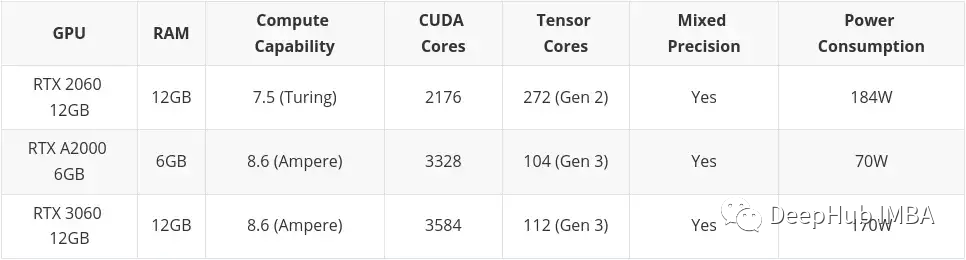
mittleres Budget
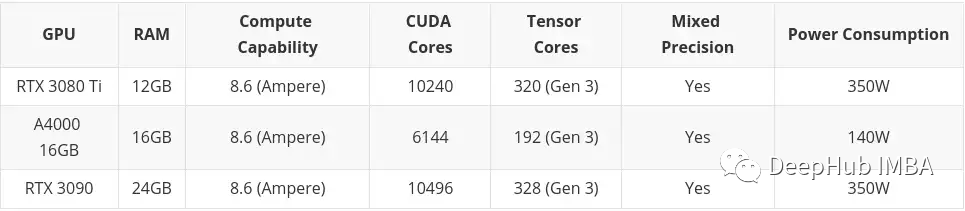
Wenn nicht Kaufen Sie es, ich werde es nicht kaufen, aber es wird morgen noch verfügbar sein Lassen Sie zweihundert fallen
Das obige ist der detaillierte Inhalt vonAuswahl der besten GPU für Deep Learning. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr