
Heim >Technologie-Peripheriegeräte >KI >Gehirn-Computer-Schnittstelle, Gehirnwellen und fMRT: KI beherrscht das Gedankenlesen
Gehirn-Computer-Schnittstelle, Gehirnwellen und fMRT: KI beherrscht das Gedankenlesen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-19 22:16:331533Durchsuche
Gedankenlesen ist eine der Superkräfte, die sich Menschen am meisten wünschen, und es muss auch die Superkraft sein, die sich die Menschen am wenigsten von anderen wünschen. Geben Sie einfach das Stichwort „Gedankenlesen“ in eine Suchmaschine ein und Sie werden eine große Anzahl verwandter Bücher, Videos und Tutorials finden, was zeigt, dass Menschen von dieser Fähigkeit besessen sind. Aber abgesehen von diesen psychologischen, verhaltensbezogenen oder mystischen Inhalten gibt es aus technischer Sicht Muster in den Signalen des menschlichen Gehirns, und daher ist Gedankenlesen (Analyse der Muster von Gehirnsignalen) möglich.
Mit der Entwicklung der KI-Technologie ist ihre Fähigkeit, Muster zu analysieren, immer ausgefeilter geworden und Gedankenlesen wird zur Realität.
Vor einigen Tagen sorgte ein von der University of Texas at Austin in Nature Neuroscience veröffentlichter Artikel für hitzige Diskussionen darüber, wie sich Gehirnsignale nicht-invasiv rekonstruieren lassen fortlaufende Sätze – Es überrascht nicht, dass dieses Modell auch das derzeit beliebte GPT-Sprachmodell verwendet. Lassen wir dieses neueste Ergebnis jedoch vorerst beiseite und schauen wir uns einige andere frühere Forschungsergebnisse zum Thema KI-Gedankenlesen an, um ein grobes Verständnis der aktuellen Forschungslandschaft zu diesem Thema zu erhalten.
Gedankenlesen lässt sich grob gesagt in zwei Kategorien einteilen: direktes Gedankenlesen und indirektes Gedankenlesen.
Indirektes Gedankenlesen bezieht sich auf das Ableiten der Gedanken und Gefühle einer Person anhand indirekter Merkmale. Zu diesen Merkmalen gehören Mimik, Körperhaltung, Körpertemperatur, Herzfrequenz, Atemrhythmus, Sprechgeschwindigkeit und Tonfall usw. In den letzten Jahren hat die auf Big Data basierende Deep-Learning-Technologie es der KI ermöglicht, Emotionen anhand von Gesichtsausdrücken recht genau zu identifizieren. Beispielsweise kann Deepface, eine leichtgewichtige Open-Source-Gesichtserkennungssoftwarebibliothek, mehrere Merkmale wie Alter, Geschlecht, Emotionen usw. umfassend analysieren Rennen. Erreichte eine Testsatzgenauigkeit von 97,53 %. Allerdings wird die Emotionsanalysetechnologie, die auf den oben genannten Merkmalen basiert, normalerweise nicht als Gedankenlesen angesehen. Schließlich kann der Mensch selbst die Emotionen anderer anhand seiner Ausdrücke und anderer Merkmale erraten. Daher wird in diesem Artikel auf die Technologie des Gedankenlesens eingegangen beschränkt sich auf das direkte Gedankenlesen.

Verwenden Sie die Deepfake-Bibliothek, um Ergebnisse der Gesichtsattributanalyse zu erhalten# 🎜🎜#
Direktes Gedankenlesen bezieht sich auf die direkte „Übersetzung“ von Gehirnsignalen in eine Form, die andere verstehen können, wie z. B. Text, Stimme und Bilder. Derzeit konzentrieren sich die Forscher auf drei Haupttypen von Gehirnsignalen: invasive Gehirn-Computer-Schnittstellen, Gehirnwellen und Neuroimaging.
Gedankenlesen basierend auf einer aufdringlichen Gehirn-Computer-SchnittstelleMan kann sagen, dass die aufdringliche Gehirn-Computer-Schnittstelle ein Standardmerkmal von Cyberpunk-Werken ist. Sie können es in vielen Filmen oder Spielen wie zum Beispiel „Cyberpunk 2077“ sehen. Die Grundidee besteht darin, die elektrischen Signale zu lesen, die zwischen Nervenzellen im oder in der Nähe des Gehirns oder Nervensystems übertragen werden. Invasiv gelesene Gehirnsignale sind im Allgemeinen genauer und weniger verrauscht als nicht-invasive Methoden.
Im Jahr 2021 schlugen Forscher der University of California, San Francisco, in der Arbeit „Neuroprothesis for Decoding Speech in a Paralyzed Person with Anarthria“ den Einsatz von KI vor, um Menschen zu helfen bei Sprachstörungen Kommunikation für Menschen mit Behinderungen. In dieser Studie handelte es sich bei der Versuchsperson um eine Person mit einer einarmigen Behinderung, die unartikuliert sprechen konnte. Bemerkenswert ist, dass ihre Experimente zur Erfassung des Signals ein Nervenimplantat verwendeten, das eine Kombination aus einem hochdichten kortikalen EEG-Elektrodenarray und einem transkutanen Verbinder nutzte. Dieser aufdringliche Ansatz führt natürlich zu einer höheren Genauigkeit – es wird eine maximale Genauigkeit von 98 % und eine mittlere Dekodierungsrate von 75 % erreicht, wobei das Modell mit Geschwindigkeiten von bis zu 18 Wörtern pro Minute dekodieren kann. Darüber hinaus verbessert die Anwendung von Sprachmodellen auch den Bedeutungsausdruck der Dekodierungsergebnisse erheblich, bei dem es sich nicht mehr nur um eine einfache Ansammlung von Zeichenfolgen handelt.
Später verbesserte das Team seine Methode im Nature Neuroscience-Artikel 2022 „Generalisierbare Rechtschreibung mithilfe einer Sprachneuroprothese bei einer Person mit schwerer Extremitäten- und Stimmparalyse“ weiter. Das System integriert das neue Sprachmodell GPT, wodurch die Leistung weiter verbessert wird. #? 🎜# Konkret ist der Workflow:
- a Zu Beginn des Satzbuchstabierversuchs versuchten die Teilnehmer, ein Wort lautlos auszusprechen und dabei den Buchstabierer bewusst zu aktivieren.
- b Neuronale Merkmale (hohe Gammaaktivität und niederfrequente Signale) werden während der Aufgabe in Echtzeit aus den aufgezeichneten kortikalen Daten extrahiert. Mikrofonsignale zeigen das Fehlen von Sprachsignalen während der Aufgabe an.
- c Spracherkennungsmodell, das aus einem rekurrenten neuronalen Netzwerk (RNN) und einer Schwellenwertoperation besteht. Seine Aufgabe besteht darin, die neuronalen Eigenschaften von Sprachausdrucksversuchen zu erkennen. Sobald der Sprechversuch des Probanden erkannt wird, wird der Rechtschreibvorgang eingeleitet.
- d Während des Buchstabierungsprozesses buchstabieren die Probanden ihre beabsichtigte Nachricht durch Buchstabendekodierungszyklen, die alle 2,5 Sekunden stattfinden. In jedem Zyklus konnten die Probanden einen Countdown sehen, und das Ende des Countdowns war der Starthinweis. Nachdem sie den Starthinweis erhalten hatten, versuchten die Probanden, lautlos das Codewort auszusprechen, das den gewünschten Buchstaben darstellte.
- e Beim Buchstabieren werden für alle Elektrodenkanäle hohe Gammaaktivität und niederfrequente Signale berechnet und nicht überlappenden Zeitfenstern von 2,5 Sekunden Länge zugeordnet.
- f Das RNN-basierte Buchstabenklassifizierungsmodell verarbeitet jedes neuronale Zeitfenster, um seine Wahrscheinlichkeit vorherzusagen, wann ein Teilnehmer jedes der 26 möglichen Codewörter lautlos sagen möchte oder versucht, einen Handbewegungsbefehl auszuführen.
- g Nachdem der Teilnehmer die Nachricht, die er ausdrücken möchte, buchstabiert hat, versucht er, seine rechte Hand zu drücken, um den Buchstabiervorgang zu beenden und den Satz zu beenden.
- h Das mit dem Handbewegungsbefehl verknüpfte neuronale Zeitfenster wird an das Klassifizierungsmodell übergeben.
- i Wenn der Klassifikator bestätigt, dass der Teilnehmer versucht hat, einen Handbewegungsbefehl zu verwenden, wird ein gültiger Satz mithilfe eines auf einem neuronalen Netzwerk basierenden Sprachmodells (DistilGPT-2) neu bewertet. Nach erneuter Bewertung wird der wahrscheinlichste Satz als endgültige Vorhersage verwendet.
Eine weitere Forschung zu implantierbaren Gehirn-Computer-Schnittstellen behauptet, erfolgreich eine effiziente Handschrifterkennung und Umwandlung von EEG-Signalen in Text erreicht zu haben. In der Nature-Studie „High-performance Brain-to-Text communication via handwriting“ ermöglichten Forscher der Stanford University gelähmten Menschen mit Rückenmarksverletzungen erfolgreich das Tippen mit einer Geschwindigkeit von 90 Zeichen pro Minute, und die ursprüngliche Online-Genauigkeit erreichte 94,1 %. Die Offline-Genauigkeit des Sprachmodells liegt bei über 99 %!
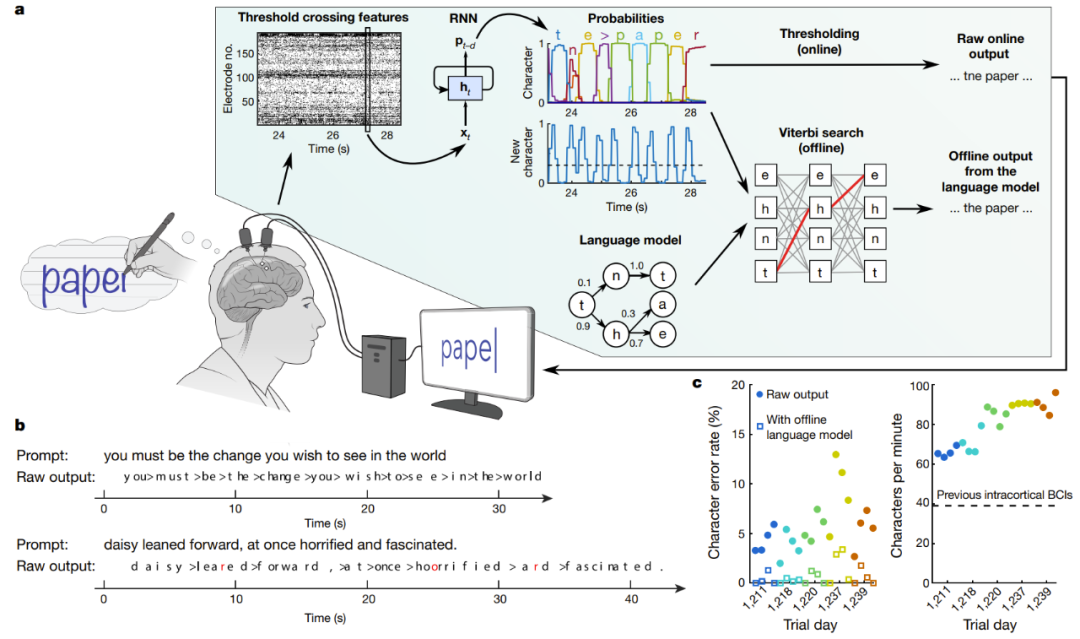
Echtzeitdekodierung von Gehirnsignalen von Personen, die versuchen, handschriftlich zu schreiben
a in der Abbildung ist ein schematisches Diagramm des Dekodierungsalgorithmus. Zunächst wird die neuronale Aktivität an jeder Elektrode zeitlich kombiniert und geglättet. Anschließend wird ein RNN verwendet, um die Zeitreihe der neuronalen Population in eine probabilistische Zeitreihe umzuwandeln, die die Wahrscheinlichkeit jedes Zeichens und die Wahrscheinlichkeit des Beginns eines neuen Zeichens beschreibt. Das RNN hat eine Ausgabeverzögerung (d) von 1 Sekunde, was ihm Zeit gibt, jedes Zeichen vollständig zu beobachten, bevor es seine Identität bestimmt. Legen Sie abschließend den Schwellenwert für die Zeichenwahrscheinlichkeit fest, um die „ursprüngliche Online-Ausgabe“ für die Echtzeitverwendung zu erhalten (wenn die Wahrscheinlichkeit eines neuen Zeichens zum Zeitpunkt t einen bestimmten Schwellenwert überschreitet, wird zum Zeitpunkt t + 0,3 Sekunden das wahrscheinlichste Zeichen angegeben). wird auf dem Bildschirm angezeigt). In einer retrospektiven Offline-Analyse kombinierten die Forscher Charakterwahrscheinlichkeiten mit einem Sprachmodell mit großem Vokabular, um den Text zu entschlüsseln, den die Teilnehmer am wahrscheinlichsten schrieben.
Gedankenlesen basierend auf Gehirnwellen
Basierend auf den Forschungsergebnissen der Gehirnforschung der letzten Jahrzehnte wissen wir, dass es bei der Signalübertragung von Nervenzellen im Gehirn winzige Ströme gibt, die subtile elektromagnetische Schwankungen erzeugen. Wenn viele Nervenzellen gleichzeitig arbeiten, können diese elektromagnetischen Schwankungen mit nicht-invasiven Präzisionsinstrumenten erfasst werden. Im Jahr 1875 beobachteten Wissenschaftler erstmals ein Phänomen fließender elektrischer Felder, bekannt als Gehirnwellen, bei Tieren. 1925 erfand Hans Berger das Elektroenzephalogramm (EEG) und zeichnete erstmals die elektrische Aktivität des menschlichen Gehirns auf. In den fast hundert Jahren seitdem hat sich die EEG-Technologie immer weiter verbessert, ihre Genauigkeit und Echtzeitleistung haben ein sehr hohes Niveau erreicht und wurden kommerziell eingesetzt. Jetzt können Sie sogar tragbare Geräte zur Erkennung und Analyse von Gehirnwellen kaufen.
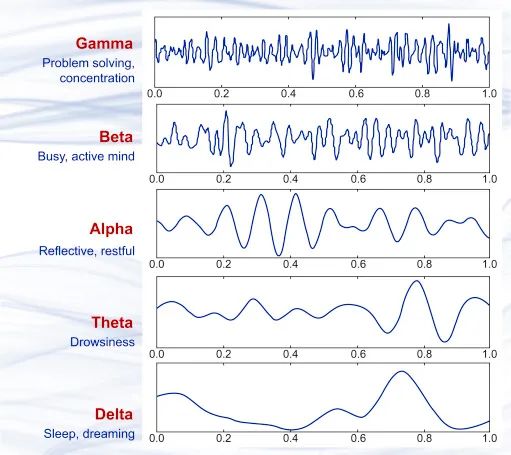
Mehrere verschiedene Beispiele für Gehirnwellenwellenformen, von oben nach unten: γ-Welle (über 35 Hz), β-Welle (12–35 Hz), α-Welle (8–12 Hz), Theta-Wellen ( 4–8 Hz) und Deltawellen (0,5–4 Hz) entsprechen in etwa verschiedenen Gehirnzuständen.
In Bezug auf die Analyse der Emotionen und Gedanken von Menschen anhand von Gehirnwellen ist die Analyse von P300-Wellen die gebräuchlichste Methode. Hierbei handelt es sich um Gehirnwellen, die vom Gehirn des Probanden etwa 300 Millisekunden nach dem Sehen eines Reizes erzeugt werden. Die Forschung zur Analyse von Gehirnwellen wird seit der Entdeckung von Gehirnwellen ununterbrochen fortgesetzt. Im Jahr 2001 schlug beispielsweise Lawrence Farwell, ein umstrittener Forscher auf diesem Gebiet, einen Algorithmus vor, der durch Auswertung von Gehirnwellenereignissen erkennen kann, ob eine Person etwas erlebt hat , und selbst wenn das Subjekt versuchen würde, es zu verbergen, wäre es vergeblich. Mit anderen Worten, es handelt sich hierbei um einen auf Gehirnwellen basierenden Lügendetektor.
Da Gehirnwellen selbst Signale mit Mustern sind, ist es selbstverständlich, neuronale Netze zur Analyse von Gehirnwellen zu verwenden. Im Folgenden stellen wir einige Methoden vor, die Wissenschaftler im Rahmen einiger Forschungen der letzten Jahre verwendet haben, um Gehirnwellensignale in Sprache, Text und Bilder zu übersetzen.
Im Jahr 2019 schlug ein russisches Forschungsteam ein visuelles Gehirn-Computer-Schnittstellensystem (BCI) vor, das Bilder basierend auf Gehirnwellen rekonstruieren kann. Die Forschungsidee ist sehr einfach: Merkmale aus Gehirnwellensignalen zu extrahieren, dann Merkmalsvektoren zu extrahieren, sie dann abzubilden, um die Position der Merkmale im verborgenen Raum zu finden, und schließlich das Bild zu dekodieren und zu rekonstruieren. Darunter ist der Bilddecoder Teil eines Bild-zu-Bild-Faltungs-Autoencoder-Modells, das 1 vollständig verbundene Eingabeschicht enthält, gefolgt von 5 Entfaltungsmodulen. Jedes Modul besteht aus 1 Entfaltungsschicht und besteht aus ReLU-Aktivierungen, während die Aktivierung von Das letzte Modul ist die hyperbolische Tangens-Aktivierungsschicht.
Eine weitere wichtige Komponente dieses Modells ist der EEG-Feature-Mapper, dessen Funktion darin besteht, Daten aus der EEG-Feature-Domäne in die Hidden-Space-Domäne des Bilddecoders zu übersetzen. Das Team verwendete LSTM als wiederkehrende Einheit im Modell und nutzte einen Aufmerksamkeitsmechanismus zur weiteren Verfeinerung. Seine Verlustfunktion besteht darin, den mittleren quadratischen Fehler zwischen der Merkmalsdarstellung des EEG und dem Bild zu minimieren. Einzelheiten finden Sie in ihrem Artikel „Natürliche Bildrekonstruktion aus Gehirnwellen: ein neuartiges visuelles BCI-System mit nativem Feedback“.
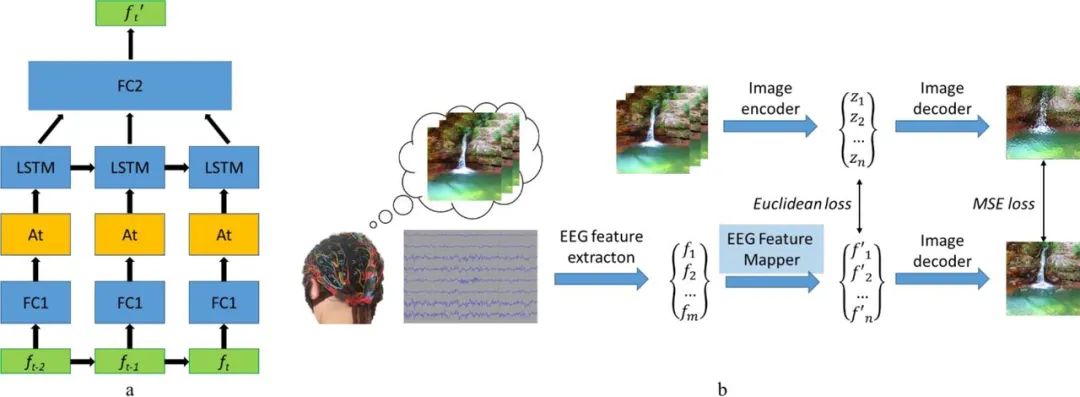
Modellstruktur (a) und Trainingsroutine (b) des EEG-Feature-Mappers
Unten sind einige Beispielergebnisse aufgeführt. Es ist ersichtlich, dass es einen signifikanten Unterschied zwischen dem rekonstruierten Bild gibt und die ursprüngliche Bildassoziation.

Das vom Subjekt gesehene Originalbild (links von jedem Bildpaar) und das aus den Gehirnwellen des Subjekts rekonstruierte Bild (rechts von jedem Bildpaar)
2022, Meta KI In der Arbeit „Decoding Speech from Non-invasive Brain Recordings“ schlug das Team eine neuronale Netzwerkarchitektur vor, die Sprachsignale aus Elektroenzephalographie- (EEG) oder Magnetenzephalographie- (MEG) Signalen dekodieren kann.
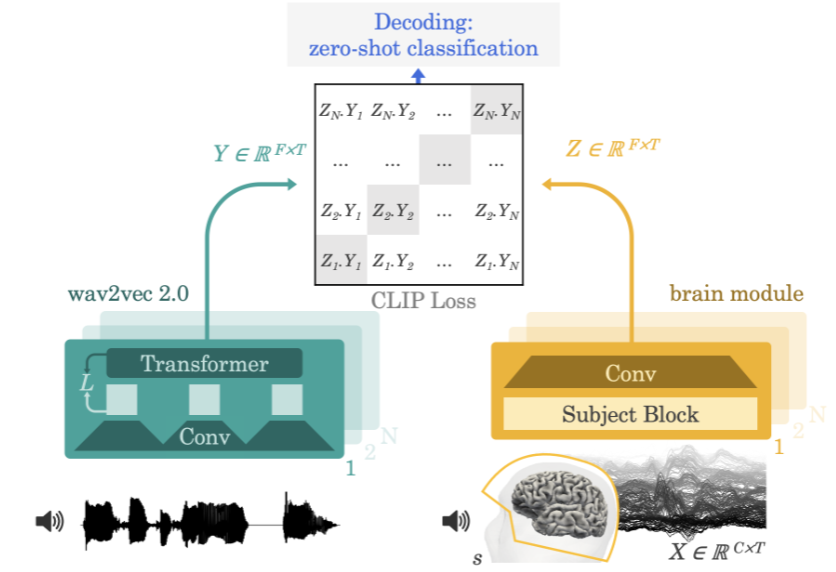
Methode des Meta-KI-Teams
Der Ansatz des Teams besteht darin, Versuchsteilnehmer Geschichten oder Sätze anhören zu lassen, während sie eine Elektroenzephalographie oder Magnetenzephalographie ihrer Gehirnaktivität aufzeichnen. Dazu extrahiert das Modell zunächst eine tiefe kontextbezogene Darstellung des 3-Sekunden-Sprachsignals (Y) durch ein vorab trainiertes selbstüberwachtes Modell (wav2vec 2.0) und lernt außerdem eine Darstellung der Gehirnaktivität in den entsprechenden ausgerichteten 3 -zweites Fenster (X) (Z). Die Darstellung Z wird durch ein tiefes Faltungsnetzwerk gegeben. Während der Auswertung fütterten die Forscher das Modell mit den verbleibenden Sätzen und berechneten jedes 3-Sekunden-Sprachsegment basierend auf jeder Gehirndarstellung. Dadurch kann dieser Dekodierungsprozess Zero-Shot sein, sodass das Modell Audioclips vorhersagen kann, die nicht im Trainingssatz enthalten sind.
Gedankenlesen basierend auf Neuroimaging
Wissenschaftler können auch eine Technologie namens funktionelle Magnetresonanztomographie (fMRT) verwenden, um die Gehirnaktivität zu verstehen. Bei der Anfang der 1990er Jahre entwickelten Technologie wird der Blutfluss im Gehirn mittels Magnetresonanztomographie untersucht, um die Gehirnaktivität zu erkennen. Die Technologie kann aufdecken, ob bestimmte Funktionsbereiche im Gehirn aktiv sind.
Was meinen wir, wenn wir sagen, dass ein bestimmter Gehirnbereich „aktiver“ ist? Wie erkennt fMRT diese Aktivität?
Wenn Neuronen in einem Gehirnbereich beginnen, mehr elektrische Signale als zuvor auszusenden, sagen wir, dass dieser Gehirnbereich aktiver ist. Wenn beispielsweise ein bestimmter Gehirnbereich aktiver wird, wenn Sie Ihr Bein heben, kann man davon ausgehen, dass dieser Bereich des Gehirns für die Steuerung des Beinhebens verantwortlich ist.
fMRT erkennt diese elektrische Aktivität durch Messung des Sauerstoffgehalts im Blut. Dies wird als Blutsauerstoffspiegel-abhängige Reaktion (BOLD) bezeichnet. Die Funktionsweise besteht darin, dass Neuronen, wenn sie aktiver sind, mehr Sauerstoff aus den roten Blutkörperchen benötigen. Dazu werden die umliegenden Blutgefäße erweitert, damit mehr Blut durchfließen kann. Wenn also Neuronen aktiver sind, steigt der Sauerstoffgehalt. Mit Sauerstoff angereichertes Blut erzeugt weniger Feldstörungen als sauerstoffarmes Blut, wodurch das Signal des Neurons (das im Wesentlichen aus Wasserstoff im Wasser besteht) länger anhält. Wenn das Signal also länger anhält, weiß die fMRT, dass der Bereich mehr Sauerstoff hat, was bedeutet, dass er aktiver ist. Nach der Farbkodierung dieser Aktivität werden fMRT-Bilder erhalten.
Als nächstes werfen wir einen Blick auf die zuvor erwähnte Forschung zur Verwendung von GPT zur Rekonstruktion semantisch konsistenter kontinuierlicher Sätze „Semantische Rekonstruktion kontinuierlicher Sprache aus nicht-invasiven Gehirnaufzeichnungen“. Sie schlagen einen nicht-invasiven Decoder vor, der kontinuierliche natürliche Sprache basierend auf kortikalen Darstellungen der semantischen Bedeutung in fMRT-Aufzeichnungen rekonstruieren kann. Bei Vorlage neuer Gehirnaufzeichnungen war der Decoder in der Lage, verständliche Wortsequenzen zu erzeugen, die die Bedeutung der von den Probanden gehörten Sprache, der imaginären Sprache und sogar stiller Videos nachbildeten, was darauf hindeutet, dass ein einzelner Sprachdecoder für eine Reihe verschiedener semantischer Aufgaben verwendet werden könnte . Der Arbeitsablauf dieses Sprachdecoders ist wie folgt:
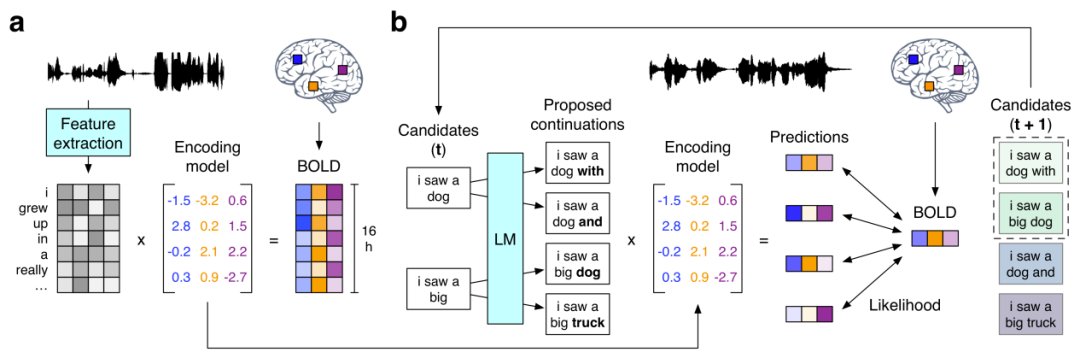
(a) BOLD fMRT-Antworten wurden aufgezeichnet, während drei Probanden 16 Stunden lang Erzählgeschichten hörten. Das System schätzt für jedes Subjekt ein Kodierungsmodell, das die Gehirnreaktionen vorhersagt, die durch die semantischen Merkmale der als Reize verwendeten Wörter hervorgerufen werden. (b) Um die Sprache anhand neuer Gehirnaufzeichnungen zu rekonstruieren, verwaltet der Decoder eine Reihe von Kandidatenwortsequenzen. Wenn ein neues Wort erkannt wird, schlägt ein Sprachmodell Kontinuität für jede Sequenz vor, und das Kodierungsmodell wird dann verwendet, um die Wahrscheinlichkeit der aufgezeichneten Gehirnreaktion für jede Kontinuitätsbedingung zu bewerten. Die wahrscheinlichste zusammenhängende Reihenfolge wird zuletzt beibehalten.
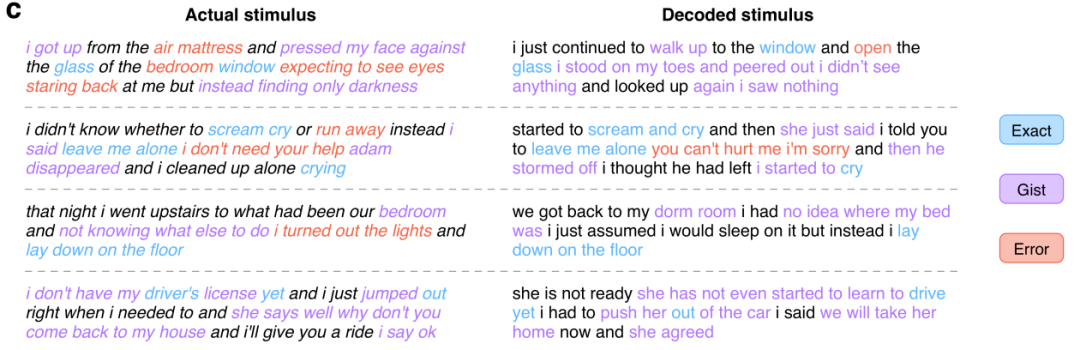
Unter diesen verwendet das Sprachmodell das GPT-Modell, das derzeit im Mittelpunkt der KI-Forschung steht. Die Forscher optimierten die GPT, die sie verwendeten, anhand eines großen Korpus von mehr als 200 Millionen Wörtern an Reddit-Kommentaren und 240 autobiografischen Geschichten aus The Moth Radio Hour und Modern Love. Das Modell wurde für 50 Epochen mit einer maximalen Kontextlänge von 100 trainiert. Nachfolgend sind einige experimentelle Ergebnisse aufgeführt:
Schließlich werfen wir einen Blick auf dieses CVPR 2023-Papier „Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding“. Forscher der National University of Singapore, der Chinese University of Hong Kong und der Stanford University behaupten, dass es dem von ihnen vorgeschlagenen MinD-Vis-Modell erstmals gelungen ist, fMRT-basierte Gehirnaktivitätssignale in Bilder zu dekodieren, und die rekonstruierten Bilder sind es nicht nur reich an Details, sondern enthalten auch genaue Semantik- und Bildmerkmale (Textur, Form usw.).
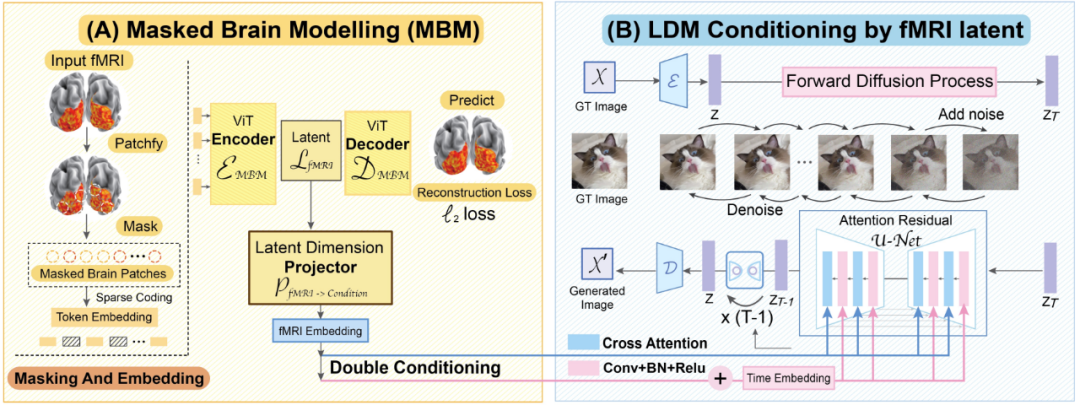
MinD-Vis-Workflow-Diagramm
Werfen wir einen Blick auf die beiden Arbeitsschritte von MinD-Vis. Wie in der Abbildung dargestellt, wird in Stufe A das Vortraining mit fMRT unter Verwendung von SC-MBM (Sparsely Coded Masked Brain Modeling) durchgeführt. Maskieren Sie dann die fMRIs nach dem Zufallsprinzip und tokenisieren Sie sie in große Einbettungen. Die Forscher trainierten einen Autoencoder, um maskierte Patches wiederherzustellen. In Stufe B wird es durch doppelte Konditionierung in das Latent Diffusion Model (LDM) integriert. Ein Latent-Dimension-Projektionsalgorithmus wurde verwendet, um den fMRI-Latentraum über zwei Pfade auf den LDM-bedingten Raum zu projizieren. Einer der Wege besteht darin, die Queraufmerksamkeitsköpfe in LDM direkt zu verbinden. Ein anderer Weg besteht darin, fMRT-Implikationen zur zeitlichen Einbettung hinzuzufügen.
Nach den experimentellen Ergebnissen in der Arbeit zu urteilen, ist die Gedankenlesefähigkeit dieses Modells tatsächlich sehr gut:

Das linke Bild ist das vom Motiv gesehene Originalbild, das rote Kästchen markiert die Rekonstruktionsergebnisse von MinD-Vis und die nächsten drei Spalten sind die Ergebnisse anderer Methoden.
Fazit
Mit der Zunahme der Datenmengen und der Verbesserung von Algorithmen versteht künstliche Intelligenz unsere Welt immer tiefer und als Teil dieser Welt sind wir Menschen von Natur aus Gegenstand des Verständnisses—— Durch die Entdeckung menschlicher Gehirnaktivitätsmuster erlangen Maschinen die Fähigkeit, von Grund auf zu verstehen, was Menschen denken. Vielleicht kann die KI eines Tages ein wahrer Meister des Gedankenlesens werden und vielleicht sogar die Fähigkeit haben, menschliche Träume mit hoher Wiedergabetreue einzufangen!
Das Obige stellt nur kurz einige aktuelle Forschungsergebnisse zur KI beim direkten Gedankenlesen vor. Tatsächlich haben einige Unternehmen begonnen, an der Kommerzialisierung verwandter Technologien zu arbeiten, wie beispielsweise Gehirn-Computer-Schnittstellen, die von Neuralink und Blackrock Neurotech vertreten werden Neurotechnologieunternehmen, deren potenzielle zukünftige Produkte spannende Anwendungen haben werden, etwa um Menschen mit unaussprechlichen Behinderungen dabei zu helfen, sich wieder mit der Welt zu verbinden, und um Maschinen fernzusteuern, die in gefährlichen Bereichen wie der Tiefsee und dem Weltraum arbeiten. Gleichzeitig hat die Entwicklung dieser Technologien vielen Menschen Hoffnung gegeben, das Geheimnis des menschlichen Bewusstseins zu entschlüsseln.
Natürlich hat diese Art von Technologie auch dazu geführt, dass sich viele Menschen Sorgen um Privatsphäre, Sicherheit und Ethik machen. Schließlich haben wir in vielen Filmen oder Romanen gesehen, wie diese Art von Technologie für böse Zwecke eingesetzt wird. Heutzutage ist die Weiterentwicklung solcher Technologien unvermeidlich. Daher ist die Frage, wie sichergestellt werden kann, dass diese Technologien im Einklang mit den menschlichen Interessen stehen, zu einer wichtigen Frage geworden, die Überlegungen und Diskussionen aller relevanten Personen und politischen Entscheidungsträger erfordert.
Das obige ist der detaillierte Inhalt vonGehirn-Computer-Schnittstelle, Gehirnwellen und fMRT: KI beherrscht das Gedankenlesen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr