
Heim >Technologie-Peripheriegeräte >KI >Konvertieren Sie Zeitreihen in ein Klassifizierungsproblem
Konvertieren Sie Zeitreihen in ein Klassifizierungsproblem

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-18 22:12:201295Durchsuche
In diesem Artikel wird der Aktienhandel als Beispiel verwendet. Wir verwenden KI-Modelle, um vorherzusagen, ob eine Aktie am nächsten Tag steigen oder fallen wird. In diesem Zusammenhang werden drei Klassifizierungsalgorithmen, XGBoost, Random Forest und Logistic Classifier, verglichen. Ein weiterer Schwerpunkt des Artikels ist die Datenaufbereitung. Wie müssen wir die Daten transformieren, damit das Modell sie verarbeiten kann?

Dieser Artikel folgt den Schritten des CRISP-DM-Prozessmodells und verwendet einen strukturierten Ansatz zur Lösung des Business Case. CRISP-DM ist eine weit verbreitete Methode in der Latentanalyse und wird häufig beim Aufbau von Data-Science-Projekten eingesetzt.
Die andere Sache ist, dass wir das Python-Paket openbb verwenden werden. Dieses Paket beinhaltet einige Datenquellen aus dem Finanzsektor und ist sehr einfach zu bedienen.
Der erste Schritt besteht darin, die notwendigen Bibliotheken zu installieren:
<code>pip install pandas numpy “openbb[all]” swifter scikit-learn</code>
Geschäftsverständnis
Zuerst sollten wir das Problem verstehen, das wir lösen möchten. In unserem Beispiel kann das Problem wie folgt definiert werden:
<code>预测股票代码 AAPL 的股价第二天会上涨还是下跌。</code>
Dann sollten wir überlegen, was Art von Maschine, die wir zur Hand haben. Das Problem der Lernmodelle. Wir wollen vorhersagen, ob die Aktie am nächsten Tag steigen oder fallen wird. Wir haben es hier also mit einem binären Klassifizierungsproblem zu tun, bei dem wir vorhersagen wollen, ob eine Aktie am nächsten Tag steigen (mit einem Wert von 1) oder fallen (mit einem Wert von 0) wird. Bei einem Klassifizierungsproblem sagen wir eine Klasse voraus. In unserem Fall handelt es sich um eine binäre Klassifizierung der Klassen 0 und 1.
Datenverständnis und -vorbereitung
Die Datenverständnisphase konzentriert sich auf die Identifizierung, Sammlung und Analyse von Datensätzen. Als ersten Schritt laden wir die Apple-Aktiendaten herunter. So geht's mit openbb:
<code>data = openbb.stocks.load(symbol = 'AAPL',start_date = '2023-01-01',end_date = '2023-04-01',monthly = False) data</code>
Dieser Code lädt Daten zwischen dem 01.01.2023 und dem 01.04.2023 herunter. Die heruntergeladenen Daten enthalten die folgenden Informationen:
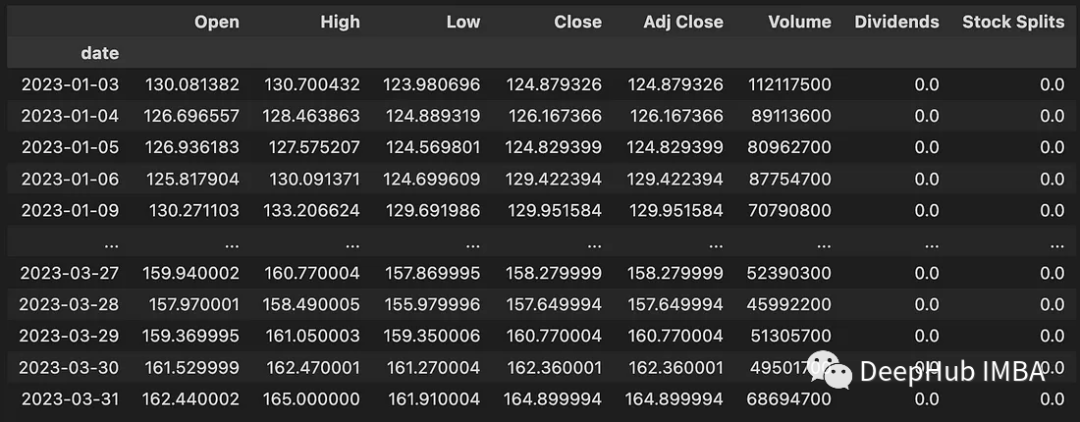
- Open: Täglicher Eröffnungspreis in USD
- High: Höchster Preis des Tages (USD)
- Low: Niedrigster Preis des Tages (USD)
- Close: Täglich Schlusskurs von USD
- Adj Close: Angepasster Schlusskurs im Zusammenhang mit Dividenden oder Aktiensplits
- Volumen: Anzahl der gehandelten Aktien
- Dividenden: Gezahlte Dividenden
- Aktiensplits: Durchführung von Aktiensplits
Wir haben die Daten heruntergeladen, aber Die Daten sind noch nicht verfügbar. Nicht für die Modellierung von Klassifizierungsmodellen geeignet. Die Daten müssen also noch für die Modellierung aufbereitet werden. Daher ist es notwendig, eine Funktion zum Herunterladen der Daten und zum anschließenden Konvertieren der Daten für die Modellierung zu entwickeln. Der folgende Code zeigt diese Funktion:
<code>def get_training_data(symbol, start_date, end_date, monthly_bool=True, lookback=10): data = openbb.stocks.load( symbol = symbol, start_date = start_date, end_date = end_date, monthly = monthly_bool) data = get_label(data) data_up_down = data['up_down'].to_numpy() training_data = get_sequence_data(data_up_down, lookback) return training_data</code>
Die erste hier enthaltene Funktion ist get_label():
<code>def encoding(n): if n > 0: return 1 else: return 0 def get_label(data): data['Delta'] = data['Close'] - data['Open'] data['up_down'] = data['Delta'].swifter.apply(lambda d: encoding(d)) return data</code>
Seine Hauptaufgabe besteht darin, die Differenz zwischen dem Schlusskurs und dem Eröffnungskurs zu berechnen. Wir markieren alle Tage, an denen der Aktienkurs stieg, mit 1 und alle Tage, an denen der Aktienkurs fiel, mit 0. Die zusätzliche Spalte up_down enthält Informationen darüber, ob der Aktienkurs an einem bestimmten Datum gestiegen oder gefallen ist. Die Funktion „swifter.apply()“ wird hier anstelle von „pandas apply()“ verwendet, da Swifter Multi-Core-Unterstützung bietet.
Die zweite Funktion ist get_sequence_data(). Der Parameter Lookback gibt an, wie viele Tage in der Vergangenheit in die Prognose einbezogen werden. Der get_sequence_data()-Code lautet wie folgt:
<code>def get_sequence_data(data_up_down, lookback): shape = (data_up_down.shape[0] - lookback + 1, lookback) strides = data_up_down.strides + (data_up_down.strides[-1],) return np.lib.stride_tricks.as_strided(data_up_down, shape=shape, strides=strides)</code>
Diese Funktion akzeptiert zwei Parameter: data_up_down und lookback. Es gibt ein neues NumPy-Array zurück, das eine Schiebefensteransicht des data_up_down-Arrays mit der angegebenen Fenstergröße darstellt, die durch das Lookback-Argument bestimmt wird. Um zu veranschaulichen, wie diese Funktion funktioniert, schauen wir uns ein kleines Beispiel an.
<code>get_sequence_data(np.array([1, 2, 3, 4, 5, 6]), 3)</code>
Die Ergebnisse sind wie folgt:
<code>array([[1, 2, 3],[2, 3, 4],[3, 4, 5],[4, 5, 6]])</code>
Nachfolgend laden wir die Daten für die Apple-Aktie herunter und transformieren sie für die Modellierung. Wir verwenden ein 10-tägiges Lookback-Fenster.
<code>data = get_training_data(symbol = 'AAPL', start_date = '2023-01-01', end_date = '2023-04-01', monthly_bool = False, lookback=10) pd.DataFrame(data).to_csv("data/data_aapl.csv")</code>
Die Daten sind fertig, beginnen wir mit der Modellierung und Bewertung des Modells.
Modellierung
Daten einlesen und Test- und Trainingsdaten generieren.
<code>data = pandas.read_csv("./data/data_aapl.csv") X=data.iloc[:,:-1] Y=data.iloc[:,-1] X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=4284, stratify=Y)</code>
Logistische Regression:
Dieser Klassifikator ist ein lineares Modell und wird häufig als Basismodell verwendet. Wir verwenden die Implementierung von scikit-learn:
<code>model_lr = LogisticRegression(random_state = 42) model_lr.fit(X_train,y_train) y_pred = model_lr.predict(X_test)</code>
XGBoost:
XGBoost ist eine Implementierung von Gradienten-verstärkten Entscheidungsbäumen, die auf Geschwindigkeit und Leistung ausgelegt sind. Es gehört zum Tree-Boosting-Algorithmus, der viele schwache Baumklassifikatoren nacheinander verbindet.
<code>model_xgb = XGBClassifier(random_state = 42) model_xgb.fit(X_train, y_train) y_pred = model_xgb.predict(X_test)</code>
Random Forest:
Random Forest bildet mehrere Entscheidungsbäume. Die Bagging-Methode wird als eine Art Ensemble-Lernen bezeichnet, da sie mehrere miteinander verbundene Lernende zum Lernen nutzt. Das Akronym „bagging“ steht für Bootstrap Aggregation. Hier kommt auch die Implementierung von scikit-learn zum Einsatz:
<code>model_rf = RandomForestClassifier(random_state = 42) model_rf.fit(X_train, y_train) y_pred = model_rf.predict(X_test)</code>
Evaluation
Nachdem wir das Modell modelliert und trainiert haben, müssen wir seine Leistung anhand der Testdaten bewerten. Recall, Precision und F1-Score werden zur Messung von Metriken verwendet. Die folgende Tabelle zeigt die Ergebnisse.
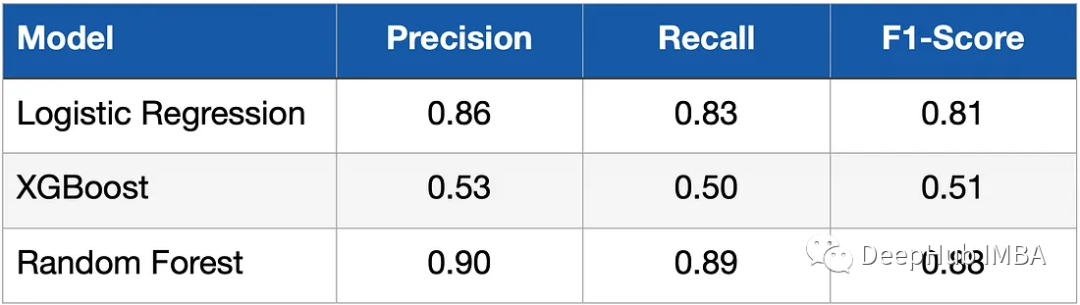
Sie können sehen, dass der logistische Klassifikator (logistische Regression) und der Zufallswald deutlich bessere Ergebnisse erzielt haben als das XGBoost-Modell. Was ist der Grund dafür? Dies liegt daran, dass die Daten relativ einfach sind und nur wenige Merkmalsdimensionen aufweisen. Außerdem ist die Länge der Daten sehr gering und nicht alle unsere Modelle wurden optimiert.
Zusammenfassung
Der Hauptzweck unseres Artikels besteht darin, vorzustellen, wie eine Zeitreihe von Aktienkursen in ein Klassifizierungsproblem umgewandelt wird, und zu demonstrieren, wie die Fensterfunktion verwendet wird, um die Zeitreihe während der Datenverarbeitung in eine Sequenz umzuwandeln Am Modell wird nicht viel Tuning durchgeführt, sodass einfachere Modelle bei der Leistungsbewertung besser abschneiden.
Das obige ist der detaillierte Inhalt vonKonvertieren Sie Zeitreihen in ein Klassifizierungsproblem. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr