
Heim >Technologie-Peripheriegeräte >KI >Die Destillation kann auch Schritt für Schritt erfolgen: Durch die neue Methode können kleine Modelle mit großen Modellen verglichen werden, die 2000-mal größer sind
Die Destillation kann auch Schritt für Schritt erfolgen: Durch die neue Methode können kleine Modelle mit großen Modellen verglichen werden, die 2000-mal größer sind

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-18 18:31:30837Durchsuche
Obwohl große Sprachmodelle aufgrund ihres großen Umfangs über erstaunliche Fähigkeiten verfügen, sind die für ihre Bereitstellung erforderlichen Kosten oft enorm. Die University of Washington hat zusammen mit dem Google Cloud Computing Artificial Intelligence Research Institute und Google Research dieses Problem weiter gelöst und das Distilling Step-by-Step-Paradigma vorgeschlagen, um das Modelltraining zu unterstützen. Im Vergleich zu LLM ist diese Methode effektiver beim Training kleiner Modelle und deren Anwendung auf bestimmte Aufgaben und erfordert weniger Trainingsdaten als herkömmliche Feinabstimmung und Destillation. Bei einer Benchmark-Aufgabe übertraf das Modell 770M T5 das Modell 540B PaLM. Beeindruckend ist, dass ihr Modell nur 80 % der verfügbaren Daten nutzte.

Während große Sprachmodelle (LLMs) beeindruckende Lernfähigkeiten mit wenigen Schüssen gezeigt haben, ist es schwierig, solche groß angelegten Modelle in realen Anwendungen einzusetzen. Eine dedizierte Infrastruktur für ein LLM mit einer Parameterskala von 175 Milliarden erfordert mindestens 350 GB GPU-Speicher. Darüber hinaus besteht das moderne LLM heute aus mehr als 500 Milliarden Parametern, was bedeutet, dass es mehr Speicher und Rechenressourcen benötigt. Solche Rechenanforderungen sind für die meisten Hersteller unerreichbar, ganz zu schweigen von Anwendungen, die eine geringe Latenz erfordern.
Um dieses Problem großer Modelle zu lösen, verwenden Entwickler häufig stattdessen kleinere spezifische Modelle. Diese kleineren Modelle werden mithilfe gängiger Paradigmen trainiert – Feinabstimmung oder Destillation. Durch die Feinabstimmung wird ein kleines vorab trainiertes Modell mithilfe nachgeschalteter, von Menschen kommentierter Daten aktualisiert. Die Destillation trainiert ein ebenso kleineres Modell unter Verwendung der vom größeren LLM erzeugten Etiketten. Leider sind diese Paradigmen bei gleichzeitiger Reduzierung der Modellgröße mit Kosten verbunden: Um eine mit LLM vergleichbare Leistung zu erzielen, sind für die Feinabstimmung teure menschliche Markierungen erforderlich, während für die Destillation große Mengen unbeschrifteter Daten erforderlich sind, die schwer zu erhalten sind.
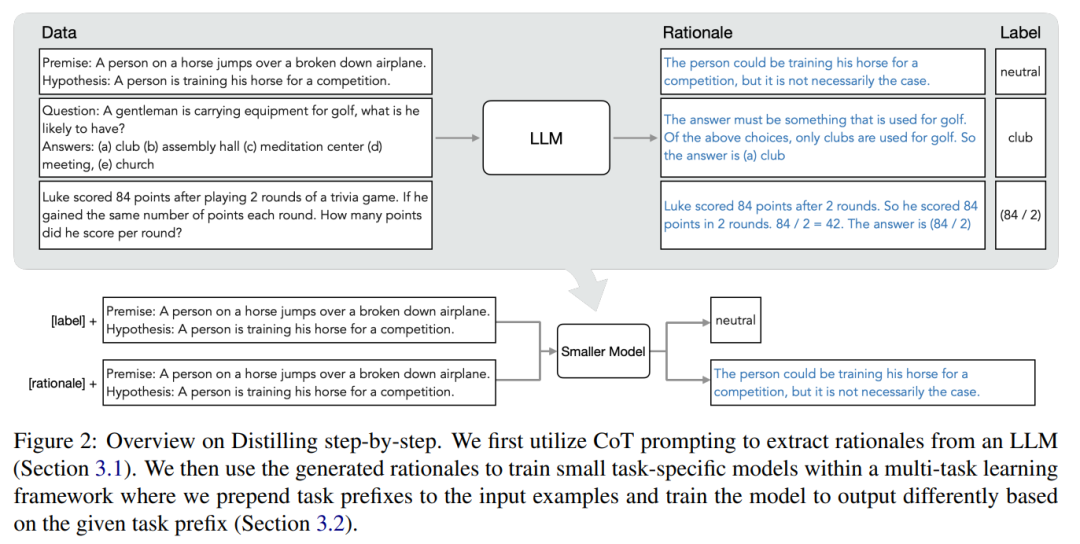
In einem Artikel mit dem Titel „Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes“ stellten Forscher der University of Washington und Google einen neuen einfachen Mechanismus vor – Schritt-für-Schritt-Destillieren, Wird verwendet, um kleinere Modelle mit weniger Trainingsdaten zu trainieren. Dieser Mechanismus reduziert die Menge an Trainingsdaten, die zur Feinabstimmung und Destillation des LLM erforderlich sind, was zu einer kleineren Modellgröße führt. Der Kern dieses Mechanismus besteht darin, die Perspektive zu ändern und LLM als etwas zu betrachten, das kann als Argument dienen und nicht als Quelle lauter Etiketten dienen. LLM kann Begründungen in natürlicher Sprache generieren, die zur Erklärung und Unterstützung der vom Modell vorhergesagten Bezeichnungen verwendet werden können. Auf die Frage „Ein Herr trägt Golfausrüstung, was könnte er haben? (a) Schläger, (b) Auditorium, (c) Meditationszentrum, (d) Konferenz, (e) Kirche“ kann LLM antworten: „(a ) Club“ durch Gedankenketten-Argumentation (CoT) und rationalisieren Sie diese Bezeichnung, indem Sie erklären, dass „die Antwort etwas sein muss, das zum Golfspielen verwendet wird.“ Von den oben genannten Optionen werden nur Schläger zum Golfen verwendet. Wir verwenden diese Begründungen als zusätzliche, umfassendere Informationen, um kleinere Modelle in einer Trainingsumgebung mit mehreren Aufgaben zu trainieren und Etikettenvorhersagen und Begründungsvorhersagen durchzuführen.
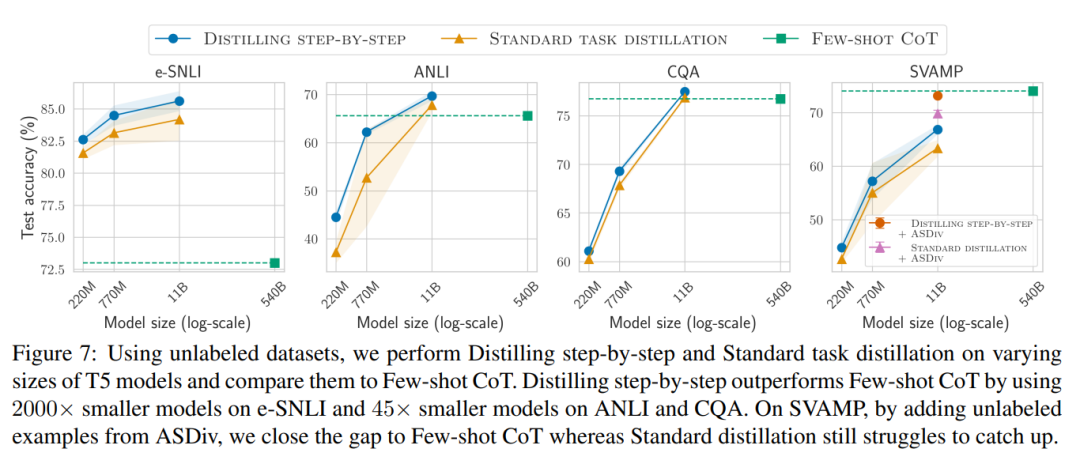
Wie in Abbildung 1 dargestellt, können durch schrittweise Destillation kleine Modelle für bestimmte Aufgaben erlernt werden, und die Anzahl der Parameter dieser Modelle beträgt weniger als 1/500 von LLM. Bei der schrittweisen Destillation werden außerdem weitaus weniger Trainingsbeispiele verwendet als bei der herkömmlichen Feinabstimmung oder Destillation. 
Die experimentellen Ergebnisse zeigen, dass es unter den 4 NLP-Benchmarks drei vielversprechende experimentelle Schlussfolgerungen gibt.
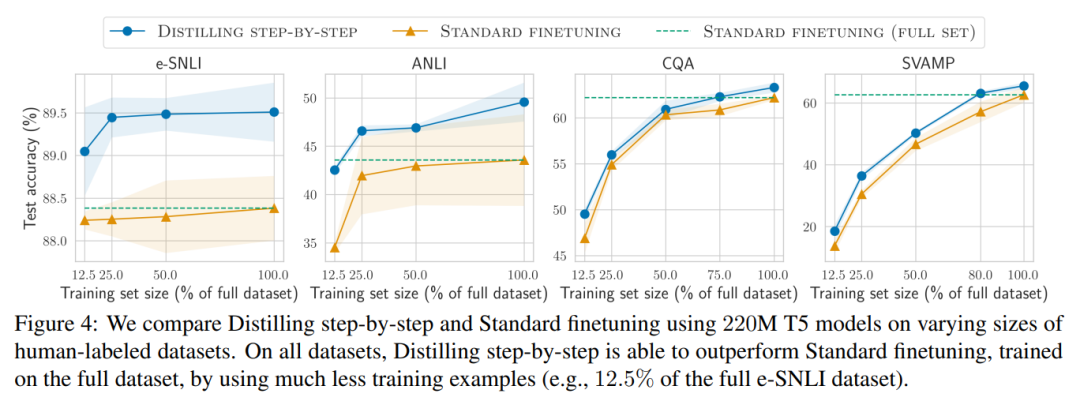
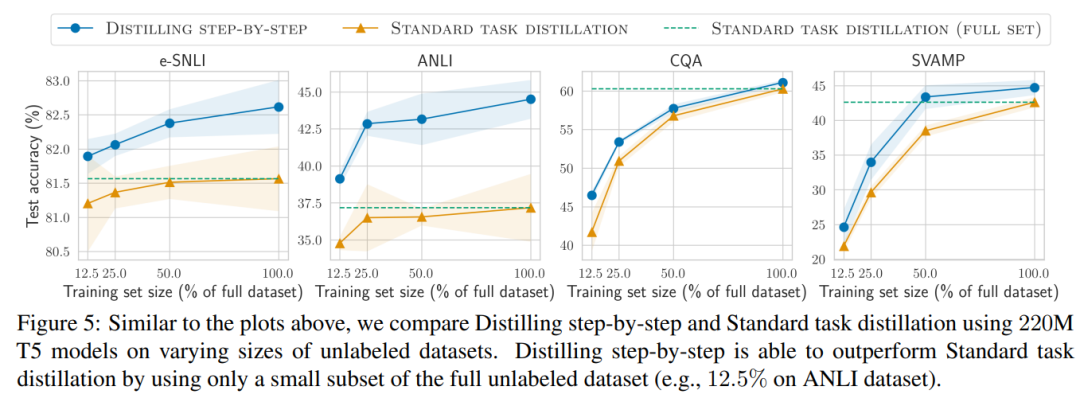
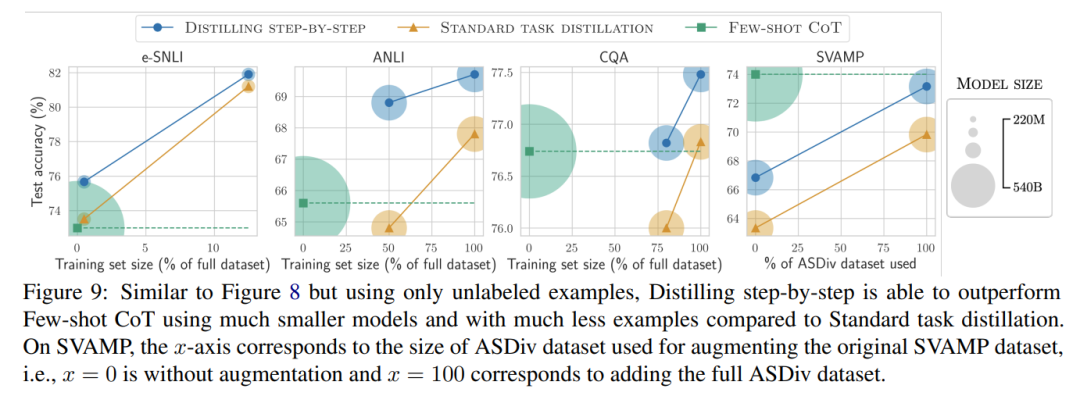
Wenn nur unbeschriftete Daten vorliegen, ist die Leistung des kleinen Modells immer noch so gut wie die von LLM – mit nur einem 11B übertrifft das T5-Modell die Leistung des 540B PaLM. Die Studie zeigt außerdem, dass eine schrittweise Destillation die zusätzlichen unbeschrifteten Daten effektiver nutzen kann, wenn ein kleineres Modell eine schlechtere Leistung als LLM erbringt, um es kleineren Modellen zu ermöglichen, die Leistung von LLM zu erreichen . Die Forscher schlugen ein neues Paradigma der schrittweisen Destillation vor, das die Argumentationsfähigkeit von LLM nutzt, um seine Vorhersagen anhand hoher Datenmengen vorherzusagen effiziente Möglichkeit, kleinere Modelle zu trainieren. Der Gesamtrahmen ist in Abbildung 2 dargestellt. Dieses Paradigma besteht aus zwei einfachen Schritten: Zunächst wird bei einem gegebenen LLM und einem unbeschrifteten Datensatz der LLM aufgefordert, ein Ausgabeetikett und einen Grund zu generieren, um zu beweisen, dass das Etikett wahr ist. Die Begründung wird in natürlicher Sprache erläutert und unterstützt die vom Modell vorhergesagte Bezeichnung (siehe Abbildung 2). Rechtfertigung ist eine aufkommende Verhaltenseigenschaft aktueller selbstüberwachter LLMs. Verwenden Sie dann zusätzlich zu den Aufgabenbezeichnungen diese Gründe, um kleinere nachgelagerte Modelle zu trainieren. Um es ganz klar auszudrücken: Gründe können umfassendere und detailliertere Informationen liefern, um zu erklären, warum eine Eingabe einer bestimmten Ausgabebezeichnung zugeordnet wird. Die Forscher überprüften im Experiment die Wirksamkeit der schrittweisen Destillation. Erstens trägt die schrittweise Destillation im Vergleich zu Standardmethoden zur Feinabstimmung und Aufgabendestillation dazu bei, eine bessere Leistung mit einer viel geringeren Anzahl von Trainingsbeispielen zu erzielen, wodurch die Dateneffizienz beim Lernen kleiner aufgabenspezifischer Modelle erheblich verbessert wird.
# 🎜 🎜# Zweitens zeigen Untersuchungen, dass die Methode der schrittweisen Destillation die Leistung von LLM bei einer kleineren Modellgröße übertrifft und die Bereitstellungskosten im Vergleich zu LLM erheblich senkt.
Schrittweise Destillation
# 🎜 🎜#
Abschließend untersuchten die Forscher die Mindestressourcen, die die schrittweise Destillationsmethode im Hinblick auf eine über LLM hinausgehende Leistung erfordert, einschließlich der Anzahl der Trainingsbeispiele und Modellgröße. Sie zeigen, dass der schrittweise Destillationsansatz sowohl die Dateneffizienz als auch die Bereitstellungseffizienz verbessert, indem weniger Daten und kleinere Modelle verwendet werden. 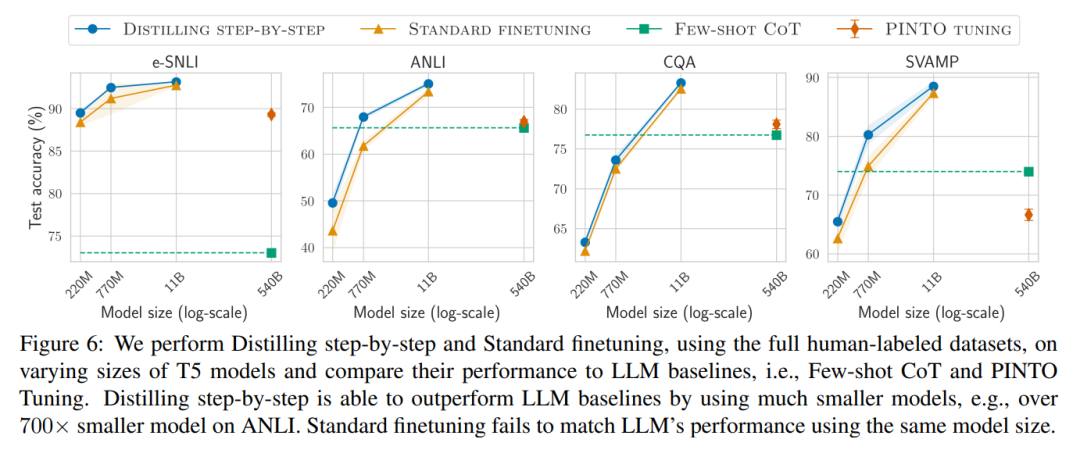
Das obige ist der detaillierte Inhalt vonDie Destillation kann auch Schritt für Schritt erfolgen: Durch die neue Methode können kleine Modelle mit großen Modellen verglichen werden, die 2000-mal größer sind. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr