
Heim >Technologie-Peripheriegeräte >KI >Große Modelle läuten die „Open-Source-Saison' ein und ziehen eine Bestandsaufnahme des Open-Source-LLM und der Datensätze des vergangenen Monats
Große Modelle läuten die „Open-Source-Saison' ein und ziehen eine Bestandsaufnahme des Open-Source-LLM und der Datensätze des vergangenen Monats

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-18 16:31:131764Durchsuche
Vor einiger Zeit wurde in durchgesickerten internen Dokumenten von Google die Ansicht geäußert, dass OpenAI und Google zwar oberflächlich betrachtet einander bei großen KI-Modellen hinterherjagen, der wahre Gewinner jedoch möglicherweise nicht aus diesen beiden hervorgeht, da es sich um eine Macht Dritter handelt erhebt sich leise. Diese Leistung ist „Open Source“.
Die gesamte Community dreht sich um das Open-Source-Modell LLaMA von Meta und erstellt schnell Modelle mit ähnlichen Funktionen wie OpenAI und die großen Modelle von Google. Darüber hinaus iteriert das Open-Source-Modell schneller, ist anpassbarer und privater.
Kürzlich sagte Sebastian Raschka, ehemaliger Assistenzprofessor an der University of Wisconsin-Madison und Chief AI Education Officer beim Startup Lightning AI: Für Open Source war der letzte Monat großartig.
Allerdings sind nacheinander so viele große Sprachmodelle (LLM) erschienen, dass es nicht einfach ist, alle Modelle fest im Griff zu behalten. In diesem Artikel teilt Sebastian Ressourcen und Forschungserkenntnisse zu den neuesten Open-Source-LLMs und Datensätzen.
Papiere und Trends
Im letzten Monat wurden viele Forschungsarbeiten veröffentlicht, daher ist es schwierig, die Favoriten auszuwählen, die ausführlich besprochen werden können. Sebastian bevorzugt Aufsätze, die zusätzliche Einblicke liefern, anstatt einfach nur leistungsfähigere Modelle zu demonstrieren. Vor diesem Hintergrund erregte das erste Pythia-Papier, das von Forschern der Eleuther AI, der Yale University und anderen Institutionen gemeinsam verfasst wurde, seine Aufmerksamkeit.

Papieradresse: https://arxiv.org/pdf/2304.01373.pdf
Pythia: Erkenntnisse aus groß angelegten Schulungen gewinnen
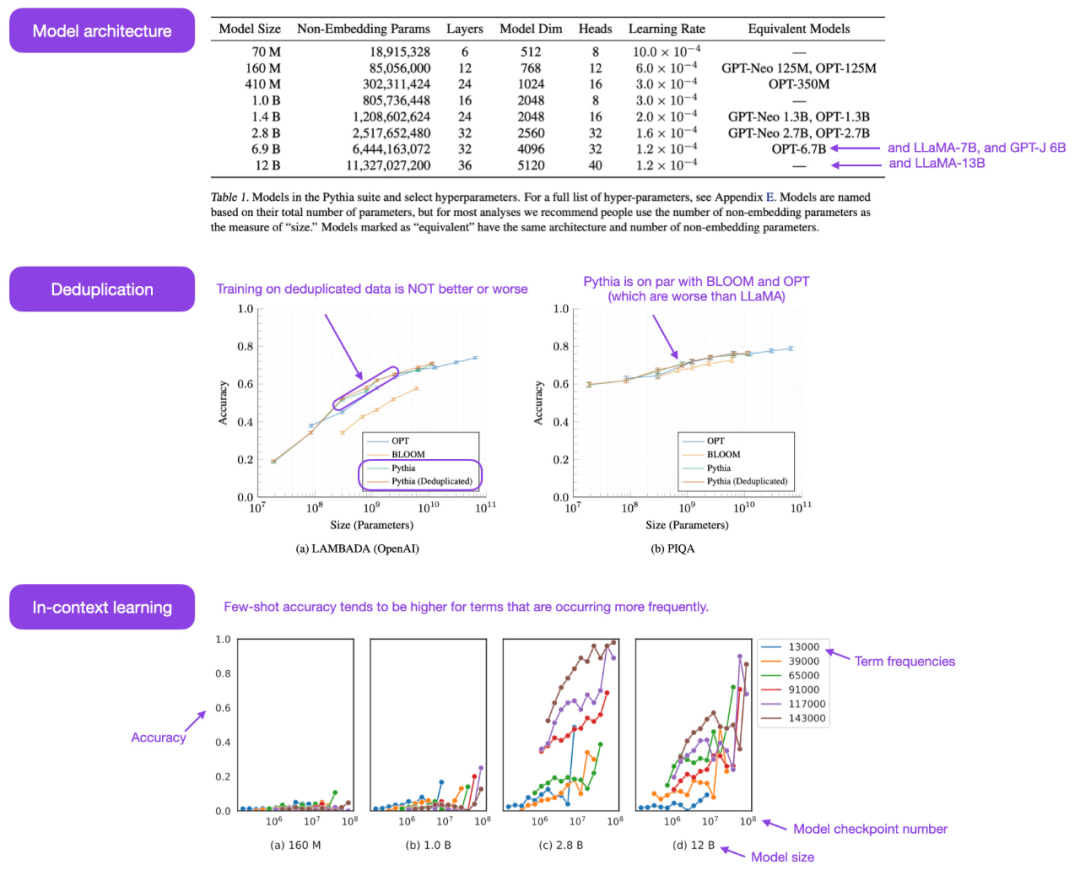
Open-Source-Pythia-Serie Das Modell ist wirklich eine interessante Alternative zu anderen Modellen im autoregressiven Decoderstil (d. h. GPT-ähnlichen Modellen). Der Artikel enthüllt einige interessante Einblicke in den Trainingsmechanismus und stellt entsprechende Modelle mit Parametern von 70M bis 12B vor.
Pythia-Modellarchitektur ähnelt GPT-3, enthält jedoch einige Verbesserungen wie Flash-Aufmerksamkeit (wie LLaMA) und Rotationspositionseinbettung (wie PaLM). Gleichzeitig wurde Pythia auf einem 800-GB-Pile mit verschiedenen Textdatensätzen und 300 B-Tokens trainiert (1 Epoche auf dem regulären Pile und 1,5 Epoche auf dem Deduplizierungs-Pile).
Das Folgende sind einige Erkenntnisse und Gedanken aus dem Pythia-Artikel:
- Wird das Training mit wiederholten Daten (d. h. Trainingsepoche> 1) irgendwelche Auswirkungen haben? Die Ergebnisse zeigen, dass die Datendeduplizierung die Leistung weder verbessert noch beeinträchtigt.
- Beeinflussen Trainingsbefehle das Gedächtnis? Leider stellt sich heraus, dass dies nicht der Fall ist. Ich entschuldige mich, denn wenn es betroffen wäre, könnte das lästige Problem des wörtlichen Gedächtnisses durch eine Neuordnung der Trainingsdaten gemildert werden.
- Eine Verdoppelung der Stapelgröße könnte die Trainingszeit halbieren, ohne die Konvergenz zu beeinträchtigen.
Open-Source-Daten
Der letzte Monat war besonders aufregend für Open-Source-KI, mit der Entstehung mehrerer Open-Source-Implementierungen von LLM und einer großen Welle von Open-Source-Datensätzen. Zu diesen Datensätzen gehören Databricks Dolly 15k, OpenAssistant Conversations (OASST1) zur Feinabstimmung der Anweisungen und RedPajama für die Vorschulung. Diese Bemühungen um Datensätze sind besonders lobenswert, da die Datenerfassung und -bereinigung 90 % der realen maschinellen Lernprojekte ausmacht, diese Arbeit jedoch nur wenigen Menschen Spaß macht. Databricks-Dolly-15-Datensatz ).
OASST1-Datensatz
Der OASST1-Datensatz wird zur Feinabstimmung des vorab trainierten LLM auf einer Sammlung von ChatGPT-Assistenten-ähnlichen Gesprächen verwendet, die von Menschen erstellt und kommentiert wurden und 161.443 in 35 Sprachen verfasste Nachrichten und 461.292 Qualitätsbewertungen enthalten . Diese sind in über 10.000 vollständig kommentierten Dialogbäumen organisiert.
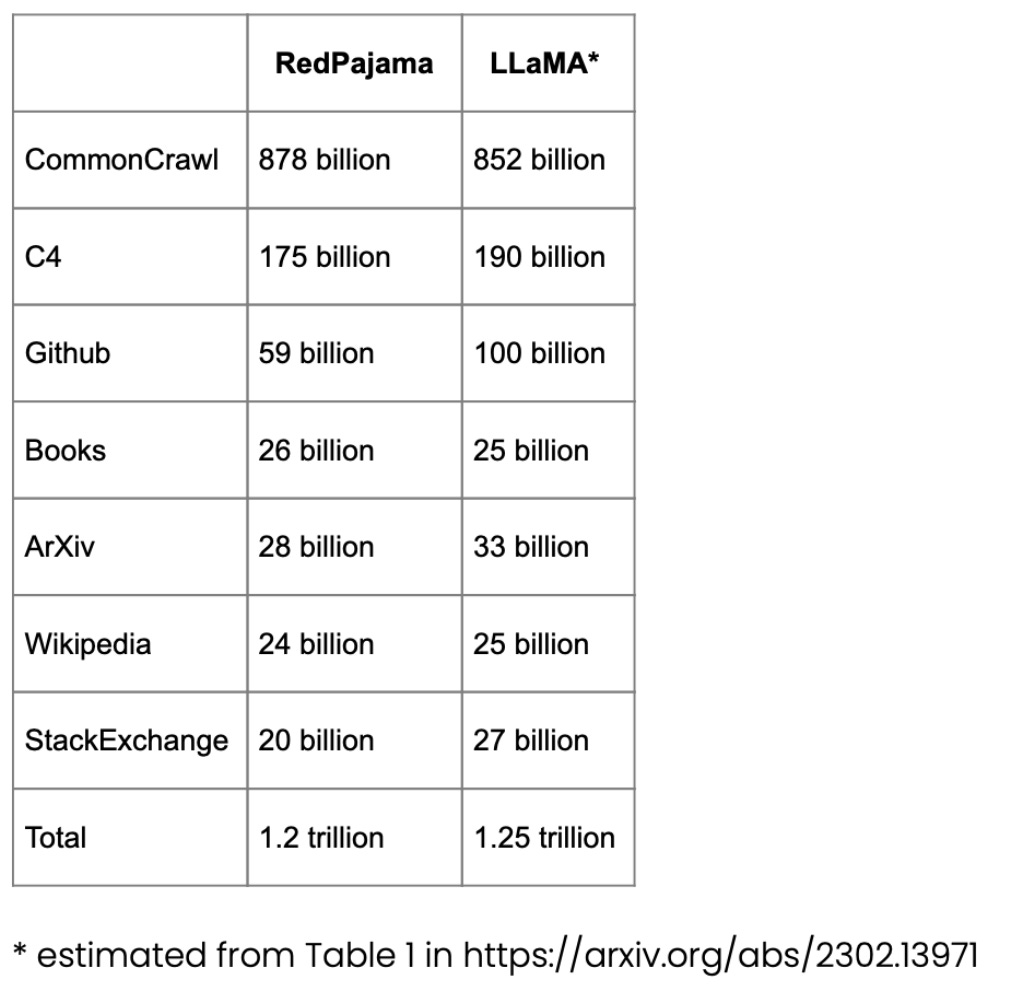
RedPajama-Datensatz für das Vortraining

RedPajama ist ein Open-Source-Datensatz für das LLM-Vortraining, ähnlich dem SOTA LLaMA-Modell von Meta. Dieser Datensatz zielt darauf ab, einen Open-Source-Konkurrenten zu den beliebtesten LLMs zu schaffen, bei denen es sich derzeit entweder um Closed-Source-Geschäftsmodelle oder nur teilweise Open-Source-Modelle handelt.
Der größte Teil von RedPajama besteht aus CommonCrawl, das Websites auf Englisch filtert, aber Wikipedia-Artikel decken 20 verschiedene Sprachen ab.
LongForm-Datensatz
Der Artikel „The LongForm: Optimizing Instruction Tuning for Long Text Generation with Corpus Extraction“ stellt eine Sammlung manuell erstellter Dokumente vor, die auf vorhandenen Korpora wie C4 und Wikipedia basieren und Anweisungen für diese Dokumente, wodurch ein auf Anweisungen abgestimmter Datensatz erstellt wird, der für die Generierung von Langtexten geeignet ist. T-Paper-Adresse: https://arxiv.org/abs/2304.08460
alPaca Libre-Projekte
Ziel des Alpaca Libre-Projekts sind MIT-lizenzierte Demos, die in ein Alpaca-kompatibles Format konvertiert wurden, um Alpaca-Projekte zu reproduzieren.
Erweitern von Open-Source-Datensätzen
Die Feinabstimmung der Anweisungen ist für uns der Schlüssel zur Weiterentwicklung von einem GPT-3-ähnlichen vorab trainierten Grundmodell zu einem leistungsfähigeren ChatGPT-ähnlichen großen Sprachmodell. Von Menschen erstellte Open-Source-Anweisungsdatensätze wie Databricks-Dolly-15 helfen dabei, dies zu erreichen. Aber wie können wir weiter skalieren? Ist es möglich, keine weiteren Daten zu erheben? Ein Ansatz besteht darin, ein LLM von seiner eigenen Iteration aus zu booten. Obwohl die Self-Instruct-Methode vor fünf Monaten vorgeschlagen wurde (und nach heutigen Maßstäben veraltet ist), ist sie immer noch eine sehr interessante Methode. Hervorzuheben ist, dass es dank Self-Instruct möglich ist, vorab trainierte LLMs an Anweisungen auszurichten, eine Methode, die fast keine Anmerkungen erfordert.
Wie funktioniert es? Kurz gesagt, es kann in die folgenden vier Schritte unterteilt werden:
Der erste ist ein Seed-Task-Pool mit einer Reihe manuell geschriebener Anweisungen (in diesem Fall 175) und Beispielanweisungen
- Der zweite ist die Verwendung ein vorab trainiertes LLM (z. B. GPT-3) zur Bestimmung der Aufgabenkategorie;
- Dann generiert das vorab trainierte LLM Antworten;
- Abschließend werden die Antworten gesammelt, zugeschnitten und gefiltert bevor Sie die Anweisungen zum Aufgabenpool hinzufügen.
- ... Befehlssätze. Gleichzeitig können auch Selbstlerner von LLM profitieren, das auf manuelle Anweisungen abgestimmt ist.
Aber der Goldstandard für die Bewertung von LLMs ist natürlich die Befragung menschlicher Bewerter. Basierend auf der menschlichen Bewertung übertrifft Self-Instruct sowohl grundlegende LLMs als auch LLMs, die auf überwachte Weise auf menschlichen Unterrichtsdatensätzen trainiert werden (z. B. SuperNI, T0 Trainer). Interessanterweise schneidet Self-Instruct jedoch nicht besser ab als Methoden, die mit Reinforcement Learning mit menschlichem Feedback (RLHF) trainiert werden. 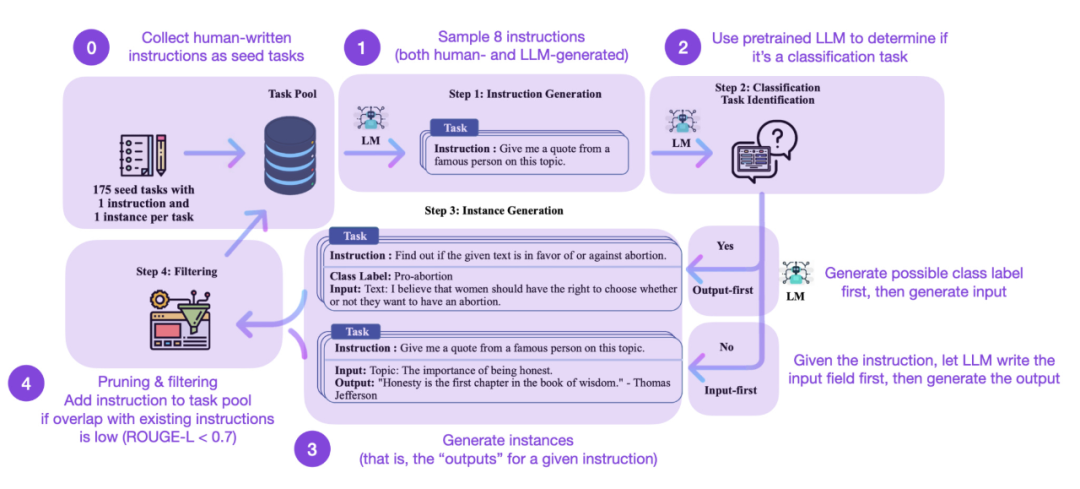
Künstlich generierter vs. synthetischer Trainingsdatensatz
Künstlich generierter Anweisungsdatensatz oder Selbstinstruktionsdatensatz, welcher ist vielversprechender? Sebastian sieht in beiden eine Zukunft. Warum nicht mit einem manuell generierten Befehlsdatensatz beginnen (z. B. databricks-dolly-15k mit 15.000 Anweisungen) und ihn dann mithilfe von Self-Instruct erweitern? Der Artikel „Synthetic Data from Diffusion Models Improves ImageNet Classification“ zeigt, dass die Kombination realer Bildtrainingssätze mit KI-generierten Bildern die Modellleistung verbessern kann. Es wäre interessant zu untersuchen, ob dies auch für Textdaten gilt.
Adresse des Artikels: https://arxiv.org/abs/2304.08466
Der aktuelle Artikel „Better Language Models of Code through Self-Improvement“ befasst sich mit der Forschung in dieser Richtung. Die Forscher fanden heraus, dass Codegenerierungsaufgaben verbessert werden können, wenn ein vorab trainiertes LLM seine eigenen generierten Daten verwendet.
Papieradresse: https://arxiv.org/abs/2304.01228
Weniger ist mehr (Weniger ist mehr)?
Außerdem zusätzlich zu immer größeren Datenmengen Wie kann die Effizienz bei kleineren Datensätzen verbessert werden, um das Modell vorab zu trainieren und am Set zu verfeinern? Der Artikel „Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes“ schlägt die Verwendung eines Destillationsmechanismus vor, um aufgabenspezifische kleinere Modelle zu verwalten, die weniger Trainingsdaten verwenden, aber die Standard-Feinabstimmungsleistung übertreffen.
Papieradresse: https://arxiv.org/abs/2305.02301
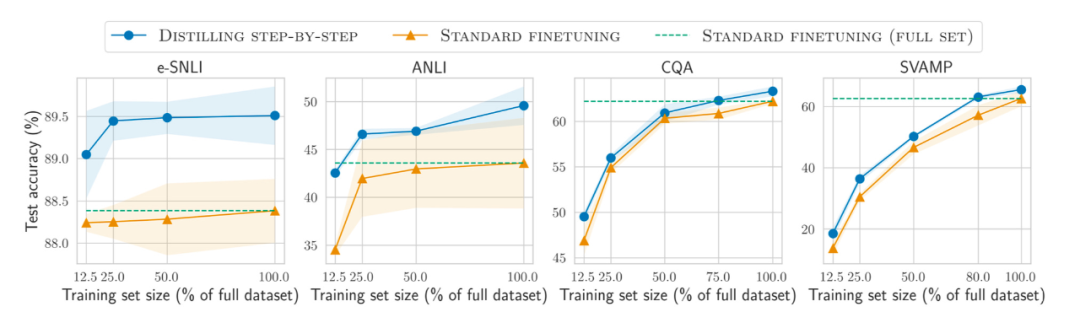
Tracking Open Source LLM
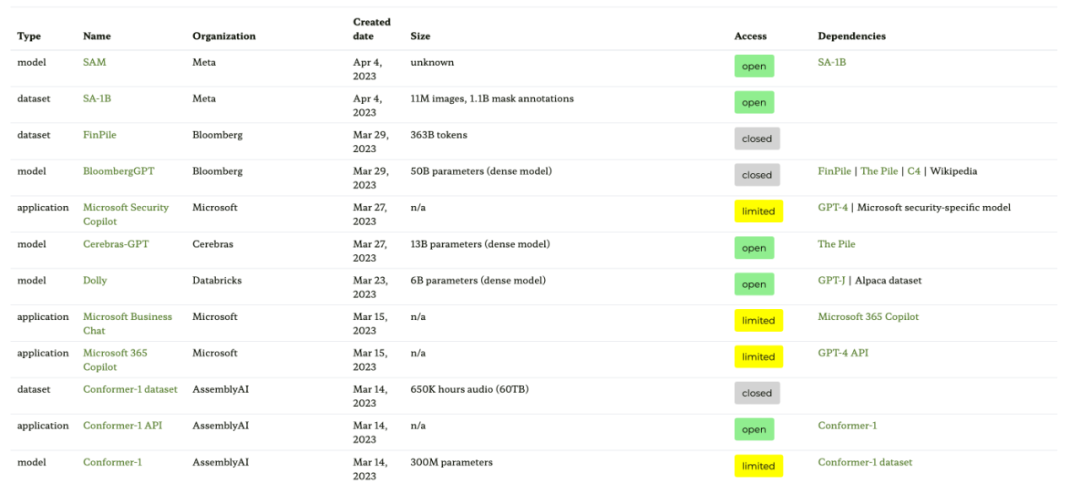
Die Zahl der Open Source LLMs explodiert einer Hand , es ist sehr gut, Trends zu verfolgen (im Vergleich zur Steuerung des Modells über eine kostenpflichtige API), aber andererseits kann es mühsam sein, den Überblick zu behalten. Die folgenden vier Ressourcen bieten unterschiedliche Zusammenfassungen der relevantesten Modelle, einschließlich ihrer Beziehungen, zugrunde liegenden Datensätze und verschiedener Lizenzinformationen.
Die erste Ressource ist die Ecosystem Graph-Website, die auf dem Papier „Ecosystem Graphs: The Social Footprint of Foundation Models“ basiert und die folgenden Tabellen und interaktiven Abhängigkeitsdiagramme (hier nicht gezeigt) bereitstellt.
Dieses Ökosystemdiagramm ist die umfassendste Liste, die Sebastian bisher gesehen hat, kann jedoch etwas verwirrend sein, da es viele weniger beliebte LLMs enthält. Eine Überprüfung des entsprechenden GitHub-Repositorys zeigt, dass es seit mindestens einem Monat aktualisiert wurde. Es ist auch unklar, ob neuere Modelle hinzugefügt werden.
... index.html?mode=table
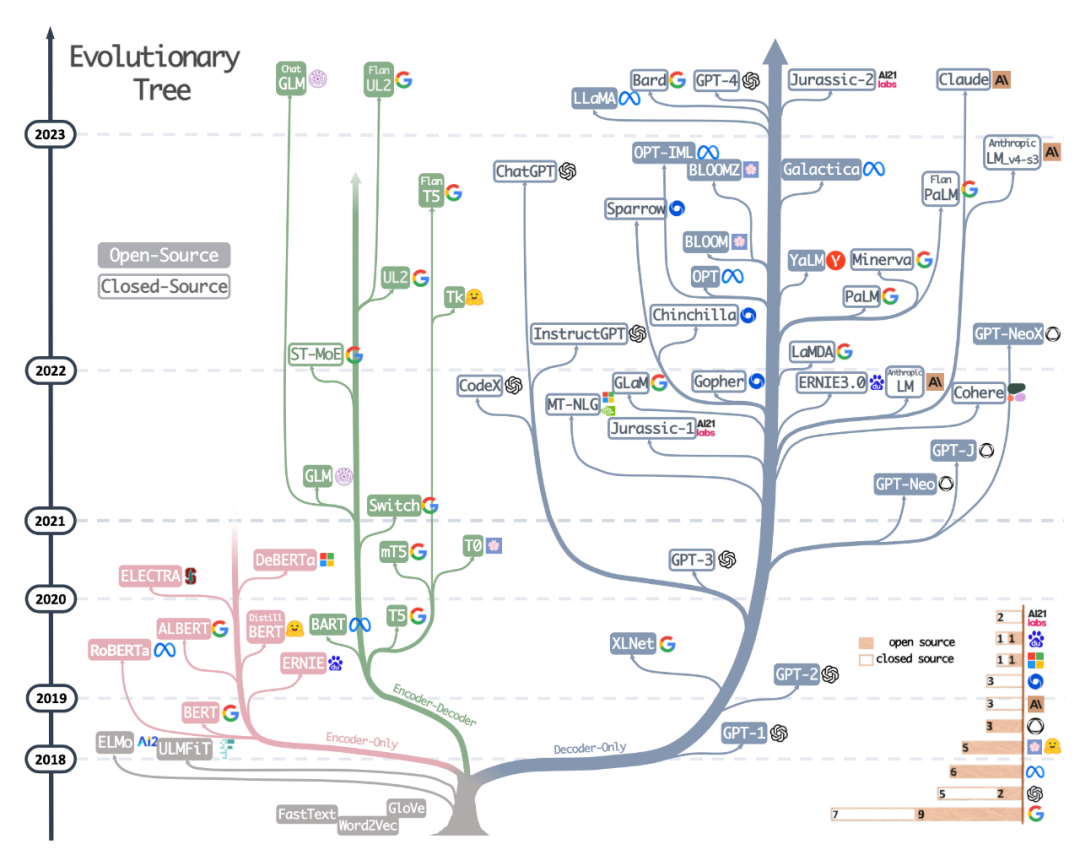
- Die zweite Ressource ist der wunderschön gezeichnete Evolutionsbaum aus dem kürzlich erschienenen Artikel „Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond“, der sich auf die beliebtesten LLMs und konzentriert ihre Beziehungen. Obwohl die Leser einen sehr schönen und klaren visuellen LLM-Evolutionsbaum gesehen haben, haben sie auch einige kleine Zweifel. Es ist nicht klar, warum die Basis nicht von der ursprünglichen Transformatorarchitektur ausgeht. Auch Open-Source-Labels sind nicht sehr genau, zum Beispiel wird LLaMA als Open Source aufgeführt, aber die Gewichtungen sind nicht unter einer Open-Source-Lizenz verfügbar (nur der Inferenzcode).
Papieradresse: https://arxiv.org/abs/2304.13712
Die dritte Ressource ist eine Tabelle, die von Sebastians Kollegin Daniela Dapena aus dem Blog „The Ultimate Battle of Language Models: Lit-LLaMA vs GPT3.5 vs Bloom vs...“ erstellt wurde.
Die folgende Tabelle ist zwar kleiner als andere Ressourcen, bietet aber den Vorteil, dass sie Modellabmessungen und Lizenzinformationen enthält. Diese Tabelle ist sehr nützlich, wenn Sie diese Modelle in einem Projekt verwenden möchten.
Blog-Adresse: https://lightning.ai/pages/community/community-discussions/the-ultimate-battle-of-lingual-models-lit-llama-vs-gpt3.5-vs -bloom-vs/
Die vierte Ressource ist die LLaMA-Cult-and-More-Übersichtstabelle, die zusätzliche Informationen zu Feinabstimmungsmethoden und Hardwarekosten bietet.
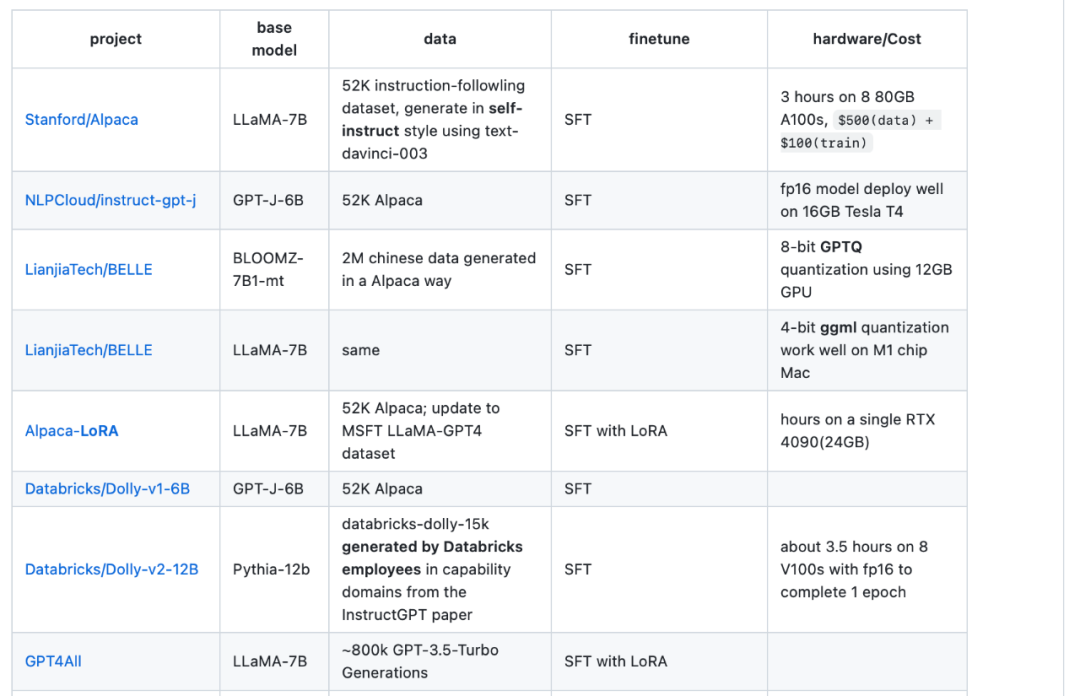
Übersichtstabellenadresse: https://github.com/shm007g/LLaMA-Cult-and-More/blob/main/chart.md
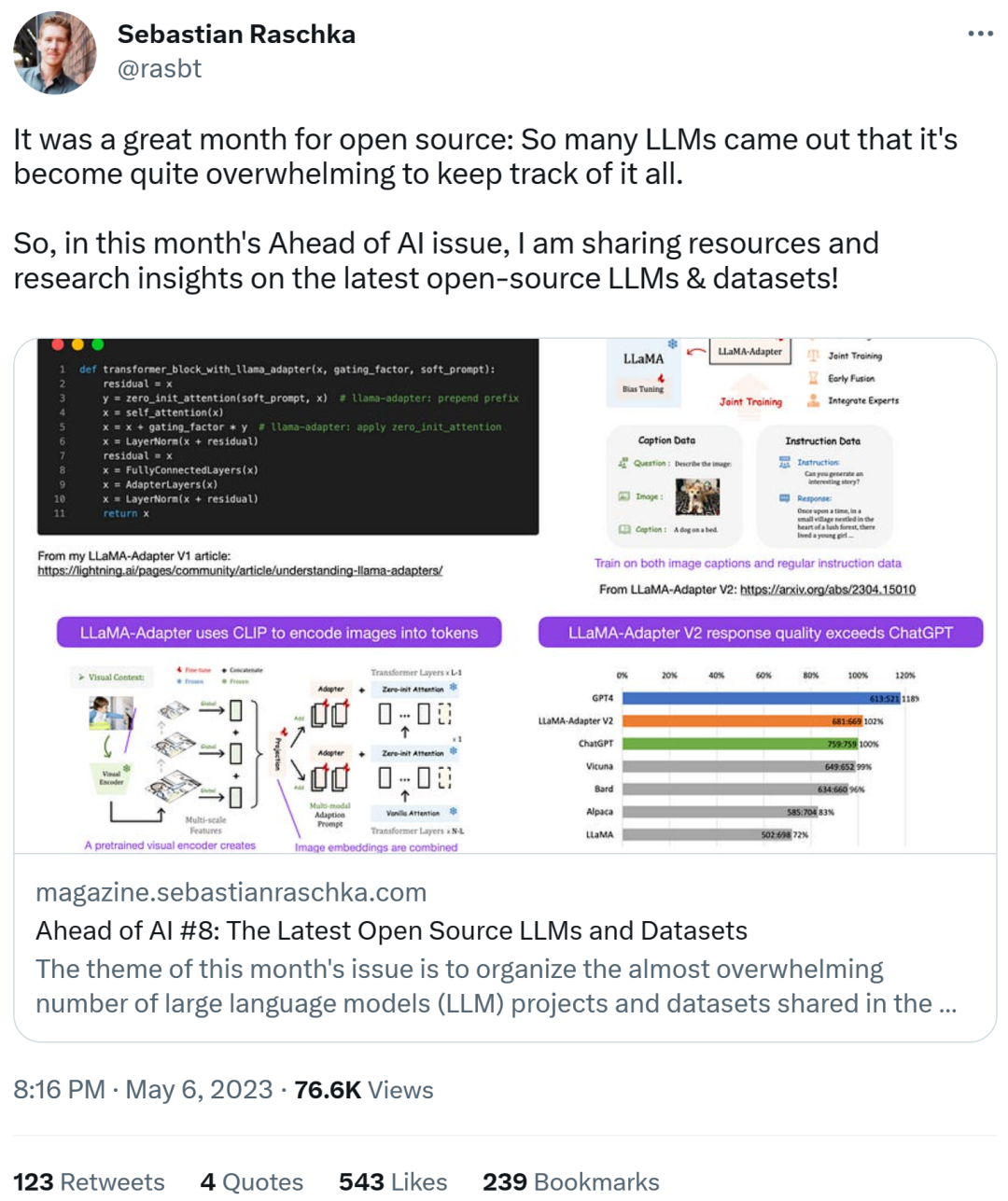
Mit LLaMA-Adapter V2 Feinabstimmung des multimodalen LLM
Sebastian prognostiziert, dass wir diesen Monat mehr multimodale LLM-Modelle sehen werden, daher müssen wir über das veröffentlichte Papier „LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model“ sprechen nicht längst. Sehen wir uns zunächst an, was ein LLaMA-Adapter ist. Es handelt sich um eine Parameter-effiziente LLM-Feinabstimmungstechnik, die die vorherigen Transformatorblöcke modifiziert und einen Gating-Mechanismus zur Stabilisierung des Trainings einführt.
Papieradresse: https://arxiv.org/abs/2304.15010
Mit der LLaMA-Adapter-Methode konnten die Forscher 52.000 Befehlspaare in nur 1 Stunde erreichen (8 A100-GPUs). Gut -Tuning eines 7B-Parameter-LLaMA-Modells. Obwohl nur die neu hinzugefügten 1,2M-Parameter (Adapterschicht) verfeinert wurden, ist das 7B-LLaMA-Modell immer noch eingefroren.
LLaMA-Adapter V2 konzentriert sich auf Multimodalität, d. h. den Aufbau eines visuellen Befehlsmodells, das Bildeingaben empfangen kann. Obwohl die ursprüngliche Version 1 Text-Tokens und Bild-Tokens empfangen konnte, wurden Bilder noch nicht vollständig erforscht.
LLaMA-Adapter Von V1 bis V2 haben Forscher die Adaptermethode durch die folgenden drei Haupttechniken verbessert.
- Frühe visuelle Wissensfusion: Anstatt visuelle und angepasste Hinweise auf jeder angepassten Ebene zu verschmelzen, verbinden Sie das visuelle Token mit dem Wort-Token im ersten Transformatorblock.
- Verwenden Sie weitere Parameter: Entsperren Sie alle Normalisierungsebenen und fügen Sie sie hinzu Bias-Einheiten und Skalierungsfaktoren für jede lineare Ebene im Transformatorblock;
- Gemeinsames Training mit disjunkten Parametern: Für Untertiteldaten wird nur die visuelle Projektionsebene (und die oben neu hinzugefügten Parameter) trainiert Auf den Daten folgen die Anweisungen.
LLaMA V2 (14M) hat viel mehr Parameter als LLaMA V1 (1,2 M), ist aber immer noch leichtgewichtig und macht nur 0,02 % der Gesamtparameter von 65B LLaMA aus. Besonders beeindruckend ist, dass der resultierende LLaMA-Adapter V2 durch die Feinabstimmung von nur 14 Millionen Parametern des 65B-LLaMA-Modells eine Leistung erbringt, die der von ChatGPT ebenbürtig ist (bei Auswertung mit dem GPT-4-Modell). Auch der LLaMA-Adapter V2 übertrifft das 13B Vicuna-Modell mit der vollständigen Feinabstimmungsmethode.
Leider fehlt im LLaMA-Adapter V2-Papier der im V1-Papier enthaltene Rechenleistungs-Benchmark, aber wir können davon ausgehen, dass V2 immer noch viel schneller ist als die vollständig fein abgestimmte Methode.

Andere Open-Source-LLM
Die Entwicklung großer Modelle geht so schnell voran, dass wir sie nicht alle auflisten können. Zu den berühmten Open-Source-LLM- und Chatbots, die diesen Monat eingeführt wurden, gehören Open-Assistant, Baize, StableVicuna, ColossalChat, Mosaic’s MPT usw. Darüber hinaus sind im Folgenden zwei besonders interessante multimodale LLMs aufgeführt.
OpenFlamingo
OpenFlamingo ist eine Open-Source-Kopie des Flamingo-Modells, das letztes Jahr von Google DeepMind veröffentlicht wurde. OpenFlamingo zielt darauf ab, multimodale Bildinferenzfunktionen für LLM bereitzustellen, die es Benutzern ermöglichen, Text- und Bildeingaben zu verschachteln.
MiniGPT-4
MiniGPT-4 ist ein weiteres Open-Source-Modell mit visuellen Sprachfunktionen. Es basiert auf dem eingefrorenen visuellen Encoder BLIP-27 und dem eingefrorenen Vicuna LLM.
NeMo Guardrails
Mit dem Aufkommen dieser großen Sprachmodelle denken viele Unternehmen darüber nach, wie und ob sie diese einsetzen sollen, wobei Sicherheitsbedenken besonders im Vordergrund stehen. Gute Lösungen gibt es noch nicht, aber es gibt zumindest einen weiteren vielversprechenden Ansatz: NVIDIA hat ein Toolkit zur Lösung des LLM-Halluzinationsproblems als Open-Source-Lösung bereitgestellt.
Kurz gesagt funktioniert diese Methode so, dass Datenbankverknüpfungen zu fest codierten Eingabeaufforderungen verwendet werden, die manuell verwaltet werden müssen. Wenn der Benutzer dann eine Eingabeaufforderung eingibt, wird dieser Inhalt zuerst mit dem ähnlichsten Eintrag in dieser Datenbank abgeglichen. Die Datenbank gibt dann eine fest codierte Eingabeaufforderung zurück, die dann an LLM übergeben wird. Wenn man also die hartcodierte Eingabeaufforderung sorgfältig testet, kann man sicherstellen, dass die Interaktion nicht von erlaubten Themen usw. abweicht.
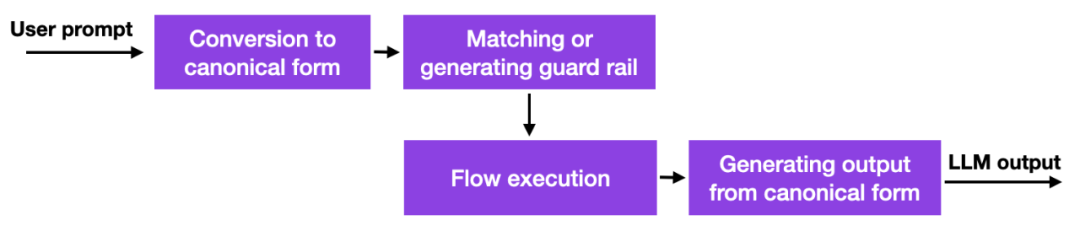
Dies ist ein interessanter, aber nicht bahnbrechender Ansatz, da er dem LLM keine besseren oder neuen Funktionen bietet, sondern lediglich das Ausmaß einschränkt, in dem der Benutzer mit dem LLM interagieren kann. Bis Forscher jedoch alternative Wege zur Linderung von Halluzinationsproblemen und negativen Verhaltensweisen bei LLM finden, könnte dies ein praktikabler Ansatz sein.
Der Leitplanken-Ansatz kann auch mit anderen Ausrichtungstechniken kombiniert werden, wie zum Beispiel dem beliebten Trainingsparadigma zur Verstärkung des menschlichen Feedbacks, das der Autor in einer früheren Ausgabe von Ahead of AI vorgestellt hat.
Konsistenzmodelle
Es ist ein guter Versuch, über andere interessante Modelle als LLM zu sprechen. OpenAI hat den Code seines Konsistenzmodells endlich als Open Source bereitgestellt: https://github.com/openai/consistency_models.
Das Konsistenzmodell gilt als praktikable und effiziente Alternative zum Diffusionsmodell. Weitere Informationen erhalten Sie im Konsistenzmodellpapier.
Das obige ist der detaillierte Inhalt vonGroße Modelle läuten die „Open-Source-Saison' ein und ziehen eine Bestandsaufnahme des Open-Source-LLM und der Datensätze des vergangenen Monats. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr