
Heim >Technologie-Peripheriegeräte >KI >GPT-4 gewinnt den neuen SOTA des schwierigsten mathematischen Argumentationsdatensatzes, und das neue Prompting verbessert die Argumentationsfähigkeiten großer Modelle erheblich
GPT-4 gewinnt den neuen SOTA des schwierigsten mathematischen Argumentationsdatensatzes, und das neue Prompting verbessert die Argumentationsfähigkeiten großer Modelle erheblich

- 王林nach vorne
- 2023-05-18 09:13:051423Durchsuche
Kürzlich veröffentlichte Huawei Lianhe Port Chinese einen Artikel mit dem Titel „Progressive-Hint Prompting Improves Reasoning in Large Language Models“, in dem Progressive-Hint Prompting (PHP) vorgeschlagen wird, um den Prozess der Beantwortung menschlicher Fragen zu simulieren. Unter dem PHP-Framework kann das Large Language Model (LLM) die mehrmals generierten Argumentationsantworten als Hinweise für nachfolgende Überlegungen verwenden und so der endgültigen richtigen Antwort schrittweise näher kommen. Um PHP zu verwenden, müssen Sie nur zwei Anforderungen erfüllen: 1) Die Frage kann mit der Inferenzantwort zusammengeführt werden, um eine neue Frage zu bilden. 2) Das Modell kann diese neue Frage verarbeiten und eine neue Inferenzantwort geben.
Die Ergebnisse zeigen, dass GP-T-4+PHP eine bessere Leistung erbringt Am Set wurden mehrere Daten-SOTA-Ergebnisse erzielt, darunter SVAMP (91,9 %), AQuA (79,9 %), GSM8K (95,5 %) und MATH (53,9 %). Diese Methode übertrifft GPT-4+CoT deutlich. Beispielsweise beträgt GPT-4+CoT im schwierigsten mathematischen Argumentationsdatensatz MATH nur 42,5 %, während sich GPT-4+PHP in der Teilmenge der Nember-Theorie (Zahlentheorie) des MATH-Datensatzes um 6,1 % verbessert, wodurch sich der Wert erhöht insgesamt MATH auf 53,9 % und erreicht SOTA.

- # 🎜 🎜#Papier-Link: https://arxiv.org/abs/2304.09797
- Code-Link: https:/ /github.com/chuanyang-Zheng/Progressive-Hint
Mit der Entwicklung von LLM Es sind einige Arbeiten zum Thema Aufforderung entstanden, darunter zwei Hauptrichtungen:
- Eine basiert auf Chain-Of-Thought (CoT, Chain of Gedanken) Repräsentativ: Stimulieren Sie die Argumentationsfähigkeit des Modells, indem Sie den Argumentationsprozess klar aufschreiben. Der andere wird durch Selbstkonsistenz (SC) durch Stichproben dargestellt Mehrere Antworten. Dann stimmen Sie ab, um die endgültige Antwort zu erhalten.
- Offensichtlich nehmen die beiden vorhandenen Methoden keine Änderungen am Problem vor, was dem einmaligen Beenden der Frage ohne Rückmeldung entspricht und überprüfen Sie noch einmal die Antworten. PHP versucht, einen menschlicheren Denkprozess zu simulieren: Verarbeiten Sie den letzten Denkprozess, fügen Sie ihn dann in die ursprüngliche Frage ein und bitten Sie LLM, erneut zu argumentieren. Wenn die letzten beiden Inferenzantworten konsistent sind, ist die erhaltene Antwort korrekt und die endgültige Antwort wird zurückgegeben. Das spezifische Flussdiagramm lautet wie folgt:
Zum ersten Mal mit LLM Bei der Interaktion sollte Base Prompting verwendet werden, wobei es sich bei dem Prompt um einen Standard-Prompt, einen CoT-Prompt oder eine verbesserte Version davon handeln kann. Mit Base Prompting können Sie eine erste Interaktion durchführen und eine vorläufige Antwort erhalten. Bei nachfolgenden Interaktionen sollte PHP verwendet werden, bis die beiden letzten Antworten übereinstimmen. 
PHP-Eingabeaufforderung wurde basierend auf Basis-Eingabeaufforderung geändert. Bei gegebener Basis-Eingabeaufforderung kann die entsprechende PHP-Eingabeaufforderung über die formulierten PHP-Eingabeaufforderungs-Designprinzipien abgerufen werden. Insbesondere wie in der folgenden Abbildung gezeigt:
Der Autor hofft, dass PHP auffordert kann große Modelle erstellen. Zwei Zuordnungsmodi gelernt: 
1) Wenn der gegebene Hinweis die richtige Antwort ist, muss die zurückgegebene Antwort immer noch die richtige Antwort sein (insbesondere wie gezeigt). in der Abbildung oben: „Hinweis ist die richtige Antwort“); Hinweis auf die falsche Antwort und Rückgabe der richtigen Antwort (spezifisch) Wie in der Abbildung oben gezeigt („Hinweis ist die falsche Antwort“).
Gemäß dieser PHP-Prompt-Designregel kann der Autor bei jedem vorhandenen Basis-Prompt den entsprechenden PHP-Prompt festlegen.
Experimente
Die Autoren verwenden sieben Datensätze, darunter AddSub, MultiArith, SingleEQ, SVAMP, GSM8K, AQuA und MATH. Gleichzeitig verwendete der Autor insgesamt vier Modelle, um die Ideen des Autors zu überprüfen, darunter text-davinci-002, text-davinci-003, GPT-3.5-Turbo und GPT-4.
Wichtige Ergebnisse
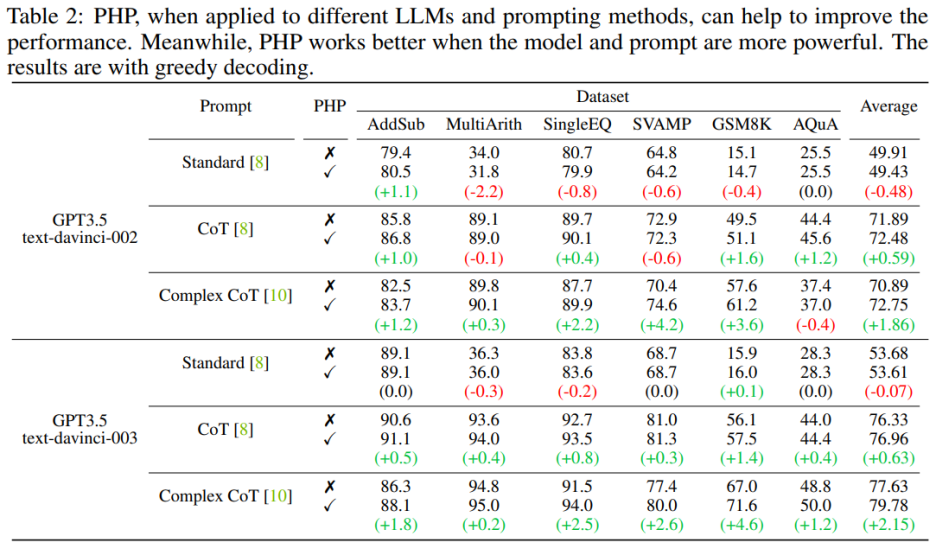
PHP ist leistungsfähiger, wenn das Sprachmodell leistungsfähiger und die Hinweise effektiver sind. Die komplexe CoT-Eingabeaufforderung weist im Vergleich zur Standard-Eingabeaufforderung und der CoT-Eingabeaufforderung erhebliche Leistungsverbesserungen auf. Die Analyse zeigt auch, dass das mithilfe von Reinforcement Learning optimierte Sprachmodell text-davinci-003 eine bessere Leistung erbringt als das mithilfe überwachter Anweisungen optimierte Modell text-davinci-002, wodurch die Dokumentleistung verbessert wird. Die Leistungsverbesserungen von text-davinci-003 werden auf seine verbesserte Fähigkeit zurückgeführt, eine bestimmte Eingabeaufforderung besser zu verstehen und anzuwenden. Wenn Sie jedoch nur die Standard-Eingabeaufforderung verwenden, ist die durch PHP erzielte Verbesserung nicht offensichtlich. Wenn PHP effektiv sein muss, ist zumindest CoT erforderlich, um die Argumentationsfähigkeiten des Modells zu stimulieren.
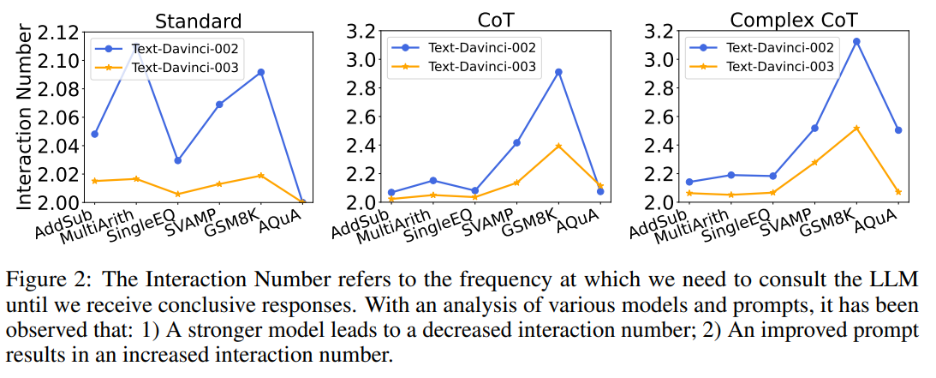
Gleichzeitig untersuchte der Autor auch den Zusammenhang zwischen der Anzahl der Interaktionen und Modellen und Aufforderungen. Wenn das Sprachmodell stärker und die Hinweise schwächer sind, nimmt die Anzahl der Interaktionen ab. Die Anzahl der Interaktionen bezieht sich auf die Häufigkeit, mit der der Agent mit LLMs interagiert. Beim Empfang der ersten Antwort beträgt die Anzahl der Interaktionen 1; beim Empfang der zweiten Antwort erhöht sich die Anzahl der Interaktionen auf 2. In Abbildung 2 zeigen die Autoren die Anzahl der Interaktionen für verschiedene Modelle und Eingabeaufforderungen. Die Forschungsergebnisse des Autors zeigen, dass:
1) Bei gleicher Eingabeaufforderung ist die Anzahl der Interaktionen von text-davinci-003 im Allgemeinen geringer als die von text-davinci-002. Dies ist hauptsächlich auf die höhere Genauigkeit von text-davinci-003 zurückzuführen, die zu einer höheren Genauigkeit der Basisantwort und der nachfolgenden Antworten führt und somit weniger Interaktion erfordert, um die endgültige richtige Antwort zu erhalten
2) Bei Verwendung des gleichen As Wenn Sie modellieren, nimmt die Anzahl der Interaktionen normalerweise zu, wenn die Eingabeaufforderung leistungsfähiger wird. Denn wenn Eingabeaufforderungen effektiver werden, werden die Denkfähigkeiten von LLMs besser genutzt, sodass sie die Eingabeaufforderungen nutzen können, um zu falschen Antworten zu springen, was letztendlich dazu führt, dass eine höhere Anzahl von Interaktionen erforderlich ist, um zur endgültigen Antwort zu gelangen, was die Anzahl der Interaktionen erhöht Interaktionen.
Hinweis Auswirkungen der Qualität
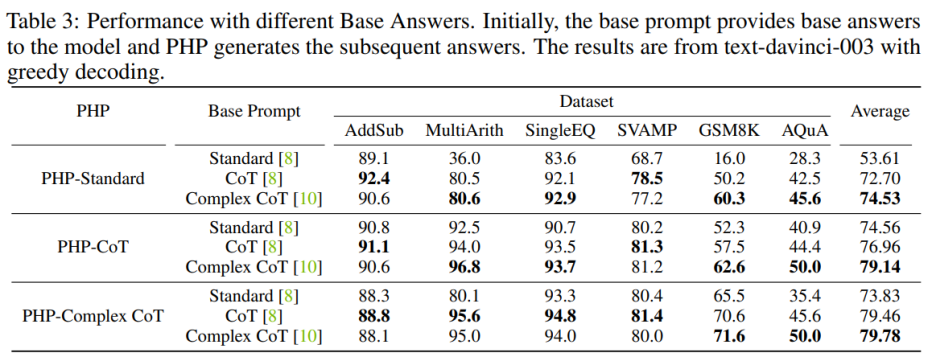
Um die Leistung von PHP-Standard zu verbessern, kann das Ersetzen von Base Prompt Standard durch Complex CoT oder CoT die endgültige Leistung erheblich verbessern. Für PHP-Standard stellten die Autoren fest, dass sich die Leistung von GSM8K von 16,0 % unter Base Prompt Standard auf 50,2 % unter Base Prompt CoT und 60,3 % unter Base Prompt Complex CoT verbesserte. Wenn Sie umgekehrt Base Prompt Complex CoT durch Standard ersetzen, wird die Leistung am Ende geringer sein. Nachdem beispielsweise der Basis-Prompt Complex CoT durch Standard ersetzt wurde, sank die Leistung von PHP-Complex CoT im GSM8K-Datensatz von 71,6 % auf 65,5 %.
Wenn PHP nicht auf der Grundlage des entsprechenden Basis-Prompts entwickelt wird, kann der Effekt noch weiter verbessert werden. PHP-CoT mit Base Prompt Complex CoT schnitt in vier der sechs Datensätze besser ab als PHP-CoT mit CoT. Ebenso schneidet PHP-Complex CoT mit Base Prompt CoT in vier der sechs Datensätze besser ab als PHP-Complex CoT mit Base Prompt Complex CoT. Der Autor vermutet, dass dies zwei Gründe hat: 1) Die Leistung von CoT und Complex CoT ist bei allen sechs Datensätzen ähnlich, 2) weil die Basisantwort von CoT (oder Complex CoT) bereitgestellt wird und dies auch bei den nachfolgenden Antworten der Fall ist basiert auf PHP-Complex CoT (oder PHP-CoT), was dem Äquivalent der Zusammenarbeit zweier Personen zur Lösung eines Problems entspricht. Daher kann in diesem Fall die Leistung des Systems weiter verbessert werden.
Ablationsexperiment
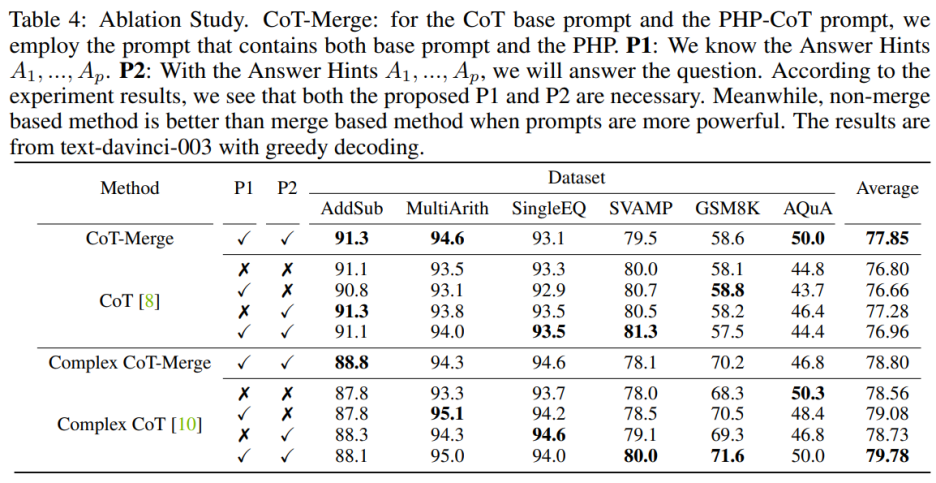
Das Einbeziehen der Sätze P1 und P2 in das Modell kann die Leistung von CoT für die drei Datensätze verbessern, aber wann Die Bedeutung dieser beiden Sätze wird besonders deutlich, wenn man die Complex CoT-Methode verwendet. Nach dem Hinzufügen von P1 und P2 wird die Leistung der Methode in fünf der sechs Datensätze verbessert. Beispielsweise verbessert sich die Leistung von Complex CoT beim SVAMP-Datensatz von 78,0 % auf 80,0 % und beim GSM8K-Datensatz von 68,3 % auf 71,6 %. Dies zeigt, dass die Wirkung der Sätze P1 und P2 signifikanter ist, insbesondere wenn die logischen Fähigkeiten des Modells stärker sind.
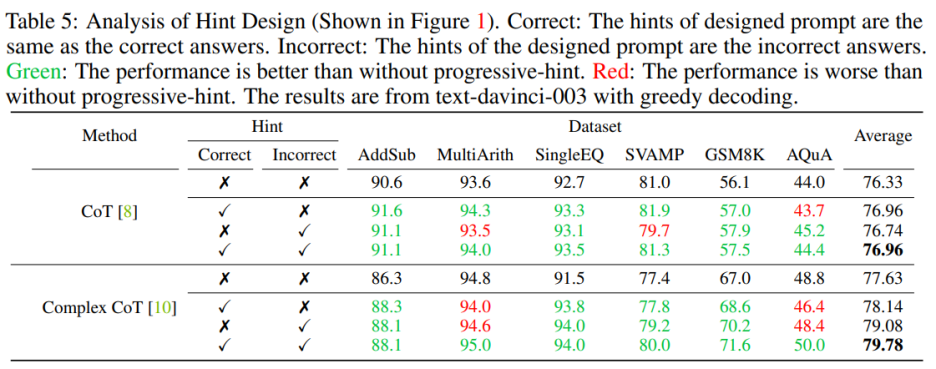
Sie müssen beim Entwerfen sowohl richtige als auch falsche Eingabeaufforderungen berücksichtigen. Beim Entwerfen von Hinweisen, die sowohl richtige als auch falsche Hinweise enthalten, ist die Verwendung von PHP besser als die Nichtverwendung von PHP. Insbesondere erleichtert die Bereitstellung des richtigen Hinweises in der Eingabeaufforderung die Generierung von Antworten, die mit dem gegebenen Hinweis übereinstimmen. Im Gegenteil, die Bereitstellung falscher Hinweise in der Eingabeaufforderung fördert die Generierung anderer Antworten durch die gegebene Eingabeaufforderung 🎜#
#🎜 🎜#
#🎜 🎜#
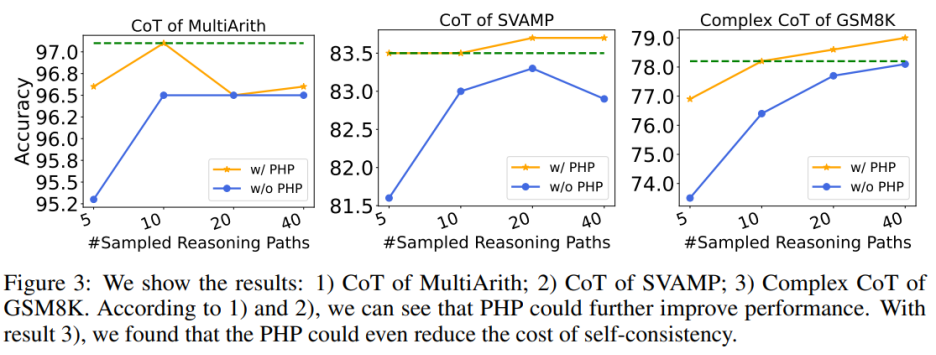
Die Verwendung von PHP kann die Leistung weiter verbessern. Durch die Verwendung ähnlicher Hinweise und einer ähnlichen Anzahl von Beispielpfaden stellten die Autoren fest, dass in Tabelle 6 und Abbildung 3 die von den Autoren vorgeschlagenen PHP-CoT- und PHP-Complex-CoT-Vorschläge immer eine bessere Leistung erbrachten als CoT und Complex-CoT. CoT+SC ist beispielsweise in der Lage, eine Genauigkeit von 96,5 % für den MultiArith-Datensatz mit Stichprobenpfaden von 10, 20 und 40 zu erreichen. Daher kann der Schluss gezogen werden, dass die beste Leistung von CoT+SC bei Verwendung von text-davinci-003 96,5 % beträgt. Nach der Implementierung von PHP stieg die Leistung jedoch auf 97,1 %. In ähnlicher Weise stellten die Autoren auch fest, dass im SVAMP-Datensatz die beste Genauigkeit von CoT+SC 83,3 % betrug, was sich nach der Implementierung von PHP weiter auf 83,7 % verbesserte. Dies zeigt, dass PHP Leistungsengpässe beseitigen und die Leistung weiter verbessern kann. 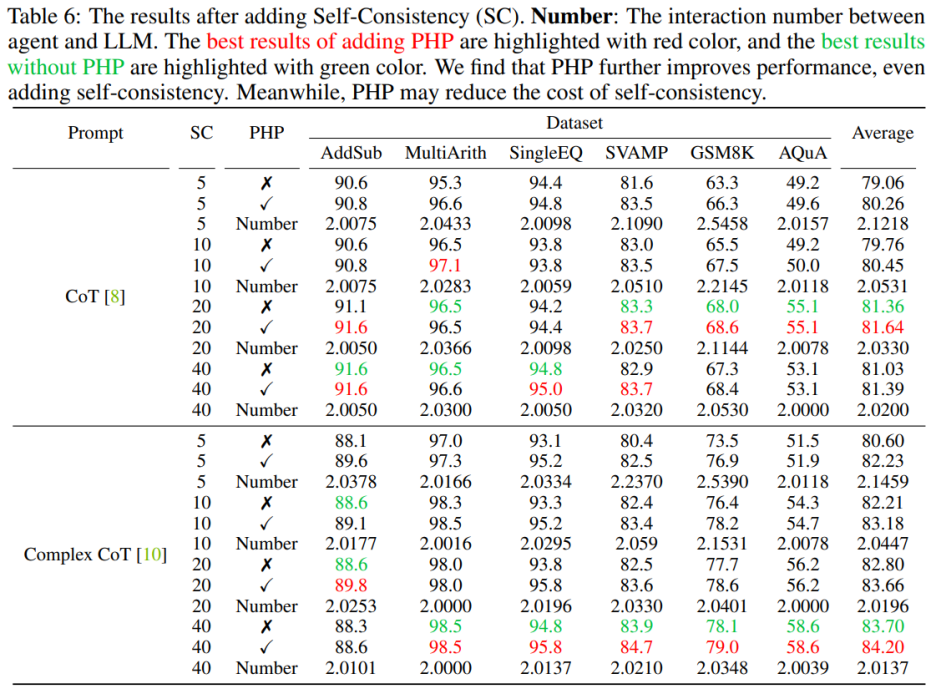
Die Verwendung von PHP kann die Kosten von SC senken. Wie wir alle wissen, erfordert SC mehr Argumentationspfade, was zu höheren Kosten führt. Tabelle 6 zeigt, dass PHP eine effektive Möglichkeit sein kann, Kosten zu senken und gleichzeitig Leistungssteigerungen aufrechtzuerhalten. Wie in Abbildung 3 dargestellt, können bei Verwendung von SC+Complex CoT 40 Beispielpfade verwendet werden, um eine Genauigkeit von 78,1 % zu erreichen, während das Hinzufügen von PHP die erforderlichen durchschnittlichen Inferenzpfade auf 10 × 2,1531 = 21,531 Pfade reduziert und die Ergebnisse immer besser werden genau Die Rate erreichte 78,2 %. Autor In Anlehnung an den Aufbau früherer Arbeiten wurden Experimente mit einem Textgenerierungsmodell durchgeführt. Mit der API-Veröffentlichung von GPT-3.5-Turbo und GPT-4 überprüften die Autoren die Leistung von Complex CoT mit PHP anhand derselben sechs Datensätze. Die Autoren verwenden Greedy Decoding (d. h. Temperatur = 0) und Complex CoT als Hinweise für beide Modelle.
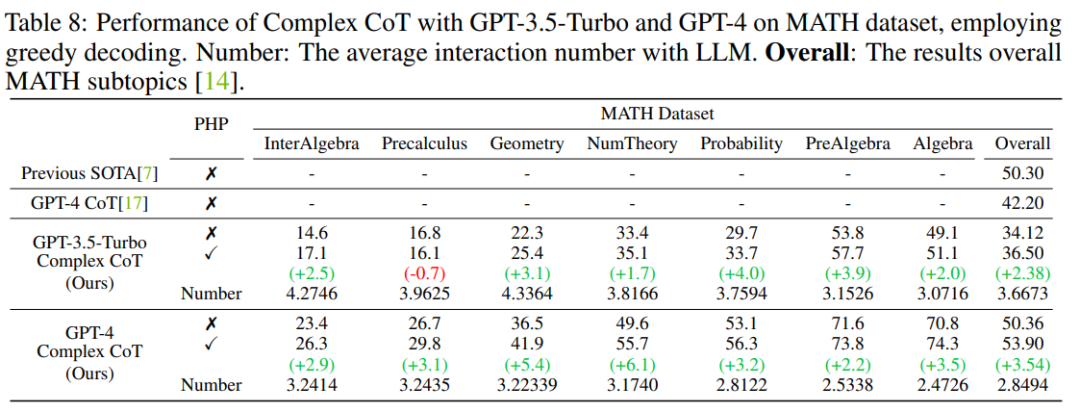
Nach dem Einsatz des GPT-4-Modells konnten die Autoren neue SOTA-Leistungen bei SVAMP-, GSM8K-, AQuA- und MATH-Benchmarks erzielen. Die vom Autor vorgeschlagene PHP-Methode verbessert kontinuierlich die Leistung von GPT-4. Darüber hinaus stellten die Autoren fest, dass GPT-4 im Vergleich zum GPT-3.5-Turbo-Modell weniger Interaktionen erforderte, was mit der Feststellung übereinstimmt, dass die Anzahl der Interaktionen abnimmt, wenn das Modell leistungsfähiger ist.
Zusammenfassung
Dieses Dokument stellt eine neue Möglichkeit für PHP zur Interaktion mit LLMs vor, die mehrere Vorteile bietet: 1) PHP erzielt erhebliche Leistungsverbesserungen bei mathematischen Argumentationsaufgaben und führt den Stand der Technik bei mehreren Argumentations-Benchmarks an Ergebnisse; 2) PHP kann LLMs durch die Verwendung leistungsfähigerer Modelle und Hinweise besser nutzen; 3) PHP kann leicht mit CoT und SC kombiniert werden, um die Leistung weiter zu verbessern.
Um die PHP-Methode besser zu verbessern, kann sich die zukünftige Forschung auf die Verbesserung des Designs manueller Eingabeaufforderungen in der Fragephase und von Eingabeaufforderungssätzen im Antwortteil konzentrieren. Darüber hinaus können nicht nur Antworten als Hinweise behandelt werden, sondern auch neue Hinweise identifiziert und extrahiert werden, die LLMs dabei helfen, das Problem noch einmal zu überdenken.
Das obige ist der detaillierte Inhalt vonGPT-4 gewinnt den neuen SOTA des schwierigsten mathematischen Argumentationsdatensatzes, und das neue Prompting verbessert die Argumentationsfähigkeiten großer Modelle erheblich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr