
Heim >Technologie-Peripheriegeräte >KI >Stellt die Worteinbettung einen zu großen Anteil an Parametern dar? MorphTE-Methode 20-facher Komprimierungseffekt ohne Verlust
Stellt die Worteinbettung einen zu großen Anteil an Parametern dar? MorphTE-Methode 20-facher Komprimierungseffekt ohne Verlust

- 王林nach vorne
- 2023-05-17 16:01:061369Durchsuche
Einführung
Die Darstellung der Worteinbettung ist die Grundlage für verschiedene Verarbeitungsaufgaben natürlicher Sprache wie maschinelle Übersetzung, Beantwortung von Fragen, Textklassifizierung usw. Sie macht normalerweise 20 bis 90 % der gesamten Modellparameter aus. Das Speichern und Zugreifen auf diese Einbettungen erfordert viel Speicherplatz, was der Modellbereitstellung und -anwendung auf Geräten mit begrenzten Ressourcen nicht förderlich ist. Um dieses Problem anzugehen, wird in diesem Artikel die MorphTE-Worteinbettungskomprimierungsmethode vorgeschlagen. MorphTE kombiniert die leistungsstarken Komprimierungsfunktionen von Tensorproduktoperationen mit Vorkenntnissen der Sprachmorphologie, um eine hohe Komprimierung der Worteinbettungsparameter (mehr als 20 Mal) bei gleichzeitiger Beibehaltung der Modellleistung zu erreichen.

- Papierlink: https://arxiv.org/abs/2210.15379
- Offener Quellcode: https://github.com/bigganbing/Fairseq_MorphTE
Modell
Die in diesem Artikel vorgeschlagene MorphTE-Worteinbettungskomprimierungsmethode unterteilt Wörter zunächst in die kleinsten Einheiten mit semantischer Bedeutung – Morpheme – und trainiert eine niedrigdimensionale Vektordarstellung für jedes Morphem und verwendet dann Tensorprodukte, um das Quantum der niedrigdimensionalen zu realisieren. dimensionale Morphemvektoren Der verschränkte Zustand wird mathematisch dargestellt, um eine hochdimensionale Wortdarstellung zu erhalten.
01 Die Morphemzusammensetzung eines Wortes
In der Linguistik ist ein Morphem die kleinste Einheit mit bestimmten semantischen oder grammatikalischen Funktionen. Bei Sprachen wie Englisch kann ein Wort in kleinere Morphemeinheiten wie Wurzeln und Affixe aufgeteilt werden. Beispielsweise kann „unfreundlich“ in „un“ für Verneinung, „kind“ für etwas wie „freundlich“ und „ly“ für ein Adverb aufgeteilt werden. Für Chinesisch kann ein chinesisches Schriftzeichen auch in kleinere Einheiten wie Radikale aufgeteilt werden, beispielsweise kann „MU“ in „氵“ und „木“ aufgeteilt werden, die für Wasser stehen.

Während Morpheme Semantik enthalten, können sie auch zwischen Wörtern geteilt werden, um verschiedene Wörter zu verbinden. Darüber hinaus kann eine begrenzte Anzahl von Morphemen zu einer größeren Anzahl von Wörtern kombiniert werden.
02 Komprimierte Darstellung von Worteinbettungen in Form verschränkter Tensoren
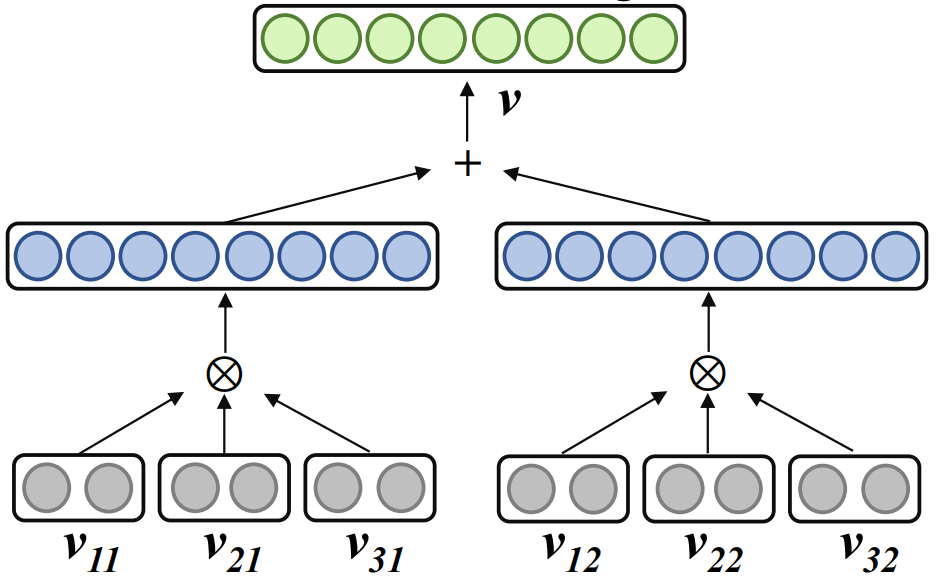
Verwandte Arbeit Word2ket verwendet ein Tensorprodukt, um eine einzelne Worteinbettung als verschränkte Tensorform mehrerer niedrigdimensionaler Vektoren darzustellen :
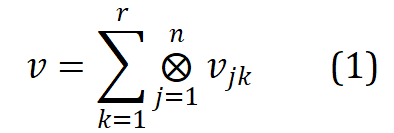
wobei , r der Rang, n die Ordnung und das Tensorprodukt darstellt. Word2ket muss diese niedrigdimensionalen Vektoren nur speichern und verwenden, um hochdimensionale Wortvektoren zu erstellen und so eine effektive Parameterreduzierung zu erreichen. Wenn beispielsweise r = 2 und n = 3 ist, kann ein Wortvektor mit einer Dimension von 512 durch zwei Gruppen von drei niedrigdimensionalen Vektortensorprodukten mit einer Dimension von 8 in jeder Gruppe erhalten werden Anzahl der Parameter wird von 512 auf 48 reduziert.
03 Morphologie-verbesserte Tensorwort-Einbettungskomprimierungsdarstellung
Durch das Tensorprodukt kann Word2ket eine offensichtliche Parameterkomprimierung erreichen. Bei komplexeren Aufgaben wie Hochleistungskomprimierung und Maschinen ist es jedoch normalerweise schwierig, eine Vorkomprimierungsleistung zu erzielen Übersetzung. Wirkung. Da niedrigdimensionale Vektoren die Grundeinheiten sind, aus denen Verschränkungstensoren bestehen, und Morpheme die Grundeinheiten sind, aus denen Wörter bestehen. Diese Studie befasst sich mit der Einführung sprachlicher Kenntnisse und schlägt MorphTE vor, das niedrigdimensionale Morphemvektoren trainiert und das Tensorprodukt der im Wort enthaltenen Morphemvektoren verwendet, um die entsprechende Worteinbettungsdarstellung zu erstellen.
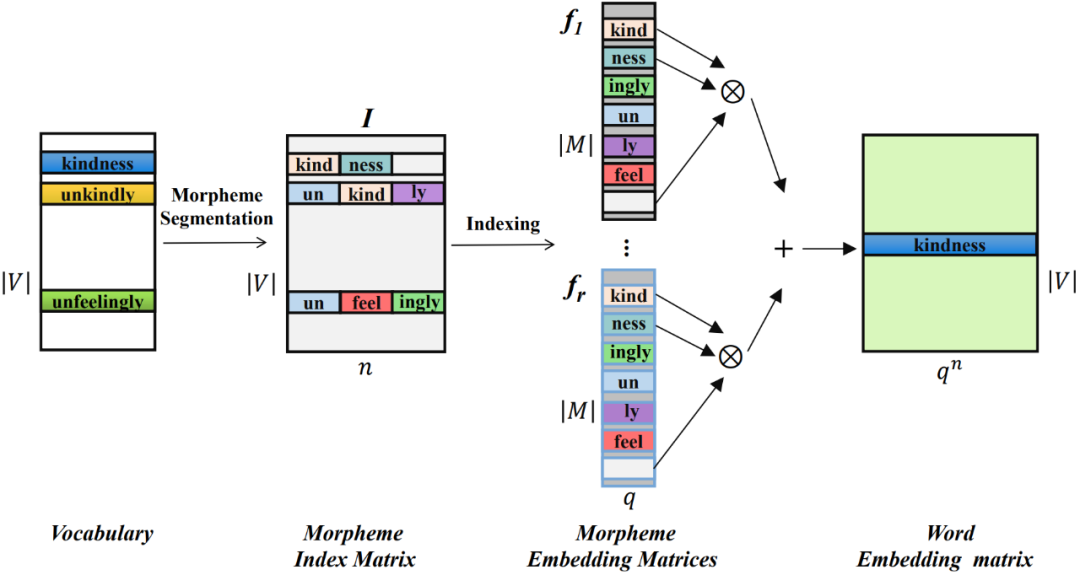
Insbesondere verwenden Sie zunächst das Morphem-Segmentierungstool, um die Wörter in der Vokabelliste V zu segmentieren. Die Morpheme aller Wörter bilden eine Morphemliste M, und die Anzahl der Morpheme ist deutlich geringer als die Anzahl von Wörtern ( ).
Konstruieren Sie für jedes Wort seinen Morphem-Indexvektor, der auf die Position des in jedem Wort enthaltenen Morphems in der Morphemtabelle zeigt. Die Morphem-Indexvektoren aller Wörter bilden eine Morphem-Indexmatrix von 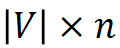 , wobei n die Ordnung von MorphTE ist.
, wobei n die Ordnung von MorphTE ist.
Für das j-te Wort 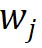 im Vokabular verwenden Sie seinen Morphem-Indexvektor #🎜🎜 ## 🎜🎜# Indexieren Sie den entsprechenden Morphemvektor aus r Gruppen parametrisierter Morphemeinbettungsmatrizen und führen Sie eine verschränkte Tensordarstellung durch Tensorprodukt durch, um die entsprechende Worteinbettung zu erhalten:
im Vokabular verwenden Sie seinen Morphem-Indexvektor #🎜🎜 ## 🎜🎜# Indexieren Sie den entsprechenden Morphemvektor aus r Gruppen parametrisierter Morphemeinbettungsmatrizen und führen Sie eine verschränkte Tensordarstellung durch Tensorprodukt durch, um die entsprechende Worteinbettung zu erhalten: 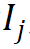 #🎜 🎜##🎜🎜 #
#🎜 🎜##🎜🎜 #
Auf die oben beschriebene Weise kann MophTE morphembasiertes sprachliches Vorwissen in die Worteinbettungsdarstellung injizieren, während die Morphemvektoren in verschiedenen Teilen zwischen Wörtern explizit verwendet werden können Bauen Sie Verbindungen zwischen Wörtern auf. Darüber hinaus sind die Anzahl und Vektordimensionen von Morphemen viel geringer als die Größe und Dimension des Vokabulars, und MophTE erreicht eine Komprimierung der Worteinbettungsparameter aus beiden Perspektiven. Daher ist MophTE in der Lage, eine qualitativ hochwertige Komprimierung von Worteinbettungsdarstellungen zu erreichen. 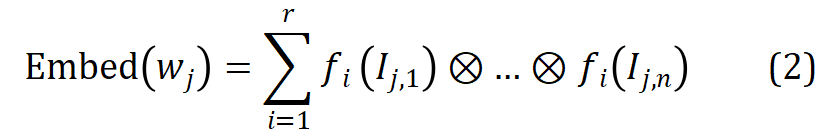
Experiment
In diesem Artikel werden hauptsächlich Experimente zu Übersetzungs-, Frage- und Antwortaufgaben in verschiedenen Sprachen und zugehörigen Worteinbettungen basierend auf Zerlegungs- und Komprimierungsmethoden durchgeführt werden verglichen.
Wie Sie der Tabelle entnehmen können, kann sich MorphTE an verschiedene Sprachen wie Englisch, Deutsch, Italienisch usw. Bei einem Komprimierungsverhältnis von mehr als dem 20-fachen ist MorphTE in der Lage, die Wirkung des Originalmodells beizubehalten, während bei fast allen anderen Komprimierungsmethoden eine Wirkungsabnahme zu verzeichnen ist. Darüber hinaus schneidet MorphTE mit einem Komprimierungsverhältnis von mehr als dem 40-fachen bei verschiedenen Datensätzen besser ab als andere Komprimierungsmethoden. #?? 38-faches Komprimierungsverhältnis unter Beibehaltung der Wirkung des Modells. 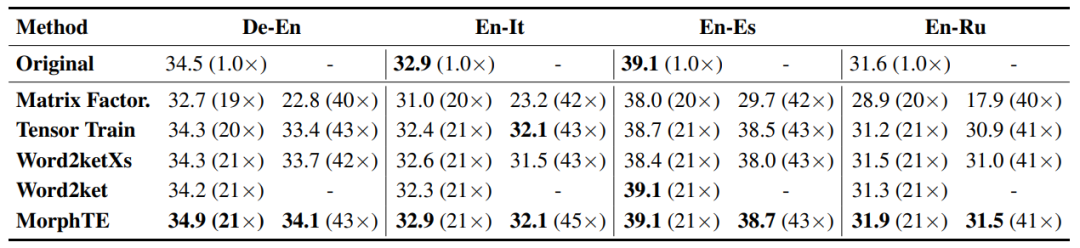
Fazit
MorphTE kombiniert a priori morphologische Sprachkenntnisse und die leistungsstarke Komprimierungsfähigkeit von Tensorprodukten, um eine qualitativ hochwertige Komprimierung von Worteinbettungen zu erreichen. Experimente mit verschiedenen Sprachen und Aufgaben zeigen, dass MorphTE eine 20- bis 80-fache Komprimierung der Worteinbettungsparameter erreichen kann, ohne die Wirkung des Modells zu beeinträchtigen. Dies bestätigt, dass die Einführung von morphembasiertem Sprachwissen das Erlernen komprimierter Darstellungen von Worteinbettungen verbessern kann. Obwohl MorphTE derzeit nur Morpheme modelliert, kann es tatsächlich zu einem allgemeinen Framework zur Verbesserung der Worteinbettungskomprimierung erweitert werden, das explizit mehr apriorisches linguistisches Wissen wie Prototypen, Wortarten, Groß- und Kleinschreibung usw. modelliert, um die Worteinbettungskomprimierung weiter zu verbessern.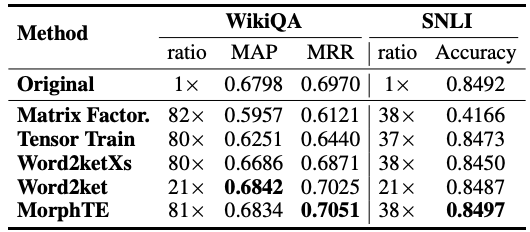
Das obige ist der detaillierte Inhalt vonStellt die Worteinbettung einen zu großen Anteil an Parametern dar? MorphTE-Methode 20-facher Komprimierungseffekt ohne Verlust. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr