
Heim >Technologie-Peripheriegeräte >KI >Video-Frage- und Antwortmodell „Iterative Joint Certification' von Google und MIT: SOTA-Leistung bei 80 % weniger Rechenleistung
Video-Frage- und Antwortmodell „Iterative Joint Certification' von Google und MIT: SOTA-Leistung bei 80 % weniger Rechenleistung

- PHPznach vorne
- 2023-05-16 18:37:061192Durchsuche
Videos sind eine allgegenwärtige Quelle für Medieninhalte, die viele Aspekte des täglichen Lebens der Menschen berühren. Immer mehr reale Videoanwendungen wie Videountertitelung, Inhaltsanalyse und Video-Fragenbeantwortung (VideoQA) stützen sich auf Modelle, die Videoinhalte mit Text oder natürlicher Sprache verbinden können.
Unter diesen stellt das Video-Frage- und Antwortmodell eine besondere Herausforderung dar, da es gleichzeitig semantische Informationen wie Ziele in der Szene und zeitliche Informationen wie z. B. erfassen muss wie sich Dinge bewegen und interagieren. Beide Arten von Informationen müssen mit einer bestimmten Absicht in den Kontext einer natürlichsprachlichen Frage gestellt werden. Da Videos außerdem über viele Frames verfügen, kann die Verarbeitung aller Frames zum Erlernen raumzeitlicher Informationen rechenintensiv sein.

Papierlink: https://arxiv.org/pdf/2208.00934.pdf#🎜 🎜# Um dieses Problem zu lösen, stellten Forscher von Google und MIT im Artikel „Video Question Answering with Iterative Video-Text Co-Tokenization“ eine neue Methode des Videotext-Lernens vor Durch „iteratives Co-Labeling“ können räumliche, zeitliche und sprachliche Informationen effektiv für die Informationsverarbeitung in Videofragen und -antworten zusammengeführt werden.

Diese Methode ist Multi-Flow Verwenden Sie unabhängige Backbone-Modelle, um Videos unterschiedlicher Maßstäbe zu verarbeiten und Videodarstellungen zu erstellen, die unterschiedliche Eigenschaften erfassen, z. B. Videos mit hoher räumlicher Auflösung oder langer Dauer. Das Modell wendet das Modul „Co-Authentifizierung“ an, um effektive Darstellungen aus der Fusion von Videostreams und Text zu erlernen. Das Modell ist sehr recheneffizient und benötigt nur 67 GFLOPs, was mindestens 50 % weniger als die vorherige Methode ist, und weist eine bessere Leistung als andere SOTA-Modelle auf.
Video-Text IterationDas Hauptziel dieses Modells besteht darin, Funktionen aus Video und Text (d. h. Benutzerfragen) zu generieren, die gemeinsam ermöglichen sie mit der entsprechenden Eingabe interagieren. Das zweite Ziel besteht darin, dies auf effiziente Weise zu tun, was für Videos sehr wichtig ist, da sie Dutzende bis Hunderte von Eingabebildern enthalten.
Das Modell lernt, die gemeinsame Video-Spracheingabe in kleinere Etikettensätze zu kennzeichnen, um beide Modalitäten gemeinsam und effektiv darzustellen. Bei der Tokenisierung verwenden Forscher beide Modi, um eine gemeinsame kompakte Darstellung zu erstellen, die in eine Transformationsschicht eingespeist wird, um die Darstellung der nächsten Ebene zu erzeugen.
Eine Herausforderung, die auch ein typisches Problem beim modalübergreifenden Lernen ist, besteht darin, dass Videobilder oft nicht direkt mit verwandtem Text korrespondieren. Die Forscher lösten dieses Problem, indem sie zwei lernbare lineare Ebenen hinzufügten, um die visuellen und textuellen Merkmalsdimensionen vor der Tokenisierung zu vereinheitlichen. Dadurch konnten die Forscher sowohl Video- als auch Textbedingungen ermitteln, wie Video-Tags gelernt wurden.
Darüber hinaus ermöglicht ein einzelner Tokenisierungsschritt keine weitere Interaktion zwischen den beiden Modi. Dazu nutzen die Forscher diese neue Feature-Darstellung, um mit den Videoeingabe-Features zu interagieren und einen weiteren Satz tokenisierter Features zu erzeugen, die dann in die nächste Transformatorschicht eingespeist werden. Durch diesen iterativen Prozess entstehen neue Features oder Markierungen, die die kontinuierliche Verbesserung der gemeinsamen Darstellung der beiden Modi darstellen. Schließlich werden diese Funktionen in einen Decoder eingespeist, der eine Textausgabe generiert.

In Übereinstimmung mit der Praxis der Videoqualitätsbewertung, individuelle Videoqualitätsbewertung Daten Vor der Feinabstimmung des Satzes trainierten die Forscher das Modell vorab. In dieser Arbeit kommentierten die Forscher Videos automatisch mit Text auf Basis der Spracherkennung und verwendeten dabei den HowTo100M-Datensatz, anstatt vorab mit dem großen VideoQA-Datensatz zu trainieren. Diese schwächeren Daten vor dem Training ermöglichten es dem Modell der Forscher dennoch, Videotextfunktionen zu erlernen.
Implementierung einer effizienten Beantwortung von VideofragenForscher wandten den iterativen Co-Authentifizierungsalgorithmus der Videosprache auf drei wichtige VideoQA-Benchmarks an: MSRVTT-QA. MSVD-QA und IVQA und zeigen, dass dieser Ansatz bessere Ergebnisse erzielt als andere hochmoderne Modelle, ohne das Modell zu groß zu machen. Darüber hinaus erfordert iteratives Co-Label-Lernen auch eine geringere Rechenleistung bei Videotext-Lernaufgaben.
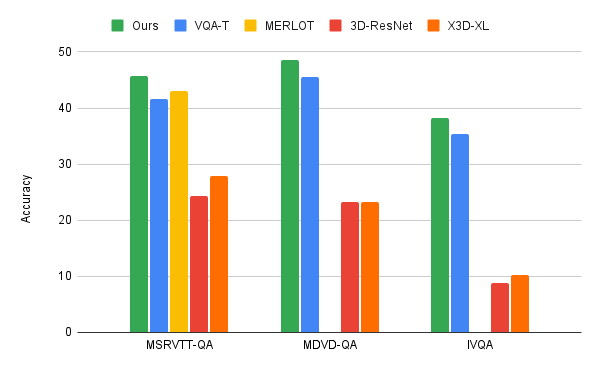
Dieses Modell verbraucht nur 67GFLOPS Rechenleistung, was einem Sechstel der Rechenleistung (360GFLOP) entspricht, die für 3D-ResNet-Videomodelle und -Text erforderlich ist, und mehr als die doppelte Effizienz des X3D-Modells . und lieferte hochpräzise Ergebnisse, die modernste Methoden übertrafen.
Multi-Stream-Videoeingabe
Für VideoQA oder andere Aufgaben mit Videoeingabe haben Forscher herausgefunden, dass Multi-Stream-Eingabe wichtig ist, um Fragen zu räumlichen und zeitlichen Beziehungen genauer zu beantworten.
Die Forscher verwendeten drei Videostreams mit unterschiedlichen Auflösungen und Bildraten: einen Eingangsvideostream mit niedriger Auflösung und hoher Bildrate (32 Bilder pro Sekunde, räumliche Auflösung 64x64, bezeichnet als 32x64x64); Bildfrequenzvideo (8x224x224); und eine dazwischen (16x112x112).
Obwohl bei drei Datenströmen offensichtlich mehr Informationen verarbeitet werden müssen, erhält man dank der iterativen Co-Labeling-Methode ein sehr effizientes Modell. Gleichzeitig ermöglichen diese zusätzlichen Datenströme die Extraktion der relevantesten Informationen.
Wie in der Abbildung unten gezeigt, führen beispielsweise Fragen zu bestimmten Aktivitäten zu höheren Aktivierungen bei Videoeingaben mit niedrigeren Auflösungen, aber höheren Bildraten, während Fragen zu allgemeinen Aktivitäten von niedriger Auflösung bis zu hohen Bildraten variieren können. Erhalten Sie Antworten mit weniger hochauflösenden Eingaben.

Ein weiterer Vorteil dieses Algorithmus besteht darin, dass sich die Tokenisierung je nach gestellter Frage ändert.
Fazit
Die Forscher schlugen eine neue Methode zum Erlernen von Videosprachen vor, die sich auf das gemeinsame Lernen über Videotextmodalitäten hinweg konzentriert. Forscher nehmen die wichtige und herausfordernde Aufgabe der Beantwortung von Videofragen in Angriff. Der Ansatz der Forscher ist effizient und genau und übertrifft aktuelle Modelle auf dem neuesten Stand der Technik, obwohl er effizienter ist.
Der Ansatz der Google-Forscher hat eine bescheidene Modellgröße und könnte mit größeren Modellen und Daten weitere Leistungsverbesserungen erzielen. Die Forscher hoffen, dass diese Arbeit weitere Forschungen zum visuellen Sprachenlernen anstoßen wird, um nahtlosere Interaktionen mit visuellen Medien zu ermöglichen.
Das obige ist der detaillierte Inhalt vonVideo-Frage- und Antwortmodell „Iterative Joint Certification' von Google und MIT: SOTA-Leistung bei 80 % weniger Rechenleistung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr