
Heim >Technologie-Peripheriegeräte >KI >Festlegen des besten Schwellenwerts für Modelle des maschinellen Lernens: Ist 0,5 der beste Schwellenwert für die binäre Klassifizierung?
Festlegen des besten Schwellenwerts für Modelle des maschinellen Lernens: Ist 0,5 der beste Schwellenwert für die binäre Klassifizierung?

- 王林nach vorne
- 2023-05-15 14:49:061086Durchsuche
Bei der binären Klassifizierung gibt der Klassifikator einen reellen Wert aus und ermittelt dann einen Schwellenwert für den Wert, um eine binäre Antwort zu generieren. Die logistische Regression gibt beispielsweise eine Wahrscheinlichkeit aus (einen Wert zwischen 0,0 und 1,0); Beobachtungen mit Werten gleich oder über 0,5 führen zu einer positiven Ausgabe (viele andere Modelle verwenden standardmäßig einen Schwellenwert von 0,5).
Aber die Verwendung des Standardschwellenwerts von 0,5 ist nicht ideal. In diesem Artikel werde ich zeigen, wie man den besten Schwellenwert aus einem binären Klassifikator auswählt. In diesem Artikel wird Plomber zur parallelen Ausführung unserer Experimente und zur Generierung von Diagrammen mithilfe von sklearn-evaluation verwendet.
Hier nehmen wir das Training der logistischen Regression als Beispiel. Angenommen, wir entwickeln ein Inhaltsmoderationssystem, bei dem das Modell Beiträge mit schädlichen Inhalten (Bilder, Videos usw.) markiert. Anschließend prüft ein Mensch diese und entscheidet, ob der Inhalt entfernt werden soll. 🎜🎜 und bewerten Sie die Leistung anhand der Verwirrungsmatrix:
import matplotlib.pyplot as plt import matplotlib as mpl from sklearn import datasets from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn_evaluation.plot import ConfusionMatrix # matplotlib settings mpl.rcParams['figure.figsize'] = (4, 4) mpl.rcParams['figure.dpi'] = 150 # create sample dataset X, y = datasets.make_classification(1000, 10, n_informative=5, class_sep=0.4) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # fit model clf = LogisticRegression() _ = clf.fit(X_train, y_train)Die Verwirrungsmatrix fasst die Leistung des Modells in vier Bereichen zusammen:
#🎜 🎜## 🎜🎜#
Wir möchten so viele Beobachtungen (aus dem Testsatz) wie möglich im oberen linken und unteren rechten Quadranten erhalten, da dies die korrekten Beobachtungen sind, die unser Modell erhalten kann. Die anderen Quadranten sind Modellfehler. 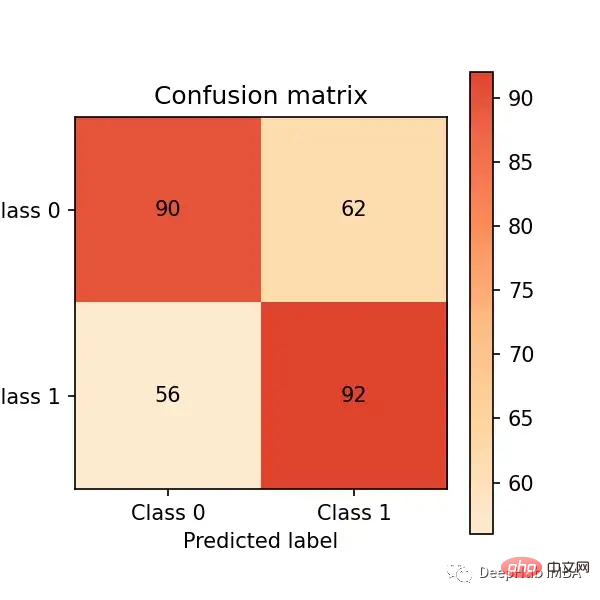
# predict on the test set y_pred = clf.predict(X_test) # plot confusion matrix cm_dot_five = ConfusionMatrix(y_test, y_pred) cm_dot_five# 🎜🎜# Wir können unseren Klassifikator aggressiver machen, indem wir einen niedrigeren Schwellenwert festlegen (d. h. mehr Beiträge als schädlich kennzeichnen) und eine neue Verwirrungsmatrix erstellen:
y_score = clf.predict_proba(X_test)
sklearn – Die Bewertungsbibliothek kann problemlos zwei Matrizen vergleichen: 
cm_dot_four = ConfusionMatrix(y_score[:, 1] >= 0.4, y_pred)Der obere Teil des Dreiecks stammt von der Schwelle von 0,5 und der untere Teil stammt von der Schwelle von 0,4:
Zwei Modelle für dasselbe Zahl Die Beobachtungen werden alle als 0 vorhergesagt (dies ist ein Zufall). 0,5-Schwelle: (90 + 56 = 146). 0,4-Schwellenwert: (78 + 68 = 146)
Eine Senkung des Schwellenwerts führt zu mehr falsch-negativen Ergebnissen (von 56 Fällen auf 68 Fälle)
Eine Senkung des Schwellenwerts führt zu einer erheblichen Erhöhung der Anzahl der falsch-negativen positiven Ergebnisse (von 92 Fällen auf 154 Fälle gestiegen)
Kleine Schwellenwertänderungen wirken sich stark auf die Verwirrungsmatrix aus. Wir haben nur zwei Schwellenwerte analysiert. Wenn wir dann die Modellleistung über alle Werte hinweg analysieren können, können wir die Schwellenwertdynamik besser verstehen. Doch bevor das passieren kann, müssen neue Metriken für die Modellbewertung definiert werden.- Bisher haben wir unsere Modelle anhand absoluter Zahlen bewertet. Um den Vergleich und die Bewertung zu erleichtern, definieren wir nun zwei normalisierte Metriken (ihre Werte liegen zwischen 0,0 und 1,0).
- PräzisionPräzision ist der Anteil der beobachteten Ereignisse, die gekennzeichnet sind (z. B. Beiträge, die unser Modell als schädlich erachtet, sind schädlich). Der Rückruf ist der Anteil der tatsächlichen Ereignisse, die von unserem Modell abgerufen wurden (d. h. welchen Anteil von allen schädlichen Beiträgen konnten wir erkennen).
Das obige Bild stammt aus Wikipedia, was gut veranschaulichen kann, wie diese beiden Indikatoren berechnet werden. Sie sind also beide proportional ein Verhältnis von 0 zu 1.
Experiment ausführen
Wir erhalten Präzisions-, Rückruf- und andere Statistiken basierend auf mehreren Schwellenwerten, um besser zu verstehen, wie sich die Schwellenwerte auf sie auswirken. Wir werden dieses Experiment auch mehrmals wiederholen, um die Variabilität zu messen.
Die Befehle in diesem Abschnitt sind alle Bash-Befehle. Sie müssen im Terminal ausgeführt werden. Wenn Sie Jupyter verwenden, können Sie den magischen Befehl %%sh verwenden. 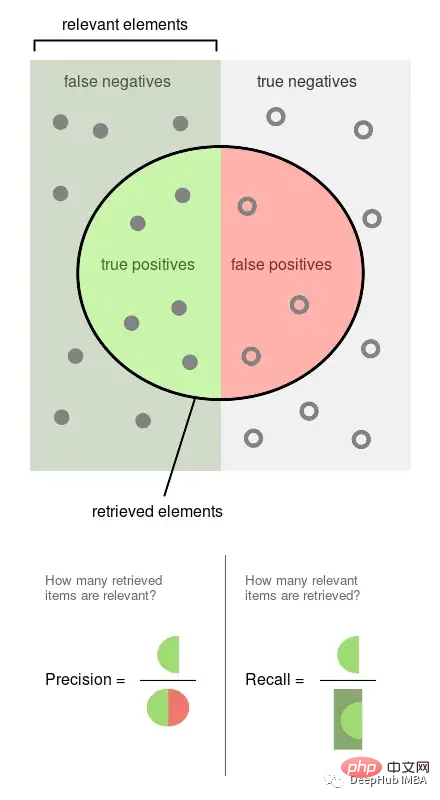
cm_dot_five + cm_dot_four
Führen wir dieses Notizbuch aus (die Konfiguration in der Datei weist Plomber Cloud an, es 20 Mal parallel auszuführen): curl -O https://raw.githubusercontent.com/ploomber/posts/master/threshold/fit.ipynb?utm_source=medium&utm_medium=blog&utm_campaign=thresholdIn ein paar Minuten werden wir das sehen 20 Das Experiment ist abgeschlossen:
ploomber cloud nb fit.ipynbLaden wir die in der CSV-Datei gespeicherten Experimentergebnisse herunter:
ploomber cloud status @latest --summary status count -------- ------- finished 20 Pipeline finished. Check outputs: $ ploomber cloud productsVisualisierung der Experimentergebnisse wird geladen Alle Versuchsergebnisse anzeigen und alle auf einmal grafisch darstellen.
ploomber cloud download 'threshold-selection/*.csv' --summary
左边的刻度(从0到1)是我们的三个指标:精度、召回率和F1。F1分为精度与查全率的调和平均值,F1分的最佳值为1.0,最差值为0.0;F1对精度和召回率都是相同对待的,所以你可以看到它在两者之间保持平衡。如果你正在处理一个精确度和召回率都很重要的用例,那么最大化F1是一种可以帮助你优化分类器阈值的方法。
这里还包括一条红色曲线(右侧的比例),显示我们的模型标记为有害内容的案例数量。
在这个的内容审核示例中,可能有X个的工作人员来人工审核模型标记的有害帖子,但是他们人数是有限的,因此考虑标记帖子的总数可以帮助我们更好地选择阈值:例如每天只能检查5000个帖子,那么模型找到10,000帖并不会带来任何的提高。如果我人工每天可以处理10000贴,但是模型只标记了100贴,那么显然也是浪费的。
当设置较低的阈值时,有较高的召回率(我们检索了大部分实际上有害的帖子),但精度较低(包含了许多无害的帖子)。如果我们提高阈值,情况就会反转:召回率下降(错过了许多有害的帖子),但精确度很高(大多数标记的帖子都是有害的)。
所以在为我们的二元分类器选择阈值时,我们必须在精度或召回率上妥协,因为没有一个分类器是完美的。我们来讨论一下如何推理选择合适的阈值。
选择最佳阈值
右边的数据会产生噪声(较大的阈值)。需要稍微清理一下,我们将重新创建这个图,我们将绘制2.5%、50%和97.5%的百分位数,而不是绘制所有值。
shape = (df.shape[0], len(metrics))
precision = np.zeros(shape)
recall = np.zeros(shape)
f1 = np.zeros(shape)
n_flagged = np.zeros(shape)
for i, df in enumerate(metrics):
precision[:, i] = df.precision.values
recall[:, i] = df.recall.values
f1[:, i] = df.f1.values
n_flagged[:, i] = df.n_flagged.values
precision_ = np.quantile(precision, q=0.5, axis=1)
recall_ = np.quantile(recall, q=0.5, axis=1)
f1_ = np.quantile(f1, q=0.5, axis=1)
n_flagged_ = np.quantile(n_flagged, q=0.5, axis=1)
plt.plot(df.threshold, precision_, color='blue', label='precision')
plt.plot(df.threshold, recall_, color='green', label='recall')
plt.plot(df.threshold, f1_, color='orange', label='f1')
plt.fill_between(df.threshold, precision_interval[0],
precision_interval[1], color='blue',
alpha=0.2)
plt.fill_between(df.threshold, recall_interval[0],
recall_interval[1], color='green',
alpha=0.2)
plt.fill_between(df.threshold, f1_interval[0],
f1_interval[1], color='orange',
alpha=0.2)
plt.xlabel('Threshold')
plt.ylabel('Metric value')
plt.legend()
ax = plt.twinx()
ax.plot(df.threshold, n_flagged_, color='red', label='flagged')
ax.fill_between(df.threshold, n_flagged_interval[0],
n_flagged_interval[1], color='red',
alpha=0.2)
ax.legend(loc=3)
plt.ylabel('Flagged')
plt.grid()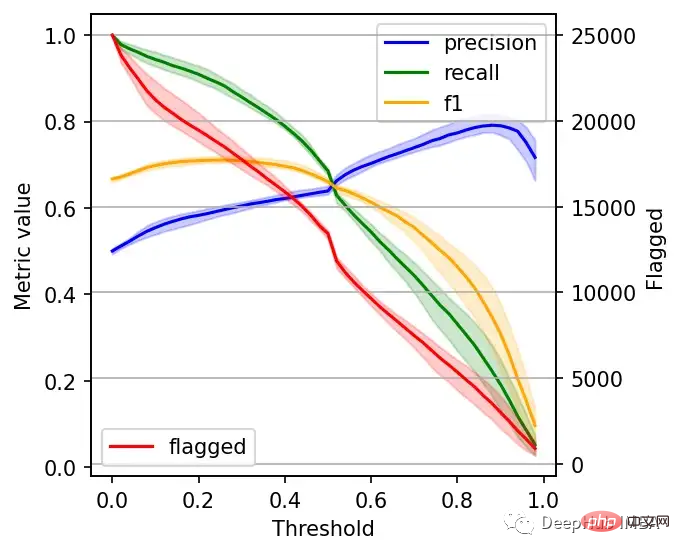
我们可以根据自己的需求选择阈值,例如检索尽可能多的有害帖子(高召回率)是否更重要?还是要有更高的确定性,我们标记的必须是有害的(高精度)?
如果两者都同等重要,那么在这些条件下优化的常用方法就是最大化F-1分数:
idx = np.argmax(f1_)
prec_lower, prec_upper = precision_interval[0][idx], precision_interval[1][idx]
rec_lower, rec_upper = recall_interval[0][idx], recall_interval[1][idx]
threshold = df.threshold[idx]
print(f'Max F1 score: {f1_[idx]:.2f}')
print('Metrics when maximizing F1 score:')
print(f' - Threshold: {threshold:.2f}')
print(f' - Precision range: ({prec_lower:.2f}, {prec_upper:.2f})')
print(f' - Recall range: ({rec_lower:.2f}, {rec_upper:.2f})')
#结果
Max F1 score: 0.71
Metrics when maximizing F1 score:
- Threshold: 0.26
- Precision range: (0.58, 0.61)
- Recall range: (0.86, 0.90)在很多情况下很难决定这个折中,所以加入一些约束条件会有一些帮助。
假设我们有10个人审查有害的帖子,他们可以一起检查5000个。那么让我们看看指标,如果我们修改了阈值,让它标记了大约5000个帖子:
idx = np.argmax(n_flagged_ <= 5000)
prec_lower, prec_upper = precision_interval[0][idx], precision_interval[1][idx]
rec_lower, rec_upper = recall_interval[0][idx], recall_interval[1][idx]
threshold = df.threshold[idx]
print('Metrics when limiting to a maximum of 5,000 flagged events:')
print(f' - Threshold: {threshold:.2f}')
print(f' - Precision range: ({prec_lower:.2f}, {prec_upper:.2f})')
print(f' - Recall range: ({rec_lower:.2f}, {rec_upper:.2f})')
# 结果
Metrics when limiting to a maximum of 5,000 flagged events:
- Threshold: 0.82
- Precision range: (0.77, 0.81)
- Recall range: (0.25, 0.36)如果需要进行汇报,我们可以在在展示结果时展示一些替代方案:比如在当前约束条件下(5000个帖子)的模型性能,以及如果我们增加团队(比如通过增加一倍的规模),我们可以做得更好。
总结
二元分类器的最佳阈值是针对业务结果进行优化并考虑到流程限制的阈值。通过本文中描述的过程,你可以更好地为用例决定最佳阈值。
另外,Ploomber Cloud!提供一些免费的算力!如果你需要一些免费的服务可以试试它。
Das obige ist der detaillierte Inhalt vonFestlegen des besten Schwellenwerts für Modelle des maschinellen Lernens: Ist 0,5 der beste Schwellenwert für die binäre Klassifizierung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr