
Heim >Technologie-Peripheriegeräte >KI >Praxis des NIO-Deep-Learning-Algorithmus
Praxis des NIO-Deep-Learning-Algorithmus

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-15 11:07:061756Durchsuche
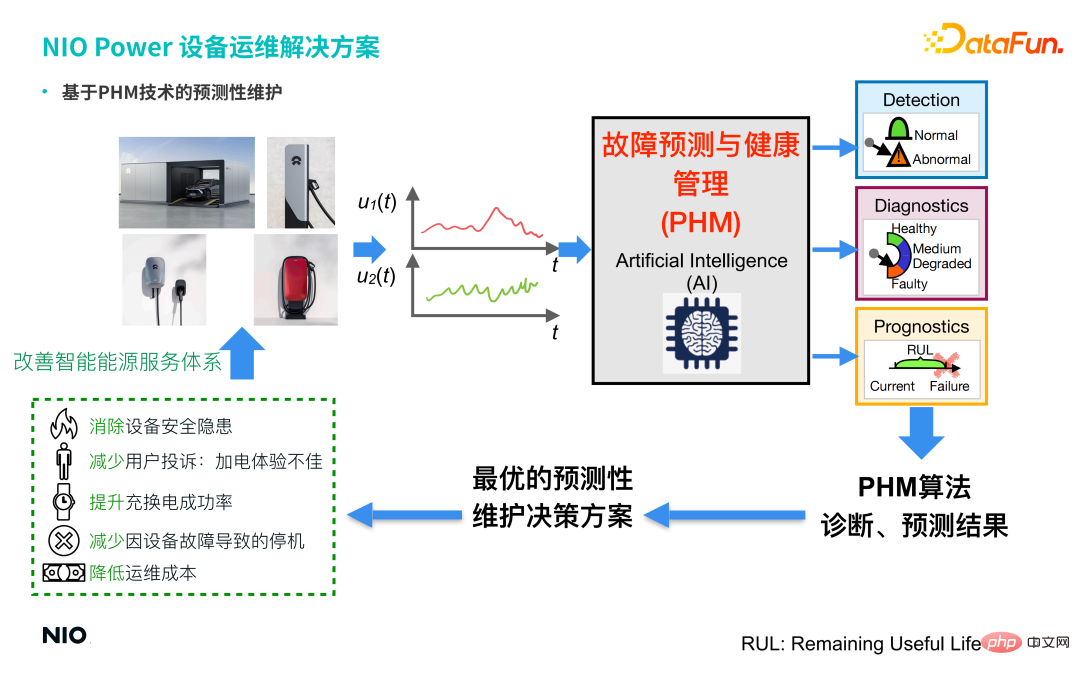
1. Geschäftshintergrund von NIO Power Die Lösung besteht darin, über ein umfassendes Netzwerk von Lade- und Wechseleinrichtungen zu verfügen und sich auf die Cloud-Technologie von NIO zu verlassen, um ein „wiederaufladbares, austauschbares und aufrüstbares“ Energiedienstleistungssystem aufzubauen, das Autobesitzern umfassende Power-up-Dienste bietet. 2. Herausforderungen beim Betrieb und der Wartung von Geräten Schnellladestationen Ladegeräte und andere Geräte stehen derzeit vor vielen Herausforderungen, darunter vor allem:

① Stellen Sie sicher, dass die Geräte keine Sicherheitsrisiken bergen.
② Benutzerbeschwerden: Schlechtes Einschalterlebnis.
③ Die Erfolgsquote beim Laden und Tauschen wird aufgrund von Geräteausfällen verringert.

④ Ausfallzeit aufgrund von Geräteausfall.
⑤ Die Betriebs- und Wartungskosten sind hoch. 2. Betriebs- und Wartungslösung für NIO Power-Geräte Schnellladestapel) enthalten beide eine große Anzahl von Sensoren, sodass die von den Sensoren in Echtzeit gesammelten Daten zur einheitlichen Speicherung und Verwaltung in der NIO Energy Cloud zusammengeführt werden, und eine vorausschauende Wartungstechnologie auf Basis von PHM (Fault Prediction and Health Management) ist vorhanden Durch die Einführung einer Reihe von KI-Algorithmen wie GAN (Generative Adversarial Network) und Conceptor (Conceptor Network) kann der Status der abnormalen Erkennung und Fehlerdiagnose der Ausrüstung ermittelt und die optimale Entscheidungslösung für die prädiktive Wartung der Ausrüstung bereitgestellt werden Basierend auf den Ergebnissen der Diagnosevorhersage und den ausgaberelevanten Betriebs- und Wartungsarbeiten erkennen Sie Folgendes:
① Eliminieren Sie Sicherheitsrisiken für die Ausrüstung.
② Reduzieren Sie Benutzerbeschwerden über schlechtes Einschalterlebnis.
③ Verbessern Sie die Erfolgsquote beim Laden und Tauschen.
④ Reduzieren Sie Ausfallzeiten durch Geräteausfälle.
⑤ Reduzieren Sie Betriebs- und Wartungskosten.
Daher hat die Einführung der PHM-Technologie und -Algorithmen dem Unternehmen effektiv dabei geholfen, sein intelligentes Energiedienstleistungssystem zu verbessern und einen geschlossenen Kreislauf zu bilden, wodurch die Servicefähigkeiten von NIO Power verbessert und optimiert werden.
3. Herausforderungen für die PHM-Technologie
Modernste PHM-Technologien basieren alle auf der datengesteuerten Technologie der künstlichen Intelligenz Modelle sind oft ideal, sie werden unter der Szene konstruiert, aber die reale Szene ist oft nicht ideal.
Wie Sie auf dem Bild oben sehen können, weisen reale Szenen häufig die folgenden Merkmale auf:
① Es gibt nur wenige Fehlermuster.
② Es ist schwierig, Fehlerproben zu kennzeichnen. Dadurch entstehen in diesem Szenario zwei Arten von Problemen: Zum einen handelt es sich um unbeaufsichtigte Lernprobleme und zum anderen um Lernprobleme bei kleinen Stichproben. Als Reaktion auf diese beiden Arten von Problemen, die in realen Szenarien auftreten, haben wir die folgenden PHM-Spitzentechnologien vorgeschlagen und sie in NIO-Power-Szenarien angewendet. Generatives gegnerisches Netzwerk, vorgeschlagen im Jahr 2014, ist eine Art von Deep-Learning-basiertem unbeaufsichtigtem Lernen Die Technologie besteht hauptsächlich aus zwei Teilnetzwerken: Generator und Diskriminator. 4. PHM-Spitzentechnologie
1. Unüberwachte Anomalieerkennung basierend auf generativem gegnerischen Netzwerk (GAN)
(1) GAN-Struktur
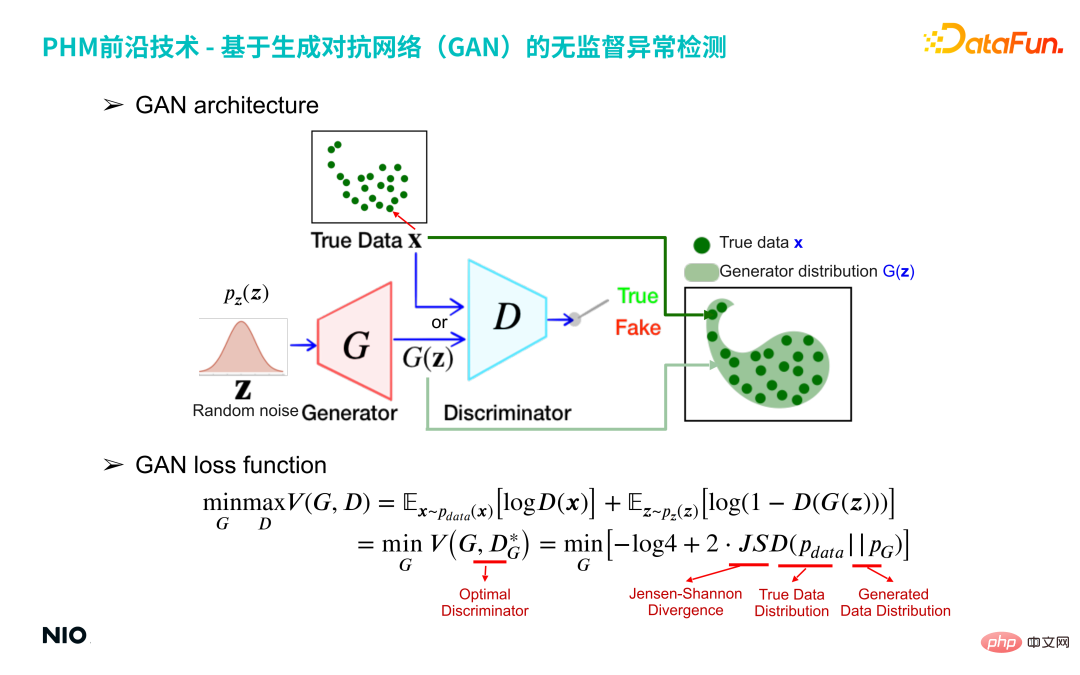
Das rote G-Netzwerk im obigen Bild ist das Generatornetzwerk und das blaue D-Netzwerk ist das Diskriminatornetzwerk.
Generatornetzwerk gibt eine Zufallszahlenverteilung (z. B. eine Gaußsche Verteilung) ein und gibt eine vom Benutzer angegebene spezifische Verteilung aus. Aus der Stichprobenperspektive werden 100 Datenproben aus der Zufallszahlenverteilung eingegeben Das G-Netzwerk ordnet diese 100 Stichproben dem gleichen Raum wie die realen Daten zu, um eine Verteilung G(z) zu bilden, und verwendet das Diskriminatornetzwerk, um die Differenz zwischen den beiden Verteilungen G(z) und den realen Daten zu erhalten X: Das G-Netzwerk wird dann optimiert, bis die G(z)-Verteilung nahe an der X-Verteilung der realen Daten liegt. Das G-Netzwerk gibt diese 100 Daten aus und bildet eine spezifische Verteilung G(z). Der Kern des
Diskriminatornetzwerks besteht darin, die ungefähre Jensen-Shanon-Divergenz der G(z)-Verteilung und der realen Daten-x-Verteilung zu konstruieren, um den Unterschied zwischen der generierten Verteilung und der realen Verteilung zu messen . Die ungefähre Jensen-Shanon-Divergenz wird durch ein standardmäßiges binäres Klassifizierungsnetzwerk basierend auf binomialer Kreuzentropie implementiert, und die Ausgabe des Diskriminatornetzwerks ist ein kontinuierlicher Wert von 0 bis 1. Wenn die Ausgabe 1 ist, wird davon ausgegangen, dass die Eingabeprobe X aus der realen Verteilung stammt. Wenn die Ausgabe 0 ist, wird die Eingabeprobe X als falsch und gefälscht betrachtet.
In der Trainingsform des GAN-Netzwerks versuchen die vom Generator erzeugten Proben, der Verteilung realer Proben nahe zu kommen, und der Diskriminator versucht, die generierten Proben als gefälscht zu unterscheiden, um sie dem Generator zur Verfügung zu stellen ein genauerer Jensen – Der Gradient des Shanon-Divergenzwerts ermöglicht es dem Generator, in eine bessere Richtung zu iterieren. Am Ende bilden die beiden eine Konfrontationsbeziehung. Der Generator generiert „verzweifelt“ falsche Daten, und der Diskriminator unterscheidet „verzweifelt“ zwischen wahren und falschen Eingabedaten. Das GAN-Netzwerk wird schließlich einen Gleichgewichtszustand erreichen: Die generierte Datenverteilung G(z) deckt die Verteilung aller realen Stichproben X gerade vollständig ab.
(2) GAN-Verlustfunktion
Das GAN-Netzwerk aus mathematischer Sicht zu verstehen, kann anhand der Verlustfunktion verstanden werden. Die Verlustfunktion kann die Wertfunktion V(G, D) verwenden, um die Parameter des G-Netzwerks und des D-Netzwerks durch gemeinsame Minmax-Optimierung für ein bestimmtes G-Netzwerk gleichzeitig zu optimieren. Das Optimierungsziel besteht darin, die Wertfunktion zu minimieren, wie gezeigt in der folgenden Formel:
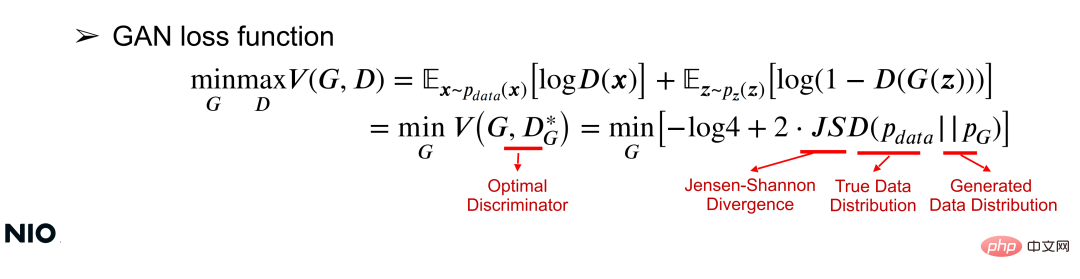
In der Formel ist JSD der Kernoptimierungsterm der Verlustfunktion und ein Maß für die Differenz zwischen den beiden Verteilungen. Wie aus der Formel hervorgeht, besteht der Kern dieser Optimierung darin, den Verteilungsunterschied zwischen X und G(z) zu minimieren. Je kleiner der Verteilungsunterschied, desto erfolgreicher wird das G-Netzwerk trainiert.
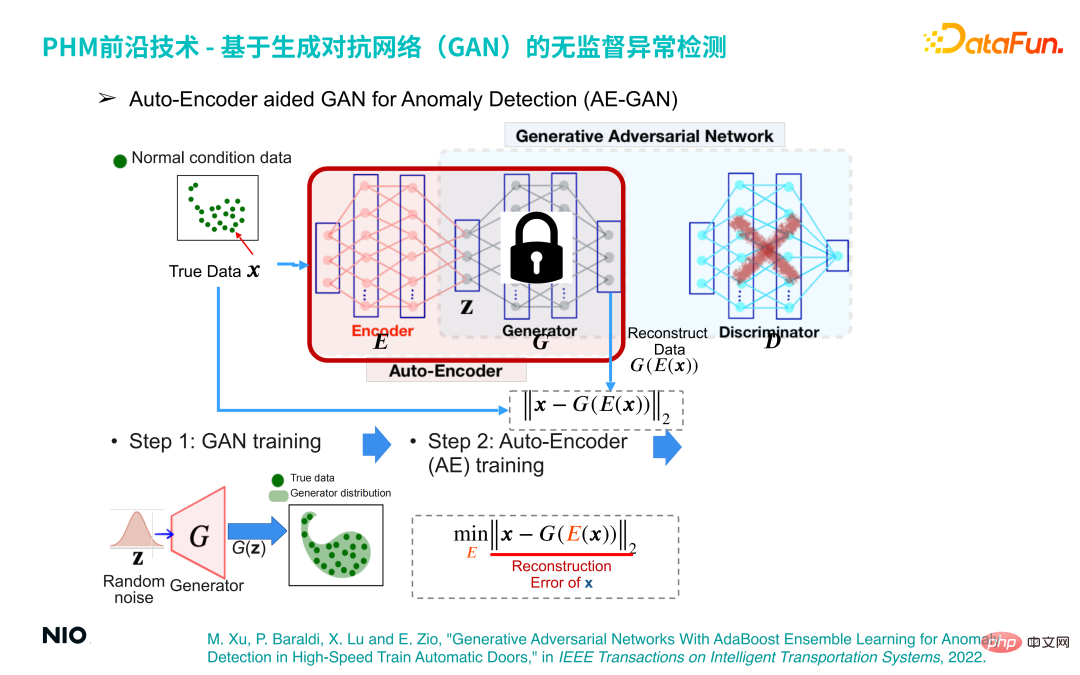
(3) Auto-Encoder-unterstütztes GAN zur Anomalieerkennung (AE-GAN)
Basierend auf dem GAN-Netzwerk wird Auto-Encoder eingeführt, um die Anomalieerkennung von Gerätebetriebsdaten zu implementieren.
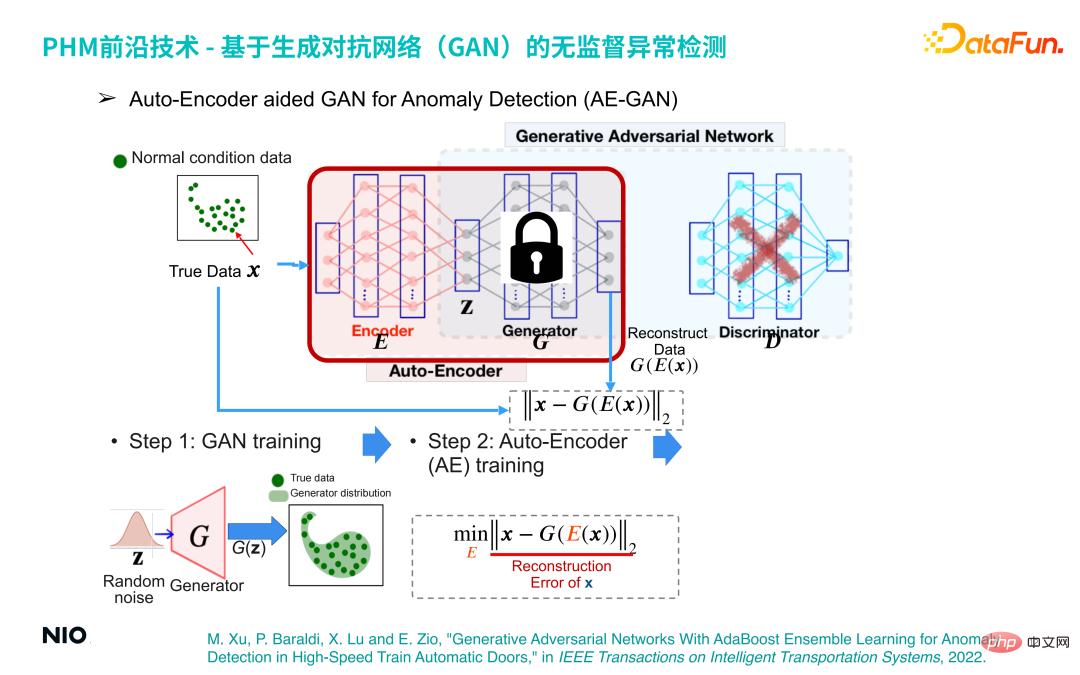
Die spezifische Implementierungsmethode ist:
Der erste Schritt besteht darin, ein GAN-Modell zu erstellen und es zu trainieren, um ein G-Netzwerk zu erhalten, das lediglich die Verteilung der Betriebsdaten der Ausrüstung rekonstruiert.
Der zweite Schritt besteht darin, den D-Netzwerkteil im GAN-Netzwerk zu verwerfen, die G-Netzwerkparameter festzulegen und das Encoder-Netzwerk vor dem G-Netzwerk einzuführen. Auf diese Weise werden das Encoder-Netzwerk und das G-Netzwerk kombiniert bilden einen Satz standardmäßiger Auto-Encoder-Netzwerke. Die Verlustfunktion dieses Netzwerks ist der Rekonstruktionsfehler.
Auf diese Weise können wir die Anomalieerkennung durch Optimierung des Auto-Encoder-Netzwerks abschließen. Das Prinzip dahinter ist: Unabhängig von der Eingabeprobe liegen die vom Auto-Encoder-Netzwerk ausgegebenen Proben innerhalb der normalen Probe Intervall. Wenn es sich bei der Eingabeprobe um eine normale Probe handelt, liegen die generierte Probe und die ursprüngliche Probe daher im gleichen Intervall, sodass der Rekonstruktionsfehler sehr klein oder sogar nahe bei 0 ist Die Probe liegt immer noch innerhalb des normalen Probenintervalls. Dies führt zu einem großen Rekonstruktionsfehler. Daher kann der Rekonstruktionsfehler verwendet werden, um zu bestimmen, ob die Probe normal ist.
Der dritte Schritt besteht darin, eine Reihe von Rekonstruktionsfehlerbewertungen durch eine kleine Menge normaler Stichproben zu erhalten und deren Maximalwert als Rekonstruktionsfehlerschwelle für die Anomalieerkennung zu verwenden.
Dieses Prinzip wurde ausführlich in dem Artikel diskutiert, der 2022 in IEEE in Transactions on Intelligent Transportation Systems veröffentlicht wurde. Die Informationen zum Artikel lauten wie folgt:
M , X. Lu und E. Zio, „Generative Adversarial Networks With AdaBoost Ensemble Learning for Anomaly Detection in High-Speed Train Automatic Doors“, IEEE in Transactions on Intelligent Transportation Systems, 2022.
2 unbeaufsichtigte RNN (Conceptor) Fehlerdiagnose bei kleinen Stichproben
Die zweite Art von Technologie, die wir verwenden, ist eine unbeaufsichtigte RNN (Conceptor-Netzwerk: Conceptor) Fehlerdiagnosetechnologie bei kleinen Stichproben.
(1) Unüberwachtes RNN
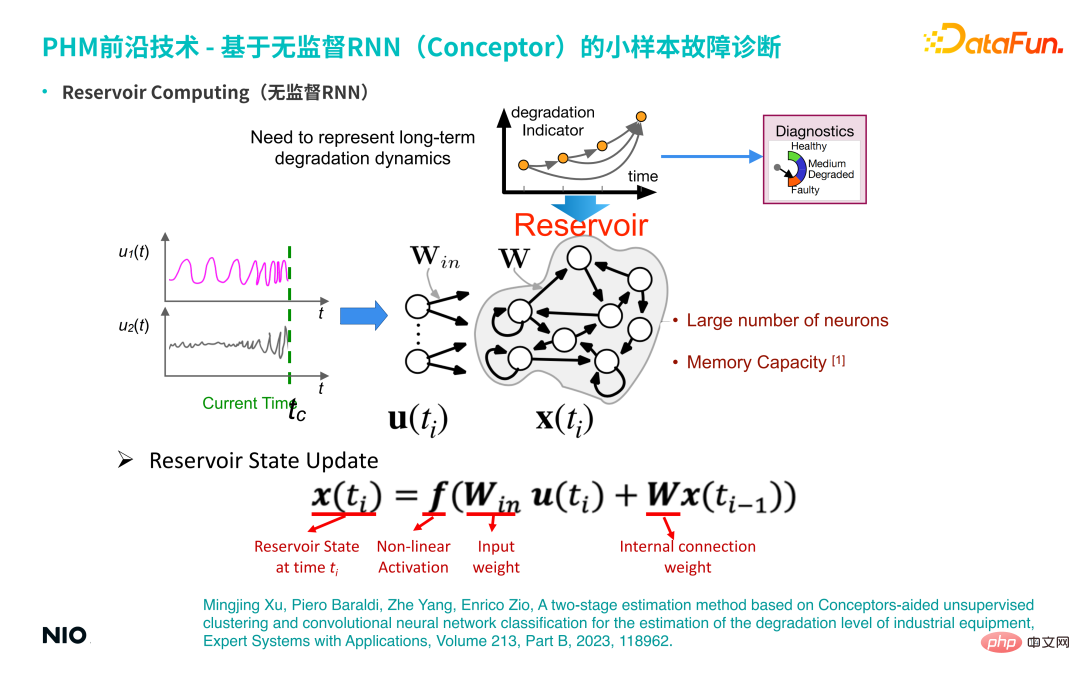
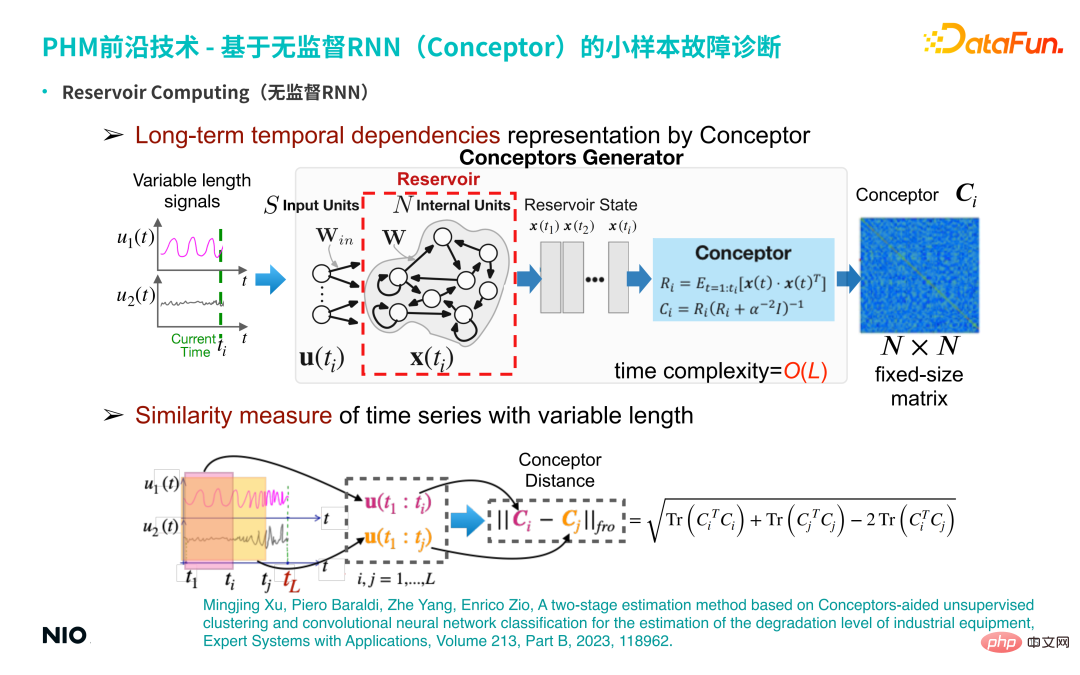
Zunächst stellen wir den Hintergrund dieser Technologie vor – unüberwachtes RNN. Im Vergleich zu gewöhnlichem RNN besteht das Besondere an unbeaufsichtigtem RNN darin, dass die Verbindungsgewichte der Neuronen in der Eingabeschicht des Netzwerks und die Verbindungsgewichte der verborgenen Schichten zufällig initialisiert und während des gesamten Trainings- und Inferenzprozesses festgelegt werden. Dies bedeutet, dass wir die Gewichtsparameter der Eingabeschicht und der verborgenen Schicht nicht trainieren müssen. Daher können wir die Neuronen der verborgenen Schicht im Vergleich zu gewöhnlichen RNN-Netzwerken sehr groß einstellen, sodass die Speicherperiode und die Speicherkapazität der Wenn das Netzwerk sehr groß ist, ist der Speicherzeitraum für die Eingabezeitreihe länger. Die Neuronen der verborgenen Schicht dieses speziellen unbeaufsichtigten RNN werden oft als Reservoir bezeichnet.
① Reservoir-StatusaktualisierungDie Statusaktualisierungsmethode ist dieselbe wie die Standard-RNN-Aktualisierungsmethode.
② Langfristige zeitliche Abhängigkeitsdarstellung durch Conceptor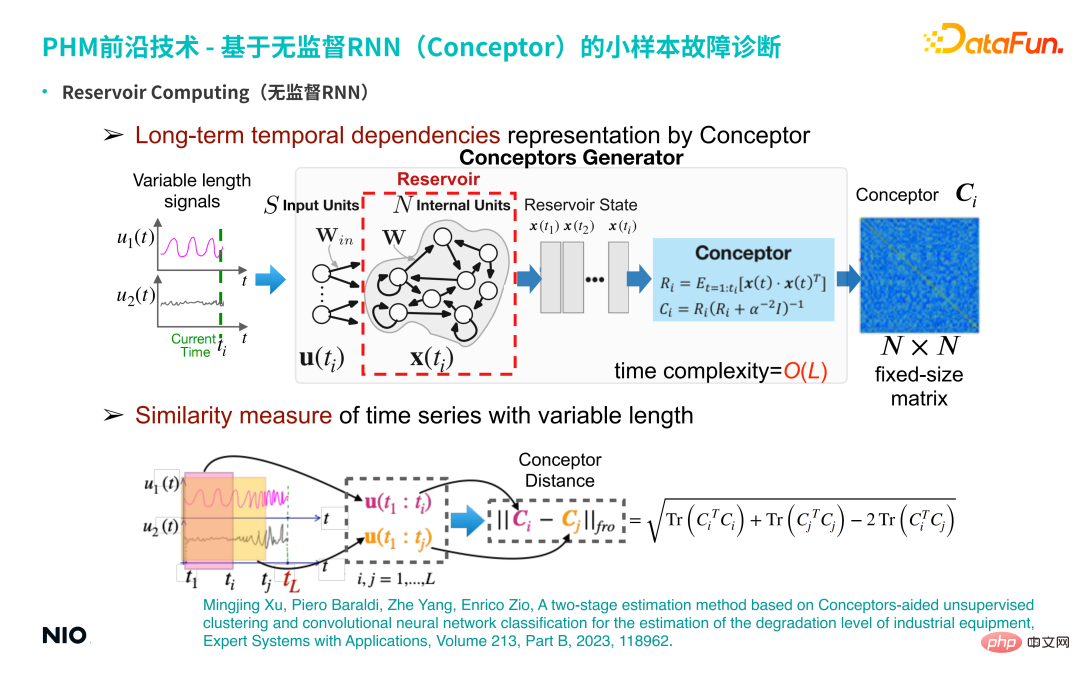
Entwickeln Sie eine unbeaufsichtigte Repräsentationslernmethode, die auf dieser unbeaufsichtigten RNN basiert. Geben Sie insbesondere eine mehrdimensionale Zeitreihe variabler Länge ein und erhalten Sie die RNN jedes Zeitschritts Neuronenzustand; verwenden Sie die Conceptor-Methode (in der Abbildung oben im hellblauen Feld dargestellt), um eine N×N-dimensionale Konzeptmatrix zu erhalten. Im Sinne der linearen Algebra bedeutet diese Matrix: Bei der Verarbeitung von Zeitreihen wird für jeden Zeitschritt das Zeitreihensignal in einen N-dimensionalen Raum projiziert (N entspricht der Skala des verborgenen Neurons).
Wenn es ti# 🎜 🎜# Zeitschritte, dann t#🎜 im N-dimensionalen Raum 🎜 #i Punkte bilden eine Punktwolke; ein solches Punktwolkenellipsoid kann in N zueinander orthogonale Richtungen zerlegt werden, und die Eigenvektoren und Merkmale in jeder Richtung werden als Wert erhalten.
Die Rolle von Conceptor besteht darin, die Eigenwerte und Eigenvektoren zu erfassen und die Eigenwerte zu normalisieren; für diese N Merkmale kann der Vektor verstanden werden Da N Eigenschaften in Zeitreihen erfasst werden (z. B. Periodizität, Trend, Volatilität und andere komplexe Zeitreihenmerkmale), werden implizite Merkmale und alle extrahierten Merkmalsinformationen in dieser N-dimensionalen Matrix erfasst (d. h. die Conceptor-Matrix, das dunkelblaue Kästchen auf der rechten Seite der Abbildung oben).
③ Ähnlichkeitsmaß von Zeitreihen mit variabler Länge Die Grundmerkmale der Matrix bestehen darin, die Conceptor-Matrizen zweier Zeitreihen zu subtrahieren und die Frobenius-Norm zu extrahieren , das heißt, um den Conceptor-Abstand der beiden Zeitreihen zu erhalten; dieser Skalar kann zur Charakterisierung der Differenz zwischen den beiden Zeitreihen verwendet werden.(2) Kleines Beispiel zur Fehlerdiagnose auf Basis von Conceptor
Basierend auf den oben genannten Eigenschaften von Conceptor kann es zur Durchführung kleinerer Stichprobenfehlerdiagnoseanalysen verwendet werden.Wenn es eine kleine Anzahl tatsächlicher Fehlerproben gibt (z. B. (weniger als 10 Fehlerproben) werden alle entsprechenden Zeitreihen in das Conceptor-Netzwerk eingegeben und zur Bildung der entsprechenden Konzeptmatrix aggregiert, die als abstrakte Darstellung des Fehlermodus dieser Kategorie dient. In ähnlicher Weise werden auch normale Proben aggregiert eine normale Konzeptmatrix. Verwenden Sie beim Testen dieselbe Methode, um die entsprechende Konzeptmatrix aus der Eingabezeitreihe zu extrahieren, und führen Sie eine vergleichende Analyse mit den Konzeptmatrizen normaler und abnormaler Stichproben durch, um die entsprechenden Konzeptunterschiede zu berechnen. Wenn die Ähnlichkeit zwischen der Eingabestichprobe und der Konzeptmatrix eines bestimmten Fehlermodus hoch ist, kann davon ausgegangen werden, dass die Stichprobe zu diesem Fehlermodus gehört.
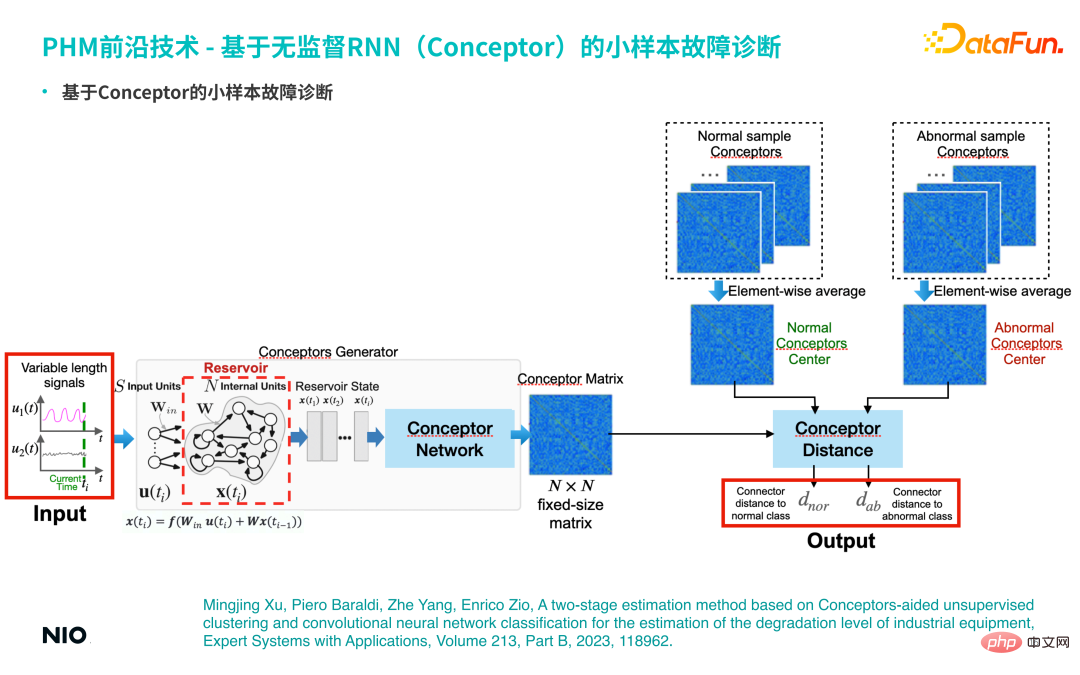
Diese Methode wird auch im folgenden Artikel ausführlich besprochen: #🎜 🎜 #
Mingjing Expertensysteme mit Anwendungen, Band 213, Teil B, 2023, 118962.
5. Anwendungsfall für intelligente Bedienung und Wartung der PHM-Technologie# 🎜🎜#1. Lose Kettenüberwachung des Batteriefachs in der Batteriewechselstation
(1) Hintergrund#🎜🎜 ##🎜 🎜#
Die Kette des Batteriefachs der Batteriewechselstation arbeitet mit dem Batteriefachheber zusammen, um die eingehenden Batterien zum Laden in das Ladefach zu heben. Wenn die Kette defekt ist, kann sie sich lösen oder sogar reißen, was dazu führen kann, dass der Akku während des Transports zum Ladebehälter hängen bleibt und nicht in den Behälter gelegt werden kann. Darüber hinaus fällt die Batterie bei einem Kettenriss herunter, was zu Batterieschäden oder sogar Brandunfällen führen kann.Daher ist es notwendig, ein Modell zu erstellen, um die Lockerheit der Kette im Voraus zu erkennen und das Auftreten damit verbundener Sicherheitsunfälle zu verhindern im Voraus und minimieren Sie das Risiko.
2. Problemstellung Vibrationen.
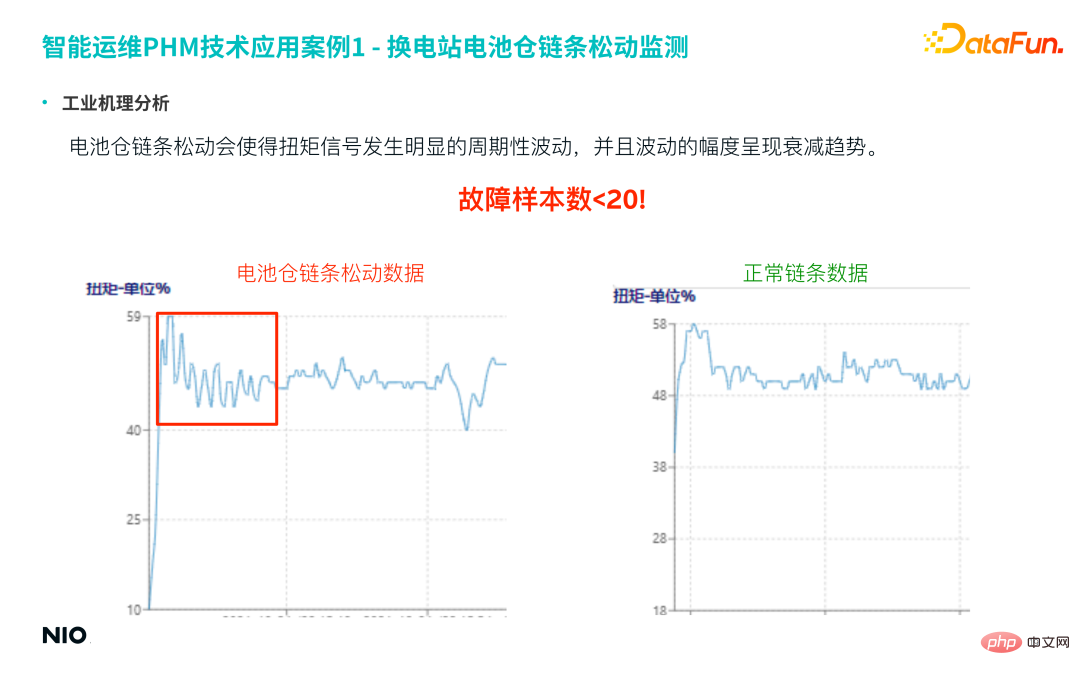
Bei fehlenden Vibrationsdaten kann die Lockerung der Kette anhand von Drehmoment, Position, Geschwindigkeit und anderen Signalen des Kettenantriebsmotors erkannt werden. (3) Analyse des Industriemechanismus Das Drehmomentsignal und die Amplitude der Schwankungen weisen einen schwächeren Trend auf. 
Die tatsächliche Anzahl der Proben für diesen Fehler ist sehr gering, weniger als 20 Proben. Da diese Art von Fehler jedoch sehr wichtig ist, sind die Genauigkeit und die Rückrufrate des Vorhersagemodells sehr hoch.
(4) Modellentwurf zur Kettenlockerungserkennung
① Teilen Sie zunächst die Originaldaten in Zeitreihen auf und extrahieren Sie die Drehmomentdaten des gleichmäßigen Prozesses für die langen Zeitreihen.
② Zerlegen Sie dann die Zeitreihe und behalten Sie nur die Schwankungseigenschaften der Zeitreihe bei.
③ Führen Sie weiter eine Spektrumanalyse der Sequenz durch und ermitteln Sie schließlich die Spektrumeigenschaften.
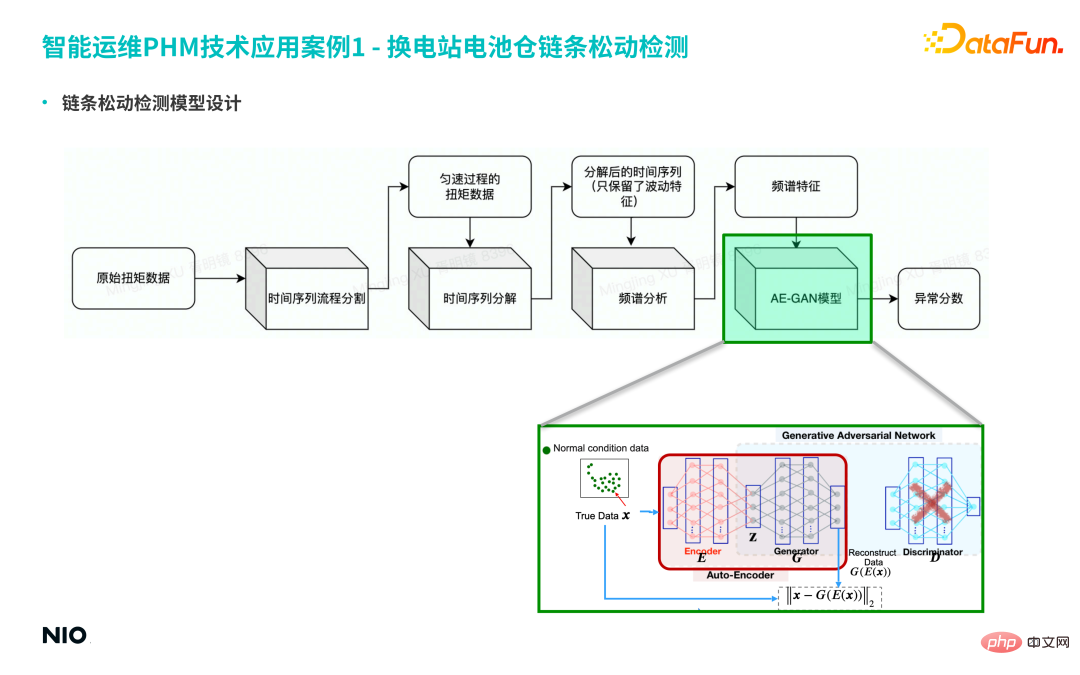
Unter diesen handelt es sich hauptsächlich um das Algorithmusmodul, das an der oben erwähnten Feature-Entwicklung beteiligt ist. In diesem Fall verwendet die Algorithmusschicht den AE-GAN-Algorithmus basierend auf den abnormalen Bewertungsergebnissen der Algorithmusschicht Die Feature-Tabelle in der Feature-Ebene. Weitere Beurteilungen und Entscheidungen werden in der Modellebene getroffen. Der endgültige Ausgabearbeitsauftrag wird zur Verarbeitung an den Spezialisten gesendet. Basierend auf dem oben genannten Prozess wird die traditionelle Erkennung von Expertenerfahrungen auf die Erkennung von KI-Algorithmen aktualisiert und die Genauigkeitsrate um mehr als 30 % erhöht.
2. Fehlerdiagnose wegen Verschlechterung der Stapelpistolenspitze(1) Analyse des industriellen Mechanismus
Zunächst wird ein physikalisches Modell basierend auf dem Ladestrom, der Spannung, der Temperatur und anderen physikalischen Signalen des Ladevorgangs erstellt Pistole, um die Eigenschaften der Pistolenspitze zu erhalten. Die physikalische Größe des Temperaturanstiegskoeffizienten wird als charakteristisches Signal für die weitere Fehlerdiagnose verwendet. Allerdings verwendet diese Art des physikbasierten Feature-Engineerings normalerweise Zeitgleitfenster zur Feature-Generierung und erhält schließlich eine neue Zeitreihe, da das Feature-Ergebnis oft verrauscht ist.
Nehmen Sie die folgende Abbildung als Beispiel. Dieses Projekt wählt normalerweise eine Woche oder einen Monat Daten als Zeitfenster aus, um eine charakteristische Zeitreihe ähnlich der folgenden Abbildung zu erhalten. Aus der Abbildung ist ersichtlich, dass das Rauschen dieser Sequenz sehr groß ist und es schwierig ist, direkt zwischen verschlechterten Proben und normalen Proben zu unterscheiden.
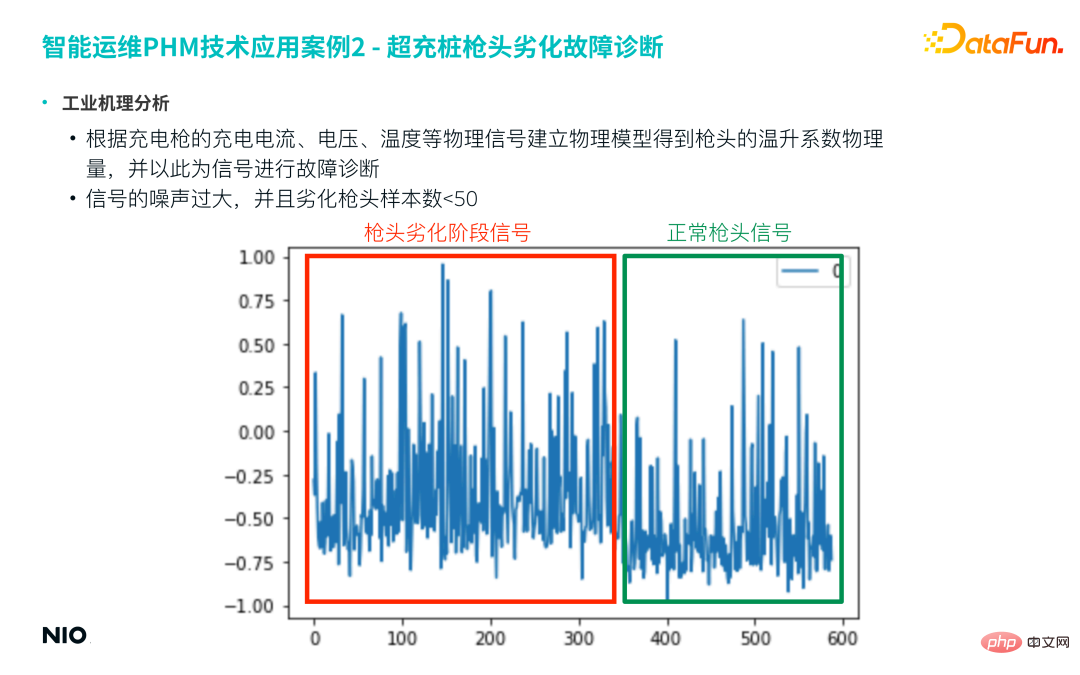
Darüber hinaus liegt die Anzahl der beschädigten Spitzen bei tatsächlichen Ausfallproben oft unter 50.
Basierend auf den beiden oben genannten Gründen wird das Conceptor-Modell eingeführt, um manuelle Erfahrungen zu beseitigen und die Zeitreiheneigenschaften verschlechterter Proben automatisch durch das Modell zu erfassen. 2) Fehlerdiagnoseprozess Ersetzen Sie jemals die Pistolenspitze.
Ordnen Sie die Fehlerbeispieldaten des entsprechenden Zeitraums basierend auf dem Datensatz zum Austausch der Pistolenspitze als Trainingssatz für das Modell zu.
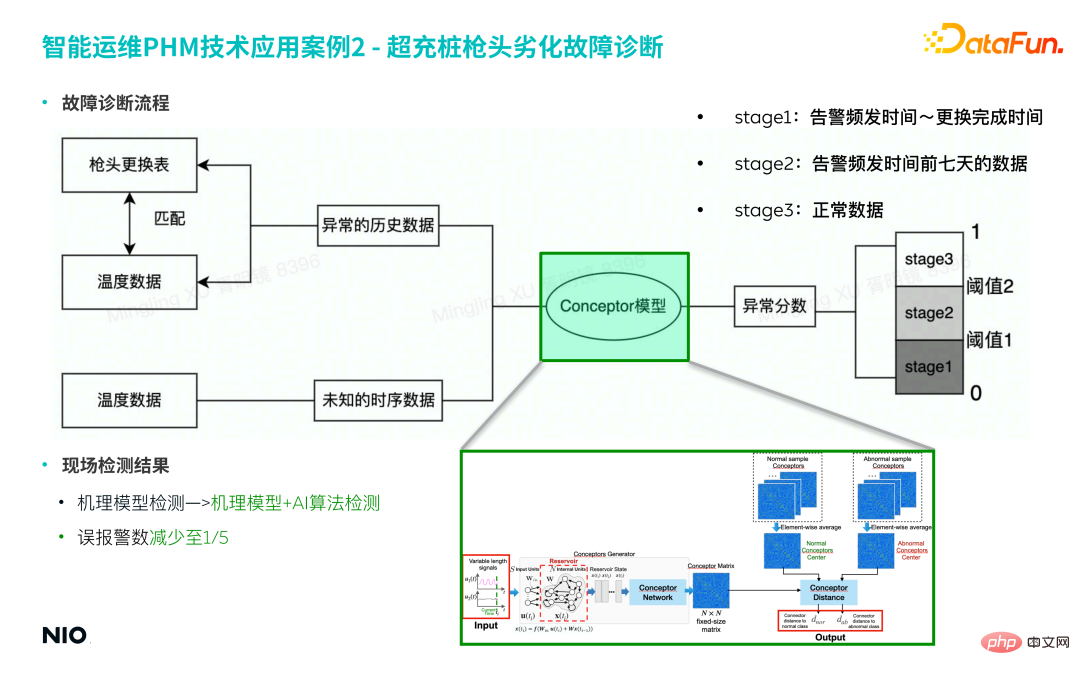
- ② Modellkonstruktion
- Der physikalische Mechanismus hinter diesem Fehler ist relativ komplex, sodass eine Modellierung auf der Grundlage von Vorkenntnissen, Expertenerfahrung und physikalischen Mechanismen relativ schwierig umzusetzen und das Modell schwer zu verallgemeinern ist .
- Die in diesem Artikel erwähnte Conceptor-Modellmethode basiert auf einer rein datengesteuerten Methode und führt keine vorherigen Funktionen zur Extraktion physischer Informationen ein, was die Komplexität des Modells erheblich reduzieren und die Modellierungseffizienz verbessern kann.
- a. Wenn Sie 50 Fehlerproben eingeben, erhalten Sie 50 Konzeptdarstellungsmatrizen;
- b. Aggregieren Sie den Mittelwert dieser 50 Matrizen und multiplizieren Sie sie mit der Darstellungsmatrix des Fehlermodus . Schwerpunkt: Berechnen Sie die Konzeptmatrix für die Eingabetestdaten, vergleichen Sie sie mit der Darstellungsmatrix des Fehlermodus Erhalten Sie dann den Anomalie-Score.
- ③ Modell-Frühwarnung
Basierend auf dem oben genannten Prozess wird die herkömmliche Methode zur Erkennung von Mechanismusmodellen zu einer Methode zur Erkennung von Mechanismusmodellen in Kombination mit der KI-Algorithmus-Erkennungsmethode aktualisiert, wodurch die Fehlalarmrate des Modells auf 1/5 des Originals reduziert werden kann.
6. Frage- und AntwortsitzungF1: Wie kann man im AE-GAN-Modell normale Proben von abnormalen Proben unterscheiden?
A1: Geben Sie für das trainierte AE-GAN-Modell eine Stichprobe in den Auto-Encoder ein und erhalten Sie den Rekonstruktionsfehler der Stichprobe. Dies ist die Anomaliebewertung. Wenn die Punktzahl unter dem angegebenen Schwellenwert liegt, wird die Stichprobe ermittelt gilt als normal und umgekehrt. Die Voraussetzung für die Verwendung dieser Methode ist, dass alle Trainingsdaten normale Beispieldaten sind.
-
F2: Verwenden Sie beim Training des GAN-Netzwerks eine Mischung aus kleinen Beispielfehlerdaten und normalen Daten? Wie kann man die beiden Daten ausgleichen?
A2: Beim Training des GAN-Netzwerks werden entweder normale Daten oder abnormale Daten in einem bestimmten Modus verwendet und gemischte Daten werden nicht verwendet Training, sodass Probleme wie ein Probenungleichgewicht nicht auftreten. Wenn in den tatsächlichen Daten eine große Lücke zwischen den beiden Arten von Datenproben besteht, wird im Allgemeinen ein GAN-Netzwerk 1 für normale Proben trainiert, und dann wird ein GAN-Netzwerk 2 für ein bestimmtes festes Muster abnormaler Proben trainiert Testproben werden auf der Grundlage der Rekonstruktionsfehler der beiden Netzwerke getestet. Endgültige Beurteilung.
F3: Wird es während des GAN-Trainings zu einem Modellkollaps kommen?
A3: Der Moduskollaps ist das Kernproblem beim GAN-Modelltraining. Erstens verstehen Sie den Zusammenbruch des Modus und zweitens konzentrieren Sie sich auf die Kernaufgaben des GAN-Trainings.
Moduszusammenbruch sind die vom Generator Focus generierten Daten auf einen bestimmten Bereich; der Grund dafür ist die Vernachlässigung der Definition der Verlustfunktion im GAN-Netzwerk. Während des GAN-Netzwerktrainingsprozesses werden der Verlust des G-Netzwerks und der Verlust des D-Netzwerks normalerweise separat berechnet, und die gemeinsame Verlustfunktion der beiden Netzwerke (dh der JSD-Verlust in der Formel) wird häufig ignoriert. Wenn ein Zusammenbruch des Trainingsmodus auftritt, konvergiert der JSD-Verlust häufig nicht; daher kann die Visualisierung des JSD-Verlusts während des Trainingsprozesses effektiv einen Moduszusammenbruch verhindern. Dies ist auch der Grund, warum viele neuere verbesserte Versionen von GAN-Modellen herausstechen und bessere Ergebnisse erzielen konnten. Darüber hinaus können auch durch die Einführung spezifischer Tricks in Standard-GAN-Netzwerke ähnliche Effekte erzielt werden.
F4: Welche Vorteile hat die zufällige Festlegung versteckter RNN-Schichten?
A4: Für Szenarien, in denen eine große Diskrepanz zwischen positiven und negativen Proben besteht und Sie häufig verwendete LSTM-, RNN-, GRNN- und andere Modelle verwenden, Sie werden häufig mit dem Problem konfrontiert, dass die Verlustfunktion nicht konvergiert. Daher besteht die Möglichkeit, solche Probleme zu lösen, darin, vom unbeaufsichtigten Lernen auszugehen, das Gewicht der verborgenen Schicht des Hauptnetzwerks zufällig festzulegen und bestimmte Methoden zu verwenden Um die charakteristischen Komponenten der generierten Konzeptmatrix zu regulieren, ist der Gewichtsparameter zwar zufällig, aber die erhaltene Darstellungskomponente kann die verborgenen Eigenschaften der Zeitreihe widerspiegeln und reicht aus, um kleine Stichprobenszenen zu unterscheiden Die Ebene wird zufällig festgelegt.
F5: Stellen Sie die Netzwerkform des Conceptor-Modells vor.
A5: Das Modell ist wie unten gezeigt.

Unter ihnen der Reserveteil ist dasselbe wie gewöhnlich. Das RNN-Netzwerk ist im Grunde dasselbe. Der einzige Unterschied besteht darin, dass Win # und W zufällig festgelegt werden (beachten Sie, dass sie werden nur einmal zufällig generiert. Anschließend wird der verborgene Zustand des Neurons bei jedem Zeitschritt berechnet und aktualisiert und die entsprechende Konzeptmatrix erhalten. Das Obige ist die vollständige Version von Conceptor. F6: Wie ist der Trainingsprozess des Encoder-Netzwerks in AE-GAN? Was sind Input und Output?
A6: Die folgende Abbildung zeigt den Trainingsprozess des Encoder-Netzwerks.
trainiert zunächst ein Standard-GAN und repariert dann das G-Netzwerk Fügen Sie dann vor dem G-Netzwerk ein Encoder-Netzwerk ein, um die beiden Netzwerke zu einem Auto-Encoder-Netzwerk zu verbinden. Die Eingabe des Auto-Encoder-Netzwerks ist die ursprüngliche Datenprobe, und die Ausgabe ist die rekonstruierte Datenprobe. Das AE-GAN-Netzwerk identifiziert abnormale Daten durch die Erstellung rekonstruierter Proben.
F7: Gibt es Papiere und zugehörige Open-Source-Codes für die beiden im Artikel beschriebenen Methoden?
A7: Einzelheiten finden Sie in den entsprechenden Kapiteln des Artikels. Der Code ist noch nicht Open Source.
F8: Kann AE-GAN zur Anomalieerkennung im Bildfeld verwendet werden?
A8: Es kann verwendet werden. Im Vergleich zu gewöhnlichen Signalen weist das Bildfeld jedoch größere Abmessungen, eine komplexere Datenverteilung und eine größere Datenmenge auf, die für das Training erforderlich ist. Wenn es zur Bildklassifizierung verwendet wird und nur wenige Datenproben vorhanden sind, wird der Modelleffekt beeinträchtigt. Wenn es zur Anomalieerkennung verwendet wird, ist der Effekt immer noch gut.
F9: Was sind die Bewertungsindikatoren für die Anomalieerkennung? Falsch-positive und falsch-negative Ergebnisse, und beide werden zusammen ausgewertet.
A9: Die intuitivsten Bewertungsindikatoren sind die Falsch-Positiv-Rate und die Falsch-Negativ-Rate. Weitere wissenschaftliche Indikatoren sind die Rückrufrate, die Präzisionsrate, der F-Score usw.
F10: Wie werden Fehlerbeispielmerkmale abgeglichen?
A10: Wenn es keinen direkteren und schnelleren Weg gibt, Fehlermerkmale zu erhalten, wird im Allgemeinen eine rein datengesteuerte Methode zum Mining von Fehlerbeispielmerkmalen verwendet. Im Allgemeinen wird ein Deep-Learning-Netzwerk aufgebaut, um die wichtigsten Merkmale zu erlernen Fehlerbeispiele und wird als Konzeptmatrix bezeichnet.
F11: Wie führt der PHM-Algorithmus die Modellauswahl durch?
A11: Für eine kleine Anzahl von Proben wird im Allgemeinen die unbeaufsichtigte RNN-Methode zur Charakterisierung der Dateneigenschaften verwendet. Wenn eine große Anzahl normaler Proben für Anomalieerkennungsprobleme vorhanden ist, kann das AE-GAN-Netzwerk verwendet werden es umsetzen.
F12: Wie erkennt man Anomalien anhand der beiden Arten von Konzeptmatrizen, die von RNN ausgegeben werden?
A12: Die von RNN ausgegebene Konzeptmatrix kann als die Menge aller Merkmale in der Eingabezeitreihe verstanden werden, da die Eigenschaften der Daten im selben Zustand ähnlich sind, die Konzeptmatrix aller Stichproben in diesem Zustand wird gemittelt und aggregiert, das heißt, die Konzeptzentrumsmatrix wird für die Eingabezeitreihe des unbekannten Zustands abstrahiert, indem die Konzeptzentrumsmatrix berechnet und mit der Konzeptzentrumsmatrix verglichen wird Ähnlichkeit ist die Kategorie, die den Eingabedaten entspricht.
F13: Wie legt man den Anomalieschwellenwert im AE-GAN-Netzwerk fest?
A13: Verwenden Sie nach Abschluss des Netzwerktrainings eine kleine Menge normaler Beispieldaten, um den Rekonstruktionsfehler zu berechnen, und verwenden Sie den Maximalwert als Schwellenwert.
F14: Wird der Anomalieschwellenwert im AE-GAN-Netzwerk aktualisiert?
A14: Im Allgemeinen wird es nicht aktualisiert. Wenn sich jedoch die ursprüngliche Datenverteilung ändert (z. B. wenn sich die Betriebsbedingungen ändern), muss der Schwellenwert möglicherweise neu trainiert werden, und es können sogar Methoden zum Transferlernen in das GAN eingeführt werden Netzwerk. Passen Sie den Schwellenwert an.
F15: Wie trainiert GAN Zeitreihen?
A15: GAN trainiert im Allgemeinen nicht die ursprüngliche Zeitreihe, sondern trainiert Merkmale, die auf der Grundlage der ursprünglichen Zeitreihe extrahiert wurden.
F16: Welche Rolle spielt die Einführung von GAN in AE-GAN im Vergleich zu traditionellem GAN? Welche Verbesserungen können erzielt werden?
A16: Traditionelles GAN wird auch häufig zur Anomalieerkennung verwendet. AE-GAN verfügt über eine eingehendere Analyse der GAN-Prinzipien, sodass auch Probleme wie der Moduskollaps weitestgehend vermieden werden können, und die Einführung von Auto-Encoder kann sicherstellen, dass das Prinzip der Anomalieerkennung genau ausgeführt wird. Dadurch wird die Fehlalarmrate reduziert.
F17: Wird es während der Feiertage insgesamt zu einem Anstieg der Zeitreihendaten von Ladesäulen kommen? Wie vermeide ich Fehleinschätzungen?
A17: Das Fehlerdiagnosemodell ist in viele Ebenen unterteilt und stellt nur die Grundlage für die Entscheidungsebene dar. Sie werden im Allgemeinen zur Unterstützung mit anderen Geschäftslogiken kombiniert Urteil.
F18: Wie kann nach dem Start des Modells der Anwendungseffekt der unbeaufsichtigten Anomalieerkennung bewertet werden?
A18: Im Allgemeinen werden auf der Grundlage der Ergebnisse der Anomalieerkennung technische Spezialisten benannt, die dies am realen Tatort bestätigen.
F19: Gibt es Versuche, mit den beiden im Artikel genannten Methoden Anomalien in Batterien in Batteriewechselstationen zu erkennen?
A19: Ähnliche Versuche sind im Gange.
F20: Wie vereinheitlicht man die Länge von Zeitreihendaten? Führt das Auffüllen mit 0 dazu, dass der Farbverlauf nicht abfällt?
A20: Das im Artikel erwähnte Conceptor-Modell kann Zeitreihen beliebiger Länge verarbeiten, sodass keine Nullen eingegeben werden müssen, und das auch vermeidet den Parameter „Training“ Prozess, sodass diese Art von Problem vermieden werden kann.
F21: Wird GAN unter Überanpassung leiden?
A21: Wenn es nur im Bereich der Anomalieerkennung verwendet wird, gilt: Je mehr „Überanpassung“, desto besser ist die Modellleistung. Darüber hinaus kommt es aufgrund der großen Zufälligkeit im G-Netzwerk des GAN-Modells während des Trainingsprozesses im Allgemeinen nicht zu einer Überanpassung.
F22: In welcher Größenordnung werden beim Training eines GAN-Modells die Trainingsdaten verwendet, um bessere Ergebnisse zu erzielen?
A22: Diese Art von Problem hängt im Allgemeinen von der Größe des neuronalen Netzwerks, den Abmessungen der verborgenen Neuronen usw. ab. Im Allgemeinen muss für ein zweischichtiges neuronales Netzwerk mit 100 Neuronen pro Schicht das Volumen der Trainingsdaten 1-2 Größenordnungen größer sein als die Dimension der verborgenen Schicht, um bessere Ergebnisse zu erzielen Außerdem müssen einige Tricks angewendet werden, um einen Zusammenbruch des Modus zu vermeiden.
F23: Die minimalen versteckten Einheitenparameter im Conceptor-Modell sind festgelegt und basieren auf Expertenerfahrungen. Wie ist die Verzerrung im Vergleich zu einem normalen RNN? Wie groß ist das Etikettenvolumen für die Fehleranalyse? Wie lässt sich der Geschäftswert quantifizieren?
A23: Viele derzeit online verfügbare Conceptor-Modelle verwenden den gleichen Satz empirischer Parameter ohne weitere Parameteranpassung; basierend auf praktischen Erfahrungen sind die relevanten Parametereinstellungen ab 10 bis 100 haben nur geringe Auswirkungen auf die Ergebnisse und der einzige Unterschied ist der Rechenaufwand. Wenn die Stichprobengröße der Fehlerdaten klein ist und Sie genauere Ergebnisse wünschen, können Sie die Parameter auf 128, 256 oder sogar höher einstellen. Dementsprechend ist der Berechnungsaufwand höher. Die Anzahl der Labels zur Fehleranalyse liegt im Allgemeinen zwischen 1 und 10. Die Quantifizierung des Geschäftswerts wird im Allgemeinen anhand von Fehlalarmen und verpassten Alarmen gemessen, da Fehlalarme und verpasste Alarme direkt in quantitative Auswirkungen auf den Geschäftswert umgewandelt werden können.
F24: Wie lassen sich Fehlerstartzeit, Präzision und Rückrufrate bestimmen?
A24: Sie können die Conceptor-Methode verwenden, um das Zeitwachstumsfenster zu verwenden, um mehrere Konzeptmatrizen zu bilden; und zur Bestimmung eine spektrale Clusterbildung an der Konzeptmatrix durchführen Zeitpunkt des Auftretens der Störung. Weitere Informationen finden Sie in den entsprechenden Artikeln im Kapitel „Conceptor“.
F25: Haben viele normale Daten den gleichen Wert? Lernt das Modell wiederholt dieselben Proben?
A25: In realen Szenarien variieren die normalen Daten aufgrund unterschiedlicher Betriebsbedingungen der Geräte oft stark.
F26: Welche Fehlereigenschaften eignen sich für GAN und welche Fehlereigenschaften eignen sich für RNN?
A26: Es ist schwierig, die spezifischen Nutzungsszenarien dieser beiden Modelle klar zu trennen; im Allgemeinen ist GAN besser darin, Probleme mit speziellen und sehr einfachen Lösungen zu lösen Spezielle Datenverteilung Diese Art von Problem ist mit einem Klassifizierungsnetzwerk schwer zu charakterisieren, und unbeaufsichtigtes RNN eignet sich besser für die Behandlung kleiner Stichprobenprobleme.
F27: Kann das in diesem Artikel erwähnte Modell in speziellen Szenarien wie der „Erkennung von Personalverstößen“ verwendet werden?
A27: Wenn domänenspezifisches Wissen eingeführt werden kann, um Funktionen höherer Ordnung zu extrahieren, ist dies im Allgemeinen möglich; Bilder werden zur Erkennung verwendet. Wenn die Bildstichprobengröße groß ist und normales Verhalten charakterisieren kann, kann das Problem in die Szenenerkennung mit CV-Domänenunterteilung umgewandelt werden, die mithilfe des in diesem Artikel erwähnten Modells erkannt werden kann.
F28: Ist Conceptor Distance ein Ähnlichkeitsurteil? Wird es mit Parametern gelernt?
A28: Es ist parameterlos.
F29: Muss ich für jeden Fehler ein Modell trainieren?
A29: Dies hängt vom spezifischen Szenario ab, einschließlich der Anforderungen des Modells, der Stichprobengröße des Fehlers und der Komplexität der Verteilung. Wenn die Ähnlichkeit der Zeitwellenformen zweier Fehler sehr hoch ist, besteht im Allgemeinen keine Notwendigkeit, ein separates Modell zu trainieren. Sie müssen jedoch nur ein Multiklassifizierungsmodell erstellen, um die Klassifizierungsgrenzen der beiden zu bestimmen Fehlermodi sind sehr unterschiedlich. Sie können das GAN-Modell verwenden, um die Daten genau zu identifizieren.
F30: Wie hoch sind die Schulungszeit und die Schulungskosten für das Modell?
A30: Der Trainingsaufwand des Conceptor-Modells ist sehr gering und kann zum Extrahieren von Features verwendet werden; die Trainingszeit des GAN-Modells ist relativ länger , aber für gemeinsame Strukturen Mit tabellarischen Daten wird die Trainingszeit nicht zu lang sein.
F31: Wie sieht der Trainingssatz normaler Proben beim Training des Modells aus? Gibt es beim Aufteilen von Zeitreihen-Schiebefenstern eine empfohlene Mindesthäufigkeit für jede Zeitreihen-Teilmenge?
A31: Die beiden Modelle selbst stellen keine Anforderungen an die Anzahl der positiven und negativen Proben; in Anbetracht der Modelltrainingszeit sind es im Allgemeinen Tausende repräsentativer Proben ausgewählte Trainingsbeispiele. Im Allgemeinen gibt es keine Mindestanzahlempfehlung für die Häufigkeit in einer Timing-Teilmenge.
F32: Wie groß ist die ungefähre Dimension der vom RNN-Netzwerk erhaltenen Merkmalsmatrix?
A32: Die Dimension der Merkmalsmatrix steht in direktem Zusammenhang mit der Anzahl der versteckten Neuronen, wenn es N versteckte Neuronen gibt Die Merkmalsmatrix ist N × N. In Anbetracht der Komplexität des Modells und der Berechnungseffizienz wird N im Allgemeinen nicht zu groß eingestellt und ein häufig verwendeter Einstellwert ist 32.
F33: Warum nicht den Diskriminator in GAN als Klassifikator verwenden? Der Diskriminator lernt nur normale Daten und abnormale Daten werden als falsche Daten klassifiziert. Welche Nachteile hat dieser Ansatz?
A33: Gemäß dem GAN-Prinzip wird das D-Netzwerk verwendet, um normale Proben und gefälschte Proben zu unterscheiden. „Kompletter Körper“-ZustandEs wird normalen Proben sehr nahe kommen, was es schwierig macht, zwischen normalen Proben und abnormalen Proben zu unterscheiden. Das AE-GAN-Netzwerk geht davon aus, dass normale Proben und abnormale Proben einen gewissen Grad an Unterscheidung aufweisen, was theoretisch ist Grundlage für die Verwendung von AE-GAN.
F34: Wie stellt das Lernmodell für kleine Stichproben die Generalisierungsfähigkeit sicher?
A34: Die Generalisierungsfähigkeit des Modells muss auf einer apriorischen Annahme basieren: Alle Fehler desselben Typs weisen eine ähnliche Datenverteilung auf. Wenn die Verteilung ähnlicher Fehlerdaten sehr unterschiedlich ist, ist es in der Regel erforderlich, die Fehlerkategorien weiter zu unterteilen, um die Generalisierungsfähigkeit des Modells sicherzustellen.
F35: Wie führt man eine Datenvorverarbeitung für Eingabedaten durch?
A35: Für die beiden im Artikel genannten Modelle müssen die Daten nur normalisiert werden.
F36: Wie schneidet GAN im Vergleich zu traditionellen unbeaufsichtigten Richtungen wie isoliertem Wald und AE ab?
A36: Durch die Vollständigkeit der Theorie kann GAN die Verteilung normaler Stichprobendaten vollständiger darstellen und dadurch eine vollständigere Entscheidungsgrenze erstellen. Methoden wie gewöhnliche AE, isolierte Gesamtstruktur und One-Class-SVM weisen jedoch keine theoretische Vollständigkeit auf und können keine vollständigere Entscheidungsgrenze konstruieren.
F37: Wenn der Diskriminator im späteren Stadium kaum zwischen normalen Proben und gefälschten Proben unterscheiden kann, wird der GAN-Teil zu diesem Zeitpunkt von geringer Bedeutung sein. Wird AE-GAN zu AE degenerieren?
A37: Wenn der Diskriminator tatsächlich keine normalen Proben und gefälschten Proben identifizieren kann, ist von außen ersichtlich, dass das Training des Generators sehr erfolgreich ist. In der Anomalieerkennungsphase wird nur der Generator verwendet Der Diskriminator wird nicht verwendet. Der Generator im GAN-Netzwerk ist von großer Bedeutung, sodass AE-GAN nicht zu AE degeneriert. Es kann als aktualisierte Version von AE verstanden werden, bei der es sich um eine regulierte AE handelt.
F38: Haben Sie versucht, Transformer anstelle von RNN zu verwenden?
A38: In Szenarien mit kleinen Stichproben und hohen Anforderungen an die Interpretierbarkeit wurde noch kein solcher Versuch unternommen, und entsprechende Versuche werden möglicherweise später unternommen.
F39: Was ist der Unterschied zwischen AE-GAN und VAE?
A39: VAE ist auch eine häufig verwendete Methode zur Anomalieerkennung. VAE verwendet eine vorherige Gaußsche Verteilung in der verborgenen Schicht und ändert die Form der vorherigen Gaußschen Verteilung, um sie an die realen Daten anzupassen, wodurch die beiden Verteilungen äquivalent werden. VAE verwendet jedoch die Verlustfunktion KL-Divergenz anstelle von JSD-Divergenz, und KL-Divergenz ist asymmetrisch und funktioniert in komplexen Beispielen möglicherweise nicht gut.
F40: Wird es während des Experiments zu starkem oder fehlendem Datenrauschen in den Signalfunktionen kommen? Was sind die besseren Methoden zur Feature-Bereinigung?
A40: Der Ladepistolenkoffer im Artikel weist erhebliche Geräusche auf. Einige auf Zeitreihen basierende Zerlegungsmethoden können periodische Elemente, Trendelemente, Rauschelemente usw. in der Zeitreihe zerlegen. Fehlende Merkmale können mithilfe unvollständiger Datenmethoden verarbeitet werden.
F41: Können Verbesserungsstrategien wie APA zum Training hinzugefügt werden?
A41: Am Beispiel von GAN wird die Probenverbesserung hauptsächlich durch Hinzufügen von Rauschen durchgeführt, und die APA-Verbesserungsstrategie wird nicht verwendet.
F42: Wenn im zweiten Schritt von 4.1.(3) der Normalbereich ein großes Intervall umfasst und es 3 Proben 1, 2 und 3 gibt, sind Proben 1 und 2 normale Proben und Probe 3 Ist die Probe 1 und die Probe 2 abnormal, liegen sie auf beiden Seiten des normalen Bereichs und Probe 3 liegt nicht weit neben der Probe 1, hat aber den normalen Bereich überschritten? Dann ist der Rekonstruktionsfehler zwischen den Proben 1 und 2 größer die der Proben 1 und 3?
A42: Die in diesem Artikel bereitgestellten Referenzen enthalten viele extreme Beispiele. Das von Ihnen zitierte Beispiel ist beispielsweise ein typisches Beispiel für eine Zwei-Gauß-Kugel. AE-GAN kann diese Art von Problemen lösen.
Das obige ist der detaillierte Inhalt vonPraxis des NIO-Deep-Learning-Algorithmus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr