
Heim >Technologie-Peripheriegeräte >KI >Chinesisches Team unterwandert Lebenslauf! SEEM teilt alle Explosionen perfekt und teilt das „augenblickliche Universum' mit einem Klick auf
Chinesisches Team unterwandert Lebenslauf! SEEM teilt alle Explosionen perfekt und teilt das „augenblickliche Universum' mit einem Klick auf

- 王林nach vorne
- 2023-05-14 22:13:041304Durchsuche
Das Aufkommen von Metas „Divide Everything“ ließ viele Menschen ausrufen, dass CV nicht mehr existiert.
Basierend auf diesem Modell haben viele Internetnutzer weitere Arbeiten durchgeführt, beispielsweise Grounded SAM.
Durch die gemeinsame Verwendung von Stable Diffusion, Whisper und ChatGPT können Sie einen Hund durch Stimme in einen Affen verwandeln.

Und jetzt können Sie durch multimodale Eingabeaufforderungen nicht nur per Spracheingabe alles überall gleichzeitig segmentieren.
Wie geht das konkret?
Klicken Sie mit der Maus, um den geteilten Inhalt direkt auszuwählen.

Öffne deinen Mund.

Wischen Sie einfach darüber und schon ist das komplette Emoticon-Paket da.

Sie können das Video sogar teilen.

Die neueste Forschung zu SEEM wurde gemeinsam von Wissenschaftlern der University of Wisconsin-Madison, Microsoft Research und anderen Institutionen durchgeführt.
Segmentieren Sie Bilder ganz einfach mithilfe verschiedener Arten von Hinweisen, visuellen Hinweisen (Punkte, Markierungen, Kästchen, Kritzeleien und Bildfragmente) und verbalen Hinweisen (Text und Audio) mit SEEM.

Adresse des Artikels: https://arxiv.org/pdf/2304.06718.pdf
Das Interessante am Titel dieses Artikels ist, dass er sich auf eine amerikanische Science-Fiction bezieht Der 2022 erschienene Film „Everything Everywhere All at Once“ hat einen sehr ähnlichen Namen.

NVIDIA-Wissenschaftler Jim Fan sagte, dass der Oscar für die beste Arbeit an „Segment Everything Everywhere All at Once“ geht.
Eine einheitliche, multifunktionale Schnittstelle zur Aufgabenspezifikation ist die Grundlage für die Erweiterung Die Größe des großformatigen Modells ist der Schlüssel. Multimodale Eingabeaufforderungen sind der Weg der Zukunft.

Nachdem sie die Zeitung gelesen hatten, sagten Internetnutzer, dass der Lebenslauf jetzt beginnt, große Modelle zu akzeptieren. Wo ist die Zukunft für Doktoranden?

Oscar Best Titled Paper
Inspiriert durch die Entwicklung prompt-basierter universeller Schnittstellen für LLMs schlugen Forscher SEEM vor.
Wie in der Abbildung gezeigt, kann das SEEM-Modell jede Segmentierungsaufgabe im offenen Satz ohne Hinweise ausführen, z. B. semantische Segmentierung, Instanzsegmentierung und Panoramasegmentierung.
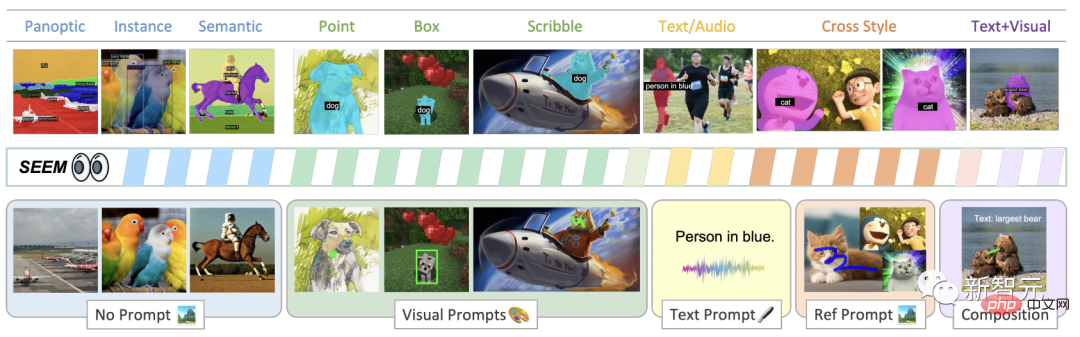
Darüber hinaus unterstützt es jede Kombination von visuellen, Text- und Zitatbereichshinweisen , was eine vielseitige und interaktive Referenzaufteilung ermöglicht.
In Bezug auf die Modellarchitektur verwendet SEEM eine gemeinsame Encoder-Decoder-Architektur. Das Besondere daran ist die komplexe Interaktion zwischen Abfragen und Eingabeaufforderungen.
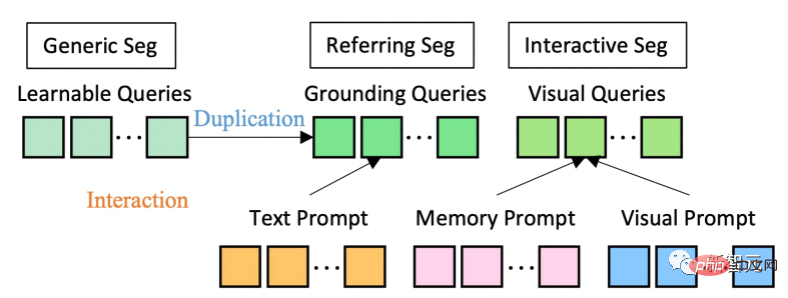
Funktionen und Hinweise werden vom entsprechenden Encoder oder Sampler-A-Gelenk codiert visueller semantischer Raum.
Lernbare Abfragen werden zufällig initialisiert, und der SEEM-Decoder akzeptiert lernbare Abfragen, Bildfunktionen und Textaufforderungen als Ein- und Ausgabe, einschließlich Klassen- und Maskeneinbettungen, für Maskierung und semantische Vorhersage.
Es ist erwähnenswert, dass das SEEM-Modell mehrere Interaktionsrunden aufweist. Jede Runde besteht aus einem manuellen Zyklus und einem Modellzyklus.
In der manuellen Schleife wird die Maskenausgabe der vorherigen Iteration manuell empfangen und durch visuelle Hinweise wird positives Feedback für die nächste Decodierungsrunde gegeben. In der Modellschleife empfängt und aktualisiert das Modell Speicherhinweise für zukünftige Vorhersagen.
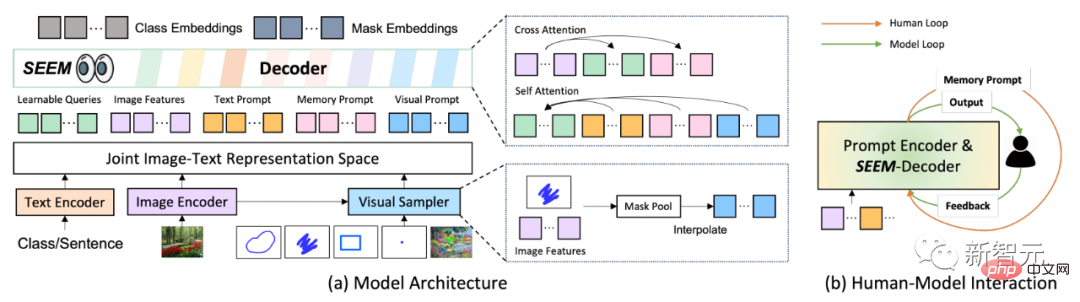
Über SEEM können Sie ein Bild des Optimus Prime-Trucks bereitstellen. Segmentieren Sie Optimus Prime auf einem beliebigen Zielbild.

Generieren Sie Masken aus vom Benutzer eingegebenem Text für die Segmentierung mit einem Klick.

Darüber hinaus können Sie mit SEEM Objekte mit ähnlicher Semantik segmentieren das Zielbild.

Darüber hinaus versteht SEEM räumliche Zusammenhänge sehr gut. Nachdem die Zebras in der oberen linken Reihe mit Graffiti versehen wurden, wird auch das Zebra ganz links segmentiert.

SEEM kann Bilder auch auf Videomasken verweisen, es ist kein Video erforderlich Datentraining kann Videos perfekt segmentieren.


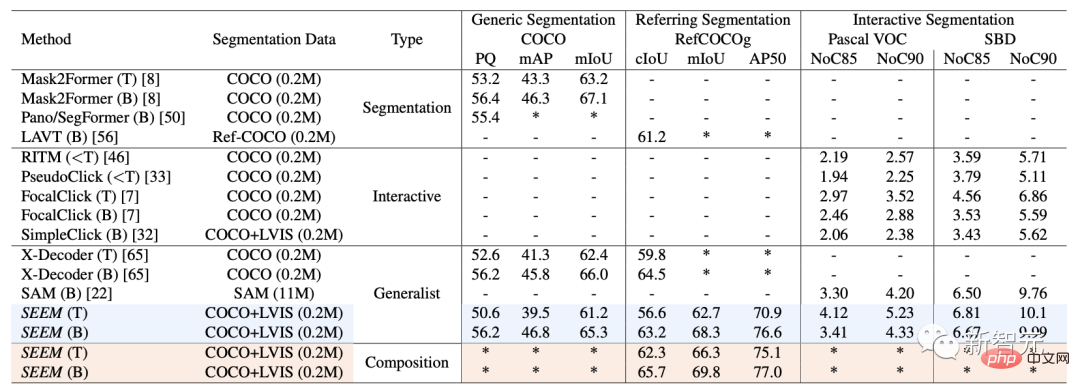
In Bezug auf Datensätze und Einstellungen wurde SEEM anhand von drei Datensätzen trainiert: Panoramasegmentierung, Referenzsegmentierung und interaktive Segmentierung.
Interaktive Segmentierung
Bei der interaktiven Segmentierung verglichen die Forscher SEEM mit modernsten interaktiven Segmentierungsmodellen.
Als allgemeines Modell hat SEEM eine vergleichbare Leistung wie RITM, SimpleClick usw. erreicht. Und es erreicht eine sehr ähnliche Leistung wie SAM und verwendet außerdem 50 weitere segmentierte Daten für das Training.
Bemerkenswerterweise unterstützt SEEM im Gegensatz zu bestehenden interaktiven Modellen nicht nur klassische Segmentierungsaufgaben, sondern auch eine breite Palette multimodaler Eingaben, darunter Text, Punkte, Kritzeleien, Begrenzungsrahmen und Bilder, die leistungsstarke Kombinationsmöglichkeiten bieten.
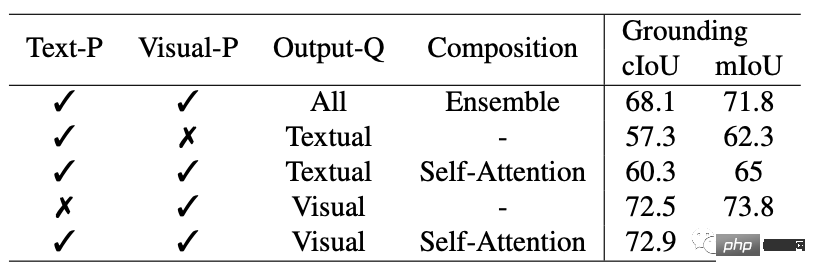
Universelle Segmentierung
Mit einem Satz von Parametern, die für alle Segmentierungsaufgaben vorab trainiert wurden, können Forscher die Leistung anhand universeller Segmentierungsdatensätze direkt bewerten.
SEEM erzielt eine bessere Leistung bei Panoramaansicht, Instanz und semantischer Segmentierung.
Forscher haben vier erwartete Ziele für SEEM:
1. Vielseitigkeit: Durch die Einführung einer multifunktionalen Eingabeaufforderungs-Engine zur Verarbeitung verschiedener Arten von Eingabeaufforderungen, einschließlich Punkten, Kästchen, Graffiti, Masken und Text und ein Referenzbereich eines anderen Bildes;
2. Durch das Erlernen eines gemeinsamen visuell-semantischen Raums, um sofortige Abfragen für visuelle und textuelle Hinweise zu kombinieren;
3 Konversationsverlaufsinformationen durch maskengesteuerte Kreuzaufmerksamkeit bewahren;
4. Semantisches Bewusstsein: Ermöglichen Sie die Segmentierung des offenen Vokabulars, indem Sie Textabfragen und Maskierungstags verwenden. Der Unterschied zwischen
und SAM
Das von Meta vorgeschlagene SAM-Modell kann einen Punkt, einen Begrenzungsrahmen und einen Satz in einem einheitlichen Framework angeben, das den Encoder dazu auffordert, Objekte mit einem Klick zu segmentieren.

SAM verfügt über eine breite Vielseitigkeit, das heißt, es verfügt über die Fähigkeit zur Übertragung ohne Proben, was ausreicht, um verschiedene Anwendungsfälle abzudecken. Es erfordert keine zusätzliche Schulung und kann sofort verwendet werden in neuen Bildfeldern, unabhängig davon, ob es sich um ein Unterwasserfoto oder ein Zellmikroskop handelt.

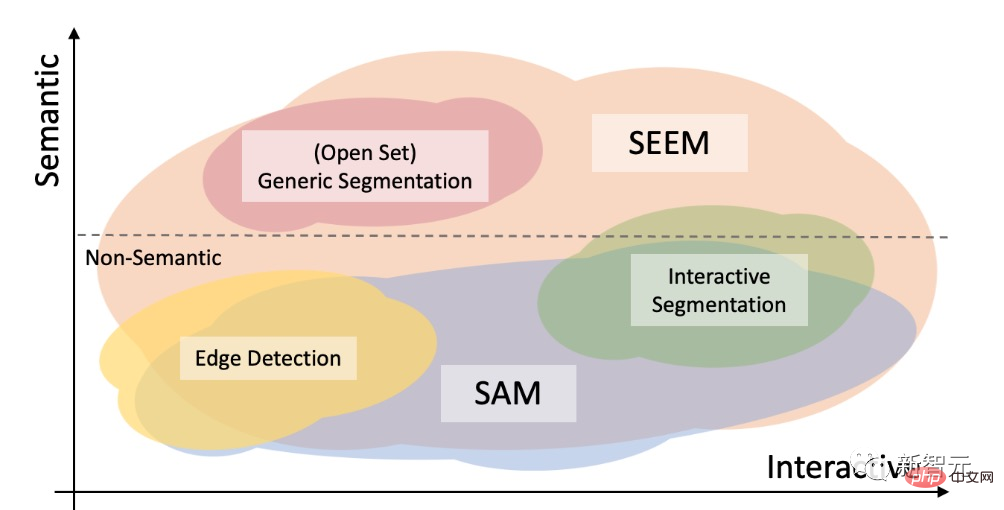
Die Forscher verglichen SEEM und SAM hinsichtlich ihrer interaktiven und semantischen Fähigkeiten für drei Segmentierungsaufgaben (Kantenerkennung, offene Menge und interaktive Segmentierung).
Die Segmentierung offener Mengen erfordert auch eine Semantik auf hoher Ebene und erfordert keine Interaktion.
Im Vergleich zu SAM deckt SEEM ein breiteres Spektrum an Interaktionen und semantischen Ebenen ab.
SAM unterstützt nur begrenzte Interaktionstypen wie Punkte und Begrenzungsrahmen und ignoriert Aufgaben mit hoher Semantik, da es selbst keine semantischen Beschriftungen ausgibt.
Für SEEM haben Forscher zwei Highlights hervorgehoben:
Erstens verfügt SEEM über einen einheitlichen Cue-Encoder, der alle visuellen und sprachlichen Hinweise in einem gemeinsamen Darstellungsraum kodiert. Daher kann SEEM eine allgemeinere Verwendung unterstützen und möglicherweise auf benutzerdefinierte Eingabeaufforderungen erweitert werden.
Zweitens leistet SEEM hervorragende Arbeit bei der Textmaskierung und der Ausgabe semantikbewusster Vorhersagen.
Vorstellung des Autors
Die Erstautorin des Artikels Xueyan Zou
Sie ist derzeit Doktorandin am Fachbereich Informatik der University of Wisconsin-Madison und ihre Betreuerin ist Professor Yong Jae Lee.
Zuvor verbrachte Zou drei Jahre an der University of California, Davis, unter der Leitung desselben Mentors und arbeitete eng mit Dr. Fanyi Xiao zusammen.
Sie erhielt ihren Bachelor-Abschluss von der Hong Kong Baptist University unter der Betreuung von Professor PC Yuen und Professor Chu Xiaowen.

Jianwei Yang

Yang ist leitender Forscher in der Deep-Learning-Gruppe von Microsoft Research in Redmond unter der Leitung von Dr. Jianfeng Gao.
Yangs Forschung konzentriert sich hauptsächlich auf Computer Vision, Vision und Sprache sowie maschinelles Lernen. Er konzentriert sich auf verschiedene Ebenen des strukturierten visuellen Verständnisses und darauf, wie diese für die intelligente Interaktion mit Menschen durch Sprache und Umweltverkörperung weiter genutzt werden können.
Bevor er im März 2020 zu Microsoft kam, promovierte Yang in Informatik an der School of Interactive Computing der Georgia Tech, wo sein Berater Professor Devi Parikh war, und er arbeitete auch eng mit Professor Dhruv Batra zusammen.
Gao Jianfeng

Gao Jianfeng ist ein angesehener Wissenschaftler und Vizepräsident von Microsoft Research, ein Mitglied von IEEE und ein angesehenes Mitglied von ACM.
Derzeit leitet Gao Jianfeng die Deep-Learning-Gruppe. Die Mission der Gruppe besteht darin, den Stand der Technik des Deep Learning und seiner Anwendungen im natürlichen Sprach- und Bildverständnis voranzutreiben und Fortschritte bei Konversationsmodellen und -methoden zu erzielen.
Die Forschung umfasst hauptsächlich neuronale Sprachmodelle für das Verständnis und die Erzeugung natürlicher Sprache, neuronales symbolisches Computing, Grundlagen und Verständnis visueller Sprache, künstliche Konversationsintelligenz usw.
Von 2014 bis 2018 war Gao Jianfeng als Partnerforschungsmanager für kommerzielle künstliche Intelligenz in der Abteilung für künstliche Intelligenz und Forschung von Microsoft und im Deep Learning Technology Center (DLTC) von Redmond Microsoft Research tätig.
Von 2006 bis 2014 war Gao Jianfeng leitender Forscher in der Gruppe zur Verarbeitung natürlicher Sprache.
Yong Jae Lee

Lee ist außerordentlicher Professor am Fachbereich Informatik der University of Washington, Madison.
Er verbrachte ein Jahr als Gastdozent für künstliche Intelligenz bei Cruise, bevor er im Herbst 2021 an die UW-Madison kam, und davor war er 6 Jahre lang als Assistenz- und außerordentlicher Professor an der University of California, Davis tätig.
Er verbrachte außerdem ein Jahr als Postdoktorand am Robotics Institute der Carnegie Mellon University.
Er erhielt seinen Doktortitel im Mai 2012 von der University of Texas in Austin bei Kristen Grauman und seinen BA von der University of Illinois in Urbana-Champaign im Mai 2006.
Außerdem arbeitete er als Sommerpraktikant bei Microsoft Research bei Larry Zitnick und Michael Cohen.
Derzeit konzentriert sich Lees Forschung auf Computer Vision und maschinelles Lernen. Lee ist besonders daran interessiert, leistungsstarke visuelle Erkennungssysteme zu entwickeln, die visuelle Daten mit minimaler menschlicher Aufsicht verstehen können.
Derzeit hat SEEM eine Demo geöffnet:
https://huggingface.co/spaces/xdecoder/SEEM
Beeilen Sie sich und probieren Sie es aus.
Das obige ist der detaillierte Inhalt vonChinesisches Team unterwandert Lebenslauf! SEEM teilt alle Explosionen perfekt und teilt das „augenblickliche Universum' mit einem Klick auf. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr