
Heim >Backend-Entwicklung >Python-Tutorial >Was ist Python-Multithreading und wie wird es verwendet?
Was ist Python-Multithreading und wie wird es verwendet?

- WBOYnach vorne
- 2023-05-13 11:55:14935Durchsuche
Was ist ein Thread? Warum willst du es?
Im Kern ist Python eine lineare Sprache, aber das Threading-Modul ist praktisch, wenn Sie mehr Rechenleistung benötigen. Obwohl Threads in Python nicht für paralleles CPU-Computing verwendet werden können, eignen sie sich gut für I/O-Vorgänge wie Web Scraping, da der Prozessor im Leerlauf ist und auf Daten wartet.
Threads verändern das Spiel, da viele Netzwerk-/Daten-I/O-bezogene Skripte die meiste Zeit damit verbringen, auf Daten von Remote-Quellen zu warten. Da Downloads möglicherweise nicht verknüpft sind (d. h. separate Websites crawlen), kann der Prozessor parallel von verschiedenen Datenquellen herunterladen und die Ergebnisse am Ende zusammenführen. Bei CPU-intensiven Prozessen bietet die Verwendung des Thread-Moduls kaum Vorteile.
Glücklicherweise sind Threads in der Standardbibliothek enthalten:
import threading from queue import Queue import time
Sie können target als aufrufbares Objekt und args verwenden, um Argumente an die Funktion zu übergeben start startet den Thread. target作为可调用对象,使用args将参数传递给函数,并start启动线程。
def testThread(num): print num if __name__ == '__main__': for i in range(5): t = threading.Thread(target=testThread, arg=(i,)) t.start()
如果你以前从未见过if __name__ == '__main__':,这基本上是一种确保嵌套在其中的代码仅在脚本直接运行(而不是导入)时运行的方法。
锁
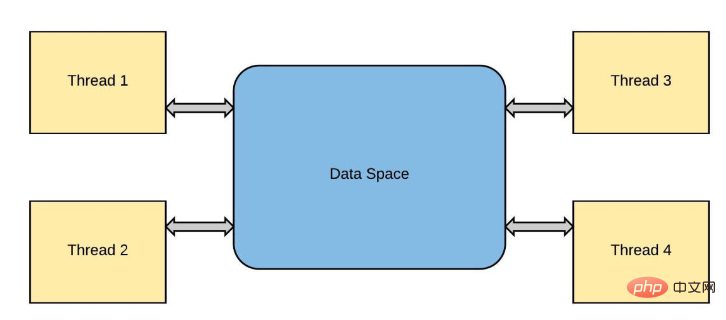
同一操作系统进程的线程将计算工作负载分布到多个内核中,如C++和Java等编程语言所示。通常,python只使用一个进程,从该进程生成一个主线程来执行运行时。由于一种称为全局解释器锁(global interpreter lock)的锁定机制,它保持在单个核上,而不管计算机有多少核,也不管产生了多少新线程,这种机制是为了防止所谓的竞争条件。
提到竞争,我想到了想到 NASCAR 和一级方程式赛车。让我们用这个类比,想象所有一级方程式赛车手都试图同时在一辆赛车上比赛。听起来很荒谬,对吧?,这只有在每个司机都可以使用自己的车的情况下才有可能,或者最好还是一次跑一圈,每次把车交给下一个司机。
这与线程中发生的情况非常相似。线程是从“主”线程“派生”的,每个后续线程都是前一个线程的副本。这些线程都存在于同一进程“上下文”(事件或竞争)中,因此分配给该进程的所有资源(如内存)都是共享的。例如,在典型的python解释器会话中:
>>> a = 8
在这里,a 通过让内存中的某个任意位置暂时保持值 8 来消耗很少的内存 (RAM)。
到目前为止一切顺利,让我们启动一些线程并观察它们的行为,当添加两个数字x时y:
import time
import threading
from threading import Thread
a = 8
def threaded_add(x, y):
# simulation of a more complex task by asking
# python to sleep, since adding happens so quick!
for i in range(2):
global a
print("computing task in a different thread!")
time.sleep(1)
#this is not okay! but python will force sync, more on that later!
a = 10
print(a)
# the current thread will be a subset fork!
if __name__ != "__main__":
current_thread = threading.current_thread()
# here we tell python from the main
# thread of execution make others
if __name__ == "__main__":
thread = Thread(target = threaded_add, args = (1, 2))
thread.start()
thread.join()
print(a)
print("main thread finished...exiting")
>>> computing task in a different thread! >>> 10 >>> computing task in a different thread! >>> 10 >>> 10 >>> main thread finished...exiting
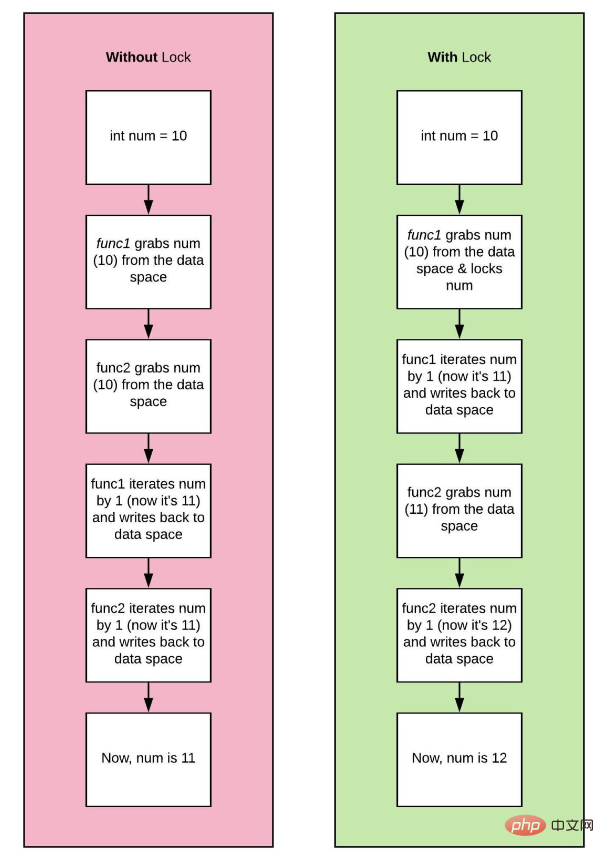
两个线程当前正在运行。让我们把它们称为thread_one和thread_two。如果thread_one想要用值10修改a,而thread_two同时尝试更新同一变量,我们就有问题了!将出现称为数据竞争的情况,并且a的结果值将不一致。
一场你没有看的赛车比赛,但从你的两个朋友那里听到了两个相互矛盾的结果!thread_one告诉你一件事,thread two
a = 8 # spawns two different threads 1 and 2 # thread_one updates the value of a to 10 if (a == 10): # a check #thread_two updates the value of a to 15 a = 15 b = a * 2 # if thread_one finished first the result will be 20 # if thread_two finished first the result will be 30 # who is right?
Wenn Sie es noch nie zuvor gesehen haben if __name__ == '__main__':, ist dies im Grunde ein Code, der sicherstellt, dass er in der Methode verschachtelt ist Das wird nur ausgeführt, wenn das Skript direkt ausgeführt (und nicht importiert) wird.
Sperren
Threads desselben Betriebssystemprozesses verteilen Rechenlasten auf mehrere Kerne, z.B. Programmiersprachen wie C++ und Java werden angezeigt. Normalerweise verwendet Python nur einen Prozess, aus dem ein Hauptthread erzeugt wird, um die Laufzeit auszuführen. Aufgrund eines Sperrmechanismus namens Global Interpreter Lock bleibt es auf einem einzelnen Kern, unabhängig davon, wie viele Kerne der Computer hat oder wie viele neue Threads erzeugt werden. Dies soll sogenannte Race Conditions verhindern.
Das ist dem, was im Thread passiert, sehr ähnlich. Threads werden vom „Haupt“-Thread „verzweigt“ und jeder nachfolgende Thread ist eine Kopie des vorherigen Threads. Diese Threads existieren alle im selben Prozess-„Kontext“ (Ereignis oder Rennen), sodass alle dem Prozess zugewiesenen Ressourcen (z. B. Speicher) gemeinsam genutzt werden. Zum Beispiel in einer typischen Python-Interpreter-Sitzung:
import sys import gc hello = "world" #reference to 'world' is 2 print (sys.getrefcount(hello)) bye = "world" other_bye = bye print(sys.getrefcount(bye)) print(gc.get_referrers(other_bye))
Hier führt a dies aus, indem es den Wert 8 vorübergehend an einer beliebigen Stelle im Speicher hält sehr wenig Speicher (RAM). 🎜
So weit so gut, starten wir einige Threads und beobachten ihr Verhalten beim Addieren von zwei Zahlen xy code>: 🎜<pre class="brush:php;toolbar:false">>>> 4
>>> 6
>>> [['sys', 'gc', 'hello', 'world', 'print', 'sys', 'getrefcount', 'hello', 'bye', 'world', 'other_bye', 'bye', 'print', 'sys', 'getrefcount', 'bye', 'print', 'gc', 'get_referrers', 'other_bye'], (0, None, 'world'), {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.sourcefileloader>, '__spec__': None, '__annotations__': {}, '__builtins__': <module>, '__file__': 'test.py', '__cached__': None, 'sys': <module>, 'gc': <module>, 'hello': 'world', 'bye': 'world', 'other_bye': 'world'}]</module></module></module></_frozen_importlib_external.sourcefileloader></pre>rrreeZwei Threads laufen derzeit. Nennen wir sie <code>thread_one und thread_two. Wenn thread_one a mit dem Wert 10 ändern möchte und thread_two gleichzeitig versucht, dieselbe Variable zu aktualisieren, haben wir ein Problem! Es tritt ein sogenannter Datenwettlauf auf, und die resultierenden Werte von a sind inkonsistent. 🎜
Eine Rennveranstaltung, die Sie nicht gesehen, aber von zwei Ihrer Freunde zwei widersprüchliche Ergebnisse gehört haben! thread_one sagt etwas, thread_one widerlegt es! Hier ist ein Pseudocode-Ausschnitt zur Veranschaulichung: 🎜
import time, os
from threading import Thread, current_thread
from multiprocessing import current_process
COUNT = 200000000
SLEEP = 10
def io_bound(sec):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start sleeping...")
time.sleep(sec)
print(f"{pid} * {processName} * {threadName} \
---> Finished sleeping...")
def cpu_bound(n):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start counting...")
while n>0:
n -= 1
print(f"{pid} * {processName} * {threadName} \
---> Finished counting...")
def timeit(function,args,threaded=False):
start = time.time()
if threaded:
t1 = Thread(target = function, args =(args, ))
t2 = Thread(target = function, args =(args, ))
t1.start()
t2.start()
t1.join()
t2.join()
else:
function(args)
end = time.time()
print('Time taken in seconds for running {} on Argument {} is {}s -{}'.format(function,args,end - start,"Threaded" if threaded else "None Threaded"))
if __name__=="__main__":
#Running io_bound task
print("IO BOUND TASK NON THREADED")
timeit(io_bound,SLEEP)
print("IO BOUND TASK THREADED")
#Running io_bound task in Thread
timeit(io_bound,SLEEP,threaded=True)
print("CPU BOUND TASK NON THREADED")
#Running cpu_bound task
timeit(cpu_bound,COUNT)
print("CPU BOUND TASK THREADED")
#Running cpu_bound task in Thread
timeit(cpu_bound,COUNT,threaded=True)🎜Was zum Teufel ist los? 🎜🎜Python ist eine interpretierte Sprache, das heißt, sie verfügt über einen Interpreter – ein Programm, das seinen Quellcode aus einer anderen Sprache analysiert! Einige dieser Interpreter in Python umfassen cpython, pypypy, Jpython und IronPython, wobei cpython die ursprüngliche Implementierung von Python ist. 🎜🎜CPython ist ein Interpreter, der externe Funktionsschnittstellen mit C und anderen Programmiersprachen bereitstellt. Er kompiliert Python-Quellcode in Zwischenbytecode, der von der virtuellen CPython-Maschine interpretiert wird. Bisher und in Zukunft drehte sich die Diskussion um CPython und das Verständnis des Verhaltens in der Umgebung. 🎜内存模型和锁定机制
编程语言使用程序中的对象来执行操作。这些对象由基本数据类型组成,如string、integer或boolean。它们还包括更复杂的数据结构,如list或classes/objects。程序对象的值存储在内存中,以便快速访问。在程序中使用变量时,进程将从内存中读取值并对其进行操作。在早期的编程语言中,大多数开发人员负责他们程序中的所有内存管理。这意味着在创建列表或对象之前,首先必须为变量分配内存。在这样做时,你可以继续释放以“释放”内存。
在python中,对象通过引用存储在内存中。引用是对象的一种标签,因此一个对象可以有许多名称,比如你如何拥有给定的名称和昵称。引用是对象的精确内存位置。引用计数器用于python中的垃圾收集,这是一种自动内存管理过程。
在引用计数器的帮助下,python通过在创建或引用对象时递增引用计数器和在取消引用对象时递减来跟踪每个对象。当引用计数为0时,对象的内存将被释放。
import sys import gc hello = "world" #reference to 'world' is 2 print (sys.getrefcount(hello)) bye = "world" other_bye = bye print(sys.getrefcount(bye)) print(gc.get_referrers(other_bye))
>>> 4
>>> 6
>>> [['sys', 'gc', 'hello', 'world', 'print', 'sys', 'getrefcount', 'hello', 'bye', 'world', 'other_bye', 'bye', 'print', 'sys', 'getrefcount', 'bye', 'print', 'gc', 'get_referrers', 'other_bye'], (0, None, 'world'), {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.sourcefileloader>, '__spec__': None, '__annotations__': {}, '__builtins__': <module>, '__file__': 'test.py', '__cached__': None, 'sys': <module>, 'gc': <module>, 'hello': 'world', 'bye': 'world', 'other_bye': 'world'}]</module></module></module></_frozen_importlib_external.sourcefileloader>
需要保护这些参考计数器变量,防止竞争条件或内存泄漏。以保护这些变量;可以将锁添加到跨线程共享的所有数据结构中。
CPython 的 GIL 通过一次允许一个线程控制解释器来控制 Python 解释器。它为单线程程序提供了性能提升,因为只需要管理一个锁,但代价是它阻止了多线程 CPython 程序在某些情况下充分利用多处理器系统。
当用户编写python程序时,性能受CPU限制的程序和受I/O限制的程序之间存在差异。CPU通过同时执行许多操作将程序推到极限,而I/O程序必须花费时间等待I/O。
因此,只有多线程程序在GIL中花费大量时间来解释CPython字节码;GIL成为瓶颈。即使没有严格必要,GIL也会降低性能。例如,一个用python编写的同时处理IO和CPU任务的程序:
import time, os
from threading import Thread, current_thread
from multiprocessing import current_process
COUNT = 200000000
SLEEP = 10
def io_bound(sec):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start sleeping...")
time.sleep(sec)
print(f"{pid} * {processName} * {threadName} \
---> Finished sleeping...")
def cpu_bound(n):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start counting...")
while n>0:
n -= 1
print(f"{pid} * {processName} * {threadName} \
---> Finished counting...")
def timeit(function,args,threaded=False):
start = time.time()
if threaded:
t1 = Thread(target = function, args =(args, ))
t2 = Thread(target = function, args =(args, ))
t1.start()
t2.start()
t1.join()
t2.join()
else:
function(args)
end = time.time()
print('Time taken in seconds for running {} on Argument {} is {}s -{}'.format(function,args,end - start,"Threaded" if threaded else "None Threaded"))
if __name__=="__main__":
#Running io_bound task
print("IO BOUND TASK NON THREADED")
timeit(io_bound,SLEEP)
print("IO BOUND TASK THREADED")
#Running io_bound task in Thread
timeit(io_bound,SLEEP,threaded=True)
print("CPU BOUND TASK NON THREADED")
#Running cpu_bound task
timeit(cpu_bound,COUNT)
print("CPU BOUND TASK THREADED")
#Running cpu_bound task in Thread
timeit(cpu_bound,COUNT,threaded=True)
>>> IO BOUND TASK NON THREADED >>> 17244 * MainProcess * MainThread ---> Start sleeping... >>> 17244 * MainProcess * MainThread ---> Finished sleeping... >>> 17244 * MainProcess * MainThread ---> Start sleeping... >>> 17244 * MainProcess * MainThread ---> Finished sleeping... >>> Time taken in seconds for running <function> on Argument 10 is 20.036664724349976s -None Threaded >>> IO BOUND TASK THREADED >>> 10180 * MainProcess * Thread-1 ---> Start sleeping... >>> 10180 * MainProcess * Thread-2 ---> Start sleeping... >>> 10180 * MainProcess * Thread-1 ---> Finished sleeping... >>> 10180 * MainProcess * Thread-2 ---> Finished sleeping... >>> Time taken in seconds for running <function> on Argument 10 is 10.01464056968689s -Threaded >>> CPU BOUND TASK NON THREADED >>> 14172 * MainProcess * MainThread ---> Start counting... >>> 14172 * MainProcess * MainThread ---> Finished counting... >>> 14172 * MainProcess * MainThread ---> Start counting... >>> 14172 * MainProcess * MainThread ---> Finished counting... >>> Time taken in seconds for running <function> on Argument 200000000 is 44.90199875831604s -None Threaded >>> CPU BOUND TASK THEADED >>> 15616 * MainProcess * Thread-1 ---> Start counting... >>> 15616 * MainProcess * Thread-2 ---> Start counting... >>> 15616 * MainProcess * Thread-1 ---> Finished counting... >>> 15616 * MainProcess * Thread-2 ---> Finished counting... >>> Time taken in seconds for running <function> on Argument 200000000 is 106.09711360931396s -Threaded</function></function></function></function>
从结果中我们注意到,multithreading在多个IO绑定任务中表现出色,执行时间为10秒,而非线程方法执行时间为20秒。我们使用相同的方法执行CPU密集型任务。好吧,最初它确实同时启动了我们的线程,但最后,我们看到整个程序的执行需要大约106秒!然后发生了什么?这是因为当Thread-1启动时,它获取全局解释器锁(GIL),这防止Thread-2使用CPU。因此,Thread-2必须等待Thread-1完成其任务并释放锁,以便它可以获取锁并执行其任务。锁的获取和释放增加了总执行时间的开销。因此,可以肯定地说,线程不是依赖CPU执行任务的理想解决方案。
这种特性使并发编程变得困难。如果GIL在并发性方面阻碍了我们,我们是不是应该摆脱它,还是能够关闭它?。嗯,这并不容易。其他功能、库和包都依赖于GIL,因此必须有一些东西来取代它,否则整个生态系统将崩溃。这是一个很难解决的问题。
多进程
我们已经证实,CPython使用锁来保护数据不受竞速的影响,尽管这种锁存在,但程序员已经找到了一种显式实现并发的方法。当涉及到GIL时,我们可以使用multiprocessing库来绕过全局锁。多处理实现了真正意义上的并发,因为它在不同CPU核上跨不同进程执行代码。它创建了一个新的Python解释器实例,在每个内核上运行。不同的进程位于不同的内存位置,因此它们之间的对象共享并不容易。在这个实现中,python为每个要运行的进程提供了不同的解释器;因此在这种情况下,为多处理中的每个进程提供单个线程。
import os
import time
from multiprocessing import Process, current_process
SLEEP = 10
COUNT = 200000000
def count_down(cnt):
pid = os.getpid()
processName = current_process().name
print(f"{pid} * {processName} \
---> Start counting...")
while cnt > 0:
cnt -= 1
def io_bound(sec):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start sleeping...")
time.sleep(sec)
print(f"{pid} * {processName} * {threadName} \
---> Finished sleeping...")
if __name__ == '__main__':
# creating processes
start = time.time()
#CPU BOUND
p1 = Process(target=count_down, args=(COUNT, ))
p2 = Process(target=count_down, args=(COUNT, ))
#IO BOUND
#p1 = Process(target=, args=(SLEEP, ))
#p2 = Process(target=count_down, args=(SLEEP, ))
# starting process_thread
p1.start()
p2.start()
# wait until finished
p1.join()
p2.join()
stop = time.time()
elapsed = stop - start
print ("The time taken in seconds is :", elapsed)
>>> 1660 * Process-2 ---> Start counting... >>> 10184 * Process-1 ---> Start counting... >>> The time taken in seconds is : 12.815475225448608
可以看出,对于cpu和io绑定任务,multiprocessing性能异常出色。MainProcess启动了两个子进程,Process-1和Process-2,它们具有不同的PIDs,每个都执行将COUNT减少到零的任务。每个进程并行运行,使用单独的CPU内核和自己的Python解释器实例,因此整个程序执行只需12秒。
请注意,输出可能以无序的方式打印,因为过程彼此独立。这是因为每个进程都在自己的默认主线程中执行函数。
我们还可以使用asyncio库(上一节我已经讲过了,没看的可以返回到上一节去学习)绕过GIL锁。asyncio的基本概念是,一个称为事件循环的python对象控制每个任务的运行方式和时间。事件循环知道每个任务及其状态。就绪状态表示任务已准备好运行,等待阶段表示任务正在等待某个外部任务完成。在异步IO中,任务永远不会放弃控制,也不会在执行过程中被中断,因此对象共享是线程安全的。
import time
import asyncio
COUNT = 200000000
# asynchronous function defination
async def func_name(cnt):
while cnt > 0:
cnt -= 1
#asynchronous main function defination
async def main ():
# Creating 2 tasks.....You could create as many tasks (n tasks)
task1 = loop.create_task(func_name(COUNT))
task2 = loop.create_task(func_name(COUNT))
# await each task to execute before handing control back to the program
await asyncio.wait([task1, task2])
if __name__ =='__main__':
# get the event loop
start_time = time.time()
loop = asyncio.get_event_loop()
# run all tasks in the event loop until completion
loop.run_until_complete(main())
loop.close()
print("--- %s seconds ---" % (time.time() - start_time))
>>> --- 41.74118399620056 seconds ---
我们可以看到,asyncio需要41秒来完成倒计时,这比multithreading的106秒要好,但对于cpu受限的任务,不如multiprocessing的12秒。Asyncio创建一个eventloop和两个任务task1和task2,然后将这些任务放在eventloop上。然后,程序await任务的执行,因为事件循环执行所有任务直至完成。
为了充分利用python中并发的全部功能,我们还可以使用不同的解释器。JPython和IronPython没有GIL,这意味着用户可以充分利用多处理器系统。
与线程一样,多进程仍然存在缺点:
数据在进程之间混洗会产生 I/O 开销
整个内存被复制到每个子进程中,这对于更重要的程序来说可能是很多开销
Das obige ist der detaillierte Inhalt vonWas ist Python-Multithreading und wie wird es verwendet?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!