
Heim >Backend-Entwicklung >Python-Tutorial >Wie Python die LRU-Cache-Strategie zum Caching verwendet
Wie Python die LRU-Cache-Strategie zum Caching verwendet

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-13 11:34:051888Durchsuche
1. Python-Cache
① Die Rolle des Cachings
Cache ist eine Optimierungstechnologie, die in Anwendungen verwendet werden kann, um kürzlich oder häufig verwendete Daten im Speicher zu speichern. Auf diese Weise kann die Geschwindigkeit des Datenzugriffs verbessert werden. Viel höher als das direkte Lesen von Festplattendateien.
Angenommen, wir erstellen eine Website zur Nachrichtenaggregation, ähnlich wie Feedly, die Nachrichten aus verschiedenen Quellen abruft und diese dann aggregiert und anzeigt. Wenn der Benutzer die Nachrichten durchstöbert, lädt das Hintergrundprogramm den Artikel herunter und zeigt ihn auf dem Bildschirm des Benutzers an. Wenn keine Caching-Technologie verwendet wird und Benutzer denselben Artikel mehrmals durchsuchen, müssen sie ihn mehrmals herunterladen, was ineffizient und unfreundlich ist.
Ein besserer Ansatz besteht darin, den Inhalt nach dem Abrufen jedes Artikels lokal zu speichern, beispielsweise in einer Datenbank. Wenn der Benutzer dann das nächste Mal denselben Artikel öffnet, kann das Hintergrundprogramm den Inhalt stattdessen aus dem lokalen Speicher öffnen Beim erneuten Herunterladen der Quelldatei wird diese Technik als Caching bezeichnet.
② Verwenden Sie das Python-Wörterbuch, um das Caching zu implementieren. Nehmen Sie als Beispiel eine Nachrichtenaggregationswebsite. Es ist nicht erforderlich, den Artikelinhalt jedes Mal herunterzuladen, sondern nur, ob der entsprechende Inhalt vorhanden ist Wenn nicht, lädt der Server den Artikel herunter.
Das folgende Beispielprogramm verwendet ein Python-Wörterbuch, um das Caching zu implementieren. Nach der Ausführung wird die URL des Artikels als Schlüssel und sein Inhalt als Wert verwendet. Sie können das Ergebnis sehen, wenn die Funktion get_article zum zweiten Mal ausgeführt wird wird direkt zurückgegeben und lässt den Server nicht herunterladen:
import requests
cache = dict()
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def get_article(url):
print("Getting article...")
if url not in cache:
cache[url] = get_article_from_server(url)
return cache[url]
get_article("https://www.escapelife.site/love-python.html")
get_article("https://www.escapelife.site/love-python.html")Speichern Sie diesen Code in einer caching.py-Datei, installieren Sie die Anforderungsbibliothek und führen Sie das Skript aus:
# 安装依赖 $ pip install requests # 执行脚本 $ python python_caching.py Getting article... Fetching article from server... Getting article...
Trotz zweimaligem Aufruf von get_article() (Zeile 17 und 18) die Zeichenfolge „ Artikel vom Server abrufen…“, gibt ihn aber trotzdem nur einmal aus. Dies liegt daran, dass nach dem ersten Zugriff auf den Artikel dessen URL und Inhalt im Cache-Wörterbuch abgelegt werden und der Code beim zweiten Mal das Element nicht erneut vom Server abrufen muss.
③ Nachteile der Verwendung von Wörterbüchern für das Caching
Bei der oben genannten Caching-Implementierung gibt es ein sehr großes Problem, nämlich dass der Inhalt des Wörterbuchs unendlich wächst, d. h., wenn eine große Anzahl von Benutzern kontinuierlich Artikel durchsucht, der Hintergrund Das Programm fügt dem Wörterbuch weiterhin Daten hinzu, die gespeichert werden müssen. Dadurch wird der Speicher des Servers gefüllt, was schließlich zum Absturz der Anwendung führt.
- Bei der oben genannten Caching-Implementierung gibt es ein sehr großes Problem, das heißt, der Inhalt des Wörterbuchs wächst unendlich, das heißt, wenn eine große Anzahl von Benutzern kontinuierlich Artikel durchsucht, stopft das Hintergrundprogramm den Inhalt weiter Das muss im Wörterbuch gespeichert werden, und der Speicher des Servers ist voll, was schließlich zum Absturz der Anwendung führt.
- Um das oben genannte Problem zu lösen, benötigen Sie eine Strategie, um zu entscheiden, welche Artikel im Speicher verbleiben und welche Artikel gelöscht werden sollen. Bei diesen Caching-Strategien handelt es sich tatsächlich um Algorithmen, die zur Verwaltung zwischengespeicherter Informationen und zur Auswahl der zu verwerfenden Elemente verwendet werden Platz für neue Artikel.
- Natürlich müssen Sie keinen Algorithmus implementieren, um den Cache zu verwalten, Sie müssen lediglich verschiedene Strategien anwenden, um Elemente aus dem Cache zu entfernen und zu verhindern, dass er über seine maximale Größe hinaus wächst. Fünf übliche Caching-Algorithmen sind wie folgt:
| glish Name | eliminierungsbedingungen, wenn sie am nützlichsten sind? First-In/First-Out | Entfernen Sie die ältesten Einträge. | Neuere Einträge werden höchstwahrscheinlich wiederverwendet Neueste Einträge |
|---|---|---|---|
| Least-Recent-Used-Algorithmus (LRU) | Least-Recent-Used | Entfernt die zuletzt verwendeten Einträge | Die zuletzt verwendeten Einträge werden am wahrscheinlichsten wiederverwendet |
| Zuletzt verwendeter Algorithmus (MRU) | Zuletzt verwendet | Entfernt die zuletzt verwendeten Einträge | Zuletzt nicht verwendete Einträge werden höchstwahrscheinlich wiederverwendet |
| Least-Recent-Hit-Algorithmus (LFU) | Am seltensten verwendet | Entfernt die am seltensten aufgerufenen Elemente | Elemente mit einer hohen Trefferquote werden eher wiederverwendet |
|
Nachdem Sie die oben genannten fünf Caching-Algorithmen gelesen haben, sind Sie etwas verwirrt, wenn Sie LRU und LFU sehen. Der Hauptgrund dafür ist, dass es schwierig ist, ihre wahre Bedeutung durch die entsprechende Erklärung auf Englisch zu verstehen . Der Unterschied zwischen LRU- und LFU-Algorithmen ist:
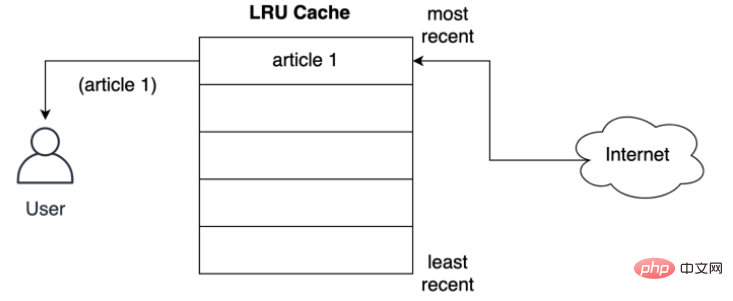
Ein Knoten führt beispielsweise einmal pro Minute eine Seitenplanung durch, wenn die erforderliche Seitenrichtung 2 1 2 4 2 3 4 ist und eine Seitenfehlerunterbrechung auftritt ; wenn der LRU-Algorithmus verwendet wird, sollte Seite 1 geändert werden (zehn Minuten). Seite 1 wurde am längsten nicht verwendet), aber gemäß dem LFU-Algorithmus sollte Seite 3 geändert werden (Seite 3 wird nur einmal innerhalb von zehn Minuten verwendet). ). 2. Detailliertes Verständnis des LRU-Algorithmus① Sehen Sie sich die Eigenschaften des LRU-Cache anDer mit der LRU-Strategie implementierte Cache wird in der Reihenfolge seiner Verwendung sortiert, und der LRU-Algorithmus wird verschoben es an den oberen Rand des Caches. Auf diese Weise kann der Algorithmus am Ende der Liste schnell die Einträge identifizieren, die am längsten nicht verwendet wurden. Wie unten gezeigt, speichert die LRU-Richtlinie Datensätze für den ersten vom Benutzer aus dem Netzwerk angeforderten Artikel:
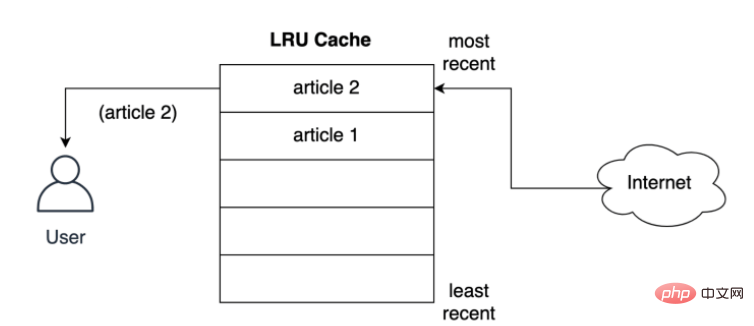
Wie speichert der Cache den Artikel im nächstgelegenen Slot, bevor er dem Benutzer bereitgestellt wird? Wie unten gezeigt, passiert, was passiert, wenn der Benutzer den zweiten Artikel anfordert: Der zweite Artikel wird an der obersten Position gespeichert, d. h. der zweite Artikel nimmt die aktuellste Position ein und verschiebt den ersten Artikel weiter nach unten in der Liste:
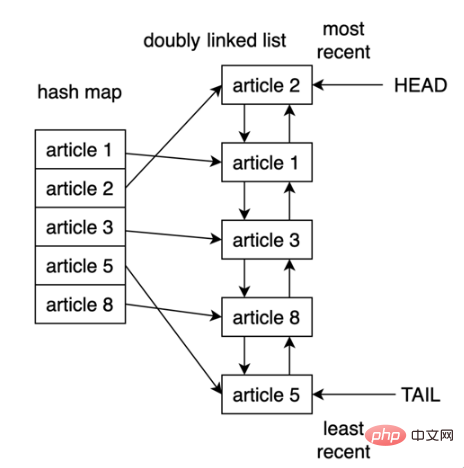
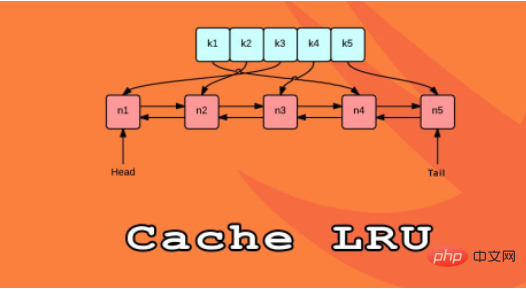
Die LRU Die Strategie geht davon aus, dass die Wahrscheinlichkeit, dass das verwendete Objekt in Zukunft verwendet wird, umso höher ist, je neuer es ist. Daher wird versucht, das Objekt möglichst lange im Cache zu halten. Wenn also ein Eintrag entfernt wird, wird der erste Eintrag zuerst entfernt Ein Cache mit Dokumentenspeicherdatensätzen. ② Sehen Sie sich die Struktur des LRU-Cache anEine Möglichkeit, den LRU-Cache in Python zu implementieren, besteht darin, eine doppelt verknüpfte Liste und eine Hash-Map zu verwenden. Das Kopfelement der doppelt verknüpften Liste zeigt auf den zuletzt verwendeten Eintrag Sein Ende zeigt auf den zuletzt verwendeten Eintrag. Die logische Struktur der LRU-Cache-Implementierung ist wie folgt:
Durch die Verwendung einer Hash-Map kann jeder Eintrag einem bestimmten Ort in der doppelt verknüpften Liste zugeordnet werden, wodurch der Zugriff auf jedes Element im Cache sichergestellt wird. Diese Strategie ist sehr schnell, da der Zugriff auf das zuletzt verwendete Element und die Aktualisierung des Caches beides O(1)-Operationen sind. Ab Python 3.2 hat Python den @lru_cache-Dekorator hinzugefügt, um die LRU-Strategie zu implementieren. Von nun an können Sie diesen Dekorator verwenden, um Funktionen zu dekorieren und ihre Berechnungsergebnisse zwischenzuspeichern. 3. Verwenden Sie lru_cache decorator① Implementierungsprinzip von @lru_cache decoratorEs gibt viele Möglichkeiten, eine schnelle Reaktion der Anwendung zu erreichen, und die Verwendung von Cache ist eine sehr gängige Methode. Caching kann bei richtiger Anwendung die Antworten beschleunigen und die zusätzliche Belastung der Rechenressourcen verringern.
Genau wie die zuvor implementierte Caching-Lösung verwendet auch der @lru_cache-Dekoratorspeicher in Python ein Wörterbuch als Speicherobjekt. Es speichert das Ausführungsergebnis der Funktion im Schlüssel des Wörterbuchs zwischen besteht aus einem Aufruf der Funktion (einschließlich der Parameter der Funktion), was bedeutet, dass die Parameter dieser Funktionen hashbar sein müssen, damit der Dekorator ordnungsgemäß funktioniert. ②Fibonacci-FolgeWir alle sollten wissen, wie man die Fibonacci-Folge berechnet. Die übliche Lösung besteht darin, rekursives Denken zu verwenden:
递归的计算简洁并且直观,但是由于存在大量重复计算,实际运行效率很低,并且会占用较多的内存。但是这里并不是需要关注的重点,只是来作为演示示例而已: # 匿名函数 fib = lambda n: 1 if n <= 1 else fib(n-1) + fib(n-2) # 将时间复杂度降低到线性 fib = lambda n, a=1, b=1: a if n == 0 else fib(n-1, b, a+b) # 保证了匿名函数的匿名性 fib = lambda n, fib: 1 if n <= 1 else fib(n-1, fib) + fib(n-2, fib) ③ 使用 @lru_cache 缓存输出结果使用 @lru_cache 装饰器来缓存的话,可以将函数调用结果存储在内存中,以便再次请求时直接返回结果: from functools import lru_cache
@lru_cache
def fib(n):
if n==1 or n==2:
return 1
else:
return fib(n-1) + fib(n-2)④ 限制 @lru_cache 装饰器大小Python 的 @lru_cache 装饰器提供了一个 maxsize 属性,该属性定义了在缓存开始淘汰旧条目之前的最大条目数,默认情况下,maxsize 设置为 128。 如果将 maxsize 设置为 None 的话,则缓存将无限期增长,并且不会驱逐任何条目。 from functools import lru_cache
@lru_cache(maxsize=16)
def fib(n):
if n==1 or n==2:
return 1
else:
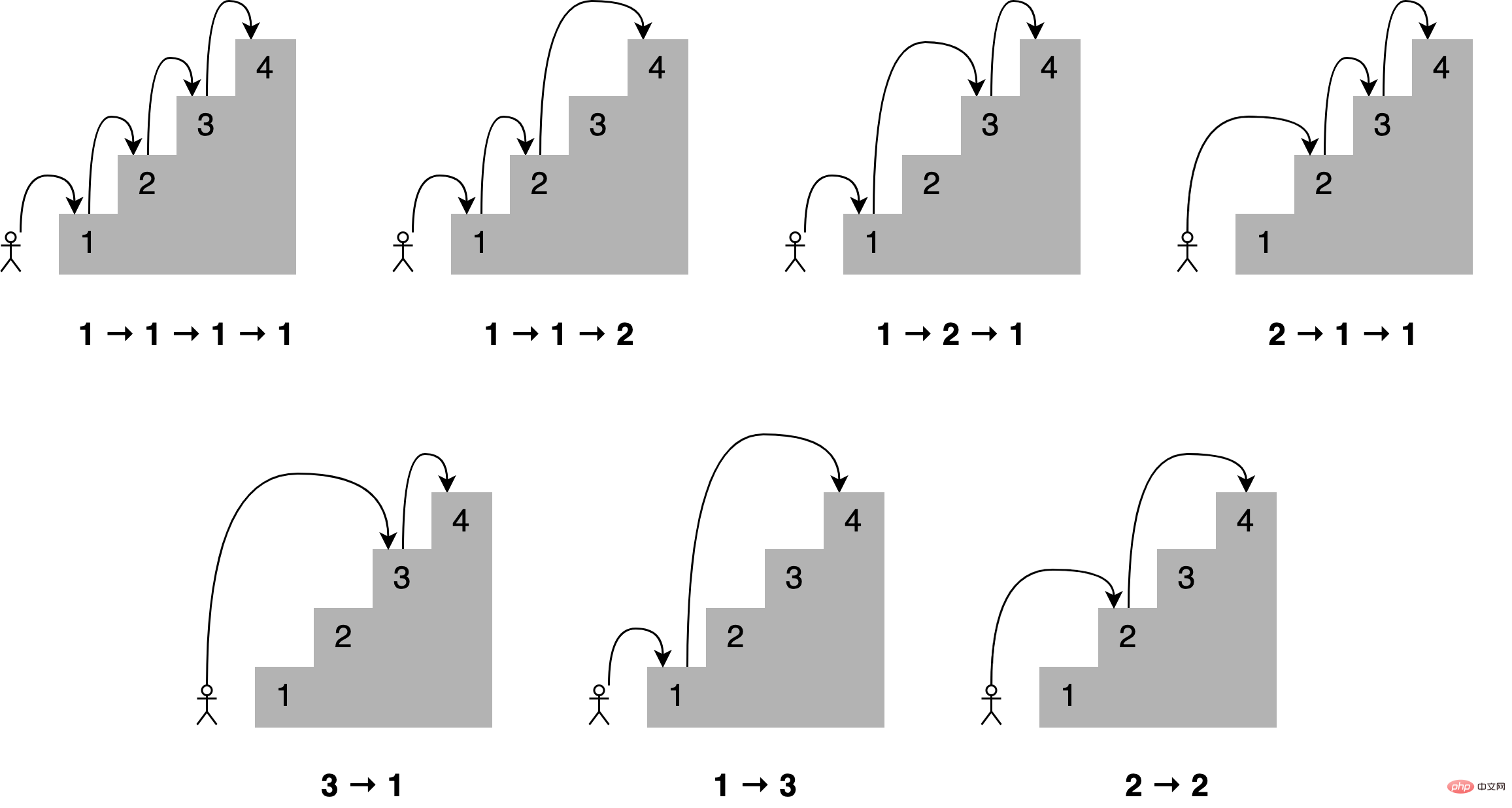
return fib(n-1) + fib(n-2)# 查看缓存列表 >>> print(steps_to.cache_info()) CacheInfo(hits=52, misses=30, maxsize=16, currsize=16) ⑤ 使用 @lru_cache 实现 LRU 缓存就像在前面实现的缓存解决方案一样,@lru_cache 在底层使用一个字典,它将函数的结果缓存在一个键下,该键包含对函数的调用,包括提供的参数。这意味着这些参数必须是可哈希的,才能让 decorator 工作。 示例:玩楼梯: 想象一下,你想通过一次跳上一个、两个或三个楼梯来确定到达楼梯中的一个特定楼梯的所有不同方式,到第四个楼梯有多少条路?所有不同的组合如下所示:
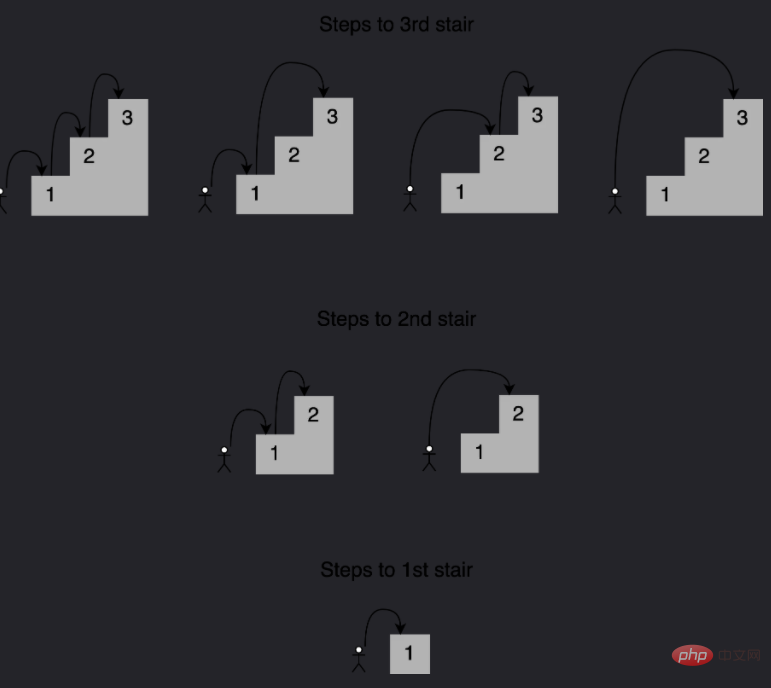
可以这样描述,为了到达当前的楼梯,你可以从下面的一个、两个或三个楼梯跳下去,将能够到达这些点的跳跃组合的数量相加,便能够获得到达当前位置的所有可能方法。 例如到达第四个楼梯的组合数量将等于你到达第三、第二和第一个楼梯的不同方式的总数。如下所示,有七种不同的方法可以到达第四层楼梯:
注意给定阶梯的解是如何建立在较小子问题的答案之上的,在这种情况下,为了确定到达第四个楼梯的不同路径,可以将到达第三个楼梯的四种路径、到达第二个楼梯的两种路径以及到达第一个楼梯的一种路径相加。 这种方法称为递归,下面是一个实现这个递归的函数: def steps_to(stair):
if stair == 1:
# You can reach the first stair with only a single step
# from the floor.
return 1
elif stair == 2:
# You can reach the second stair by jumping from the
# floor with a single two-stair hop or by jumping a single
# stair a couple of times.
return 2
elif stair == 3:
# You can reach the third stair using four possible
# combinations:
# 1. Jumping all the way from the floor
# 2. Jumping two stairs, then one
# 3. Jumping one stair, then two
# 4. Jumping one stair three times
return 4
else:
# You can reach your current stair from three different places:
# 1. From three stairs down
# 2. From two stairs down
# 2. From one stair down
#
# If you add up the number of ways of getting to those
# those three positions, then you should have your solution.
return (
steps_to(stair - 3)
+ steps_to(stair - 2)
+ steps_to(stair - 1)
)
print(steps_to(4))将此代码保存到一个名为 stairs.py 的文件中,并使用以下命令运行它: $ python stairs.py 7 太棒了,这个代码适用于 4 个楼梯,但是数一下要走多少步才能到达楼梯上更高的地方呢?将第 33 行中的楼梯数更改为 30,并重新运行脚本: $ python stairs.py 53798080 可以看到结果超过 5300 万个组合,这可真的有点多。 时间代码: 当找到第 30 个楼梯的解决方案时,脚本花了相当多的时间来完成。要获得基线,可以度量代码运行的时间,要做到这一点,可以使用 Python 的 timeit module,在第 33 行之后添加以下代码: setup_code = "from __main__ import steps_to"
36stmt = "steps_to(30)"
37times = repeat(setup=setup_code, stmt=stmt, repeat=3, number=10)
38print(f"Minimum execution time: {min(times)}")还需要在代码的顶部导入 timeit module: from timeit import repeat 以下是对这些新增内容的逐行解释:
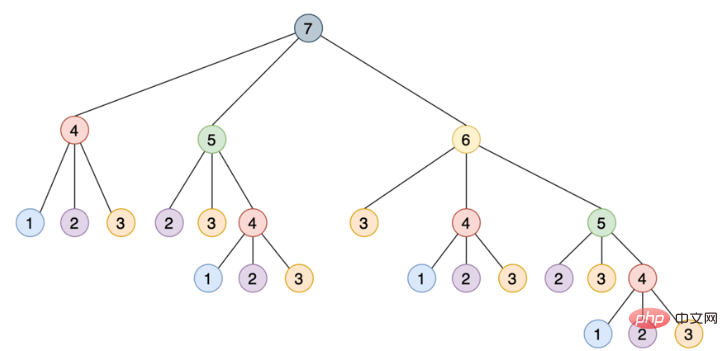
$ python stairs.py 53798080 Minimum execution time: 40.014977024000004 可以看到的秒数取决于特定硬件,在我的系统上,脚本花了 40 秒,这对于 30 级楼梯来说是相当慢的。 使用记忆来改进解决方案: 这种递归实现通过将其分解为相互构建的更小的步骤来解决这个问题,如下所示是一个树,其中每个节点表示对 steps_to() 的特定调用:
注意需要如何使用相同的参数多次调用 steps_to(),例如 steps_to(5) 计算两次,steps_to(4) 计算四次,steps_to(3) 计算七次,steps_to(2) 计算六次,多次调用同一个函数会增加不必要的计算周期,结果总是相同的。 为了解决这个问题,可以使用一种叫做记忆的技术,这种方法将函数的结果存储在内存中,然后在需要时引用它,从而确保函数不会为相同的输入运行多次,这个场景听起来像是使用 Python 的 @lru_cache 装饰器的绝佳机会。 只要做两个改变,就可以大大提高算法的运行时间:
下面是两个更新后的脚本顶部的样子: from functools import lru_cache from timeit import repeat @lru_cache def steps_to(stair): if stair == 1: 运行更新后的脚本产生如下结果: $ python stairs.py 53798080 Minimum execution time: 7.999999999987184e-07 缓存函数的结果会将运行时从 40 秒降低到 0.0008 毫秒,这是一个了不起的进步。@lru_cache 装饰器存储了每个不同输入的 steps_to() 的结果,每次代码调用带有相同参数的函数时,它都直接从内存中返回正确的结果,而不是重新计算一遍答案,这解释了使用 @lru_cache 时性能的巨大提升。 ⑥ 解包 @lru_cache 的功能有了@lru_cache 装饰器,就可以将每个调用和应答存储在内存中,以便以后再次请求时进行访问,但是在内存耗尽之前,可以节省多少次调用呢? Python 的 @lru_cache 装饰器提供了一个 maxsize 属性,它定义了在缓存开始清除旧条目之前的最大条目数,缺省情况下,maxsize 设置为 128,如果将 maxsize 设置为 None,那么缓存将无限增长,并且不会驱逐任何条目。如果在内存中存储大量不同的调用,这可能会成为一个问题。 如下是 @lru_cache 使用 maxsize 属性: from functools import lru_cache
from timeit import repeat
@lru_cache(maxsize=16)
def steps_to(stair):
if stair == 1:在本例中,将缓存限制为最多 16 个条目,当一个新调用传入时,decorator 的实现将会从现有的 16 个条目中删除最近最少使用的条目,为新条目腾出位置。 要查看添加到代码中的新内容会发生什么,可以使用 @lru_cache 装饰器提供的 cache_info() 来检查命中和未命中的次数以及当前缓存的大小。为了清晰起见,删除乘以函数运行时的代码,以下是修改后的最终脚本: from functools import lru_cache
from timeit import repeat
@lru_cache(maxsize=16)
def steps_to(stair):
if stair == 1:
# You can reach the first stair with only a single step
# from the floor.
return 1
elif stair == 2:
# You can reach the second stair by jumping from the
# floor with a single two-stair hop or by jumping a single
# stair a couple of times.
return 2
elif stair == 3:
# You can reach the third stair using four possible
# combinations:
# 1. Jumping all the way from the floor
# 2. Jumping two stairs, then one
# 3. Jumping one stair, then two
# 4. Jumping one stair three times
return 4
else:
# You can reach your current stair from three different places:
# 1. From three stairs down
# 2. From two stairs down
# 2. From one stair down
#
# If you add up the number of ways of getting to those
# those three positions, then you should have your solution.
return (
steps_to(stair - 3)
+ steps_to(stair - 2)
+ steps_to(stair - 1)
)
print(steps_to(30))
print(steps_to.cache_info())如果再次调用脚本,可以看到如下结果: $ python stairs.py 53798080 CacheInfo(hits=52, misses=30, maxsize=16, currsize=16) 可以使用 cache_info() 返回的信息来了解缓存是如何执行的,并对其进行微调,以找到速度和存储之间的适当平衡。下面是 cache_info() 提供的属性的详细说明:
如果需要从缓存中删除所有条目,那么可以使用 @lru_cache 提供的 cache_clear()。 四、添加缓存过期假设想要开发一个脚本来监视 Real Python 并在任何包含单词 Python 的文章中打印字符数。真正的 Python 提供了一个 Atom feed,因此可以使用 feedparser 库来解析提要,并使用请求库来加载本文的内容。 如下是监控脚本的实现: import feedparser
import requests
import ssl
import time
if hasattr(ssl, "_create_unverified_context"):
ssl._create_default_https_context = ssl._create_unverified_context
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def monitor(url):
maxlen = 45
while True:
print("\nChecking feed...")
feed = feedparser.parse(url)
for entry in feed.entries[:5]:
if "python" in entry.title.lower():
truncated_title = (
entry.title[:maxlen] + "..."
if len(entry.title) > maxlen
else entry.title
)
print(
"Match found:",
truncated_title,
len(get_article_from_server(entry.link)),
)
time.sleep(5)
monitor("https://realpython.com/atom.xml")将此脚本保存到一个名为 monitor.py 的文件中,安装 feedparser 和请求库,然后运行该脚本,它将持续运行,直到在终端窗口中按 Ctrl+C 停止它: $ pip install feedparser requests $ python monitor.py Checking feed... Fetching article from server... The Real Python Podcast – Episode #28: Using ... 29520 Fetching article from server... Python Community Interview With David Amos 54256 Fetching article from server... Working With Linked Lists in Python 37099 Fetching article from server... Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... The Real Python Podcast – Episode #27: Prepar... 30784 Checking feed... Fetching article from server... The Real Python Podcast – Episode #28: Using ... 29520 Fetching article from server... Python Community Interview With David Amos 54256 Fetching article from server... Working With Linked Lists in Python 37099 Fetching article from server... Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... The Real Python Podcast – Episode #27: Prepar... 30784 代码解释:
每当脚本加载一篇文章时,“Fetching article from server…”的消息就会打印到控制台,如果让脚本运行足够长的时间,那么将看到这条消息是如何反复显示的,即使在加载相同的链接时也是如此。 这是一个很好的机会来缓存文章的内容,并避免每五秒钟访问一次网络,可以使用 @lru_cache 装饰器,但是如果文章的内容被更新,会发生什么呢?第一次访问文章时,装饰器将存储文章的内容,并在以后每次返回相同的数据;如果更新了帖子,那么监视器脚本将永远无法实现它,因为它将提取存储在缓存中的旧副本。要解决这个问题,可以将缓存条目设置为过期。 from functools import lru_cache, wraps
from datetime import datetime, timedelta
def timed_lru_cache(seconds: int, maxsize: int = 128):
def wrapper_cache(func):
func = lru_cache(maxsize=maxsize)(func)
func.lifetime = timedelta(seconds=seconds)
func.expiration = datetime.utcnow() + func.lifetime
@wraps(func)
def wrapped_func(*args, **kwargs):
if datetime.utcnow() >= func.expiration:
func.cache_clear()
func.expiration = datetime.utcnow() + func.lifetime
return func(*args, **kwargs)
return wrapped_func
return wrapper_cache
@timed_lru_cache(10)
def get_article_from_server(url):
...代码解释: 第 4 行:@timed_lru_cache 装饰器将支持缓存中条目的生命周期(以秒为单位)和缓存的最大大小; 第 6 行:代码用 lru_cache 装饰器包装了装饰函数,这允许使用 lru_cache 已经提供的缓存功能; 第 7 行和第 8 行:这两行用两个表示缓存生命周期和它将过期的实际日期的属性来修饰函数; 第 12 到 14 行:在访问缓存中的条目之前,装饰器检查当前日期是否超过了过期日期,如果是这种情况,那么它将清除缓存并重新计算生存期和过期日期。 请注意,当条目过期时,此装饰器如何清除与该函数关联的整个缓存,生存期适用于整个缓存,而不适用于单个项目,此策略的更复杂实现将根据条目的单个生存期将其逐出。 在程序中,如果想要实现不同缓存策略,可以查看 cachetools 这个库,该库提供了几个集合和修饰符,涵盖了一些最流行的缓存策略。 使用新装饰器缓存文章: 现在可以将新的 @timed_lru_cache 装饰器与监视器脚本一起使用,以防止每次访问时获取文章的内容。为了简单起见,把代码放在一个脚本中,可以得到以下结果: import feedparser
import requests
import ssl
import time
from functools import lru_cache, wraps
from datetime import datetime, timedelta
if hasattr(ssl, "_create_unverified_context"):
ssl._create_default_https_context = ssl._create_unverified_context
def timed_lru_cache(seconds: int, maxsize: int = 128):
def wrapper_cache(func):
func = lru_cache(maxsize=maxsize)(func)
func.lifetime = timedelta(seconds=seconds)
func.expiration = datetime.utcnow() + func.lifetime
@wraps(func)
def wrapped_func(*args, **kwargs):
if datetime.utcnow() >= func.expiration:
func.cache_clear()
func.expiration = datetime.utcnow() + func.lifetime
return func(*args, **kwargs)
return wrapped_func
return wrapper_cache
@timed_lru_cache(10)
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def monitor(url):
maxlen = 45
while True:
print("\nChecking feed...")
feed = feedparser.parse(url)
for entry in feed.entries[:5]:
if "python" in entry.title.lower():
truncated_title = (
entry.title[:maxlen] + "..."
if len(entry.title) > maxlen
else entry.title
)
print(
"Match found:",
truncated_title,
len(get_article_from_server(entry.link)),
)
time.sleep(5)
monitor("https://realpython.com/atom.xml")请注意第 30 行如何使用 @timed_lru_cache 装饰 get_article_from_server() 并指定 10 秒的有效性。在获取文章后的 10 秒内,任何试图从服务器访问同一篇文章的尝试都将从缓存中返回内容,而不会到达网络。 运行脚本并查看结果: $ python monitor.py Checking feed... Fetching article from server... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Fetching article from server... Match found: Python Community Interview With David Amos 54254 Fetching article from server... Match found: Working With Linked Lists in Python 37100 Fetching article from server... Match found: Python Practice Problems: Get Ready for Your ... 164887 Fetching article from server... Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Match found: Python Community Interview With David Amos 54254 Match found: Working With Linked Lists in Python 37100 Match found: Python Practice Problems: Get Ready for Your ... 164887 Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Match found: Python Community Interview With David Amos 54254 Match found: Working With Linked Lists in Python 37100 Match found: Python Practice Problems: Get Ready for Your ... 164887 Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Fetching article from server... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Fetching article from server... Match found: Python Community Interview With David Amos 54254 Fetching article from server... Match found: Working With Linked Lists in Python 37099 Fetching article from server... Match found: Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... Match found: The Real Python Podcast – Episode #27: Prepar... 30783 请注意,代码在第一次访问匹配的文章时是如何打印“Fetching article from server…”这条消息的。之后,根据网络速度和计算能力,脚本将从缓存中检索文章一两次,然后再次访问服务器。 该脚本试图每 5 秒访问这些文章,缓存每 10 秒过期一次。对于实际的应用程序来说,这些时间可能太短,因此可以通过调整这些配置来获得显著的改进。 五、@lru_cache 装饰器的官方实现简单理解,其实就是一个装饰器: def lru_cache(maxsize=128, typed=False):
if isinstance(maxsize, int):
if maxsize < 0:
maxsize = 0
elif callable(maxsize) and isinstance(typed, bool):
user_function, maxsize = maxsize, 128
wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo)
return update_wrapper(wrapper, user_function)
elif maxsize is not None:
raise TypeError('Expected first argument to be an integer, a callable, or None')
def decorating_function(user_function):
wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo)
return update_wrapper(wrapper, user_function)
return decorating_function_CacheInfo = namedtuple("CacheInfo", ["hits", "misses", "maxsize", "currsize"])
def _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo):
sentinel = object() # unique object used to signal cache misses
make_key = _make_key # build a key from the function arguments
PREV, NEXT, KEY, RESULT = 0, 1, 2, 3 # names for the link fields
cache = {} # 存储也使用的字典
hits = misses = 0
full = False
cache_get = cache.get
cache_len = cache.__len__
lock = RLock() # 因为双向链表的更新不是线程安全的所以需要加锁
root = [] # 双向链表
root[:] = [root, root, None, None] # 初始化双向链表
if maxsize == 0:
def wrapper(*args, **kwds):
# No caching -- just a statistics update
nonlocal misses
misses += 1
result = user_function(*args, **kwds)
return result
elif maxsize is None:
def wrapper(*args, **kwds):
# Simple caching without ordering or size limit
nonlocal hits, misses
key = make_key(args, kwds, typed)
result = cache_get(key, sentinel)
if result is not sentinel:
hits += 1
return result
misses += 1
result = user_function(*args, **kwds)
cache[key] = result
return result
else:
def wrapper(*args, **kwds):
# Size limited caching that tracks accesses by recency
nonlocal root, hits, misses, full
key = make_key(args, kwds, typed)
with lock:
link = cache_get(key)
if link is not None:
# Move the link to the front of the circular queue
link_prev, link_next, _key, result = link
link_prev[NEXT] = link_next
link_next[PREV] = link_prev
last = root[PREV]
last[NEXT] = root[PREV] = link
link[PREV] = last
link[NEXT] = root
hits += 1
return result
misses += 1
result = user_function(*args, **kwds)
with lock:
if key in cache:
pass
elif full:
oldroot = root
oldroot[KEY] = key
oldroot[RESULT] = result
root = oldroot[NEXT]
oldkey = root[KEY]
oldresult = root[RESULT]
root[KEY] = root[RESULT] = None
del cache[oldkey]
cache[key] = oldroot
else:
last = root[PREV]
link = [last, root, key, result]
last[NEXT] = root[PREV] = cache[key] = link
full = (cache_len() >= maxsize)
return result
def cache_info():
"""Report cache statistics"""
with lock:
return _CacheInfo(hits, misses, maxsize, cache_len())
def cache_clear():
"""Clear the cache and cache statistics"""
nonlocal hits, misses, full
with lock:
cache.clear()
root[:] = [root, root, None, None]
hits = misses = 0
full = False
wrapper.cache_info = cache_info
wrapper.cache_clear = cache_clear
return wrapper
|
Das obige ist der detaillierte Inhalt vonWie Python die LRU-Cache-Strategie zum Caching verwendet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!