
Heim >Technologie-Peripheriegeräte >KI >Verwenden Sie handgefertigte Funktionen, um die Modellleistung zu verbessern
Verwenden Sie handgefertigte Funktionen, um die Modellleistung zu verbessern

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-12 16:55:061307Durchsuche
Durch die Durchführung handgefertigter Feature-Engineerings an Rohdaten können wir die Modellgenauigkeit und -leistung auf ein neues Niveau heben und so den Weg für genauere Vorhersagen und intelligentere Geschäftsentscheidungen ebnen, die wie nie zuvor optimiert und die Geschäftsfähigkeiten verbessert werden können .

Rohdaten sind wie ein Puzzle ohne Bild – aber mit Feature Engineering können wir die Teile zusammenfügen, obwohl wir viele Daten haben eine Fundgrube für Finanzinstitute, die Modelle für maschinelles Lernen entwickeln möchten, aber es ist auch wichtig zu erkennen, dass nicht alle Daten informativ sind. Darüber hinaus werden die manuellen Funktionen manuell entworfen und die Gründe für jeden Vorgang können erklärt werden, was auch zu einer besseren Interpretierbarkeit führt.
Beim Feature Engineering geht es nicht nur um die Auswahl der besten Features. Dazu gehört auch die Reduzierung von Rauschen und Redundanz in den Daten, um die Generalisierungsfähigkeit des Modells zu verbessern. Dies ist von entscheidender Bedeutung, da Modelle bei der Verarbeitung unsichtbarer Daten eine gute Leistung erbringen müssen, um wirklich nützlich zu sein.
Datensatzbeschreibung
Der in diesem Artikel beschriebene Datensatz wurde anonymisiert und maskiert, um die Vertraulichkeit der Kundendaten zu wahren. Features können wie folgt klassifiziert werden:
D_* = 拖欠变量 S_* = 支出变量 P_* = 支付变量 B_* = 平衡变量 R_* = 风险变量
Es gibt insgesamt 100 Integer-Features und 100 Gleitkomma-Features, die den Status des Kunden in den letzten 12 Monaten darstellen. Dieser Datensatz enthält Informationen zu Kundenberichten im Bereich von 1 bis 13. Zwischen den einzelnen Kreditkartenabrechnungen eines Kunden kann eine Lücke von 30 bis 180 Tagen liegen (d. h. die Kreditkartenabrechnung eines Kunden kann fehlen). Jeder Kunde wird durch eine Kunden-ID repräsentiert. Die Beispieldaten der ersten 5 Datensätze von Kunden mit customer_ID=0 lauten wie folgt:
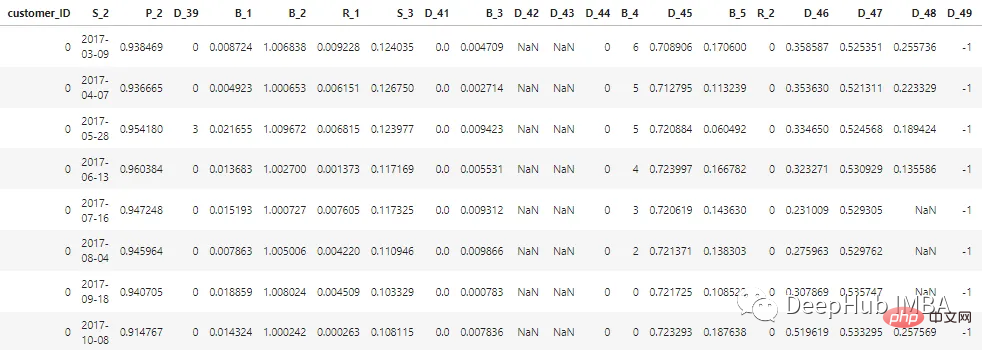
Unter den 7 Millionen customer_IDs sind 98 % der Labels „0“ (Guter Kunde, kein Ausfall), 2 % sind mit „1“ (schlechter Kunde, Ausfall) gekennzeichnet.
Der Datensatz ist groß, daher verwenden wir cudf, um die Verarbeitung zu beschleunigen. Wenn Sie cudf nicht installiert haben, gilt das Gleiche für Pandas
# LOAD LIBRARIES
import pandas as pd, numpy as np # CPU libraries
import cudf # GPU libraries
import matplotlib.pyplot as plt, gc, os
df = cudf.read_parquet('./data.parquet')Funktionsgenerierungsmethode# 🎜🎜## 🎜🎜#Es gibt Hunderte von Ideen, die zum Generieren von Features verwendet werden können. Wir stellen jedoch auch sicher, dass diese Features dazu beitragen, die Leistung des Modells zu verbessern: #🎜🎜 #
#🎜 🎜#Aggregationsfunktionen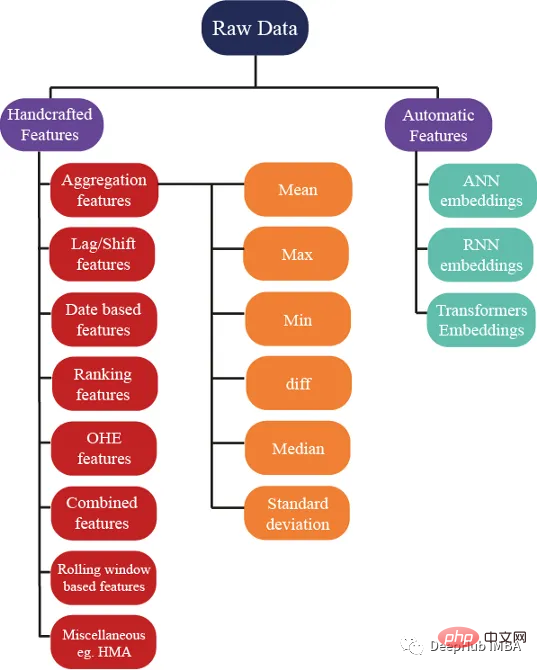 Aggregation ist das Geheimnis zum Verständnis komplexer Daten. Durch die Berechnung zusammenfassender Statistiken für kategoriale Gruppierungsvariablen wie Kunden-ID (C_ID) oder Produktkategorie oder Aggregationen numerischer Variablen können wir unsichtbare Muster und Trends entdecken. Mit zusammenfassenden Statistiken wie Mittelwert, Maximum, Minimum, Standardabweichung und Median können wir genauere Vorhersagemodelle erstellen und aussagekräftige Erkenntnisse aus Kundendaten, Transaktionsdaten oder anderen numerischen Daten gewinnen.
Aggregation ist das Geheimnis zum Verständnis komplexer Daten. Durch die Berechnung zusammenfassender Statistiken für kategoriale Gruppierungsvariablen wie Kunden-ID (C_ID) oder Produktkategorie oder Aggregationen numerischer Variablen können wir unsichtbare Muster und Trends entdecken. Mit zusammenfassenden Statistiken wie Mittelwert, Maximum, Minimum, Standardabweichung und Median können wir genauere Vorhersagemodelle erstellen und aussagekräftige Erkenntnisse aus Kundendaten, Transaktionsdaten oder anderen numerischen Daten gewinnen.
Diese statistischen Attribute können für jeden Kunden berechnet werden.
cat_features = ["B_1","B_2","D_1","D_2","D_10","P_21","D_126","D_3","D_42","R_66","R_68"]
num_features = [col for col in all_cols if col not in cat_features] #all features accept cateforical features.
test_num_agg = df.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last','median']) #grouping by customerID
test_num_agg.columns = ['_'.join(x) for x in test_num_agg.columns]Mittelwert: Der Durchschnittswert einer numerischen Variablen, der einen allgemeinen Eindruck von der zentralen Tendenz der Daten vermitteln kann. Der Durchschnitt erfasst:
Das durchschnittliche Bankguthaben eines Kunden.
Durchschnittliche Kundenausgaben. Die durchschnittliche Zeit zwischen zwei Kreditauszügen (die Zeit zwischen Kreditzahlungen).- Das durchschnittliche Risiko, Geld zu leihen.
- Standardabweichung (Std): Ein Maß für die Verteilung von Daten um den Mittelwert, das Aufschluss über den Grad der Variabilität in den Daten geben kann. Eine hohe Schwankung der Guthaben weist darauf hin, dass Kunden Geld ausgeben.
- Mindest- und Höchstwerte erfassen das Vermögen eines Kunden und erfassen auch Informationen über die Ausgaben und das Risiko eines Kunden.
Median: Wenn die Daten stark verzerrt sind, ist die Verwendung des Mittelwerts keine bessere Idee, daher kann der Median verwendet werden (der Mittelwert des Werts kann verwendet werden).
#🎜🎜 # Die neuesten Werte sind wahrscheinlich das wichtigste Merkmal, da sie Informationen über die letzte bekannte Kreditauskunft des Kunden enthalten und den aktuellen Status des Kundenkontos angeben.Es ist unklug, die oben genannten statistischen Eigenschaften zu verwenden kategoriale Variablen, denn die Berechnung der minimalen, maximalen oder Standardabweichung liefert uns keine nützlichen Informationen. Was können wir also tun? Wir können Merkmale wie Anzahl und eindeutige Menge verwenden, um das Merkmal zu berechnen. Der neueste Wert kann ebenfalls verwendet werden 🎜#
cat_features = ["B_1","B_2","D_1","D_2","D_10","P_21","D_126","D_3","D_42","R_66","R_68"]
test_cat_agg = df.groupby("customer_ID")[cat_features].agg(['count', 'last', 'nunique'])
test_cat_agg.columns = ['_'.join(x) for x in test_cat_agg.columns] Diese Informationen erfassen jedoch nicht, ob der Kunde einer bestimmten Kategorie zugeordnet ist. Daher erfolgt dies durch One-Hot-Codierung der Variablen. Dies wird dann durch die Aggregation der Variablen wie Mittelwert, Summe und Letzte erreicht Der Mittelwert erfasst das Verhältnis zwischen der Gesamtzahl der Zugehörigkeiten eines Kunden zu dieser Kategorie und der Gesamtzahl der Kontoauszüge基于排名的特征
在预测客户行为方面,基于排名的特征是非常重要的。通过根据收入或支出等特定属性对客户进行排名,我们可以深入了解他们的财务习惯并更好地管理风险。
使用 cudf 的 rank 函数,我们可以轻松计算这些特征并使用它们来为预测提供信息。例如,可以根据客户的消费模式、债务收入比或信用评分对客户进行排名。然后这些特征可用于预测违约或识别有可能拖欠付款的客户。
基于排名的特征还可用于识别高价值客户、目标营销工作和优化贷款优惠。例如,可以根据客户接受贷款提议的可能性对客户进行排名,然后将排名最高的客户作为目标。
df[feat+'_rank']=df[feat].rank(pct=True, method='min')
PCT用于是否做百分位排名。客户的排名也可以基于分类特征来计算。
df[feat+'_rank']=df.groupby([cat_feat]).rank(pct=True, method='min')
特征组合
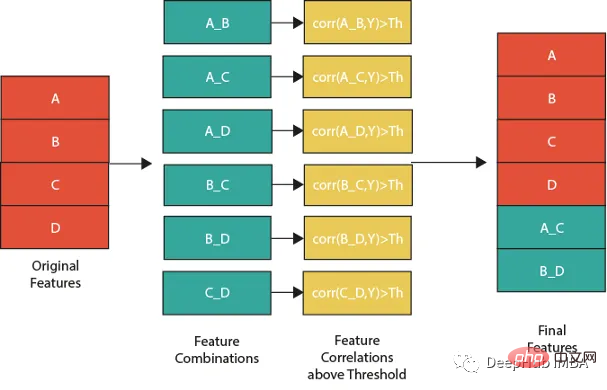
特征组合的一种流行方法是线性或非线性组合。这包括采用两个或多个现有特征,将它们组合在一起创建一个新的复合特征。然后使用这个复合特征来识别单独查看单个特征时可能不可见的模式、趋势和相关性。
例如,假设我们正在分析客户消费习惯的数据集。可以从个人特征开始,比如年龄、收入和地点。但是通过以线性或非线性的方式组合这些特性,可以创建新的复合特性,使我们能够更多地了解客户。可以结合收入和位置来创建一个复合特征,该特征告诉我们某一地区客户的平均支出。
但是并不是所有的特征组合都有用。关键是要确定哪些组合与试图解决的问题最相关,这需要对数据和问题领域有深刻的理解,并仔细分析创建的复合特征和试图预测的目标变量之间的相关性。
下图展示了一个组合特征并将信息用于模型的过程。作为筛选条件,这里只选择那些与目标相关性大于最大值 0.9 的特征。
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features] for feat1 in features: for feat2 in features: th=max(np.corr(feat1,Y)[0],np.corr(feat1,Y)[0]) #calculate threshold feat3=df[feat1]-df[feat2] #difference feature corr3=np.corr(feat3,Y)[0] if(corr3>max(th,0.9)): #if correlation greater than max(th,0.9) we add it as feature df[feat1+'_'+feat2]=feat3
基于时间/日期的特征
在数据分析方面,基于时间的特征非常重要。通过根据时间属性(例如月份或星期几)对数据进行分组,可以创建强大的特征。这些特征的范围可以从简单的平均值(如收入和支出)到更复杂的属性(如信用评分随时间的变化)。
借助基于时间的特征,还可以识别在孤立地查看数据时可能看不到的模式和趋势。下图演示了如何使用基于时间的特征来创建有用的复合属性。
首先,计算一个月内的值的平均值(可以使用该月的某天或该月的某周等),将获得的DF与原始数据合并,并取各个特征之间的差。
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features]
month_Agg=df.groupby([month])[features].agg('mean')#grouping based on month feature
month_Agg.columns = ['_month_'.join(x) for x in month_Agg.columns]
month_Agg.reset_index(inplace=True)
df=df.groupby(month_Agg,notallow='month')
for feat in features: #create composite features b taking difference
df[feat+'_'+feat+'_month_mean']=df[feat]-df[feat+'_month_mean']
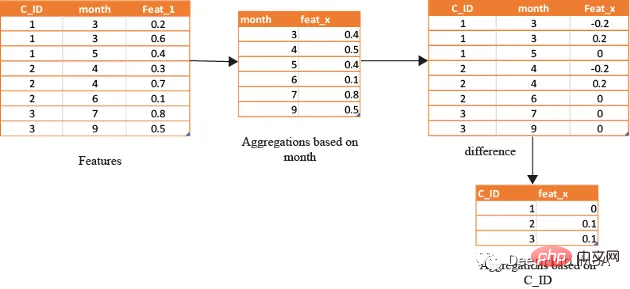
还可以通过使用时间作为分组变量来创建基于排名的特征,如下所示
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features] month_Agg=df.groupby([month])[features].rank(pct=True) #grouping based on month feature month_Agg.columns = ['_month_'.join(x) for x in month_Agg.columns] month_Agg.reset_index(inplace=True) df=pd.concat([df,month_Agg],axis=1) #concat to original dataframe
滞后特征
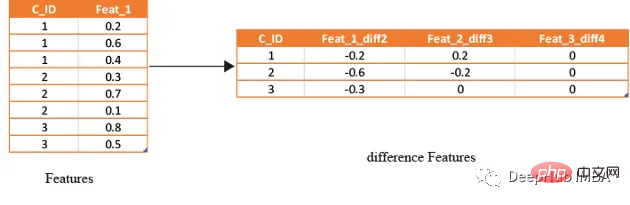
滞后特征是有效预测金融数据的重要工具。这些特征包括计算时间序列中当前值与之前值之间的差值。通过将滞后特征纳入分析,可以更好地理解数据中的模式和趋势,并做出更准确的预测。
如果滞后特征显示客户连续几个月按时支付信用卡账单,可能会预测他们将来不太可能违约。相反,如果延迟特征显示客户一直延迟或错过付款,可能会预测他们更有可能违约。
# difference function calculate the lag difference for numerical features
#between last value and shift last value.
def difference(groups,num_features,shift):
data=(groups[num_features].nth(-1)-groups[num_features].nth(-1*shift)).rename(columns={f: f"{f}_diff{shift}" for f in num_features})
return data
#calculate diff features for last -2nd last, last -3rd last, last- 4th last
def get_difference(data,num_features):
print("diff features...")
groups=data.groupby('customer_ID')
df1=difference(groups,num_features,2).fillna(0)
df2=difference(groups,num_features,3).fillna(0)
df3=difference(groups,num_features,4).fillna(0)
df1=pd.concat([df1,df2,df3],axis=1)
df1.reset_index(inplace=True)
df1.sort_values(by='customer_ID')
del df2,df3
gc.collect()
return df1train_diff = get_difference(df, num_features)
基于滚动窗口的特性
这些特征只是取最后3(4,5,…x)值的平均值,这取决于数据,因为基于时间的最新值携带了关于客户最新状态的信息。
xth=3 #define the window size
df["cumulative"]=df.groupby('customer_ID').sort_values(by=['time'],ascending=False).cumcount()
last_info=df[df["cumulative"]<=xth]
last_info = last_info.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last','median']) #grouping by customerID
last_info.columns = ['_'.join(x) for x in last_info.columns]其他的特征提取方法
上面的方法已经创建了足够多的特征来构建一个很棒的模型。但是根据数据的性质,还可以创建更多的特征。例如:可以创建像null计数这样的特征,它可以计算客户当前的总null值,从而帮助捕获基于树的算法无法理解的特征分布。
def calc_nan(df,features):
print("calculating nan_info...")
df_nan = (df[features].mul(0) + 1).fillna(0) #marke non_null values as 1 and null as zero
df_nan['customer_ID'] = df['customer_ID']
nan_sum = df_nan.groupby("customer_ID").sum().sum(axis=1) #total unknown values for a customer
nan_last = df_nan.groupby("customer_ID").last().sum(axis=1)#how many last values that are not known
del df_nan
gc.collect()
return nan_sum,nan_last这里可以不使用平均值,而是使用修正的平均值,如基于时间的加权平均值或 HMA(hull moving average)。
Zusammenfassung
In diesem Artikel werden einige der häufigsten handgefertigten Feature-Strategien vorgestellt, die zur Vorhersage des Ausfallrisikos in der realen Welt verwendet werden. Es gibt jedoch immer neue und innovative Möglichkeiten, Features zu entwerfen, und die Methode zum manuellen Festlegen von Features ist zeitaufwändig und mühsam. Daher werden wir in einem späteren Artikel die Verwendung von Tools für die automatische Feature-Generierung vorstellen.
Das obige ist der detaillierte Inhalt vonVerwenden Sie handgefertigte Funktionen, um die Modellleistung zu verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr