
Heim >Technologie-Peripheriegeräte >KI >KI beendet das Malen auf dem Mobiltelefon innerhalb von 12 Sekunden! Google schlägt eine neue Methode zur Beschleunigung der Diffusionsmodellinferenz vor
KI beendet das Malen auf dem Mobiltelefon innerhalb von 12 Sekunden! Google schlägt eine neue Methode zur Beschleunigung der Diffusionsmodellinferenz vor

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-12 10:43:051143Durchsuche
Mit Stable Diffusion dauert es nur 12 Sekunden, um ein Bild zu erzeugen, bei dem nur die Rechenleistung des Mobiltelefons genutzt wird.
Und es ist die Art, die 20 Iterationen abgeschlossen hat.

Sie müssen wissen, dass die aktuellen Diffusionsmodelle grundsätzlich mehr als 1 Milliarde Parameter umfassen. Wenn Sie schnell ein Bild generieren möchten, müssen Sie entweder Cloud Computing verwenden oder Die lokale Hardware muss leistungsstark genug sein.
Da Anwendungen für große Modelle immer beliebter werden, dürfte die Ausführung großer Modelle auf PCs und Mobiltelefonen in Zukunft ein neuer Trend sein.
Als Ergebnis haben Google-Forscher dieses neue Ergebnis vorgelegt. Der Name lautet Geschwindigkeit ist alles, was Sie brauchen: Beschleunigen Sie groß angelegte Diffusionsmodelle auf Geräten durch GPU-Optimierung Denkgeschwindigkeit.

Dreistufige Optimierungsbeschleunigung
Diese Methode ist für stabile Diffusion optimiert, kann aber auch an andere Diffusionen angepasst werden Modell. Die Aufgabe besteht darin, Bilder aus Text zu generieren.
Spezifische Optimierung kann in drei Teile unterteilt werden:
- Entwerfen Sie einen speziellen Kernel
- Verbessern Achtung Modelleffizienz
- Winograd-Faltungsbeschleunigung
Schauen Sie sich zunächst den speziell entwickelten Kernel an, der Gruppennormalisierungs- und GELU-Aktivierungsfunktionen enthält.
Gruppennormalisierung wird in der gesamten UNet-Architektur implementiert. Diese Normalisierung funktioniert durch die Aufteilung der Kanäle der Feature-Map in kleinere Gruppen und die Normalisierung jeder Gruppe unabhängig, wodurch die Gruppennormalisierung weniger von der Stapelgröße abhängt und an a angepasst werden kann größeres Spektrum an Batchgrößen und Netzwerkarchitekturen.
Die Forscher haben einen einzigartigen Kernel in Form eines GPU-Shaders entworfen, der alle Kernel in einem einzigen GPU-Befehl ohne Zwischentensoren ausführen kann.
Die GELU-Aktivierungsfunktion enthält eine große Anzahl numerischer Berechnungen, wie z. B. Strafe, Gaußsche Fehlerfunktion usw.
Durch einen speziellen Shader zur Integration dieser numerischen Berechnungen und der zugehörigen Divisions- und Multiplikationsoperationen können diese Berechnungen in einen einfachen Zeichenaufruf eingefügt werden.
Draw-Aufruf ist ein Vorgang, bei dem die CPU die Bildprogrammierschnittstelle aufruft und die GPU zum Rendern anweist.
Als nächstes stellt das Papier zwei Optimierungsmethoden vor, wenn es darum geht, die Effizienz des Aufmerksamkeitsmodells zu verbessern.
Eine davon ist die teilweise Fusion der Softmax-Funktion.
Um zu vermeiden, dass die gesamte Softmax-Berechnung für die große Matrix A durchgeführt wird, wurde in der Studie ein GPU-Shader zur Berechnung der L- und S-Vektoren entwickelt, um die Berechnungen zu reduzieren, was letztendlich zu einem Tensor der Größe N×2 führte . Anschließend werden die Softmax-Berechnung und die Matrixmultiplikation der Matrix V zusammengeführt.
Dieser Ansatz reduziert den Speicherbedarf und die Gesamtlatenz des Zwischenprogramms erheblich.
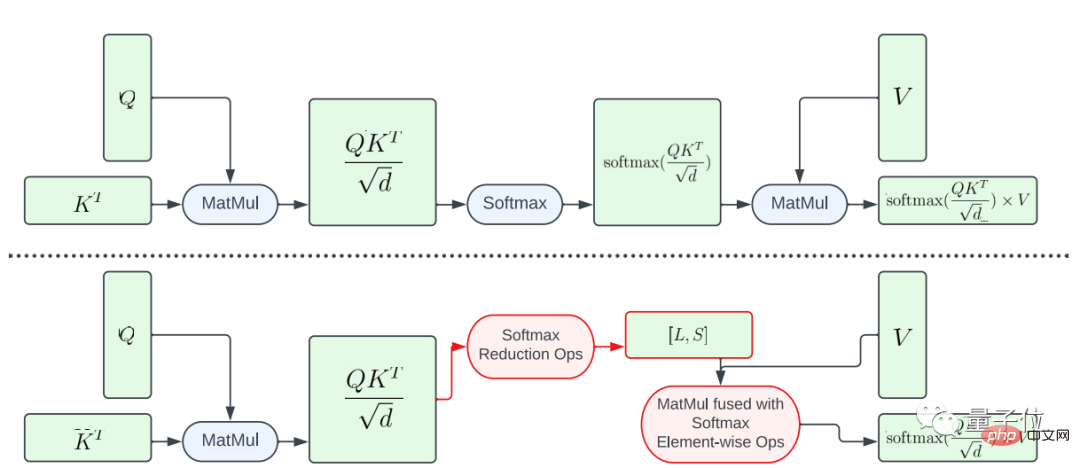
Es sollte betont werden, dass die Parallelität der rechnerischen Abbildung von A nach L und S begrenzt ist, da die Elemente im Ergebnistensor größer sind als diese im Eingabetensor A Die Anzahl der Elemente ist viel kleiner.
Um die Parallelität zu erhöhen und die Latenz weiter zu reduzieren, organisierte diese Studie die Elemente in A in Blöcken und unterteilte die Reduktionsoperationen in mehrere Teile.
Die Berechnung wird dann für jeden Block durchgeführt und dann auf das Endergebnis reduziert.
Durch sorgfältig konzipiertes Threading und Speicher-Cache-Management kann eine geringere Latenz in mehreren Teilen mit einem einzigen GPU-Befehl erreicht werden.
Eine weitere Optimierungsmethode ist FlashAttention.
Dies ist der IO-bewusste präzise Aufmerksamkeitsalgorithmus, der letztes Jahr populär wurde. Es gibt zwei spezifische Beschleunigungstechnologien: inkrementelle Berechnung nach Block, also Kacheln, und Neuberechnung der Aufmerksamkeit im Rückwärtsdurchlauf Achtung Force-Operationen sind in CUDA-Kernel integriert.
Im Vergleich zur Standard-Aufmerksamkeit kann diese Methode den HBM-Zugriff (Speicher mit hoher Bandbreite) reduzieren und die Gesamteffizienz verbessern.
Allerdings ist der FlashAttention-Kern sehr registerintensiv, sodass das Team diese Optimierungsmethode gezielt einsetzt.
Sie verwenden FlashAttention auf der Adreno-GPU und der Apple-GPU mit Aufmerksamkeitsmatrix d=40 und verwenden in anderen Fällen die Partial-Fusion-Softmax-Funktion.
Der dritte Teil ist die Winograd-Faltungsbeschleunigung.
Sein Prinzip besteht einfach darin, mehr Additionsberechnungen zu verwenden, um Multiplikationsberechnungen zu reduzieren und dadurch die Anzahl der Berechnungen zu reduzieren.
Aber auch die Nachteile liegen auf der Hand, was zu einem höheren Videospeicherverbrauch und numerischen Fehlern führt, insbesondere wenn die Kachel relativ groß ist.
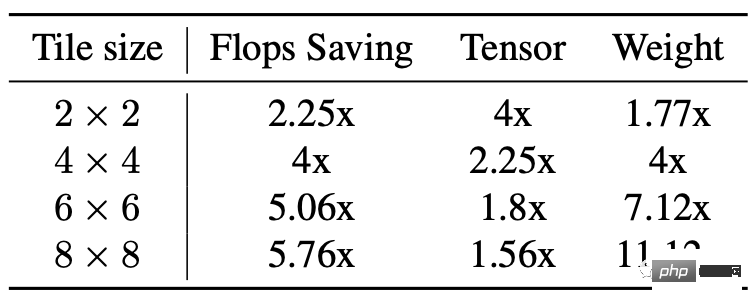
Das Rückgrat der stabilen Diffusion basiert stark auf 3×3-Faltungsschichten, insbesondere im Bilddecoder, wo 90 % der Schichten aus 3×3-Faltungsschichten bestehen.
Nach der Analyse stellten die Forscher fest, dass die Verwendung von 4×4-Kacheln das beste Gleichgewicht zwischen Modellrecheneffizienz und Videospeicherauslastung darstellt.
Experimentelle Ergebnisse
Um den Verbesserungseffekt zu bewerten, führten die Forscher zunächst Benchmark-Tests auf Mobiltelefonen durch.
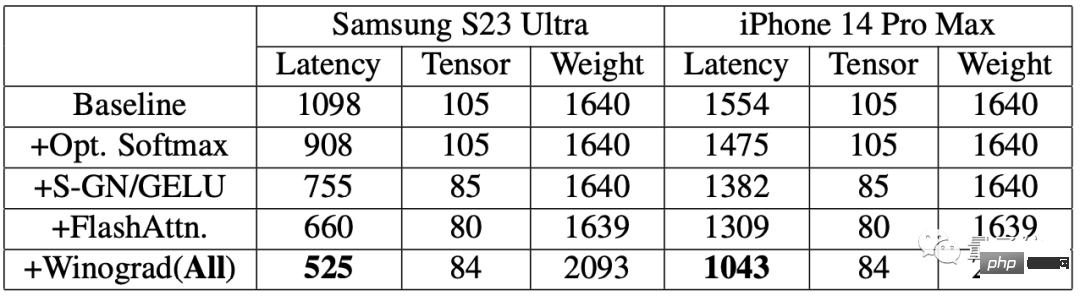
Die Ergebnisse zeigen, dass nach Verwendung des Beschleunigungsalgorithmus die Geschwindigkeit der Bilderzeugung auf beiden Telefonen deutlich verbessert wurde.
Unter anderem wurde die Latenz beim Samsung S23 Ultra um 52,2 % und die Latenz beim iPhone 14 Pro Max um 32,9 % reduziert.
Generieren Sie auf dem Samsung S23 Ultra ein Bild mit 512 x 512 Pixeln durchgängig aus Text, mit 20 Iterationen und in weniger als 12 Sekunden.
Papieradresse: https://www.php.cn/link/ba825ea8a40c385c33407ebe566fa1bc
Das obige ist der detaillierte Inhalt vonKI beendet das Malen auf dem Mobiltelefon innerhalb von 12 Sekunden! Google schlägt eine neue Methode zur Beschleunigung der Diffusionsmodellinferenz vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr