
Heim >Technologie-Peripheriegeräte >KI >DetGPT, das Bilder lesen, chatten und modalübergreifendes Denken und Positionieren durchführen kann, ist hier, um komplexe Szenarien umzusetzen.
DetGPT, das Bilder lesen, chatten und modalübergreifendes Denken und Positionieren durchführen kann, ist hier, um komplexe Szenarien umzusetzen.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-11 23:28:051298Durchsuche
Menschen haben schon immer davon geträumt, dass Roboter Menschen bei der Bewältigung von Lebens- und Arbeitsangelegenheiten unterstützen können. „Bitte helfen Sie mir, die Temperatur der Klimaanlage herunterzudrehen“ und sogar „Bitte helfen Sie mir, eine Website für ein Einkaufszentrum zu schreiben“ wurden in den letzten Jahren alle mit Heimassistenten und Copilot umgesetzt, die von OpenAI veröffentlicht wurden.
Das Aufkommen von GPT-4 zeigt uns erneut das Potenzial multimodaler großer Modelle für das visuelle Verständnis. In Bezug auf Open-Source-Modelle kleiner und mittlerer Größe schneiden LLAVA und minigpt-4 gut ab. Sie können Bilder ansehen und chatten und auch Rezepte in Essensbildern für Menschen erraten. Allerdings stehen diese Modelle bei der tatsächlichen Umsetzung immer noch vor großen Herausforderungen: Sie verfügen nicht über präzise Positionierungsmöglichkeiten, können die spezifische Position eines Objekts im Bild nicht angeben und können komplexe menschliche Anweisungen zur Erkennung bestimmter Objekte nicht verstehen bestimmte Aufgaben ausführen. In tatsächlichen Szenarien stoßen Menschen auf komplexe Probleme. Wenn sie den intelligenten Assistenten bitten können, die richtige Antwort zu erhalten, indem sie ein Foto machen, ist eine solche „Foto-und-Fragen“-Funktion einfach cool.
Um die Funktion „Foto und Fragen“ zu realisieren, muss der Roboter über mehrere Fähigkeiten verfügen:
#🎜🎜 # 1. Fähigkeit zum Sprachverständnis: Fähigkeit, menschliche Absichten zuzuhören und zu verstehen
2. Fähigkeit zum visuellen Verständnis: Fähigkeit, die Objekte im Bild zu verstehen# 🎜 🎜#
3. Fähigkeit zum gesunden Menschenverstand: Fähigkeit, komplexe menschliche Absichten in präzise Ziele umzuwandeln, die lokalisiert werden können.4 Fähigkeit: Kann entsprechende Objekte auf dem Bildschirm lokalisieren und erkennen. Forscher der Hong Kong University of Science and Technology und der Hong Kong University haben jedoch ein vollständig Open-Source-Modell DetGPT (vollständiger Name DetectionGPT) vorgeschlagen, das nur drei Millionen Parameter feinabstimmen muss, sodass das Modell problemlos über komplexe und lokale Argumente verfügen kann Objektpositionierungsfunktionen und können auf die meisten Szenen im großen Maßstab verallgemeinert werden. Dies bedeutet, dass das Modell menschliche abstrakte Anweisungen verstehen kann, indem es auf der Grundlage seines eigenen Wissens argumentiert, und Objekte von menschlichem Interesse in Bildern leicht identifizieren kann! Sie haben das Modell in eine „Foto- und Frage“-Demo umgewandelt. Sie können es gerne online erleben: https://detgpt.github.io/
DetGPT ermöglicht es Benutzern Verwenden Sie natürliche Sprache. Bedienen Sie alles ohne umständliche Befehle oder Schnittstellen. Gleichzeitig verfügt DetGPT auch über intelligente Argumentations- und Zielerkennungsfunktionen, die die Bedürfnisse und Absichten des Benutzers genau verstehen können. Wenn ein Mensch beispielsweise den verbalen Befehl „Ich möchte ein Kaltgetränk trinken“ sendet, sucht der Roboter zunächst in der Szene nach einem Kaltgetränk, findet es aber nicht. Also begann ich zu denken: „In der Szene gibt es kein kaltes Getränk, wo soll ich es finden?“ Durch das leistungsstarke Modell des gesunden Menschenverstandes dachte ich an den Kühlschrank, scannte also die Szene, fand den Kühlschrank und konnte den Ort des Getränks erfolgreich sperren!
Offener Quellcode: 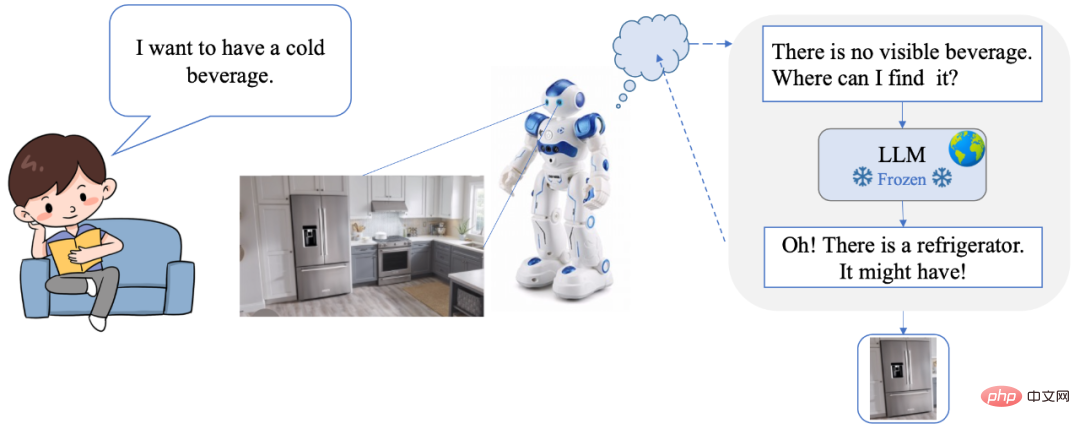
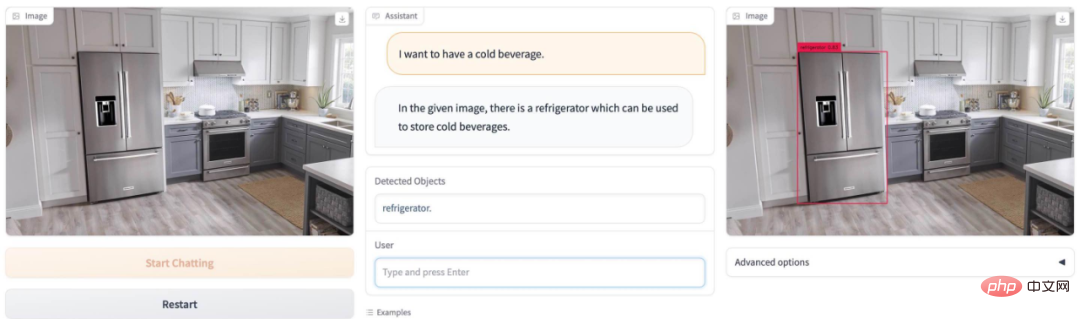
- https://www.php.cn/link/10eb6500bd1e4a3704818012a1593cc3#🎜 🎜## 🎜🎜 # Demo-Online-Testversion: https://detgpt.github.io/ Wenn Sie im Sommer durstig sind, wo ist das Eis? Getränk auf dem Bild? DetGPT Leicht verständlich Finden Sie den Kühlschrank:
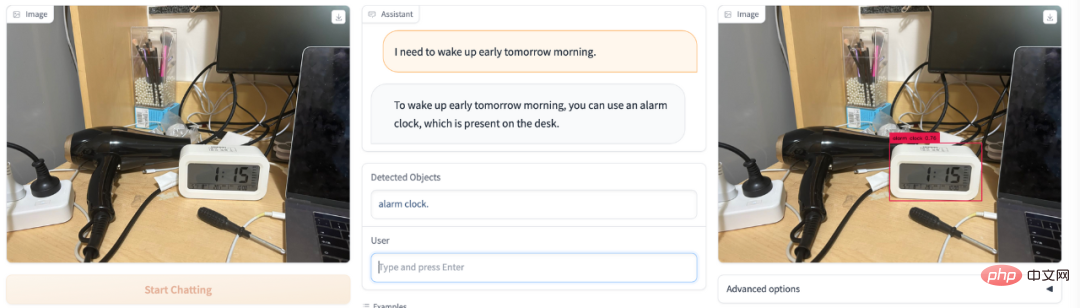
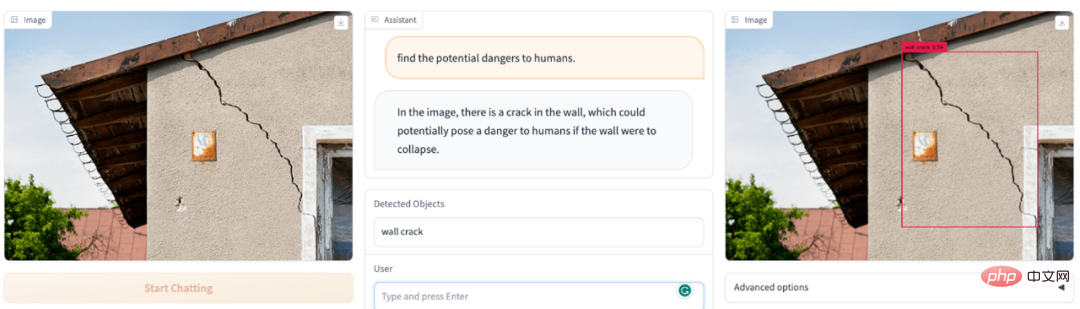
Welche gefährlichen Dinge befinden sich im Sichtfeld des Bildes? DetGPT wird Ihr Sicherheitsbeauftragter: Welche Gegenstände auf dem Bild sind gefährlich für Kinder? DetGPT ist immer noch in Ordnung: Eine neue Richtung, die Aufmerksamkeit verdient: Verwendung von gesundem Menschenverstand, um eine genauere Erkennung offener Ziele zu erreichen Traditionelle Erkennungsaufgaben erfordern die Voreinstellung möglicher Objektkategorien für die Erkennung. Doch eine genaue und umfassende Beschreibung der zu erkennenden Objekte ist für den Menschen unfreundlich oder sogar unrealistisch. Insbesondere (1) sind Menschen aufgrund ihres begrenzten Gedächtnisses/Wissens nicht immer in der Lage, die Zielobjekte, die sie erkennen möchten, genau auszudrücken. Beispielsweise empfehlen Ärzte Menschen mit hohem Blutdruck, mehr Obst zu essen, um Kalium zu ergänzen. Ohne zu wissen, welche Früchte reich an Kalium sind, können sie dem Erkennungsmodell keine spezifischen Fruchtnamen geben Der Mensch muss nur ein Foto machen, und das Modell selbst wird kaliumreiche Früchte denken, begründen und erkennen. (2) Die Objektkategorien, die Menschen veranschaulichen können, sind nicht umfassend. Wenn wir beispielsweise Verhaltensweisen überwachen, die mit der öffentlichen Ordnung an öffentlichen Orten unvereinbar sind, können Menschen möglicherweise einfach einige Szenarien auflisten, wie z. B. das Halten von Messern und das Rauchen öffentliche Ordnung“ zum Erkennungsmodell hinzufügen. Wenn das Modell selbstständig denkt und auf der Grundlage seines eigenen Wissens Schlussfolgerungen zieht, kann es mehr schlechtes Verhalten erfassen und auf verwandte Kategorien verallgemeinern, die erkannt werden müssen. Schließlich ist das Wissen, das normale Menschen verstehen, begrenzt, und die Arten von Objekten, die zitiert werden können, sind ebenfalls begrenzt. Wenn es jedoch ein Gehirn wie ChatGPT zur Unterstützung und Argumentation gibt, werden die Anweisungen, die Menschen geben müssen, viel einfacher sein Die erhaltenen Antworten können auch viel genauer und umfassender sein. Basierend auf der Abstraktion und den Grenzen menschlicher Anweisungen schlugen Forscher der Hong Kong University of Science and Technology und der University of Hong Kong eine neue Richtung der „inferentiellen Zielerkennung“ vor. Vereinfacht ausgedrückt gibt der Mensch einige abstrakte Aufgaben, und das Modell kann selbst verstehen und überlegen, welche Objekte im Bild diese Aufgabe erfüllen und sie erkennen können. Um ein einfaches Beispiel zu nennen: Wenn ein Mensch beschreibt: „Ich möchte ein kaltes Getränk, wo kann ich es finden“, sieht das Modell ein Foto einer Küche und kann den „Kühlschrank“ erkennen. Dieses Thema erfordert die perfekte Kombination der Bildverständnisfähigkeiten multimodaler Modelle und des reichhaltigen Wissens, das in großen Sprachmodellen gespeichert ist, und deren Verwendung in feinkörnigen Erkennungsaufgabenszenarien: Verwendung des Gehirns von Sprachmodellen, um menschliche abstrakte Anweisungen genau zu verstehen Suchen Sie Bilder nach Objekten von menschlichem Interesse ohne voreingestellte Objektkategorien. „Inferentielle Zielerkennung“ ist ein schwieriges Problem, da der Detektor nicht nur die grobkörnigen/abstrakten Anweisungen des Benutzers verstehen und darüber nachdenken muss, sondern auch die aktuell gesehenen visuellen Informationen analysieren muss, um das Ziel zu lokalisieren . aus dem Zielobjekt. In dieser Richtung haben Forscher von HKUST und HKU einige vorläufige Untersuchungen durchgeführt. Insbesondere nutzen sie einen vorab trainierten visuellen Encoder (BLIP-2), um visuelle Bildmerkmale zu erhalten und die visuellen Merkmale über eine Ausrichtungsfunktion am Textraum auszurichten. Verwenden Sie ein umfangreiches Sprachmodell (Robin/Vicuna), um Benutzerfragen zu verstehen und die angezeigten visuellen Informationen zu kombinieren, um Überlegungen zu den Objekten anzustellen, an denen der Benutzer wirklich interessiert ist. Die Objektnamen werden dann einem vortrainierten Detektor (Grouding-DINO) zur Vorhersage bestimmter Standorte zugeführt. Auf diese Weise kann das Modell das Bild gemäß den Anweisungen des Benutzers analysieren und den Standort des für den Benutzer interessanten Objekts genau vorhersagen. Es ist erwähnenswert, dass die Schwierigkeit hier hauptsächlich darin besteht, dass das Modell in der Lage sein muss, eine aufgabenspezifische Ausgabe für verschiedene spezifische Aufgaben zu erzielen, ohne die ursprünglichen Fähigkeiten des Modells so stark wie möglich zu beeinträchtigen. Um das Sprachmodell dazu zu bringen, einem bestimmten Muster zu folgen, Schlussfolgerungen zu ziehen und eine Ausgabe zu generieren, die dem Zielerkennungsformat entspricht, unter der Voraussetzung, Bilder und Benutzeranweisungen zu verstehen, verwendete das Forschungsteam ChatGPT, um modalübergreifende Befehlsdaten zu generieren, um diese zu verfeinern. Tunen Sie das Modell. Konkret nutzten sie ChatGPT, um auf der Grundlage von 5.000 Coco-Bildern 30.000 modalübergreifende Bild-Text-Feinabstimmungsdatensätze zu erstellen. Um die Effizienz des Trainings zu verbessern, haben sie andere Modellparameter festgelegt und nur die modalübergreifende lineare Zuordnung gelernt. Experimentelle Ergebnisse belegen, dass das Sprachmodell selbst dann, wenn nur die lineare Ebene fein abgestimmt ist, feinkörnige Bildmerkmale verstehen und bestimmten Mustern folgen kann, um inferenzbasierte Bilderkennungsaufgaben auszuführen, was eine hervorragende Leistung zeigt. Dieses Forschungsthema hat großes Potenzial. Basierend auf dieser Technologie wird der Bereich der Heimroboter weiter glänzen: Menschen zu Hause können abstrakte oder grobkörnige Sprachanweisungen verwenden, damit Roboter benötigte Gegenstände verstehen, identifizieren und lokalisieren und damit verbundene Dienste bereitstellen können. Im Bereich der Industrieroboter wird diese Technologie unendliche Vitalität ausstrahlen: Industrieroboter können natürlicher mit menschlichen Arbeitern zusammenarbeiten, ihre Anweisungen und Bedürfnisse genau verstehen und intelligente Entscheidungen und Abläufe treffen. An der Produktionslinie können menschliche Arbeiter grobkörnige Sprachanweisungen oder Texteingaben verwenden, um es Robotern zu ermöglichen, die zu verarbeitenden Artikel automatisch zu verstehen, zu identifizieren und zu lokalisieren, wodurch die Produktionseffizienz und -qualität verbessert wird. Basierend auf dem Zielerkennungsmodell mit eigenen Argumentationsfähigkeiten können wir intelligentere, natürlichere und effizientere Roboter entwickeln, um Menschen bequemere, effizientere und humanere Dienste zu bieten. Dies ist ein Bereich mit breiten Perspektiven. Es verdient auch mehr Aufmerksamkeit und weitere Erforschung durch Forscher. Es ist erwähnenswert, dass DetGPT mehrere Sprachmodelle unterstützt und anhand von zwei Sprachmodellen verifiziert wurde: Robin-13B und Vicuna-13B. Das Sprachmodell der Robin-Serie ist ein Dialogmodell, das vom LMFlow-Team der Hong Kong University of Science and Technology trainiert wurde (https://github.com/OptimalScale/LMFlow). Es hat bei mehreren Benchmarks zur Bewertung der Sprachkenntnisse vergleichbare Ergebnisse erzielt (Modell-Download: https://github.com/OptimalScale/LMFlow#model-zoo). Heart of the Machine berichtete zuvor, dass das LMFlow-Team exklusives ChatGPT in nur 5 Stunden auf der Consumer-Grafikkarte 3090 trainieren kann. Heute haben uns dieses Team und das HKU NLP Laboratory eine weitere multimodale Überraschung beschert. 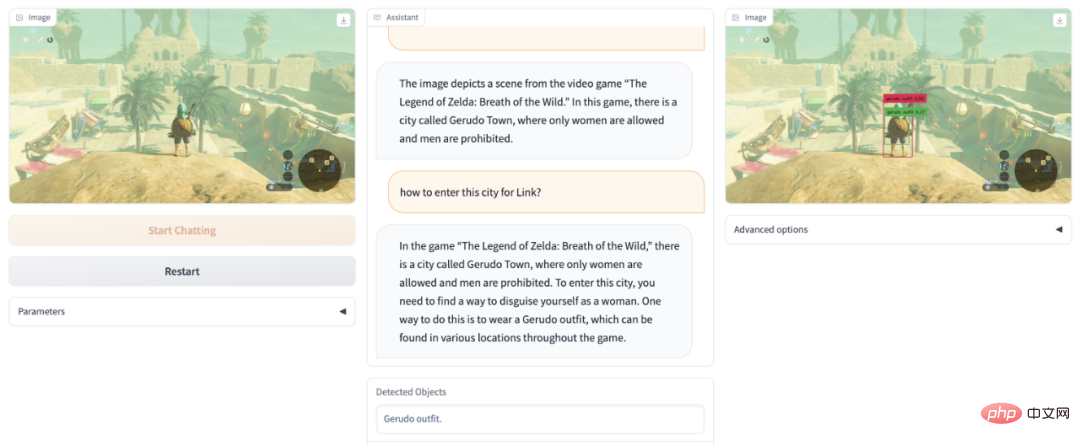
Welche Funktionen hat DetGPT?

Einführung in die Methode
Das obige ist der detaillierte Inhalt vonDetGPT, das Bilder lesen, chatten und modalübergreifendes Denken und Positionieren durchführen kann, ist hier, um komplexe Szenarien umzusetzen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr